OMP算法代码学习
0、符号说明如下
1、OMP重构算法流程



2、正交匹配追踪(OMP)MATLAB代码(CS_OMP.m)
function[theta]=CS_OMP(y,A,t)
%CS_OMP Summary of this function goes here
%Version: 1.0 written by jbb0523 @2015-04-18
% Detailed explanation goes here
% y = Phi * x
% x = Psi * theta
% y = Phi*Psi * theta
% 令 A = Phi*Psi, 则y=A*theta
% 现在已知y和A,求theta
[y_rows,y_columns]=size(y);
ify_rows<y_columns
y=y';%y should be a column vector
end
[M,N]=size(A); %传感矩阵A为M*N矩阵
theta=zeros(N,1); %用来存储恢复的theta(列向量)
At=zeros(M,t); %用来迭代过程中存储A被选择的列
Pos_theta=zeros(1,t); %用来迭代过程中存储A被选择的列序号
r_n=y; %初始化残差(residual)为y
forii=1:t %迭代t次,t为输入参数
product=A'*r_n; %传感矩阵A各列与残差的内积
[val,pos]=max(abs(product)); %找到最大内积绝对值,即与残差最相关的列
At(:,ii)=A(:,pos); %存储这一列
Pos_theta(ii)=pos; %存储这一列的序号
A(:,pos)=zeros(M,1); %清零A的这一列,其实此行可以不要,因为它与残差正交
%y=At(:,1:ii)*theta,以下求theta的最小二乘解(Least Square)
theta_ls=(At(:,1:ii)'*At(:,1:ii))^(-1)*At(:,1:ii)'*y; %最小二乘解
%At(:,1:ii)*theta_ls是y在At(:,1:ii)列空间上的正交投影
r_n=y-At(:,1:ii)*theta_ls; %更新残差
end
theta(Pos_theta)=theta_ls; %恢复出的theta
end
3、OMP单次重构测试代码(CS_Reconstuction_Test.m)
%压缩感知重构算法测试
clear all;close all;clc;
M=64;%观测值个数
N=256;%信号x的长度
K=10;%信号x的稀疏度
Index_K=randperm(N);
x=zeros(N,1);
x(Index_K(1:K))=5*randn(K,1);%x为K稀疏的,且位置是随机的
Psi=eye(N);%x本身是稀疏的,定义稀疏矩阵为单位阵x=Psi*theta
Phi=randn(M,N);%测量矩阵为高斯矩阵
A=Phi*Psi;%传感矩阵
y=Phi*x;%得到观测向量y
%% 恢复重构信号x
tic
theta=CS_OMP(y,A,K);
x_r=Psi*theta;% x=Psi * theta
toc
%% 绘图
figure;
plot(x_r,'k.-');%绘出x的恢复信号
hold on;
plot(x,'r');%绘出原信号x
hold off;
legend('Recovery','Original')
fprintf('\n恢复残差:');
norm(x_r-x)%恢复残差
1)图:
Elapsed time is 0.849710 seconds.
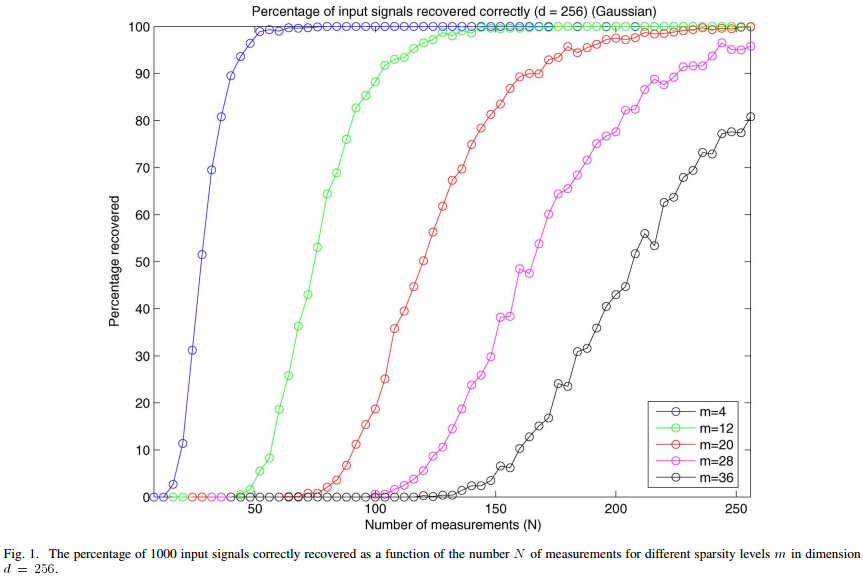
4、测量数M与重构成功概率关系曲线绘制例程代码
%压缩感知重构算法测试CS_Reconstuction_MtoPercentage.m
% 绘制参考文献中的Fig.1
% 参考文献:Joel A. Tropp and Anna C. Gilbert
% Signal Recovery From Random Measurements Via Orthogonal Matching
% Pursuit,IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 53, NO. 12,
% DECEMBER 2007.
% Elapsed time is 1171.606254 seconds.(@20150418night)
clear all;close all;clc;
%% 参数配置初始化
CNT=1000;%对于每组(K,M,N),重复迭代次数
N=256;%信号x的长度
Psi=eye(N);%x本身是稀疏的,定义稀疏矩阵为单位阵x=Psi*theta
K_set=[4,12,20,28,36];%信号x的稀疏度集合
Percentage=zeros(length(K_set),N);%存储恢复成功概率
%% 主循环,遍历每组(K,M,N)
tic
forkk=1:5
K=K_set(kk);%本次稀疏度
M_set=K:5:N;%M没必要全部遍历,每隔5测试一个就可以了
PercentageK=zeros(1,length(M_set));%存储此稀疏度K下不同M的恢复成功概率
formm=1:length(M_set)
M=M_set(mm);%本次观测值个数
P=0;
forcnt=1:CNT%每个观测值个数均运行CNT次
Index_K=randperm(N);
x=zeros(N,1);
x(Index_K(1:K))=5*randn(K,1);%x为K稀疏的,且位置是随机的
Phi=randn(M,N);%测量矩阵为高斯矩阵
A=Phi*Psi;%传感矩阵
y=Phi*x;%得到观测向量y
theta=CS_OMP(y,A,K);%恢复重构信号theta
x_r=Psi*theta;% x=Psi * theta
ifnorm(x_r-x)<1e-6%如果残差小于1e-6则认为恢复成功
P=P+1;
end
end
PercentageK(mm)=P/CNT*100;%计算恢复概率
end
Percentage(kk,1:length(M_set))=PercentageK;
end
toc
save MtoPercentage1000%运行一次不容易,把变量全部存储下来
%% 绘图
S=['-ks';'-ko';'-kd';'-kv';'-k*'];
figure;
forkk=1:length(K_set)
K=K_set(kk);
M_set=K:5:N;
L_Mset=length(M_set);
plot(M_set,Percentage(kk,1:L_Mset),S(kk,:));%绘出x的恢复信号
hold on;
end
hold off;
xlim([0256]);
legend('K=4','K=12','K=20','K=28','K=36');
xlabel('Number of measurements(M)');
ylabel('Percentage recovered');
title('Percentage of input signals recovered correctly(N=256)(Gaussian)');
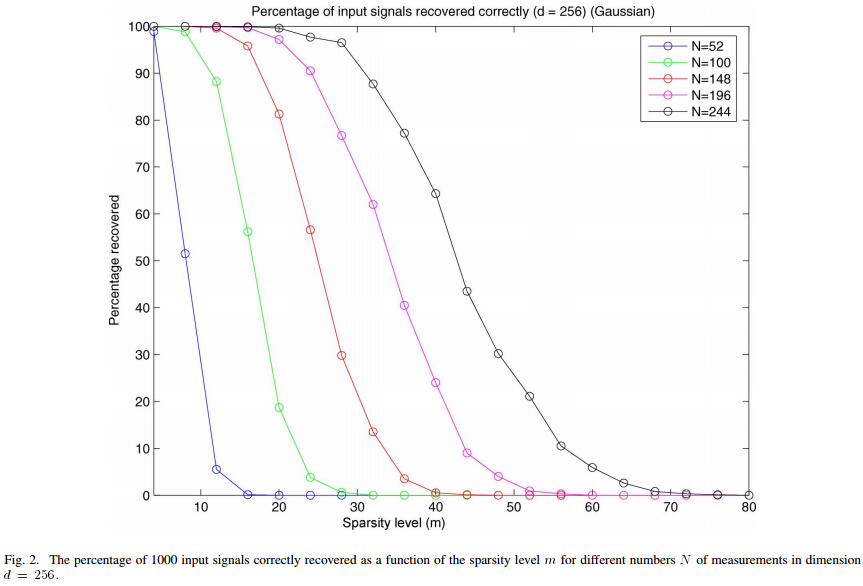
5、信号稀疏度K与重构成功概率关系曲线绘制例程代码
%压缩感知重构算法测试CS_Reconstuction_KtoPercentage.m
% 绘制参考文献中的Fig.2
% 参考文献:Joel A. Tropp and Anna C. Gilbert
% Signal Recovery From Random Measurements Via Orthogonal Matching
% Pursuit,IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 53, NO. 12,
% DECEMBER 2007.
% Elapsed time is 1448.966882 seconds.(@20150418night)
clear all;close all;clc;
%% 参数配置初始化
CNT=1000;%对于每组(K,M,N),重复迭代次数
N=256;%信号x的长度
Psi=eye(N);%x本身是稀疏的,定义稀疏矩阵为单位阵x=Psi*theta
M_set=[52,100,148,196,244];%测量值集合
Percentage=zeros(length(M_set),N);%存储恢复成功概率
%% 主循环,遍历每组(K,M,N)
tic
formm=1:length(M_set)
M=M_set(mm);%本次测量值个数
K_set=1:5:ceil(M/2);%信号x的稀疏度K没必要全部遍历,每隔5测试一个就可以了
PercentageM=zeros(1,length(K_set));%存储此测量值M下不同K的恢复成功概率
forkk=1:length(K_set)
K=K_set(kk);%本次信号x的稀疏度K
P=0;
forcnt=1:CNT%每个观测值个数均运行CNT次
Index_K=randperm(N);
x=zeros(N,1);
x(Index_K(1:K))=5*randn(K,1);%x为K稀疏的,且位置是随机的
Phi=randn(M,N);%测量矩阵为高斯矩阵
A=Phi*Psi;%传感矩阵
y=Phi*x;%得到观测向量y
theta=CS_OMP(y,A,K);%恢复重构信号theta
x_r=Psi*theta;% x=Psi * theta
ifnorm(x_r-x)<1e-6%如果残差小于1e-6则认为恢复成功
P=P+1;
end
end
PercentageM(kk)=P/CNT*100;%计算恢复概率
end
Percentage(mm,1:length(K_set))=PercentageM;
end
toc
save KtoPercentage1000test%运行一次不容易,把变量全部存储下来
%% 绘图
S=['-ks';'-ko';'-kd';'-kv';'-k*'];
figure;
formm=1:length(M_set)
M=M_set(mm);
K_set=1:5:ceil(M/2);
L_Kset=length(K_set);
plot(K_set,Percentage(mm,1:L_Kset),S(mm,:));%绘出x的恢复信号
hold on;
end
hold off;
xlim([0125]);
legend('M=52','M=100','M=148','M=196','M=244');
xlabel('Sparsity level(K)');
ylabel('Percentage recovered');
title('Percentage of input signals recovered correctly(N=256)(Gaussian)');
OMP算法代码学习的更多相关文章
- 【中国象棋人机对战】引入了AI算法,学习低代码和高代码如何混编并互相调用
以低代码和高代码(原生JS代码)混编的方式引入了AI算法,学习如何使用表达式调用原生代码的.整个过程在众触低代码应用平台进行,适合高阶学员. AI智能级别演示 AI算法分三个等级,体现出来的智能水平不 ...
- 压缩感知重构算法之OMP算法python实现
压缩感知重构算法之OMP算法python实现 压缩感知重构算法之CoSaMP算法python实现 压缩感知重构算法之SP算法python实现 压缩感知重构算法之IHT算法python实现 压缩感知重构 ...
- 推荐一个算法编程学习中文社区-51NOD【算法分级,支持多语言,可在线编译】
最近偶尔发现一个算法编程学习的论坛,刚开始有点好奇,也只是注册了一下.最近有时间好好研究了一下,的确非常赞,所以推荐给大家.功能和介绍看下面介绍吧.首页的标题很给劲,很纯粹的Coding社区....虽 ...
- 关于统计变换(CT/MCT/RMCT)算法的学习和实现
原文地址http://blog.sina.com.cn/s/blog_684c8d630100turx.html 刚开会每周的例会,最讨厌开会了,不过为了能顺利毕业,只能忍了.闲话不多说了,下面把上周 ...
- MP算法和OMP算法及其思想
主要介绍MP(Matching Pursuits)算法和OMP(Orthogonal Matching Pursuit)算法[1],这两个算法尽管在90年代初就提出来了,但作为经典的算法,国内文献(可 ...
- 算法导论学习---红黑树具体解释之插入(C语言实现)
前面我们学习二叉搜索树的时候发如今一些情况下其高度不是非常均匀,甚至有时候会退化成一条长链,所以我们引用一些"平衡"的二叉搜索树.红黑树就是一种"平衡"的二叉搜 ...
- 稀疏分解中的MP与OMP算法
MP:matching pursuit匹配追踪 OMP:正交匹配追踪 主要介绍MP与OMP算法的思想与流程,解释为什么需要引入正交? !!今天发现一个重大问题,是在读了博主的正交匹配追踪(OMP)在稀 ...
- MP和OMP算法
转载:有点无耻哈,全部复制别人的.写的不错 作者:scucj 文章链接:MP算法和OMP算法及其思想 主要介绍MP(Matching Pursuits)算法和OMP(Orthogonal Matchi ...
- 毕业设计预习:SM3密码杂凑算法基础学习
SM3密码杂凑算法基础学习 术语与定义 1 比特串bit string 由0和1组成的二进制数字序列. 2 大端big-endian 数据在内存中的一种表示格式,规定左边为高有效位,右边为低有效位.数 ...
随机推荐
- 201521123086《JAVA程序设计》第二周学习总结
一.本章学习总结 学会在Java程序中使用函数,使程序层次更清晰 使用StringBuilder编写代码,减少内存空间的占用 使用BigDecimal精确计算浮点数 使用枚举类型编写函数,掌握返回值使 ...
- 201521123095 《Java程序设计》第1周学习总结
1. 本周学习总结 开始了对JAVA的初步了解和学习,了解了如何编写简单的JAVA程序. 了解了Java的诞生及发展以及如何运用JVN JRE JDK JVM让JAVA可以 ...
- 201521123007《Java程序设计》第13周学习总结
1. 本周学习总结 以你喜欢的方式(思维导图.OneNote或其他)归纳总结多网络相关内容. 2. 书面作业 1. 网络基础 1.1 比较ping www.baidu.com与ping cec.jmu ...
- 201521123057 《Java程序设计》第9周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常相关内容. 2. 书面作业 常用异常 1.题目5-1 1.1 截图你的提交结果(出现学号) 答: 1.2 自己以前编写的代码中经 ...
- 201521123070 《JAVA程序设计》第14周学习总结
1. 本章学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多数据库相关内容. 2. 书面作业 Q1. MySQL数据库基本操作 建立数据库,将自己的姓名.学号作为一条记录插入.(截图,需出现 ...
- Java课程设计——学生基本信息管理
1.团队名称.团队成员介绍 团队名称:学生基本信息管理设计小组 团队成员:花雨芸(组长)--负责管理界面的编写 丁蓉(组员)--负责登陆的设计编写 2.项目git地址 https://git.osch ...
- 多线程:多线程设计模式(三):Master-Worker模式
Master-Worker模式是常用的并行模式之一,它的核心思想是,系统有两个进程协作工作:Master进程,负责接收和分配任务:Worker进程,负责处理子任务.当Worker进程将子任务处理完成后 ...
- C# 各种常用集合类型的线程安全版本
在C#里面我们常用各种集合,数组,List,Dictionary,Stack等,然而这些集合都是非线程安全的,当多线程同时读写这些集合的时候,有可能造成里面的数据混乱,为此微软从Net4.0开始专门提 ...
- 自学Unity3D 之 贪吃蛇 添加摄像机跟随
在Unity的世界中, 物体的位置都是由向量构成的. 今天所需要做的就是让摄像机保持跟蛇头的相对距离. 首先 设蛇头的位置在A 点 , 摄像机的位置在B 点 则 我们可以知道 他们的offse ...
- Sql Server——运用代码创建数据库及约束
在没有学习运用代码创建数据库.表和约束之前,我们只能用鼠标点击操作,这样看起来就不那么直观(高大上)了. 在写代码前要知道在哪里写和怎么运行: 点击新建查询,然后中间的白色空白地方就是写代码的地方了. ...