Java集合系列[4]----LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHashMap源码之前,读者有必要先去了解HashMap的源码,可以查看我上一篇文章的介绍《Java集合系列[3]----HashMap源码分析》。只要深入理解了HashMap的实现原理,回过头来再去看LinkedHashMap,HashSet和LinkedHashSet的源码那都是非常简单的。因此,读者们好好耐下性子来研究研究HashMap源码吧,这可是买一送三的好生意啊。在前面分析HashMap源码时,我采用以问题为导向对源码进行分析,这样使自己不会像无头苍蝇一样乱分析一通,读者也能够针对问题更加深入的理解。本篇我决定还是采用这样的方式对LinkedHashMap进行分析。
1. LinkedHashMap内部采用了什么样的结构?
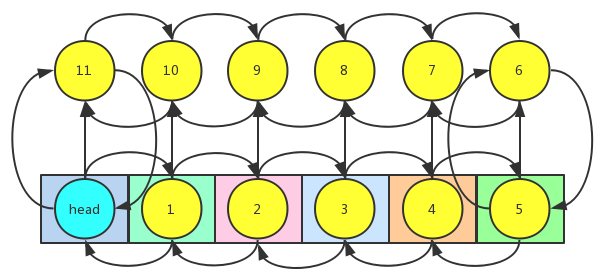
可以看到,由于LinkedHashMap是继承自HashMap的,所以LinkedHashMap内部也还是一个哈希表,只不过LinkedHashMap重新写了一个Entry,在原来HashMap的Entry上添加了两个成员变量,分别是前继结点引用和后继结点引用。这样就将所有的结点链接在了一起,构成了一个双向链表,在获取元素的时候就直接遍历这个双向链表就行了。我们看看LinkedHashMap实现的Entry是什么样子的。
private static class Entry<K,V> extends HashMap.Entry<K,V> {
//当前结点在双向链表中的前继结点的引用
Entry<K,V> before;
//当前结点在双向链表中的后继结点的引用
Entry<K,V> after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
//从双向链表中移除该结点
private void remove() {
before.after = after;
after.before = before;
}
//将当前结点插入到双向链表中一个已存在的结点前面
private void addBefore(Entry<K,V> existingEntry) {
//当前结点的下一个结点的引用指向给定结点
after = existingEntry;
//当前结点的上一个结点的引用指向给定结点的上一个结点
before = existingEntry.before;
//给定结点的上一个结点的下一个结点的引用指向当前结点
before.after = this;
//给定结点的上一个结点的引用指向当前结点
after.before = this;
}
//按访问顺序排序时, 记录每次获取的操作
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//如果是按访问顺序排序
if (lm.accessOrder) {
lm.modCount++;
//先将自己从双向链表中移除
remove();
//将自己放到双向链表尾部
addBefore(lm.header);
}
}
void recordRemoval(HashMap<K,V> m) {
remove();
}
}
2. LinkedHashMap是怎样实现按插入顺序排序的?
//父类put方法中会调用的该方法
void addEntry(int hash, K key, V value, int bucketIndex) {
//调用父类的addEntry方法
super.addEntry(hash, key, value, bucketIndex);
//下面操作是方便LRU缓存的实现, 如果缓存容量不足, 就移除最老的元素
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
} //父类的addEntry方法中会调用该方法
void createEntry(int hash, K key, V value, int bucketIndex) {
//先获取HashMap的Entry
HashMap.Entry<K,V> old = table[bucketIndex];
//包装成LinkedHashMap自身的Entry
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
//将当前结点插入到双向链表的尾部
e.addBefore(header);
size++;
}
LinkedHashMap重写了它的父类HashMap的addEntry和createEntry方法。当要插入一个键值对的时候,首先会调用它的父类HashMap的put方法。在put方法中会去检查一下哈希表中是不是存在了对应的key,如果存在了就直接替换它的value就行了,如果不存在就调用addEntry方法去新建一个Entry。注意,这时候就调用到了LinkedHashMap自己的addEntry方法。我们看到上面的代码,这个addEntry方法除了回调父类的addEntry方法之外还会调用removeEldestEntry去移除最老的元素,这步操作主要是为了实现LRU算法,下面会讲到。我们看到LinkedHashMap还重写了createEntry方法,当要新建一个Entry的时候最终会调用这个方法,createEntry方法在每次将Entry放入到哈希表之后,就会调用addBefore方法将当前结点插入到双向链表的尾部。这样双向链表就记录了每次插入的结点的顺序,获取元素的时候只要遍历这个双向链表就行了,下图演示了每次调用addBefore的操作。由于是双向链表,所以将当前结点插入到头结点之前其实就是将当前结点插入到双向链表的尾部。
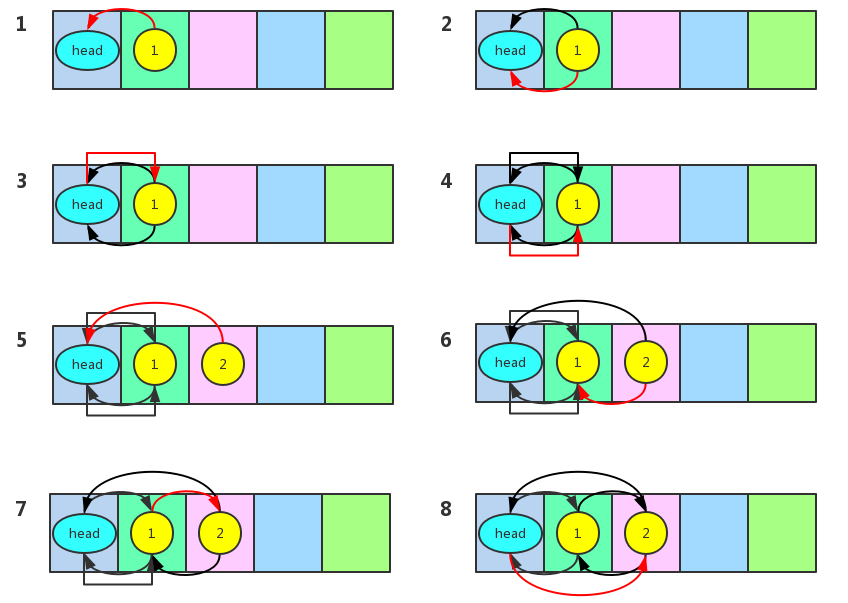
3. 怎样利用LinkedHashMap实现LRU缓存?
我们知道缓存的实现依赖于计算机的内存,而内存资源是相当有限的,不可能无限制的存放元素,所以我们需要在容量不够的时候适当的删除一些元素,那么到底删除哪个元素好呢?LRU算法的思想是,如果一个数据最近被访问过,那么将来被访问的几率也更高。所以我们可以删除那些不经常被访问的数据。接下来我们看看LinkedHashMap内部是怎样实现LRU机制的。
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
//双向链表头结点
private transient Entry<K,V> header;
//是否按访问顺序排序
private final boolean accessOrder;
...
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
//根据key获取value值
public V get(Object key) {
//调用父类方法获取key对应的Entry
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null) {
return null;
}
//如果是按访问顺序排序的话, 会将每次使用后的结点放到双向链表的尾部
e.recordAccess(this);
return e.value;
}
private static class Entry<K,V> extends HashMap.Entry<K,V> {
...
//将当前结点插入到双向链表中一个已存在的结点前面
private void addBefore(Entry<K,V> existingEntry) {
//当前结点的下一个结点的引用指向给定结点
after = existingEntry;
//当前结点的上一个结点的引用指向给定结点的上一个结点
before = existingEntry.before;
//给定结点的上一个结点的下一个结点的引用指向当前结点
before.after = this;
//给定结点的上一个结点的引用指向当前结点
after.before = this;
}
//按访问顺序排序时, 记录每次获取的操作
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//如果是按访问顺序排序
if (lm.accessOrder) {
lm.modCount++;
//先将自己从双向链表中移除
remove();
//将自己放到双向链表尾部
addBefore(lm.header);
}
}
...
}
//父类put方法中会调用的该方法
void addEntry(int hash, K key, V value, int bucketIndex) {
//调用父类的addEntry方法
super.addEntry(hash, key, value, bucketIndex);
//下面操作是方便LRU缓存的实现, 如果缓存容量不足, 就移除最老的元素
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
//是否删除最老的元素, 该方法设计成要被子类覆盖
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
}
为了更加直观,上面贴出的代码中我将一些无关的代码省略了,我们可以看到LinkedHashMap有一个成员变量accessOrder,该成员变量记录了是否需要按访问顺序排序,它提供了一个构造器可以自己指定accessOrder的值。每次调用get方法获取元素式都会调用e.recordAccess(this),该方法会将当前结点移到双向链表的尾部。现在我们知道了如果accessOrder为true那么每次get元素后都会把这个元素挪到双向链表的尾部。这一步的目的是区别出最常使用的元素和不常使用的元素,经常使用的元素放到尾部,不常使用的元素放到头部。我们再回到上面的代码中看到每次调用addEntry方法时都会判断是否需要删除最老的元素。判断的逻辑是removeEldestEntry实现的,该方法被设计成由子类进行覆盖并重写里面的逻辑。注意,由于最近被访问的结点都被挪动到双向链表的尾部,所以这里是从双向链表头部取出最老的结点进行删除。下面例子实现了一个简单的LRU缓存。
public class LRUMap<K, V> extends LinkedHashMap<K, V> {
private int capacity;
LRUMap(int capacity) {
//调用父类构造器, 设置为按访问顺序排序
super(capacity, 1f, true);
this.capacity = capacity;
}
@Override
public boolean removeEldestEntry(Map.Entry<K, V> eldest) {
//当键值对大于等于哈希表容量时
return this.size() >= capacity;
}
public static void main(String[] args) {
LRUMap<Integer, String> map = new LRUMap<Integer, String>(4);
map.put(1, "a");
map.put(2, "b");
map.put(3, "c");
System.out.println("原始集合:" + map);
String s = map.get(2);
System.out.println("获取元素:" + map);
map.put(4, "d");
System.out.println("插入之后:" + map);
}
}
结果如下:

注:以上全部分析基于JDK1.7,不同版本间会有差异,读者需要注意
Java集合系列[4]----LinkedHashMap源码分析的更多相关文章
- java集合系列之LinkedList源码分析
java集合系列之LinkedList源码分析 LinkedList数据结构简介 LinkedList底层是通过双端双向链表实现的,其基本数据结构如下,每一个节点类为Node对象,每个Node节点包含 ...
- java集合系列之ArrayList源码分析
java集合系列之ArrayList源码分析(基于jdk1.8) ArrayList简介 ArrayList时List接口的一个非常重要的实现子类,它的底层是通过动态数组实现的,因此它具备查询速度快, ...
- Java集合系列:-----------03ArrayList源码分析
上一章,我们学习了Collection的架构.这一章开始,我们对Collection的具体实现类进行讲解:首先,讲解List,而List中ArrayList又最为常用.因此,本章我们讲解ArrayLi ...
- Java集合系列[1]----ArrayList源码分析
本篇分析ArrayList的源码,在分析之前先跟大家谈一谈数组.数组可能是我们最早接触到的数据结构之一,它是在内存中划分出一块连续的地址空间用来进行元素的存储,由于它直接操作内存,所以数组的性能要比集 ...
- Java集合系列[3]----HashMap源码分析
前面我们已经分析了ArrayList和LinkedList这两个集合,我们知道ArrayList是基于数组实现的,LinkedList是基于链表实现的.它们各自有自己的优劣势,例如ArrayList在 ...
- Java集合系列[2]----LinkedList源码分析
上篇我们分析了ArrayList的底层实现,知道了ArrayList底层是基于数组实现的,因此具有查找修改快而插入删除慢的特点.本篇介绍的LinkedList是List接口的另一种实现,它的底层是基于 ...
- java多线程系列(九)---ArrayBlockingQueue源码分析
java多线程系列(九)---ArrayBlockingQueue源码分析 目录 认识cpu.核心与线程 java多线程系列(一)之java多线程技能 java多线程系列(二)之对象变量的并发访问 j ...
- Java并发系列[2]----AbstractQueuedSynchronizer源码分析之独占模式
在上一篇<Java并发系列[1]----AbstractQueuedSynchronizer源码分析之概要分析>中我们介绍了AbstractQueuedSynchronizer基本的一些概 ...
- Java并发系列[3]----AbstractQueuedSynchronizer源码分析之共享模式
通过上一篇的分析,我们知道了独占模式获取锁有三种方式,分别是不响应线程中断获取,响应线程中断获取,设置超时时间获取.在共享模式下获取锁的方式也是这三种,而且基本上都是大同小异,我们搞清楚了一种就能很快 ...
随机推荐
- [Upper case conversion ] 每个单词的首小写字母转换为对应的大写字母
Given a string , write a program to title case every first letter of words in string. Input:The firs ...
- NOI2009 植物大战僵尸
啊一道好题感觉写得挺爽的啊这题这种有一点懵逼然后学了一点东西之后很明朗的感觉真是好!预处理参考 :http://www.cppblog.com/MatoNo1/archive/2014/11/01/1 ...
- bzoj 4310: 跳蚤
Description 很久很久以前,森林里住着一群跳蚤.一天,跳蚤国王得到了一个神秘的字符串,它想进行研究. 首先,他会把串分成不超过 k 个子串,然后对于每个子串 S,他会从S的所有子串中选择字典 ...
- OpenGL ES学习001---绘制三角形
PS:OpenGL ES是什么? OpenGL ES (OpenGL for Embedded Systems) 是 OpenGL三维图形 API 的子集,针对手机.PDA和游戏主机等嵌入式设备而设计 ...
- 深入学习rollup来进行打包
深入学习rollup来进行打包 阅读目录 一:什么是Rollup? 二:如何使用Rollup来处理并打包JS文件? 三:设置Babel来使旧浏览器也支持ES6的代码 四:添加一个debug包来记录日志 ...
- requireJS(版本是2.1.15)学习教程(一)
一:为什么要使用requireJS? 很久之前,我们所有的JS文件写到一个js文件里面去进行加载,但是当业务越来越复杂的时候,需要分成多个JS文件进行加载,比如在页面中head内分别引入a.js,b. ...
- vmware workstation14永久激活密钥分享
vmware workstation14永久激活密钥分享 VMware Workstation是一款功能强大的桌面虚拟计算机软件,简单来说就是最强的中文虚拟机了,可以在桌面上运行不同的操作系统,下面就 ...
- 房上的猫:了解java与学习java前的准备
一.java 概述: 1.通常指完成某些事情的一种既定方式和过程 2.程序可以看做对一系列动作执行过程的描述 3.计算机按照某种顺序完成一系列指令的集合称为程序 4.计算机仅识别二进制低级语言 ...
- 初识BASH SHELL
什么是Shell shell翻译成中文就是"壳"的意思.简单来说就是shell是计算机用户与操作系统内核进行"沟通"的一种工具.Windows系统中有power ...
- 如何使用MOQ进行单元测试
使用MOQ来伪装和隔离被依赖对象,从而提高被测对象的测试效果. 安装 通过http://code.google.com/p/moq可以下载MOQ的最新版本.在SSL项目中,我们使用的是MOQ 3.1. ...