使用numpy实现批量梯度下降的感知机模型
生成多维高斯分布随机样本
生成多维高斯分布所需要的均值向量和方差矩阵
这里使用numpy中的多变量正太分布随机样本生成函数,按照要求设置均值向量和协方差矩阵。以下设置两个辅助函数,用于指定随机变量维度,生成相应的均值向量和协方差矩阵。
import numpy as np
from numpy.random import multivariate_normal
from math import sqrt
均值向量生成函数
输入:
n:指定随机样本的维度
输出:
m1,m2:正类样本和负类样本的均值向量
def generate_mean_vector(n):
m1=1/np.sqrt(np.arange(1,n+1))
m2=-1/np.sqrt(np.arange(1,n+1))
return m1,m2
协方差矩阵生成函数
输入:
n:指定随机样本的维度
输出:
cov:协方差矩阵,特殊化为对角阵
def generate_cov_matrix(n):
cov=np.eye(n)
return cov/n
测试协方差矩阵生成函数
cov=generate_cov_matrix(3)
print(cov)
print(cov.shape)
[[ 0.33333333 0. 0. ]
[ 0. 0.33333333 0. ]
[ 0. 0. 0.33333333]]
(3, 3)
测试正负样本的均值矩阵生成函数
mean1,mean2=generate_mean_vector(3)
print(mean1)
print(mean2)
len(mean1)
[ 1. 0.70710678 0.57735027]
[-1. -0.70710678 -0.57735027]
3
生成多维高斯分布的数据点
这里之间调用numpy中的函数
def generate_data(m1,m2,n):
mean1,mean2=generate_mean_vector(n)
cov=generate_cov_matrix(n)
dataSet1=multivariate_normal(mean1,cov,m1)
dataSet2=multivariate_normal(mean2,cov,m2)
return dataSet1,dataSet2
测试数据点生成函数
generate_data(5,5,2)
(array([[ 1.22594293, 0.63712588],
[ 2.5778577 , 1.01123791],
[ 1.16177917, 0.26111813],
[ 0.27808353, 3.47596707],
[ 1.07724333, 1.72858977]]), array([[-1.62291142, -1.19754211],
[-1.0161682 , 0.9159203 ],
[-0.98557188, -2.15175781],
[-0.62078416, -1.11943163],
[-1.9053243 , -1.36074614]]))
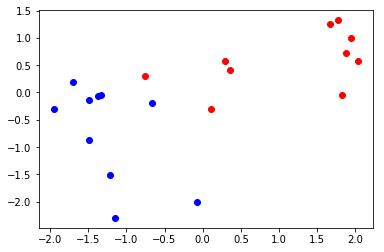
二维数据分布的可视化
from matplotlib import pyplot
class1,class2=generate_data(10,10,2)
class1=np.transpose(class1)
class2=np.transpose(class2)
pyplot.plot(class1[0],class1[1],'ro')
pyplot.plot(class2[0],class2[1],'bo')
pyplot.show()
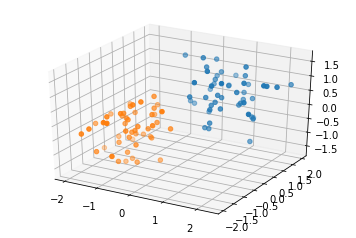
三维数据分布的可视化
#import matplotlib as mpl
#mpl.use('Agg')
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
class0,class1=generate_data(50,50,3)
class0=np.transpose(class0)
class1=np.transpose(class1)
fig=plt.figure()
ax=fig.add_subplot(111,projection='3d')
ax.scatter(class0[0],class0[1],class0[2],'ro')
ax.scatter(class1[0],class1[1],class1[2],'ro')
#fig.show()
pyplot.show()
感知机模型类
此模型的接口尽量与sklearn的模型接口保持一致
属性:
lr:learning rate,学习率
dim:样本空间的维度
weight:感知机模型的权重向量,包括偏置(在向量的最后一位)
方法:
init
输入:
lr:感知机模型的学习率
fit
输入:
X_train:训练样本的属性
y_train:训练样本的类别
epochs:算法迭代的最多次数
输出:模型的权重参数
predict
输入:
X:需要预测类别的样本集合
data_extend:布尔型变量,指示输入矩阵X是否经过了扩展预处理
输出:
result:预测结果向量
evaluate
输入:
X_test:测试集的样本属性
y_test:测试集的样本类别
data_extend:测试机样本矩阵是否经过了拓展
输出:
result:一个布尔向量,指示预测是否正确
get_weight
输出:
weight:模型的权重
class Perceptron():
def __init__(self,lr=0.01):
self.lr=lr
def fit(self,X_train,y_train,epochs=10):
#获取样本空间的维度
self.dim=X_train.shape[1]
#初始化权重为零,将最后一个权重作为偏置
self.weight=np.zeros((1,self.dim+1))
#拓展样本的维度,将偏置作为权重统一处理
X_train=np.hstack((X_train,np.ones((X_train.shape[0],1))))
epoch=0
while epoch < epochs:
epoch+=1
isCorrect=self.evaluate(X_train,y_train,data_extend=True)
#完全分类正确则停止迭代
if np.sum(isCorrect)==isCorrect.shape[0]:
break
X_error=X_train[np.logical_not(isCorrect)]
y_error=y_train[np.logical_not(isCorrect)]
self.weight=self.weight+self.lr*np.dot(y_error,X_error)
#返回预测结果向量
def predict(self,X,data_extend=False):
if data_extend==False:
X=np.hstack((X,np.ones((X.shape[0],1))))
p=np.dot(X,np.transpose(self.weight))
#注意:在这里p是二维数组,要将其转化为一维的
p=p.ravel()
p[p>0]=1;p[p<=0]=-1
return p
#返回布尔向量,如果预测为真则返回一,否则返回零
def evaluate(self,X_test,y_test,data_extend=False):
y_pred=self.predict(X_test,data_extend)
#注意这里是对应位置相乘(只有相乘的两个向量都为一维数组时才成立)
result=y_pred*y_test
return result==1
#返回模型参数,最后一个为偏置
def getweight(self):
return self.weight
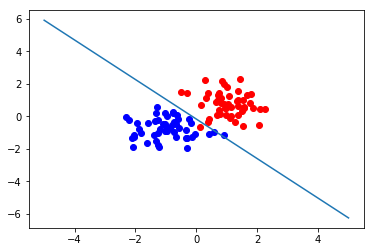
二维样本分类测试与可视化
def test_2d(m1=5,m2=5,epochs=10,lr=0.01):
X1,X2=generate_data(m1,m2,2)
X=np.vstack((X1,X2))
y=np.concatenate(([1]*m1,[-1]*m2))
model=Perceptron(lr)
model.fit(X,y,epochs)
np.transpose(np.matrix([1,2,3]))*3
c1=np.transpose(X1)
c2=np.transpose(X2)
pyplot.plot(c1[0],c1[1],'ro')
pyplot.plot(c2[0],c2[1],'bo')
w=model.getweight()
pyplot.plot([-5,5],[-1*w[0,2]/w[0,1]-w[0,0]/w[0,1]*-5,-1*w[0,2]/w[0,1]-w[0,0]/w[0,1]*5])
pyplot.show()
test_2d(50,50,1000,lr=0.01)

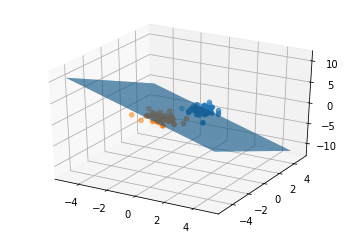
三维样本分类测试与可视化
def test_3d(m1=5,m2=5,epochs=10,lr=0.01):
X1,X2=generate_data(m1,m2,3)
X=np.vstack((X1,X2))
y=np.concatenate(([1]*m1,[-1]*m2))
model=Perceptron(lr)
model.fit(X,y,epochs)
#from matplotlib import pyplot
c0=np.transpose(X1)
c1=np.transpose(X2)
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
fig3=plt.figure()
ax=fig3.add_subplot(111,projection='3d')
ax.scatter(c0[0],c0[1],c0[2],'ro')
ax.scatter(c1[0],c1[1],c1[2],'ro')
w=model.getweight()
X=np.arange(-5,5,0.05);Y=np.arange(-5,5,0.05)
X,Y=np.meshgrid(X,Y)
Z=(w[0,0]*X+w[0,1]*Y+w[0,3])/(-1*w[0,2])
ax.plot_surface(X,Y,Z,rstride=1,cstride=1)
ax.set_facecolor('white')
ax.set_alpha(0.01)
#fig3.show()
pyplot.show()
test_3d(50,50,100)
使用numpy实现批量梯度下降的感知机模型的更多相关文章
- 【Python】机器学习之单变量线性回归 利用批量梯度下降找到合适的参数值
[Python]机器学习之单变量线性回归 利用批量梯度下降找到合适的参数值 本题目来自吴恩达机器学习视频. 题目: 你是一个餐厅的老板,你想在其他城市开分店,所以你得到了一些数据(数据在本文最下方), ...
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比[转]
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- 【转】 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- batch gradient descent(批量梯度下降) 和 stochastic gradient descent(随机梯度下降)
批量梯度下降是一种对参数的update进行累积,然后批量更新的一种方式.用于在已知整个训练集时的一种训练方式,但对于大规模数据并不合适. 随机梯度下降是一种对参数随着样本训练,一个一个的及时updat ...
- 批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降(MBGD)的理解
梯度下降法作为机器学习中较常使用的优化算法,其有着三种不同的形式:批量梯度下降(Batch Gradient Descent).随机梯度下降(Stochastic Gradient Descent ...
- online learning,batch learning&批量梯度下降,随机梯度下降
以上几个概念之前没有完全弄清其含义及区别,容易混淆概念,在本文浅析一下: 一.online learning vs batch learning online learning强调的是学习是实时的,流 ...
- NN优化方法对照:梯度下降、随机梯度下降和批量梯度下降
1.前言 这几种方法呢都是在求最优解中常常出现的方法,主要是应用迭代的思想来逼近.在梯度下降算法中.都是环绕下面这个式子展开: 当中在上面的式子中hθ(x)代表.输入为x的时候的其当时θ參数下的输出值 ...
- 机器学习-随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- Tensorflow细节-P84-梯度下降与批量梯度下降
1.批量梯度下降 批量梯度下降法是最原始的形式,它是指在每一次迭代时使用所有样本来进行梯度的更新.从数学上理解如下: 对应的目标函数(代价函数)即为: (1)对目标函数求偏导: (2)每次迭代对参数进 ...
随机推荐
- 移动端效果之IndexList
写在前面 接着前面的移动端效果讲,这次讲解的的是IndexList的实现原理.效果如下: 代码请看这里:github 移动端效果之swiper 移动端效果之picker 移动端效果之cellSwipe ...
- linux系统下Python虚拟环境的安装和使用
前言:进行python项目开发的时候,由于不同的项目需要使用不同的资源包和相关的配置,因此创建多个python虚拟环境,在虚拟环境下开发就显得很有必要. 安装虚拟环境 步骤: 打开Linux终端(快捷 ...
- 关于Page_Load事件发生情况
Page_Load事件会在第一次加载页面时发生和将该页面回发到服务器时发生 第一种情况Page.IsPostBack返回false,第二种返回True. 若在Page_Load事件中有一些对控件的操作 ...
- [Java第一个游戏]JFrame文本框下贪吃蛇
刚刚接触java的文本框绘图的知识点,然后就可以按照老师的提醒做一些简单的游戏,对JFrame加深一下,下面就贪吃蛇给出一些源代码,其实正真的实现的代码并不多,只是稍微处理一下就可以明白,下面代码均有 ...
- java中的static关键字详解
static对于我们这些初学者在编写代码和阅读代码是一个难以理解的关键字,也是大量公司面试题最喜欢考的之一.下面我就来就先讲述一下static关键字的用法和我们初学者容易误解的地方. static关键 ...
- Akka(33): Http:Marshalling,to Json
Akka-http是一项系统集成工具.这主要依赖系统之间的数据交换功能.因为程序内数据表达形式与网上传输的数据格式是不相同的,所以需要对程序高级结构化的数据进行转换(marshalling or se ...
- 阿里巴巴Java开发手册思维导图
趁着有时间把阿里巴巴Java开发手册又看了一遍了,很多时候觉得看完之后,发现自己好像一点都不记得了里面的内容了.只能把大概内容画一遍在脑子里形成一张图方便记忆,这样就更能够记得自己的看完的内容了.其中 ...
- 一起来学linux:NFS服务器搭建
p { margin-bottom: 0.25cm; line-height: 120% } a:link { } nfs是network file system的缩写,作用在于让不同的网络,不同的机 ...
- Input文本框属性及js
<input id="txt_uname" maxlength="16" onblur="validata()" onkeyup=&q ...
- Caffe Ubuntu16.04 GPU安装