SQL SERVER大话存储结构(6)_数据库数据文件
1 创建数据文件时,在考虑什么
1.1 数据文件与文件组
- 建立表格及索引时,只能指定到某一个文件组,不能够指定到这个文件组的某个文件
- 同一个文件组内的数据文件,起到一个平摊分布数据的作用,如果是位于不同的驱动器,则有利于提高并发IO,如果是位于同一个驱动器,则有利于后期的运维管理;
- 当使用表分区的时候,每一个分区会使用到一个辅助数据文件(可以同一个驱动器,也可以不同)
- 大库的灵活运维管理,其实呢,如果在同一个驱动器上建立多个数据文件,对IO性能并没有任何改善,但是,却为后期的管理提供了方便性,尤其是大库管理,比如线上数据库损坏,需要还原出来一个新的数据文件,或者是测试环境的搭建等等,很多时候会遇到剩余的磁盘空间并不足以来存放这个大库,但是如果是多个数据文件,那么就可以分开指定驱动器存储,减少磁盘大小的要求。
- 使用表分区
- 当磁盘IO资源出现瓶颈的情况下,可以考虑迁移部分热表到 其他文件组的文件上(不同驱动器),分散IO;
- 当磁盘空间不足但是想把文件中的 冷表(类似与记录登录日志)的表格,迁移到其他驱动器上,可以考虑使用文件组;
- 历史数据和热数据分开,历史归档数据损坏,不影响热数据;
- 大库的灵活运维管理,可以使用文件组来备份数据库的一部分,比如某些特定的表格放在 辅助数据文件上,出事故后,还原的时候,可以对数据库进行部分还原,主文件组还原结束,即可提供服务,但在其他文件组上的对象暂时不能使用,等到其他文件组也还原结束,其存储的数据才能提供服务。
--案例 1 :给数据库 dbpage新增 文件组 testfg,并在这个文件组内建立辅助数据文件 dbpage_3,dbpage_4
USE [master]
GO
ALTER DATABASE [dbpage] ADD FILEGROUP [testfg]
GO ALTER DATABASE [dbpage]
ADD FILE (
NAME = N'dbpage_3',
FILENAME = N'D:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER2012\MSSQL\DATA\dbpage_3.ndf' ,
SIZE = 51200KB ,
FILEGROWTH = 10240KB
) TO FILEGROUP [testfg]
GO ALTER DATABASE [dbpage]
ADD FILE (
NAME = N'dbpage_4',
FILENAME = N'D:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER2012\MSSQL\DATA\dbpage_4.ndf' ,
SIZE = 51200KB ,
FILEGROWTH = 10240KB
) TO FILEGROUP [testfg]
GO --案例 2 :指定文件组创建表格
CREATE TABLE tbtest(id int not null,name varchar(10) not null) on [testfg] --案例 3 :迁移表到其他文件组
--表无聚集索引,通过建立聚集索引,把整个表格迁移到 指定文件组
alter table tbtest add constraint pk_tbtest primary key (id) on [testfg] --表有聚集索引
方法一:重建聚集索引,先删除聚集索引,然后再建立新的聚集索引指定到文件组,如上一个SQL
方法二:利用表分区,先建立 中间表格,中间表添加分区方案,分区建立在 指定的文件组上,然后再 需要迁移到表格上执行 swith partion,然后重命名表格,最后删除旧表,中间表格的分区脚步这里不涉及 ALTER TABLE tbtest SWITCH PARTITION 1 TO tbtest_new PARTITION 1
GO EXEC sp_rename 'tbtest','tbtest_old'
EXEC sp_rename 'tbtest_new','tbtest'
GO DROP TABLE tbtest_old
GO
select
fg.name fgname,o.name tbname ,index_id,rows,au.type_desc,au.container_id,au.total_pages,au.used_pages,au.data_pages
from sys.partitions p
join sys.allocation_units au on p.partition_id=au.container_id
join sys.filegroups fg on fg.data_space_id=au.data_space_id
join sys.objects o on p.object_id=o.object_id
where o.type='u' and p.object_id=object_id('orders')


with data as(
select
fg.name fg_name, o.name tbname
from sys.partitions p
join sys.allocation_units au on p.partition_id=au.container_id
join sys.objects o on p.object_id=o.object_id
join sys.filegroups fg on fg.data_space_id=au.data_space_id
where o.type='u'
group by o.name,fg.name
)
select
a.fg_name,
count(*) tbcount,
tbnames=stuff((select ','+b.tbname from data b where a.fg_name=b.fg_name order by tbname for xml path('')),1,1,'')
from data a
group by fg_name

1.2 增长选项
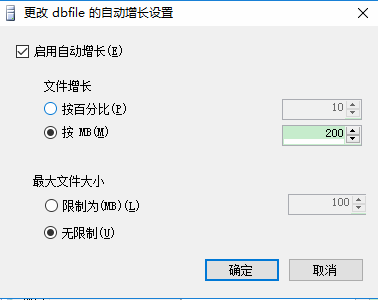
1.3 即时初始化
- 创建数据库
- 向现有数据库中添加文件
- 增大现有文件的大小、包括自动增长操作(不含日志文件的自动增长)
- 还原数据库或文件组

/*
以全局方式打开跟踪标记 3004 和 3605。
3004:查看SQL Server对日志文件进行填零初始化的过程
3605:要求DBCC的输出放到SQL server ERROR LOG
-1:以全局方式打开指定的跟踪标记。
*/ DBCC TRACEON(3004,3605,-1)
GO --创建测试库
CREATE DATABASE [xinysu]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'xinysu',
FILENAME = N'D:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER2012\MSSQL\DATA\xinysu.mdf' ,
SIZE = 104857600KB , FILEGROWTH = 204800KB
)
LOG ON
( NAME = N'xinysu_log',
FILENAME = N'D:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER2012\MSSQL\DATA\xinysu_log.ldf' ,
SIZE = 524288KB , FILEGROWTH = 102400KB
)
GO --查看错误日志
Exec xp_readerrorlog 0,1,Null,Null,'2017-05-29 10:28:00','2017-05-29 10:30:00' --删除测试库
DROP DATABASE xinysu
GO DBCC TRACEOFF(3004,3605,-1)
GO
2 DB收缩
2.1 指令及设置
DBCC SHRINKFILE ( { file_name | file_id } { [ , EMPTYFILE ] | [ [ , target_size ] [ , { NOTRUNCATE | TRUNCATEONLY } ] ] } ) [ WITH NO_INFOMSGS ]
/*
target_size
用兆字节表示的文件大小(用整数表示)。 如果未指定,则 DBCC SHRINKFILE 将文件大小减少到默认文件大小。 默认大小为创建文件时指定的大小。如果target_size指定,DBCC SHRINKFILE 尝试将文件收缩到指定的大小。 将要释放的文件部分中的已使用页重新定位到保留的文件部分中的可用空间。
EMPTYFILE
将所有数据从指定的文件都迁移到其他文件相同的文件组。 换而言之,清空文件将迁移数据,从指定的文件到同一个文件组中的其他文件。 清空文件可确保你没有新数据将添加到文件。可以通过删除该文件ALTER DATABASE语句。
NOTRUNCATE
文件末尾的可用空间不会返回给操作系统,文件的物理大小也不会更改。 因此,指定 NOTRUNCATE 时,文件看起来未收缩。
NOTRUNCATE 只适用于数据文件。 日志文件不受影响。
TRUNCATEONLY
将文件末尾的所有可用空间释放给操作系统,但不在文件内部执行任何页移动。 数据文件只收缩到最后分配的区。
target_size如果使用 TRUNCATEONLY 指定将被忽略。
TRUNCATEONLY 选项不会移动日志中的信息,但会删除日志文件末尾的失效 VLF。
WITH NO_INFOMSGS
取消显示所有信息性消息。
*/
--举例说明
DBCC SHRINKFILE ( dbpage_data, 100 )
DBCC SHRINKFILE ( dbpage_data, EMPTYFILE)
--清空 dbpage_data 数据文件上面的所有内容
DBCC SHRINKFILE ( dbpage_data, 100 ,NOTRUNCATE)
--收缩数据库 datapage的数据文件,文件名师 dbpage_data,收缩到100Mb
--重新分配超过100Mb的数据行到前面100Mb未分配的区,保留空闲空间
DBCC SHRINKFILE ( dbpage_data, TRUNCATEONLY)
--收缩数据库 datapage的数据文件,文件名是 dbpage_data,文件末尾未使用的空间释放给操作系统,不会重新分配数据行到未分配的区
DBCC SHRINKDATABASE ( database_name | database_id | 0 [ , target_percent ] [ , { NOTRUNCATE | TRUNCATEONLY } ] ) [ WITH NO_INFOMSGS ]
/*
database_name | database_id | 0
要收缩的数据库的名称或 ID。 如果指定 0,则使用当前数据库。
target_percent
数据库收缩后的数据库文件中所需的剩余可用空间百分比。
NOTRUNCATE
通过将已分配的区从文件末尾移动到文件前面的未分配区来压缩数据文件中的数据。 target_percent是可选的。
文件末尾的可用空间不会返回给操作系统,文件的物理大小也不会更改。 因此,指定 NOTRUNCATE 时,数据库看起来未收缩。
NOTRUNCATE 只适用于数据文件。 日志文件不受影响。
TRUNCATEONLY
将文件末尾的所有可用空间释放给操作系统,但不在文件内部执行任何页移动。 数据文件只收缩到最后分配的区。 target_percent如果使用 TRUNCATEONLY 指定将被忽略。
TRUNCATEONLY 将影响日志文件。 若要仅截断数据文件,请使用 DBCC SHRINKFILE。
WITH NO_INFOMSGS
取消严重级别从 0 到 10 的所有信息性消息。
*/
--举例说明
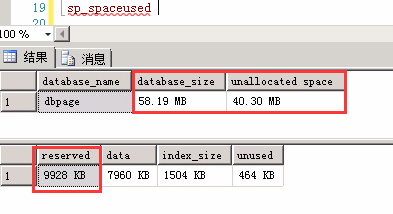
DBCC SHRINKDATABASE (dbpage, 20)
--对数据库dbpage执行收缩处理,其中收缩后空闲空间占整个数据库大小的 20%
--等同于先执行 DBCC SHRINKDATABASE (dbpage, 20, NOTRUNCATE) ,再执行DBCC SHRINKDATABASE (dbpage, 20, TRUNCATEONLY)
DBCC SHRINKDATABASE (dbpage, 20, NOTRUNCATE)
--对数据库dbpage执行收缩处理,其中收缩后空闲空间占整个数据库大小的 20%
--数据文件,分配文件末尾的区到文件前面未分配的区,压缩空间不会返回给操作系统,文件大小不变
DBCC SHRINKDATABASE (dbpage, 20, TRUNCATEONLY)
--对数据库dbpage执行收缩处理,但是收缩的空间不一定是 20%
--收缩的空间是文件末尾的可用空间,也就是 target_percent 在这里指定了也没有用
--日志文件跟数据文件,释放文件末尾的可用空间给系统文件,但是文件内不执行任何数据页移动
.png)
.png)


.png)
2.2 原理
- 文件并没有变小
- 是否执行的命令含有 NOTRUNCATE
- 是否指定的大小比实际数据的大小还要小
- 数据文件没有空闲的区
- 日志文件中的LSN无法截断,详情查看本系列第6篇
- 执行时间非常久
- 某些 基于版本控制隔离级别 的事务 堵塞了 收缩操作,这里会在 errorlog中有记录,可以查看
- 如果是这个原因堵塞,可以选择停止收缩操作或者停止事务操作或者等待
- 回收的空间特别大,并且回收的空间上有大量的数据页面需要重分配到前面的空闲数据页面上
3 空间计算方法和区别
.png)

3.1 基于区统计
.png)
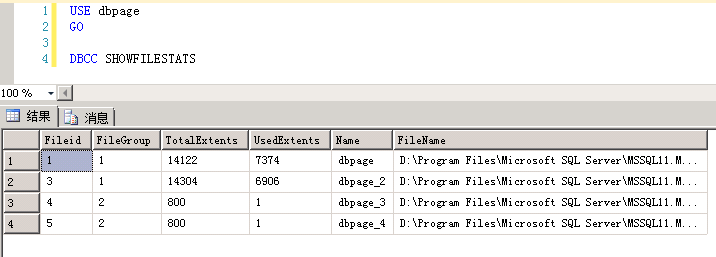
3.2 基于页面统计
3.2.1 sp_spaceused
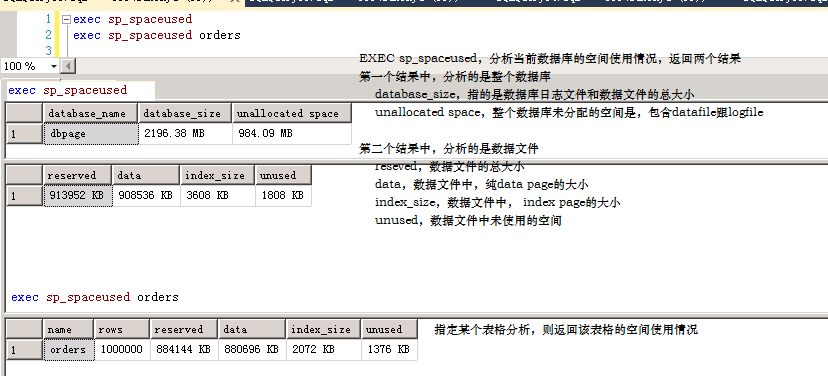
3.2.2 sys.dm_db_partition_status
select
o.name,
sum(case when (p.index_id<2) then row_count end) rows,
sum(p.reserved_page_count)*8 reseved_kb,
sum(p.reserved_page_count-p.used_page_count)*8 unused_kb,
sum(p.used_page_count)*8 used_kb,
sum(case when (p.index_id<2) then (p.in_row_data_page_count+p.lob_used_page_count+p.row_overflow_used_page_count)
else p.lob_used_page_count+p.row_overflow_used_page_count end
)*8 data_kb,
sum(p.used_page_count-(case when (p.index_id<2) then (p.in_row_data_page_count+p.lob_used_page_count+p.row_overflow_used_page_count)
else p.lob_used_page_count+p.row_overflow_used_page_count end)
)*8 index_kb
from sys.dm_db_partition_stats p inner join sys.objects o on p.object_id=o.object_id
where o.type='u'
and o.name in ('orders','tba','tb_clu_no_unique')
group by o.name
order by o.name

3.2.3 DBCC SHOWCONTIG
.png)
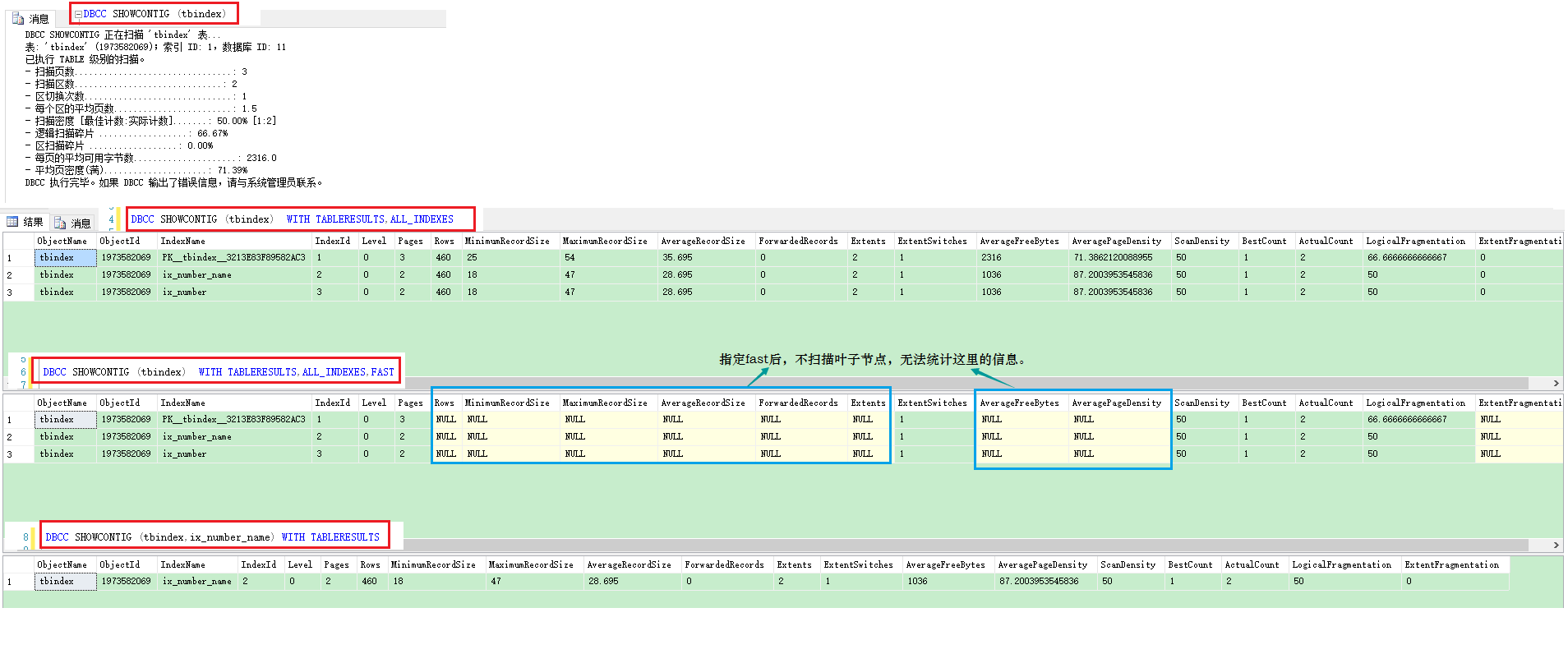
.png)

SQL SERVER大话存储结构(6)_数据库数据文件的更多相关文章
- SQL SERVER大话存储结构(3)_数据行的行结构
一行数据是如何来存储的呢? 变长列与定长列,NULL与NOT NULL,实际是如何整理存放到 8k的数据页上呢? 对表格进行增减列,修改长度,添加默认值等DDL SQL ...
- SQL SERVER大话存储结构(4)_复合索引与包含索引
索引这块从存储结构来分,有2大类,聚集索引和非聚集索引,而非聚集索引在堆表或者在聚集索引表都会对其 键值有所影响,这块可以详细查看本系列第二篇文章:SQL SERVER大话存储结构 ...
- SQL SERVER大话存储结构(5)_SQL SERVER 事务日志解析
本系列上一篇博文链接:SQL SERVER大话存储结构(4)_复合索引与包含索引 1 基本介绍 每个数据库都具有事务日志,用于记录所有事物以及每个事物对数据库所作的操作. 日志的记录 ...
- SQL SERVER大话存储结构(1)_数据页类型及页面指令分析
如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有.望各位支持! SQLServer的数据页大 ...
- SQL SERVER大话存储结构(2)_非聚集索引如何查找到行记录
如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有.望各位支持! 1 行记录如何存储 这里引入两个 ...
- 人人都是 DBA(VIII)SQL Server 页存储结构
当在 SQL Server 数据库中创建一张表时,会在多张系统基础表中插入所创建表的信息,用于管理该表.通过目录视图 sys.tables, sys.columns, sys.indexes 可以查看 ...
- [转帖]真TM长的:SQL Server 2008存储结构——GAM和SGAM、PFS结构、IAM结构、DCM&BCM
谈到GAM和SGAM,我们不得不从数据库的页和区说起. https://blog.csdn.net/snowfoxmonitor/article/details/49991015 一个数据库由用户定义 ...
- SQL Server DBA日常查询视图_数据库对象视图
1.数据库 use master; exec sp_helpdb 1.1查询数据库大小 1.2查询数据库状态 use msdb select name, user_access_desc, --用户访 ...
- 为何SQL SERVER使用sa账号登录还原数据库BAK文件失败,但是使用windows登录就可以
今天发现一个问题,就是公司开发服务器上的sql server使用sa账号登录后,还原一个数据库bak文件老是报错,错误如下: TITLE: Microsoft SQL Server Managemen ...
随机推荐
- vim粘贴代码问题
vim粘贴代码问题 vim 在使用xshell进行vim操作的时候,经常会直接粘贴一些外部的代码,然后粘贴上之后会出现逐行缩进的情况,之前一直没有去找为啥,并且逐行的给他弄回去. 转自:https:/ ...
- HTML解析器BeautifulSoup
BeautifulSoup是Python的一个库,可解析用urllib2抓取下来的HTML 1.Beautiful Soup 安装 可以利用 pip 来安装,在Python程序中导入 pip inst ...
- fir.im Weekly - 如何在 iOS 上构建 TensorFlow 应用
本期 fir.im Weekly 收集了最近新鲜出炉的 iOS /Android 技术分享,包括 iOS 系统开发 TensorFlow 教程.iOS 新架构.iOS Notifications 推送 ...
- jasmine 初探(一)
前言 <敏捷软件开发>这本书由享誉全球的软件开发专家和软件大师Robert C.Martin所著中提到两个开发方式: TDD(Test Driven Development)测试驱动开发 ...
- office web apps 部署-搭建域控服务器
开始第一条先说注意事项:我所配置的环境是用了三台2012server虚拟机,三台虚拟机必须要加下域控,而且登录操作的时候必须以域账号登录,否则测试不通过!在笔记本上搭建了两个虚拟机(window se ...
- Hopfield神经网络实现污染字体的识别
这个网络的内部使用的是hebb学习规则 贴上两段代码: package geym.nn.hopfiled; import java.util.Arrays; import org.neuroph.co ...
- [笔记]机器学习(Machine Learning) - 01.线性回归(Linear Regression)
线性回归属于回归问题.对于回归问题,解决流程为: 给定数据集中每个样本及其正确答案,选择一个模型函数h(hypothesis,假设),并为h找到适应数据的(未必是全局)最优解,即找出最优解下的h的参数 ...
- Redis学习-SortedSet
Sorted-Sets和Sets类型极为相似,它们都是字符串的集合,都不允许重复的成员出现在一个Set中.它们之间的主要差别是Sorted-Sets中的每一个成员都会有一个分数(score)与之关联, ...
- iOS开发中,info.plist配置用户隐私的保护
info.plist 配置[用户隐私的保护] >= iOS10 Privacy - Bluetooth Peripheral Usage Description --> App需要您的 ...
- Quartz.net 定时任务之简单任务
一.概述 1.quartz.net 是一款从java quartz 上延伸出来的定时任务框架. 2.我在网上看到很多大神写过关于quartz.net 的博客.文章等,在这些博客文章里也学会了很多关于q ...