Python 项目实践二(下载数据)第四篇
接着上节继续学习,在本节中,你将下载JSON格式的人口数据,并使用json模块来处理它们。Pygal提供了一个适合初学者使用的地图创建工具,你将使用它来对人口数据进行可视化,以探索全球人口的分布情况。
一 制作世界人口地图
1 下载世界人口数据和提取相关的数据
可以去(http://data.okfn.org/)下载population_data.json,来研究一下population_data.json,看看如何着手处理这个文件中的数据:
[
{
"Country Name": "Arab World",
"Country Code": "ARB",
"Year": "1960",
"Value": "96388069"
},
{
"Country Name": "Arab World",
"Country Code": "ARB",
"Year": "1961",
"Value": "98882541.4"
},
省略。。。。
}
这个文件实际上就是一个很长的Python列表,其中每个元素都是一个包含四个键的字典:国家名、国别码、年份以及表示人口数量的值。我们只关心每个国家2010年的人口数量,因此我们首先编写一个打印这些信息的程序:
import json
#将数据加载到一个列表中
filename= 'population_data.json'
with open(filename) as f :
pop_data = json.load(f)
for pop_dic in pop_data :
if pop_dic["Year"] == '2010' :
country_name= pop_dic['Country Name']
population = pop_dic['Value']
print(country_name + ":" + population)
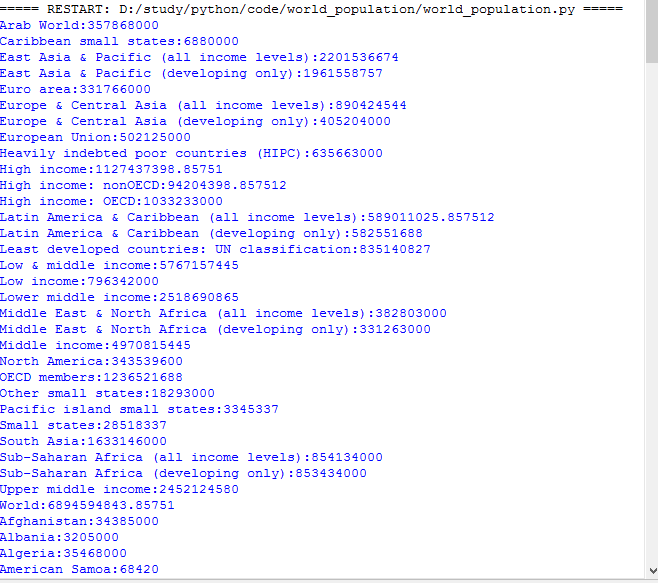
结果如下:
2 将字符串转换为数字值
population_data.json中的每个键和值都是字符串。为处理这些人口数据,我们需要将表示人口数量的字符串转换为数字值,为此我们使用函数int():
population = int(pop_dic['Value']) print(country_name + ":" + str(population))
然而,对于有些值,这种转换会导致错误,如下所示:
===== RESTART: D:/study/python/code/world_population/world_population.py ===== Arab World:357868000 Caribbean small states:6880000 East Asia & Pacific (all income levels):2201536674 East Asia & Pacific (developing only):1961558757 Euro area:331766000 Europe & Central Asia (all income levels):890424544 Europe & Central Asia (developing only):405204000 European Union:502125000 Heavily indebted poor countries (HIPC):635663000 Traceback (most recent call last): File "D:/study/python/code/world_population/world_population.py", line 12, in <module> population = int(pop_dic['Value']) ValueError: invalid literal for int() with base 10: '1127437398.85751' >>>
导致上述错误的原因是,Python不能直接将包含小数点的字符串'1127437398.85751'转换为整数(这个小数值可能是人口数据缺失时通过插值得到的)。为消除这种错误,我们先将字符串转换为浮点数,再将浮点数转换为整数:
population = int(float(pop_dict['Value']))
函数float()将字符串转换为小数,而函数int()丢弃小数部分,返回一个整数。每个字符串都成功地转换成了浮点数,再转换为整数。以数字格式存储人口数量值后,就可以使用它们来制作世界人口地图了。
三 获取两个字母的国别码
制作地图前,还需要解决数据存在的最后一个问题。Pygal中的地图制作工具要求数据为特定的格式:用国别码表示国家,以及用数字表示人口数量。处理地理政治数据时,经常需要用到几个标准化国别码集。population_data.json中包含的是三个字母的国别码,但Pygal使用两个字母的国别码。我们需要想办法根据国家名获取两个字母的国别码。Pygal使用的国别码存储在模块i18n(internationalization的缩写)中。字典COUNTRIES包含的键和值分别为两个字母的国别码和国家名。要查看这些国别码,可从模块i18n中导入这个字典,并打印其键和值:
from pygal.i18n import COUNTRIES
for country_code in sorted(COUNTRIES.keys()):
print(country_code, COUNTRIES[country_code])
报错:
======== RESTART: D:/study/python/code/world_population/countries.py ========
Traceback (most recent call last):
File "D:/study/python/code/world_population/countries.py", line 1, in <module>
from pygal.i18n import COUNTRIES
ModuleNotFoundError: No module named 'pygal.i18n'
>>>
原因和解决方案:
The i18n module was removed in pygal-2.0.0, however, it can now be found in the pygal_maps_world plugin. You can install that with pip install pygal_maps_world. Then you can access COUNTRIES as pygal.maps.world.COUNTRIES: from pygal.maps.world import COUNTRIES
按上面的操作:
from pygal.maps.world import COUNTRIES
for country_code in sorted(COUNTRIES.keys()):
print(country_code, COUNTRIES[country_code])
结果如下:
为获取国别码,我们将编写一个函数,它在COUNTRIES中查找并返回国别码。我们将这个函数放在一个名为country_codes的模块中,以便能够在可视化程序中导入它:
from pygal.maps.world import COUNTRIES
def get_country_code(country_name):
#根据指定的国家,返回Pygal使用的两个字母的国别码
for code,name in COUNTRIES.items():
if name == country_name :
return code
# 如果没有找到指定的国家,就返回None
return None
print(get_country_code('Andorra'))
print(get_country_code('United Arab Emirates'))
print(get_country_code('Afghanistan'))
结果如下:
======= RESTART: D:/study/python/code/world_population/contry_codes.py ======= ad ae af >>>
接下来,在world_population.py中导入get_country_code:
import json
from country_codes import get_country_code
#将数据加载到一个列表中
filename= 'population_data.json'
with open(filename) as f :
pop_data = json.load(f)
# 打印每个国家2010年的人口数量
for pop_dic in pop_data :
if pop_dic["Year"] == '2010' :
country_name= pop_dic['Country Name']
population = int(float(pop_dic['Value']))
code =get_country_code(country_name)
if code :
print(code + ":" + str(population))
else :
print("ERROR -" + country_name)
结果如下:
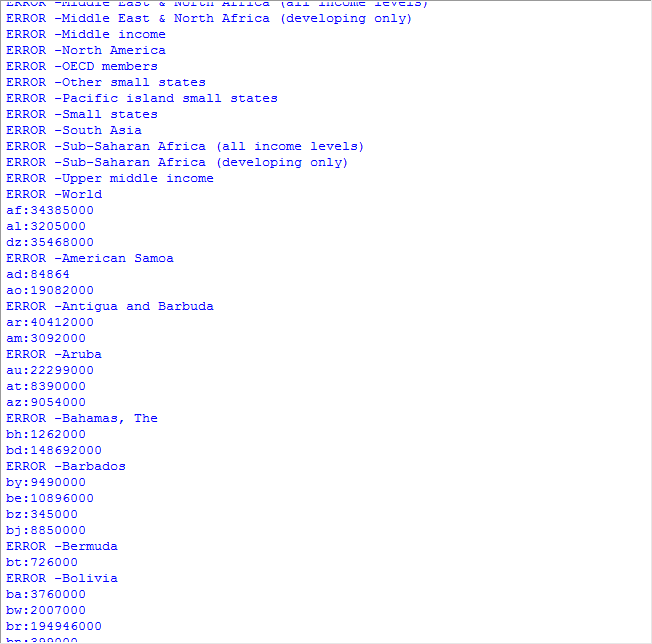
导致显示错误消息的原因有两个。首先,并非所有人口数量对应的都是国家,有些人口数量对应的是地区(阿拉伯世界)和经济类群(所有收入水平)。其次,有些统计数据使用了不同的完整国家名(如Yemen, Rep.,而不是Yemen)。当前,我们将忽略导致错误的数据,看看根据成功恢复了的数据制作出的地图是什么样的。
3 绘制世界地图
有了国别码后,制作世界地图易如反掌。Pygal提供了图表类型Worldmap,可帮助你制作呈现各国数据的世界地图。为演示如何使用Worldmap,我们来创建一个突出北美、中美和南美的简单地图:
import pygal
#此处书中的代码已过时,请用最新的。
wm = pygal.maps.world.World()
wm.title = 'North, Central, and South America'
wm.add('North America', ['ca', 'mx', 'us'])
wm.add('Central America', ['bz', 'cr', 'gt', 'hn', 'ni', 'pa', 'sv'])
wm.add('South America', ['ar', 'bo', 'br', 'cl', 'co', 'ec', 'gf',
'gy', 'pe', 'py', 'sr', 'uy', 've'])
wm.render_to_file('americas.svg')
(1)我们创建了一个Worldmap实例,并设置了该地图的的title属性
(2)了方法add(),它接受一个标签和一个列表,其中后者包含我们要突出的国家的国别码。每次调用add()都将为指定的国家选择一种新颜色,并在图表左边显示该颜色和指定的标签。我们要以同一种颜色显示整个北美地区,因此第一次调用add()时,在传递给它的列表中包含'ca'、'mx'和'us',以同时突出加拿大、墨西哥和美国。接下来,对中美和南美国家做同样的处理。
(3)方法render_to_file()创建一个包含该图表的.svg文件,你可以在浏览器中打开它。输出是一幅以不同颜色突出北美、中美和南美的地图,如下图:

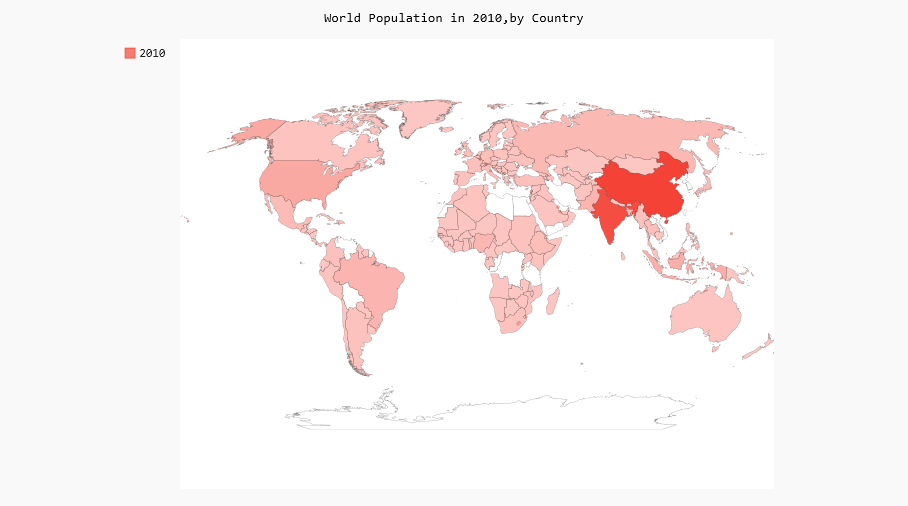
4 绘制完整的世界人口地图
要呈现其他国家的人口数量,需要将前面处理的数据转换为Pygal要求的字典格式:键为两个字母的国别码,值为人口数量。为此,在world_population.py中添加如下代码:
import json
from country_codes import get_country_code
import pygal
#将数据加载到一个列表中
filename= 'population_data.json'
with open(filename) as f :
pop_data = json.load(f)
cc_populations ={}
for pop_dict in pop_data :
if pop_dict['Year'] == '2010' :
country_name= pop_dict['Country Name']
population = int(float(pop_dict['Value']))
code =get_country_code(country_name)
if code :
cc_populations[code] = population
wm = pygal.maps.world.World()
wm.title="World Population in 2010,by Country"
wm.add('2010',cc_populations)
wm.render_to_file("world_population.svg")
如下图:
5根据人口数量将国家分组
印度和中国的人口比其他国家多得多,但在当前的地图中,它们的颜色与其他国家差别较小。中国和印度的人口都超过了10亿,接下来人口最多的国家是美国,但只有大约3亿。下面不将所有国家都作为一个编组,而是根据人口数量分成三组——少于1000万的、介于1000万和10亿之间的以及超过10亿的。
import json
from country_codes import get_country_code
import pygal
#将数据加载到一个列表中
filename= 'population_data.json'
with open(filename) as f :
pop_data = json.load(f)
cc_populations ={}
for pop_dict in pop_data :
if pop_dict['Year'] == '2010' :
country_name= pop_dict['Country Name']
population = int(float(pop_dict['Value']))
code =get_country_code(country_name)
if code :
cc_populations[code] = population
# 根据人口数量将所有的国家分成三组
cc_pops_1, cc_pops_2, cc_pops_3 = {}, {}, {}
for cc, pop in cc_populations.items():
if pop < 10000000:
cc_pops_1[cc] = pop
elif pop < 1000000000:
cc_pops_2[cc] = pop
else:
cc_pops_3[cc] = pop
# 看看每组分别包含多少个国家
print(len(cc_pops_1), len(cc_pops_2), len(cc_pops_3))
wm = pygal.maps.world.World()
wm.title="World Population in 2010,by Country"
#wm.add('2010',cc_populations)
wm.add('0-10m', cc_pops_1)
wm.add('10m-1bn', cc_pops_2)
wm.add('>1bn', cc_pops_3)
wm.render_to_file("world_population.svg")
结果如下:
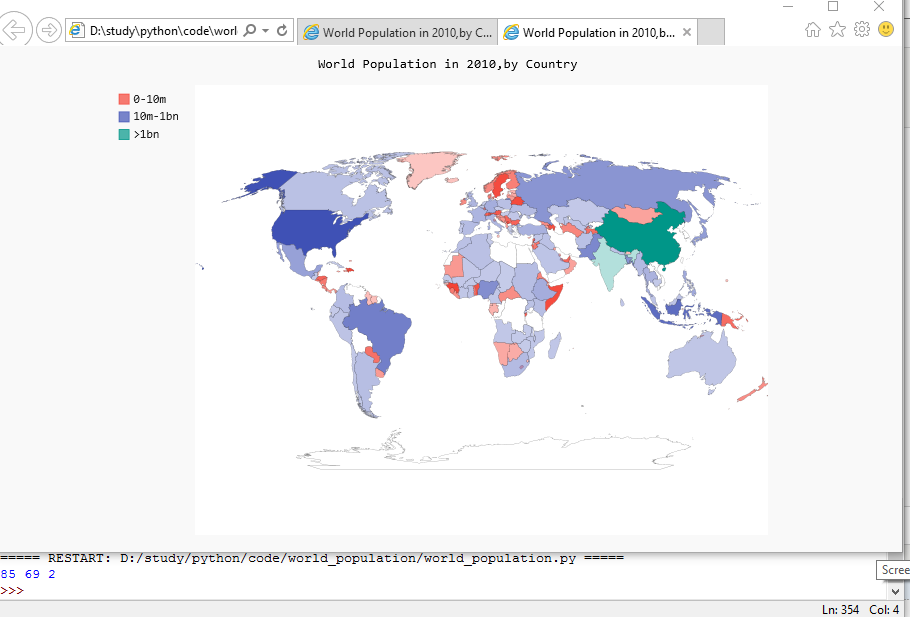
现在使用了三种不同的颜色,让我们能够看出人口数量上的差别。在每组中,各个国家都按人口从少到多着以从浅到深的颜色。
6 使用Pygal设置世界地图的样式
在这个地图中,根据人口将国家分组虽然很有效,但默认的颜色设置很难看。例如,在这里,Pygal选择了鲜艳的粉色和绿色基色。下面使用Pygal样式设置指令来调整颜色。我们也让Pygal使用一种基色,但将指定该基色,并让三个分组的颜色差别更大:
import json
from country_codes import get_country_code
import pygal
from pygal.style import RotateStyle
#将数据加载到一个列表中
filename= 'population_data.json'
with open(filename) as f :
pop_data = json.load(f)
cc_populations ={}
for pop_dict in pop_data :
if pop_dict['Year'] == '2010' :
country_name= pop_dict['Country Name']
population = int(float(pop_dict['Value']))
code =get_country_code(country_name)
if code :
cc_populations[code] = population
# 根据人口数量将所有的国家分成三组
cc_pops_1, cc_pops_2, cc_pops_3 = {}, {}, {}
for cc, pop in cc_populations.items():
if pop < 10000000:
cc_pops_1[cc] = pop
elif pop < 1000000000:
cc_pops_2[cc] = pop
else:
cc_pops_3[cc] = pop
# 看看每组分别包含多少个国家
print(len(cc_pops_1), len(cc_pops_2), len(cc_pops_3))
wm_style=RotateStyle('#336699')
wm = pygal.maps.world.World(style=wm_style)
wm.title="World Population in 2010,by Country"
#wm.add('2010',cc_populations)
wm.add('0-10m', cc_pops_1)
wm.add('10m-1bn', cc_pops_2)
wm.add('>1bn', cc_pops_3)
wm.render_to_file("world_population.svg")
Pygal样式存储在模块style中,我们从这个模块中导入了样式RotateStyle。创建这个类的实例时,需要提供一个实参——十六进制的RGB颜色;Pygal将根据指定的颜色为每组选择颜色。十六进制格式的RGB颜色是一个以井号(#)打头的字符串,后面跟着6个字符,其中前两个字符表示红色分量,接下来的两个表示绿色分量,最后两个表示蓝色分量。每个分量的取值范围为00(没有相应的颜色)~FF(包含最多的相应颜色)。如果你在线搜索hex color chooser(十六进制颜色选择器),可找到让你能够尝试选择不同的颜色并显示其RGB值的工具。这里使用的颜色值(#336699)混合了少量的红色(33)、多一些的绿色(66)和更多一些的蓝色(99),它为RotateStyle提供了一种淡蓝色基色。
效果如下图:

7 加亮颜色主题
Pygal通常默认使用较暗的颜色主题。为方便印刷,我使用LightColorizedStyle加亮了地图的颜色。这个类修改整个图表的主题,包括背景色、标签以及各个国家的颜色。要使用这个样式,先导入它:
from pygal.style import LightColorizedStyle, RotateStyle
再使用RotateStyle创建一种样式,并传入另一个实参base_style:
wm_style = RotateStyle('#336699', base_style=LightColorizedStyle)
最后的代码和效果图如下:
import json
from country_codes import get_country_code
import pygal
from pygal.style import RotateStyle,LightColorizedStyle
#将数据加载到一个列表中
filename= 'population_data.json'
with open(filename) as f :
pop_data = json.load(f)
cc_populations ={}
for pop_dict in pop_data :
if pop_dict['Year'] == '2010' :
country_name= pop_dict['Country Name']
population = int(float(pop_dict['Value']))
code =get_country_code(country_name)
if code :
cc_populations[code] = population
# 根据人口数量将所有的国家分成三组
cc_pops_1, cc_pops_2, cc_pops_3 = {}, {}, {}
for cc, pop in cc_populations.items():
if pop < 10000000:
cc_pops_1[cc] = pop
elif pop < 1000000000:
cc_pops_2[cc] = pop
else:
cc_pops_3[cc] = pop
# 看看每组分别包含多少个国家
print(len(cc_pops_1), len(cc_pops_2), len(cc_pops_3))
wm_style=RotateStyle('#336699',base_style=LightColorizedStyle)
wm = pygal.maps.world.World(style=wm_style)
wm.title="World Population in 2010,by Country"
#wm.add('2010',cc_populations)
wm.add('0-10m', cc_pops_1)
wm.add('10m-1bn', cc_pops_2)
wm.add('>1bn', cc_pops_3)
wm.render_to_file("world_population.svg")
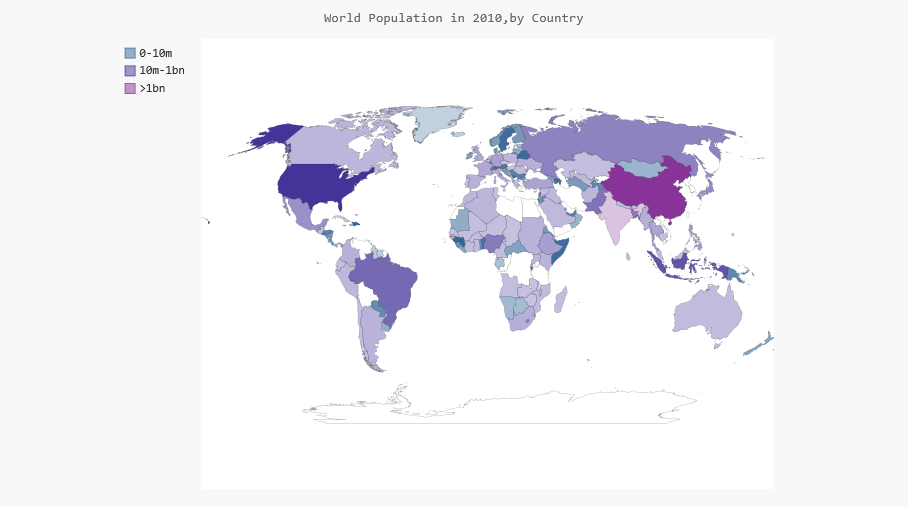
未完待续,今天是元旦节第二天,加油!
Python 项目实践二(下载数据)第四篇的更多相关文章
- Python 项目实践二(下载数据)第三篇
接着上节继续学习,在本章中,你将从网上下载数据,并对这些数据进行可视化.网上的数据多得难以置信,且大多未经过仔细检查.如果能够对这些数据进行分析,你就能发现别人没有发现的规律和关联.我们将访问并可视化 ...
- Python 项目实践二(生成数据)第二篇之随机漫步
接着上节继续学习,在本节中,我们将使用Python来生成随机漫步数据,再使用matplotlib以引人瞩目的方式将这些数据呈现出来.随机漫步是这样行走得到的路径:每次行走都完全是随机的,没有明确的方向 ...
- Python 项目实践二(生成数据)第二篇
接着上节继续学习,在本节中,我们将使用Python来生成随机漫步数据,再使用matplotlib以引人瞩目的方式将这些数据呈现出来.随机漫步是这样行走得到的路径:每次行走都完全是随机的,没有明确的方向 ...
- Python 项目实践二(生成数据)第一篇
上面那个小游戏教程写不下去了,以后再写吧,今天学点新东西,了解的越多,发现python越强大啊! 数据可视化指的是通过可视化表示来探索数据,它与数据挖掘紧密相关,而数据挖掘指的是使用代码来探索数据集的 ...
- Python 项目实践一(外星人入侵)第一篇
python断断续续的学了一段实践,基础课程终于看完了,现在跟着做三个小项目,第一个是外星人入侵的小游戏: 一 Pygame pygame 是一组功能强大而有趣的模块,可用于管理图形,动画乃至声音,让 ...
- Python 项目实践一(外星人入侵)第二篇
接着上次的继续学习. 一 创建一个设置类 每次给游戏添加新功能时,通常也将引入一些新设置.下面来编写一个名为settings的模块,其中包含一个名为Settings的类,用于将所有设置存储在一个地方, ...
- [转]ionic项目之上传下载数据
本文转自:http://blog.csdn.net/superjunjin/article/details/44158567 一,首先是上传数据 记得在angularjs的controller中注入$ ...
- windows使用python调用wget批处理下载数据
wget是linux/unix下通常使用的下载http/ftp的数据,使用非常方便,其实wget目前经过编译,也可在windows下使用.最近需要下载大量的遥感数据,使用了python写了批处理下载程 ...
- Python 项目实践三(Web应用程序)第四篇
接着上节继续学习,本章将建立用户账户 Web应用程序的核心是让任何用户都能够注册账户并能够使用它,不管用户身处何方.在本章中,你将创建一些表单,让用户能够添加主题和条目,以及编辑既有的条目.你还将学习 ...
随机推荐
- Flash真的老了,HTML5将取代其地位
简单讲一些网页开发的趋势吧! Flash老了 Flash是一个落后于时代的技术,靠对客户端的高资源占用率来获取传输过程的低带宽占用. Flash不再安全 Flash是一个落后于时代的技术,靠对客户端的 ...
- Git命令行对照表
git init # 初始化本地git仓库(创建新仓库) git config --global user.name "xxx" # 配置用户名 git config --glob ...
- openstack集群环境准备
#0.openstack集群环境准备 openstack pike 部署 目录汇总 http://www.cnblogs.com/elvi/p/7613861.html #openstack集群环境准 ...
- linux下php7安装memcached、redis扩展
linux下php7安装memcached.redis扩展 1.php7安装Memcached扩展 比如说我现在使用了最新的 Ubuntu 16.04,虽然内置了 PHP 7 源,但 memcache ...
- 怎么配置Jupyter Notebook默认启动目录?
前言 系统环境:win10 x64:跟环境也没啥关系,在LInux下也一样... 前段时间重换了系统后,发现Jupyter Notebook的默认启动目录不太对呀,所以,就翻到了以前的笔记,还是记在这 ...
- 智能合约语言 Solidity 教程系列3 - 函数类型
Solidity 教程系列第三篇 - Solidity 函数类型介绍. 写在前面 Solidity 是以太坊智能合约编程语言,阅读本文前,你应该对以太坊.智能合约有所了解,如果你还不了解,建议你先看以 ...
- 简陋的斗地主,js实现
最近闲了两天没事做,用js写了个斗地主,练习练习.代码和功能都很简陋,还有bug,咋只是聊聊自己的思路. 这里说说斗地主主要包含的功能:洗牌,发牌,玩家出牌.电脑出牌,出牌规则的验证,输赢啥的没有判断 ...
- DOM操作整理
DOM获取 1. 直接获取 document.getElementById("box_id") 通过ID获取 document.getElementsByName("my ...
- codevs1050
题目地址:http://codevs.cn/problem/1050/ 分析: 最開始想直接用状压做,发现怎么都想不出来.就和当年的多行多米诺骨牌(这道题至少最后还是把普通状压做法看懂了). 直到听到 ...
- iOS旋钮动画-CircleKnob
欢迎相同喜欢动效的project师/UI设计师/产品添加我们 iOS动效特攻队–>QQ群:547897182 iOS动效特攻队–>熊熊:648070256 前段时间和群里的一个设计师配合. ...