Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地。(Python版本为3.6.0)
一.获取整个页面数据
def getHtml(url):
page=urllib.request.urlopen(url)
html=page.read()
return html
说明:
向getHtml()函数传递一个网址,就可以把整个页面下载下来.
urllib.request 模块提供了读取web页面数据的接口,我们可以像读取本地文件一样读取www和ftp上的数据.
二.筛选页面中想要的数据
在百度贴吧找到了几张漂亮的图片,想要下载下来.使用火狐浏览器,在图片位置鼠标右键单单击有查看元素选项,点进去之后就会进入开发者模式,并且定位到图片所在的前段代码
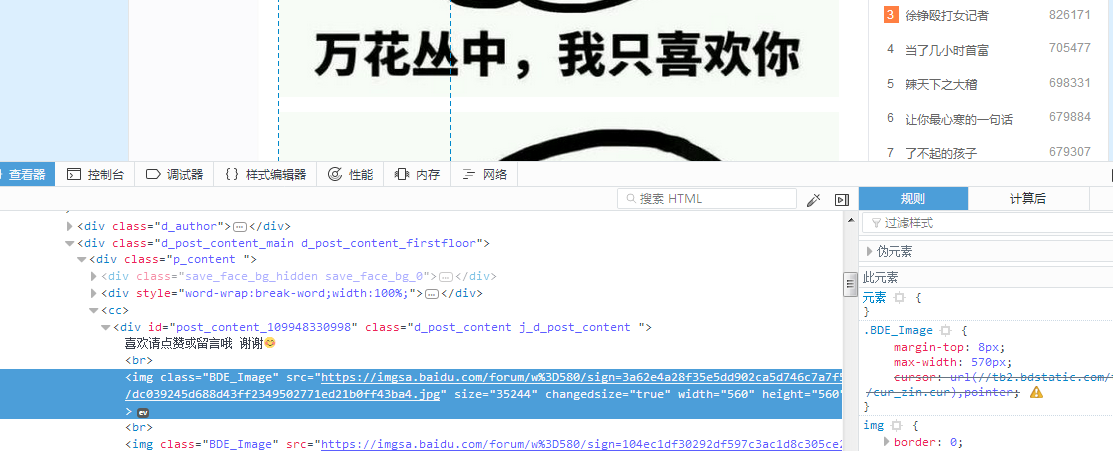
现在主要观察图片的正则特征,编写正则表达式.
reg=r'src="(https://imgsa[^>]+\.(?:jpeg|jpg))"'
#参考正则
编写代码
def getImg(html):
reg=r'src="(https://imgsa[^>]+\.(?:jpeg|jpg))"'
imgre = re.compile(reg)
imglist = re.findall(imgre,html.decode('utf-8'))
return imglist
说明:
re.compile() 可以把正则表达式编译成一个正则表达式对象.
re.findall() 方法读取html 中包含 imgre(正则表达式)的数据。
运行脚本将得到整个页面中包含图片的URL地址。
三.将页面筛选的数据保存到本地
编写一个保存的函数
def saveFile(x):
if not os.path.isdir(path):
os.makedirs(path)
t = os.path.join(path,'%s.img'%x)
return t
完整代码:
'''
Created on 2017年7月15日 @author: Administrator
'''
import urllib.request,os
import re def getHtml(url):
page=urllib.request.urlopen(url)
html=page.read()
return html path='D:/workspace/Python1/reptile/__pycache__/img' def saveFile(x):
if not os.path.isdir(path):
os.makedirs(path)
t = os.path.join(path,'%s.img'%x)
return t html=getHtml('https://tieba.baidu.com/p/5248432620') print(html) print('\n') def getImg(htnl):
reg=r'src="(https://imgsa[^>]+\.(?:jpeg|jpg))"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html.decode('utf-8'))
x=
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,saveFile(x))
print(imgurl)
x+=
if x==:
break
print(x)
return imglist getImg(html)
print('end')
核心是用到了urllib.request.urlretrieve()方法,直接将远程数据下载到本地
最后,有点问题还没有完全解决,这里也向大家请教一下.
当下载图片超过23张时会报错:
urllib.error.HTTPError: HTTP Error 500: Internal Server Error
不知道是什么问题,求助.
Python简易爬虫爬取百度贴吧图片的更多相关文章
- 【Python】Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地.(Python版本为3.6.0) 一.获取整个页面数据 def getHtml(url): page=urllib.requ ...
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://www.cnblogs.com/huangxie/p/5473273.html 这一篇我想写写如何爬取百度图片的爬虫 ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
随机推荐
- JS语句
JS语句包括: 1.顺序语句 2.分支语句: if...else switch...case 3.循环语句 一.先看顺序语句: </body> < ...
- cp的用法
1.cp的功能 拷贝一个或多个文件(或目录)到目的地 2.例子 1)一次拷贝多个源文件到目的地#cp /mnt/hgfs/DOC/{1,2,3,4,5}.txt /root/ldj 2)只拷贝链接文件 ...
- IIS虚拟目录与UNC路径权限初探
最近在一个项目中涉及到了虚拟目录与UNC路径的问题,总结出来分享给大家. 问题描述 某客户定制化项目(官网),有一个图片上传的功能.客户的Web机器有10台,通过F5负载均衡分摊请求. 假设这10台机 ...
- document事件及例子
一.关于鼠标事件:onclick:鼠标单击触发 ondbclick:鼠标双击触发 onmouseover:鼠标移上触发 onmouseout:鼠标离开触发 onmousemove:鼠标移动触发 二.关 ...
- Jquery页面滚动动态加载数据,页面下拉自动加载内容
<!DOCTYPE=html> <html> <head> <script src="js/jquery.js" type="t ...
- 单人纸牌_NOI导刊2011提高(04)
单人纸牌 时间限制: 1 Sec 内存限制: 128 MB 题目描述 单人纸牌游戏,共 36 张牌分成 9 叠,每叠 4 张牌面向上.每次,游戏者可以从某两个不同的牌堆最顶上取出两张牌面相同的牌(如 ...
- java http请求,字节流获取百度数据
请求的地址为: http://api.map.baidu.com/place/v2/search?&q=%E9%A5%AD%E5%BA%97®ion=%E9%87%8D%E5%B ...
- sublime 设置字体
通过菜单Preferences/Settings - User,添加下面这行配置就可以修改字体: "font_face": "Courier New", &qu ...
- KBEngine简单RPG-Demo源码解析(3)
十四:在世界中投放NPC/MonsterSpace的cell创建完毕之后, 引擎会调用base上的Space实体, 告知已经获得了cell(onGetCell),那么我们确认cell部分创建好了之后就 ...
- 怎样把echarts图表做成响应式的
如果想要把echarts图表给做成响应式的那么就应该用rem 单位,给图表的外围容器设置rem 单位,然后调用jquery 的resize方法,$(window).resize(function(){ ...