刨根究底字符编码之十——Unicode字符集的字符编码方式CEF
Unicode字符集的字符编码方式CEF

一、字符编码方式CEF的选择
1.
由于Unicode字符集非常大,有些字符的编号(码点值)需要两个或两个以上字节来表示,而要对这样的编号进行编码,也必须使用两个或两个以上字节。
比如,汉字“严”的Unicode码(Unicode码点值、Unicode编号)是十六进制数4E25,转换成二进制数有15位(100 1110 0010 0101),对“严”这个字符的编号进行编码的话,至少需要2个字节。表示其他更大编号的字符,可能需要3个字节或者4个字节,甚至更多。
2.
这带来两个问题:
一是,如何才能区别Unicode字符和ASCII字符的编码?计算机怎么知道三个字节表示的是一个字符,而不是分别表示三个字符呢?
二是,我们知道,英文字母只用一个字节来编码就够了,而如果Unicode统一硬性规定,每个字符都用两个、三个或四个字节来编码,那么每个英文字母编码的前面都必然有一个、两个到三个字节全是0,这对于存储和传输来说是极大的浪费。
这就涉及到了字符编码方式CEF的选择问题。Unicode字符的编码方式一般有三种:UFF-8、UTF-16、UTF-32。在具体介绍这些编码方式之前,需要再次深入了解两个概念——码点(Code Point)与码元(Code Unit)。
二、码点
1.
一个字符集一般可以用一张或多张由多个行和多个列所构成的二维表来表示。
二维表中行与列相交的点,称之为码点(Code Point代码点),也称之为码位(Code position代码位);每个码点分配一个唯一的编号,称之为码点值或码点编号,除开某些特殊区域(比如代理区、专用区)的非字符码点和保留码点,每个码点唯一对应于一个字符。
因此,除开非字符码点和保留码点,码点值(即码点编号)通常来说就是其所对应的字符的编号,所以码点值有时也可以直接称之为字符编号,虽然不够准确,但更为直接。
2.
字符集中所有码点数量的总和,称之为编号空间(Code Space,又被称之为代码空间、编码空间、码点空间、码空间)。
码点值最初用两个字节的十六进制数字表示,比如字母A的Unicode码点值为0041,常写作U+0041,这种形式称为Unicode码点名称,不严格地来讲,也可称之Unicode字符名称(因为存在着非字符码点和保留码点,并非每个码点都分配了字符,所以这种称呼不够准确,不过目前更为普遍)。
3.
后来随着Unicode字符集的不断增补扩大(比如现在的Unicode字符集至少需要21位才能全部表示),码点值也扩展为用三个字节或以上的十六进制数字表示。
例如,ASCII字符集用0~127这连续的128个数字编号分别表示128个字符。GBK字符集使用区位码的方式为每个字符编号,首先定义一个94×94的矩阵,行称为“区”,列称为“位”,然后将所有国标汉字放入矩阵当中,这样每个汉字就可以用唯一的“区位”码来标识了。例如“中”字被放到54区第48位,因此其区位码(字符编号)就是5448。
而目前Unicode标准中,将字符按照一定的类别划分到0~16这17个平面(Plane层面)中,每个平面中拥有2^16 = 65536个码点,因此,目前Unicode字符集所拥有的码点总数,也就是Unicode的编号空间为17*65536=1114112。
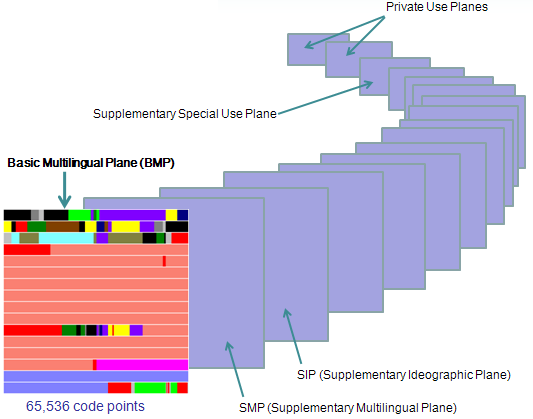
注意,网络上的很多文章中,代码点、码点、码点值、码值、代码位、码位、字符码、Unicode码、字符编号、字符编码、编码方案、编码方式、编码格式等等经常互相代替混用。
(笨笨阿林原创文章,转载请注明出处)
三、码元
1.
在计算机存储和网络传输时,码点值(即字符编号)被映射到一个或多个码元(Code Unit代码单元、编码单元)。
码元可理解为字符编码方式CEF(Character Encoding Form)对码点值进行编码处理时作为一个整体来看待的最小基本单元(基本单位)。
2.
为什么非要引入“码元”这个概念?或者说,为什么非要强调“码元”这个概念?
码元某种程度上可认为对应于高级语言中的基本数据类型。而高级语言层面的基本数据类型,若要更深入一步地来讲,实质上对应于机器硬件层面(汇编语言)的数据类型byte字节、word字、dword双字等在硬件中的表达与处理机制。
之所以要强调“码元”的概念,是因为字符编码作为一串数字序列,最终还是得通过机器硬件层面的数据类型来表示。
而码元的实质,就是机器硬件层面(汇编语言)的数据类型;不同的码元,代表着不同位数的数据类型。
3.
数据类型有单字节与多字节之分,所以码元也有单字节与多字节之分;多字节数据类型由于历史的原因,存在着字节序的所谓大端序(Big-Endian)与小端序(Little-Endian)之分,因此多字节码元也存在着大端序与小端序之分(具体详见前文中有关字节序的解释;注意,单字节数据类型则没有字节序的问题,所以单字节码元也就没有字节序问题)。
这就是之所以要强调“码元”这个概念的关键原因。
4.
码点值(即字符编号)的具体实现方式——字符编码方式CEF,就是由一个或多个码元这样的最小基本单元构成的。
最常用的码元是8位(1字节)的单字节码元,另外还有16位(2字节)和32位(4字节)两种多字节码元,分别相当于C++中的无符号整型BYTE、WORD、DWORD(在VC++6.0中,这三种数据类型的定义分别为:
typedef unsigned char BYTE;,1个字节;
typedef unsigned short WORD;,2个字节;
typedef unsigned long DWORD;,4个字节)。
(笨笨阿林原创文章,转载请注明出处)
5.
于是,三种码元对应就有了Unicode字符编号(码点值)的三种UTF编码方式(即Unicode码转换格式Unicode Transformation Format,或称通用字符集转换格式UCS Transformation Format):
UTF-8(8-bit Unicode/UCS Transformation Format),
UTF-16(16-bit Unicode/UCS Transformation Format),
UTF-32(32-bit Unicode/UCS Transformation Format);
或者反过来说,Unicode字符编号(码点值)的三种UTF编码方式(UTF-8、UTF-16、UTF-32)分别采用了不同的码元(BYTE、WORD、DWORD)来编码。
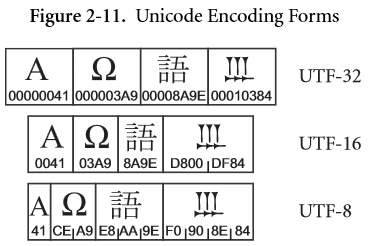
例如,“汉字”这两个中文字符的Unicode码点值(Unicode字符编号)是0x6C49和0x5B57,其三种UTF编码在VC++6.0中可按如下定义进行“模拟”:

6.
注意,这里之所以说是“模拟”,因为从本质上来讲,在机器硬件层面上的所有数据类型,只存在着被视作一个整体来处理的比特序列(比特流)的位数不同之分,不存在着高级语言层面上数据类型的数值、字符串、布尔值等的语义不同之分。
因此,机器硬件层面上的数据类型与高级语言层面上的数据类型,严格来讲,在本质含义上还是有着很大不同的。当然,高级语言层面上的数据类型最终还是会被转化为机器硬件层面上的数据类型,毕竟计算机只“认识”由0和1所组成的比特流。具体详见前文中有关字节序的解释。
7.
这里用BYTE、WORD、DWORD分别表示无符号8位整数、无符号16位整数和无符号32位整数;因而UTF-8、UTF-16、UTF-32可认为分别以BYTE、WORD、DWORD作为码元。
“汉字”这两个中文字符的UTF-8编码需要六个BYTE(共6个单字节码元),大小是6个字节;UTF-16编码需要两个WORD(共2个双字节码元),大小是4个字节;UTF-32编码需要两个DWORD(共2个四字节码元),大小是8个字节。
由于多字节数据类型的数据在计算机存取时存在一个字节序的问题,因此,UTF-16、UTF-32这两种编码方式所编码出来的逻辑意义上的多字节码元序列,在映射为物理意义上的字节序列时,字节序列的字节序因系统平台的不同而不同。
前面已经多次强调过了,这里再次特别强调一下:由单字节数据类型所组成的多字节数据是不存在字节序的问题的。因此,采用单字节码元进行编码的UTF-8编码,虽然ASCII字符为单字节编码,但非ASCII字符是多字节编码的,但却不存在字节序问题,这是跟同样为多字节编码、但采用多字节码元的UTF-16、UTF-32不同之处。详见下表所列:
Unicode字符集三大UTF编码方式(UTF-8、UTF-16、UTF-32)比较一览表
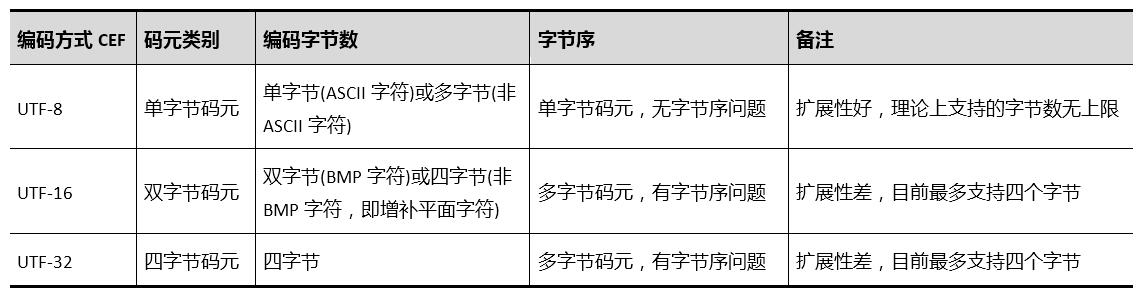
(笨笨阿林原创文章,转载请注明出处)
【预告:下一篇将重点讲解UTF-8编码方式与字节序标记(BOM),敬请关注!】
刨根究底字符编码之十——Unicode字符集的字符编码方式CEF的更多相关文章
- 刨根究底字符编码之十——Unicode字符集的编码方式以及码点、码元
Unicode字符集的编码方式以及码点.码元 一.字符编码方式CEF的选择 1. 由于Unicode字符集非常大,有些字符的编号(码点值)需要两个或两个以上字节来表示,而要对这样的编号进行编码,也必须 ...
- Unicode字符集,utf8编码,base64编码简单了解
Unicode字符集,utf8编码,base64编码简单了解 Unicode字符集,ASCII,GB2312编码集合等,类似于不同的字典,不同的字符的编码,类似于字典中的字在哪一个页哪一排. 当不同系 ...
- JAVA字符编码二:Unicode,ISO-8859,GBK,UTF-8编码及相互转换
第二篇:JAVA字符编码系列二:Unicode,ISO-8859-1,GBK,UTF-8编码及相互转换 1.函数介绍 在Java中,字符串用统一的Unicode编码,每个字符占用两个字节,与编码有 ...
- 关于Unicode,字符集,字符编码,每个程序员都应该知道的事
关于Unicode,字符集,字符编码,每个程序员都应该知道的事 作者:Jack47 李笑来的文章如何判断一个人是否聪明?中提到: 必要.清晰.且准确的概念,是一切思考的基石.所谓思考,很大程度上,就是 ...
- 关于Unicode,字符集,字符编码
基本概念 字符[character] 字符代表了字母表中的字符,标点符号和其他的一些符号.在计算机中,文本是由字符组成的. 字符集合[character set] 由一套用于特定用途的字符组成,例如支 ...
- zzy:java采用的是16位的Unicode字符集作为编码方式------理解
java语言使用16位的Unicode字符集作为编码方式,是疯狂Java中的原话. 1,编码方式只是针对字符类型的(不包括字符串类,数值类型int等,这些只是在解释[执行]的时候放到Jvm的不同内存块 ...
- Java应用开发中的字符集与字符编码
事出有因 在向HttpURLConnection的输出流写入内容时,因没有设置charset,导致接收方对数据的验签不一致. URL url = new URL(requestUrl); //打开连接 ...
- 字符串编码研究:Unicode
Unicode Unicode 编码系统可分为编码方式和实现方式两个层次. 1.编码方式 Unicode字符平面映射定义了所有的Unicode字符集. 2.实现方式(UTF8,UTF16) UTF-8 ...
- 刨根究底字符编码之十六——Windows记事本的诡异怪事:微软为什么跟联通有仇?(没有BOM,所以被误判为UTF8。“联通”两个汉字的GB内码,其第一第二个字节的起始部分分别是“110”和“10”,,第三第四个字节也分别是“110”和“10”)
1. 当用一个软件(比如Windows记事本或Notepad++)打开一个文本文件时,它要做的第一件事是确定这个文本文件究竟是使用哪种编码方式保存的,以便于该软件对其正确解码,否则将显示为乱码. 一般 ...
随机推荐
- POI框架实现创建Excel表、添加数据、读取数据
public class TestPOI2Excel {//创建2003版本Excel用此方法 @Test public void testWrite03Excel() throws Exceptio ...
- 在ASP.NET MVC4中配置Castle
---恢复内容开始--- Castle是针对.NET平台的一个非常优秀的开源项目,重点是开源的哦.它在NHibernate的基础上进一步封装,其原理基本与NHibernate相同,但它较好地解决NHi ...
- Java常用的八种排序算法与代码实现
1.直接插入排序 经常碰到这样一类排序问题:把新的数据插入到已经排好的数据列中. 将第一个数和第二个数排序,然后构成一个有序序列 将第三个数插入进去,构成一个新的有序序列. 对第四个数.第五个数--直 ...
- android通过代码获取华为手机的EMUI系统版本号
因为app中用到华为推送,但是华为推送在不同版本上是存在不同问题的,需要单独来处理. 那么最基本的问题是要获取EMUI系统的版本号. 上网翻了很多博客帖子,基本上是在获取root权限下去读取/syst ...
- php变量布尔值验证
使用 PHP 函数对变量 $x 进行比较 表达式 gettype() empty() is_null() isset() boolean : if($x) $x = ""; str ...
- 原生态JS实现banner图的常用所有功能
虽然,用jQuery实现banner图的各种效果十分简单快捷,但是我今天用css+js代码实现了几个banner图的常用功能,效果还不错. 此次,主要想实现以下功能: 1. banner图循环不间断切 ...
- stm32中断学习总结
经过了两天,终于差不多能看懂32的中断了,由于是用的库函数操作的,所以有些内部知识并没有求甚解,只是理解知道是这样的.但对于要做简单开发的我来说这些已经够了. 我学习喜欢从一个例程来看,下面的程序是我 ...
- js倒计时,秒倒计时,天倒计时
按天倒计时 HTML代码1: <Script Language="JavaScript"> <!-- Begin var timedate= new Date(& ...
- Python、PyCharm的安装及使用方法(Mac版)
上周跟朋友喝咖啡时聊起我想学Python,她恰好也有这个打算,顺便推荐了一本书<编程小白的第1本Python入门书>,我推送到Kindle后,随手翻看了下,用语平实,简洁易懂. 之前在R语 ...
- ssh整合时报出的异常及解决办法
com.opensymphony.xwork2.inject.DependencyException: com.opensymphony.xwork2.inject.ContainerImpl$Mis ...