python机器学习实战(一)
python机器学习实战(一)
版权声明:本文为博主原创文章,转载请指明转载地址
www.cnblogs.com/fydeblog/p/7140974.html
前言
这篇notebook是关于机器学习中监督学习的k近邻算法,将介绍2个实例,分别是使用k-近邻算法改进约会网站的效果和手写识别系统.
操作系统:ubuntu14.04 运行环境:anaconda-python2.7-notebook 参考书籍:机器学习实战 notebook writer ----方阳
k-近邻算法(kNN)的工作原理:存在一个样本数据集合,也称作训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一组数据与所属分类的对应关系,输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似的分类标签。
注意事项:在这里说一句,默认环境python2.7的notebook,用python3.6的会出问题,还有我的目录可能跟你们的不一样,你们自己跑的时候记得改目录,我会把notebook和代码以及数据集放到结尾的百度云盘,方便你们下载!
1.改进约会网站的匹配效果
1-1.准备导入数据
from numpy import *
import operator def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
先来点开胃菜,在上面的代码中,我们导入了两个模块,一个是科学计算包numpy,一个是运算符模块,在后面都会用到,在createDataSet函数中,我们初始化了group,labels,我们将做这样一件事,[1.0,1.1]和[1.0,1.0] 对应属于labels中 A 分类,[0,0]和[0,0.1]对应属于labels中的B分类,我们想输入一个新的二维坐标,根据上面的坐标来判断新的坐标属于那一类,在这之前,我们要实现k-近邻算法,下面就开始实现
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
代码解析:
函数的第一行是要得到数据集的数目,例如group.shape就是(4,2),shape[0]反应数据集的行,shape[1]反应列数
函数的第二行是array对应相减,tile会生成关于Inx的dataSetSize大小的array,例如,InX是[0,0],则tile(InX,(4,1))是array([[0, 0], [0, 0], [0, 0],[0, 0]]),然后与dataSet对应相减,得到新的array
函数的第三行是对第二步的结果进行平方算法,方便下一步算距离
函数的第四行是进行求和,注意是axis=1,也就是array每个二维数组成员进行求和(行求和),如果是axis=0就是列求和
第五行是进行平方距离的开根号
以上5行实现的是距离的计算 ,下面的是选出距离最小的k个点,对类别进行统计,返回所占数目多的类别
classCount定义为存储字典,里面有‘A’和‘B’,它们的值是在前k个距离最小的数据集中的个数,本例最后classCount={'A':1,'B':2},函数argsort是返回array数组从小到大的排列的序号,get函数返回字典的键值,由于后面加了1,所以每次出现键值就加1,就可以就算出键值出现的次数里。最后通过sorted函数将classCount字典分解为列表,sorted函数的第二个参数导入了运算符模块的itemgetter方法,按照第二个元素的次序(即数字)进行排序,由于此处reverse=True,是逆序,所以按照从大到小的次序排列。
1-2.准备数据:从文本中解析数据
这上面是k-近邻的一个小例子,我的标题还没介绍,现在来介绍标题,准备数据,一般都是从文本文件中解析数据,还是从一个例子开始吧!
本次例子是改进约会网站的效果,我们定义三个特征来判别三种类型的人
特征一:每年获得的飞行常客里程数
特征二:玩视频游戏所耗时间百分比
特征三:每周消费的冰淇淋公升数
根据以上三个特征:来判断一个人是否是自己不喜欢的人,还是魅力一般的人,还是极具魅力的人
于是,收集了1000个样本,放在datingTestSet2.txt中,共有1000行,每一行有四列,前三列是特征,后三列是从属那一类人,于是问题来了,我们这个文本文件的输入导入到python中来处理,于是需要一个转换函数file2matrix,函数输入是文件名字字符串,输出是训练样本矩阵(特征矩阵)和类标签向量
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
这个函数比较简单,就不详细说明里,这里只介绍以下一些函数的功能吧!
open函数是打开文件,里面必须是字符串,由于后面没加‘w’,所以是读文件
readlines函数是一次读完文件,通过len函数就得到文件的行数
zeros函数是生成numberOfLines X 3的矩阵,是array型的
strip函数是截掉所有的回车符
split函数是以输入参数为分隔符,输出分割后的数据,本例是制表键,最后输出元素列表
append函数是向列表中加入数据
1-3.分析数据:使用Matplotlib创建散点图
首先,从上一步得到训练样本矩阵和类标签向量,先更换一下路径
cd /home/fangyang/桌面/machinelearninginaction/Ch02/
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,0], datingDataMat[:,1], 15.0*array(datingLabels), 15.0*array(datingLabels)) #scatter函数是用来画散点图的
plt.show()
结果显示

1-4. 准备数据: 归一化处理
我们从上图可以上出,横坐标的特征值是远大于纵坐标的特征值的,这样再算新数据和数据集的数据的距离时,数字差值最大的属性对计算结果的影响最大,我们就可能会丢失掉其他属性,例如这个例子,每年获取的飞行常客里程数对计算结果的影响远大于其余两个特征,这是我们不想看到的,所以这里采用归一化数值处理,也叫特征缩放,用于将特征缩放到同一个范围内。
本例的缩放公式 newValue = (oldValue - min) / (max - min)
其中min和max是数据集中的最小特征值和最大特征值。通过该公式可将特征缩放到区间(0,1)
下面是特征缩放的代码
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
normDataSet(1000 X 3)是归一化后的数据,range(1X3)是特征的范围差(即最大值减去最小值),minVals(1X3)是最小值。
原理上面已介绍,这里不在复述。
1-5.测试算法:作为完整程序验证分类器
好了,我们已经有了k-近邻算法、从文本解析出数据、还有归一化处理,现在可以使用之前的数据进行测试了,测试代码如下
def datingClassTest():
hoRatio = 0.50
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount
这里函数用到里之前讲的三个函数:file2matrix、autoNorm和classify0.这个函数将数据集分成两个部分,一部分当作分类器的训练样本,一部分当作测试样本,通过hoRatio进行控制,函数hoRatio是0.5,它与样本总数相乘,将数据集平分,如果想把训练样本调大一些,可增大hoRatio,但最好不要超过0.8,以免测试样本过少,在函数的最后,加了错误累加部分,预测出来的结果不等于实际结果,errorCount就加1,然后最后除以总数就得到错误的概率。
说了这么多,都还没有测试以下,下面来测试一下!先从简单的开始(已将上面的函数放在kNN.py中了)
import kNN
group , labels = kNN.createDataSet()
group #结果在下
array([[ 1. , 1.1],
[ 1. , 1. ],
[ 0. , 0. ],
[ 0. , 0.1]])
labels #结果在下
['A', 'A', 'B', 'B']
这个小例子最开始提过,有两个分类A和B,通过上面的group为训练样本,测试新的数据属于那一类
kNN.classify0([0,0], group, labels, 3) #使用k-近邻算法进行测试
'B' #结果是B分类
直观地可以看出[0,0]是与B所在的样本更近,下面来测试一下约会网站的匹配效果
先将文本中的数据导出来,由于前面在分析数据画图的时候已经用到里file2matrix,这里就不重复用了。
datingDataMat #结果在下
array([[ 4.09200000e+04, 8.32697600e+00, 9.53952000e-01],
[ 1.44880000e+04, 7.15346900e+00, 1.67390400e+00],
[ 2.60520000e+04, 1.44187100e+00, 8.05124000e-01],
...,
[ 2.65750000e+04, 1.06501020e+01, 8.66627000e-01],
[ 4.81110000e+04, 9.13452800e+00, 7.28045000e-01],
[ 4.37570000e+04, 7.88260100e+00, 1.33244600e+00]])
datingLabels #由于过长,只截取一部分,详细去看jupyter notebook
然后对数据进行归一化处理
normMat , ranges , minVals = kNN.autoNorm(datingDataMat) #使用归一化函数
normMat
array([[ 0.44832535, 0.39805139, 0.56233353],
[ 0.15873259, 0.34195467, 0.98724416],
[ 0.28542943, 0.06892523, 0.47449629],
...,
[ 0.29115949, 0.50910294, 0.51079493],
[ 0.52711097, 0.43665451, 0.4290048 ],
[ 0.47940793, 0.3768091 , 0.78571804]])
ranges
array([ 9.12730000e+04, 2.09193490e+01, 1.69436100e+00])
minVals
array([ 0. , 0. , 0.001156])
最后进行测试,运行之前的测试函数datingClassTest
kNN.datingClassTest()
由于过长,只截取一部分,详细去看jupyter notebook

可以看到上面结果出现错误32个,错误率6.4%,所以这个系统还算不错!
1-6.系统实现
我们可以看到,测试固然不错,但用户交互式很差,所以结合上面,我们要写一个完整的系统,代码如下:
def classifyPerson():
resultList = ['not at all', 'in small doses', 'in large doses']
percentTats = float(raw_input("percentage of time spent playing video games?"))
ffMiles = float(raw_input("frequent flier miles earned per year?"))
iceCream = float(raw_input("liters of ice cream consumed per year?"))
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = array([ffMiles, percentTats, iceCream])
classifierResult = classify0((inArr-minVals)/ranges, normMat, datingLabels,3)
print "You will probably like this person" , resultList[classifierResult - 1]
运行情况
kNN.classifyPerson()
percentage of time spent playing video games?10 #这里的数字都是用户自己输入的
frequent flier miles earned per year?10000
liters of ice cream consumed per year?0.5
You will probably like this person in small doses
这个就是由用户自己输出参数,并判断出感兴趣程度,非常友好
2. 手写识别系统
下面再介绍一个例子,也是用k-近邻算法,去实现对一个数字的判断,首先我们是将宽高是32X32的像素的黑白图像转换成文本文件存储,但我们知道文本文件必须转换成特征向量,才能进入k-近邻算法中进行处理,所以我们需要一个img2vector函数去实现这个功能!
img2vector代码如下:
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
这个函数挺简单的,先用zeros生成1024的一维array,然后用两重循环,外循环以行递进,内循环以列递进,将32X32的文本数据依次赋值给returnVect
好了,转换函数写好了,说一下训练集和测试集,所有的训练集都放在trainingDigits文件夹中,测试集放在testDigits文件夹中,训练集有两千个样本,0~9各有200个,测试集大约有900个样本,这里注意一点,所有在文件夹里的命名方式是有要求的,我们是通过命名方式来解析出它的真实数字,然后与通过k-近邻算法得出的结果相对比,例如945.txt,这里的数字是9,连接符前面的数字就是这个样本的真实数据。该系统实现的方法与前面的约会网站的类似,就不多说了。
系统测试代码如下
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits') #load the training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits') #iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))
这里的listdir是从os模块导入的,它的功能是列出给定目录下的所有文件名,以字符串形式存放,输出是一个列表
这里的split函数是要分离符号,得到该文本的真实数据,第一个split函数是以小数点为分隔符,例如‘1_186.txt’ ,就变成了['1_186','txt'],然后取出第一个,就截掉了.txt,第二个split函数是以连接符_为分隔符,就截掉后面的序号,剩下前面的字符数据‘1’,然后转成int型就得到了它的真实数据,其他的没什么,跟前面一样
下面开始测试
kNN.handwritingClassTest()
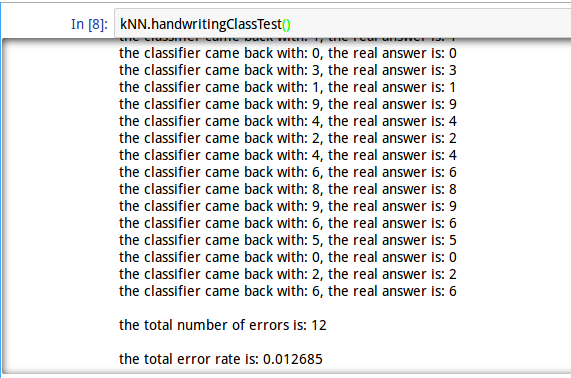
我们可以看到最后结果,错误率1.2%, 可见效果还不错!
这里把整个kNN.py文件贴出来,主要是上面已经介绍的函数
'''
Input: inX: vector to compare to existing dataset (1xN)
dataSet: size m data set of known vectors (NxM)
labels: data set labels (1xM vector)
k: number of neighbors to use for comparison (should be an odd number) Output: the most popular class label
''' from numpy import *
import operator
from os import listdir def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0] def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals def datingClassTest():
hoRatio = 0.50 #hold out 10%
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount def classifyPerson():
resultList = ['not at all', 'in small doses', 'in large doses']
percentTats = float(raw_input("percentage of time spent playing video games?"))
ffMiles = float(raw_input("frequent flier miles earned per year?"))
iceCream = float(raw_input("liters of ice cream consumed per year?"))
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = array([ffMiles, percentTats, iceCream])
classifierResult = classify0((inArr-minVals)/ranges, normMat, datingLabels,3)
print "You will probably like this person" , resultList[classifierResult - 1] def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits') #load the training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits') #iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))
结尾
至此,这个k-近邻算法的介绍到这里就结束了,希望这篇文章对你的学习有帮助!
百度云链接: https://pan.baidu.com/s/1OuyOuGi9r8eaPS9gglAzBg
python机器学习实战(一)的更多相关文章
- python机器学习实战(二)
python机器学习实战(二) 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7159775.html 前言 这篇noteboo ...
- python机器学习实战(三)
python机器学习实战(三) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7277205.html 前言 这篇notebook是关于机器 ...
- python机器学习实战(四)
python机器学习实战(三) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7364317.html 前言 这篇notebook是关于机器学 ...
- Python 机器学习实战 —— 监督学习(上)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- Python 机器学习实战 —— 监督学习(下)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- Python 机器学习实战 —— 无监督学习(上)
前言 在上篇<Python 机器学习实战 -- 监督学习>介绍了 支持向量机.k近邻.朴素贝叶斯分类 .决策树.决策树集成等多种模型,这篇文章将为大家介绍一下无监督学习的使用.无监督学习顾 ...
- Python 机器学习实战 —— 无监督学习(下)
前言 在上篇< Python 机器学习实战 -- 无监督学习(上)>介绍了数据集变换中最常见的 PCA 主成分分析.NMF 非负矩阵分解等无监督模型,举例说明使用使用非监督模型对多维度特征 ...
- 【Python机器学习实战】决策树和集成学习(一)
摘要:本部分对决策树几种算法的原理及算法过程进行简要介绍,然后编写程序实现决策树算法,再根据Python自带机器学习包实现决策树算法,最后从决策树引申至集成学习相关内容. 1.决策树 决策树作为一种常 ...
- Python机器学习实战<一>:环境的配置
详细要学习的书籍就是<机器学习实战>Machine Learning in Action,Peter Harrington Windows下要安装3个文件,各自是; 1.Python(因为 ...
随机推荐
- 谈一谈JDK8的函数式编程 (一)
系列之前我想说的 最近有一段时间没写博客了,这几天回到学校,才闲下来,决定写一写最近学习到的只是,既是为了分享,也是为了巩固.之前看到过一篇调查,文章的数据是学习新知识,光是看只能获得大约5%,然 ...
- 【Python的迭代器,生成器】
一.可迭代对象和迭代器 1.迭代的概念 上一次输出的结果为下一次输入的初始值,重复的过程称为迭代,每次重复即一次迭代,并且每次迭代的结果是下一次迭代的初始值 注:循环不是迭代 while True: ...
- GPU编程--Shared Memory(4)
GPU的内存按照所属对象大致分为三类:线程独有的.block共享的.全局共享的.细分的话,包含global, local, shared, constant, and texture memoey, ...
- SqlDataReader 之指定转换无效
//获取最新显示顺序数据 string str = string.Format(@"if exists(select ShowOrder from GIS_FuncDefaultLayer ...
- JS学习笔记——JavaScript继承的6种方法(原型链、借用构造函数、组合、原型式、寄生式、寄生组合式)
JavaScript继承的6种方法 1,原型链继承 2,借用构造函数继承 3,组合继承(原型+借用构造) 4,原型式继承 5,寄生式继承 6,寄生组合式继承 1.原型链继承. <script t ...
- java面试基础题(三)
程序员面试之九阴真经 谈谈final, finally, finalize的区别: final:::修饰符(关键字)如果一个类被声明为final,意味着它不能再派生出新的子类,不能作为父类被继承.因此 ...
- Linux下串口通信工具minicom的用法
一.查看串口设备 例如,将USB转串口线插入交换机Console口后,执行命令:$ll /dev/ttyUSB* 二.连接串口设备 $sudo minicom -D /dev/ttyUSB0 三.设置 ...
- MongoDB--数据库与Collection注意事项
<h2> <strong>注意事项:</strong></h2>1.数据库名注意应该全部小写,不能包含空格,最大长度为64K名称<br /& ...
- Tomcat7的热部署
所谓热部署就是在tomcat不停机的情况下,将新的war包放上去,达到服务不中断,用户无察觉的目的,实现的原理很简单,这里做下记录,以便后期查看. 1.1 安装tomcat7 略 1.2 在tomca ...
- maven 不同环境加载不同的properties 文件
http://haohaoxuexi.iteye.com/blog/1900568 //参考文章 实际项目中pom配置如下 <profiles> <profile> <i ...