真刀真枪压测:基于TCPCopy的仿真压测方案
本文档适用人员:技术人员
- 为什么要做仿真测试
- TCPCopy是如何工作的
- 实作:仿真测试的拓扑
- 实作:操作步骤
- 可能会遇到的问题
- ip_conntrack
- 少量丢包
- 离线重放
- 不提取7层信息
- 观测的性能指标
2010年,网易技术部的王斌在王波的工作基础上开发了 TCPCopy - A TCP Stream Replay Tool。2011年9月开源。当前版本号是 1.0.0。很多公司的模拟在线测试都是基于 TCPCopy 做的,如一淘。
- Online Server(OS):上面要部署 TCPCopy,从数据链路层(pcap 接口)抓请求数据包,发包是从IP层发出去;
- Test Server(TS):最新的架构调整把 intercept 的工作从 TS 中 offload 出来。TS 设置路由信息,把 被测应用 的需要被捕获的响应数据包信息路由到 AS;
- Assistant Server(AS):这是一台独立的辅助服务器,原则上一定要用同网段的一台闲置服务器来充当辅助服务器。AS 在数据链路层截获到响应包,从中抽取出有用的信息,再返回给相应的 OS 上的 tcpcopy 进程。
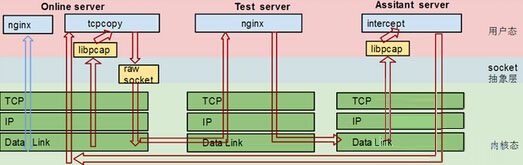

为了便于理解 pcap 抓包,下面简单描述一下 libpcap 的工作原理。
一个包的捕捉分为三个主要部分:
- 面向底层包捕获,
- 面向中间层的数据包过滤,
- 面向应用层的用户接口。
这与 Linux 操作系统对数据包的处理流程是相同的(网卡->网卡驱动->数据链路层->IP层->传输层->应用程序)。包捕获机制是在数据链路层增加一个旁路处理(并不干扰系统自身的网络协议栈的处理),对发送和接收的数据包通过Linux内核做过滤和缓冲处理,最后直接传递给上层应用程序。如下图2所示:
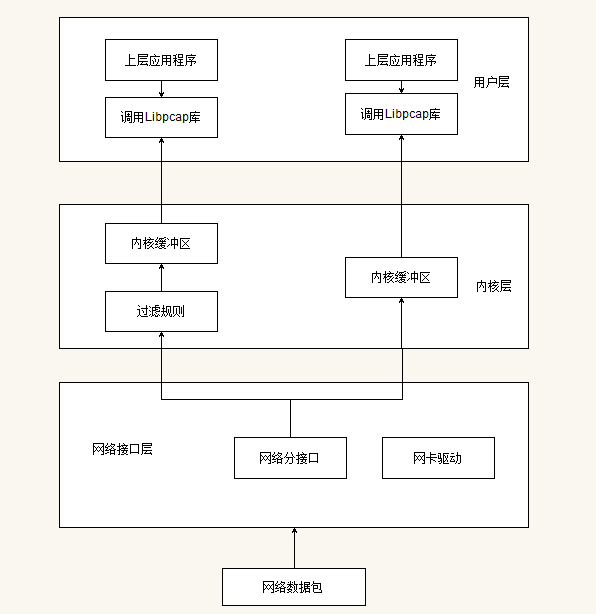
图2 libpcap的三部分
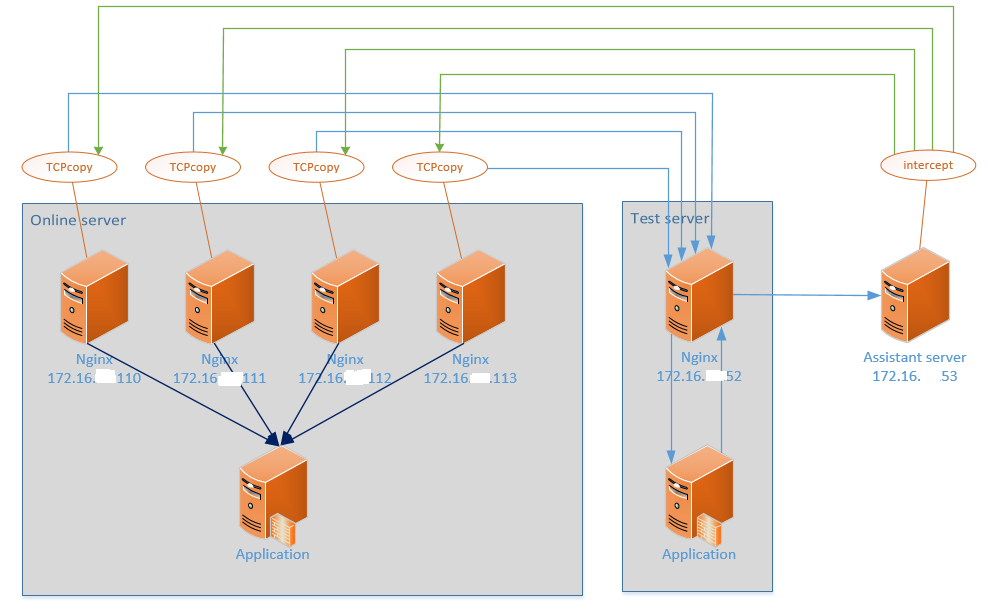
环境如下:
- Online Server
- 4个生产环境 Nginx
- 172.16.***.110
- 172.16.***.111
- 172.16.***.112
- 172.16.***.113
- Test Server
- 一个镜像环境的 Nginx
- 172.16.***.52
- Assistant Server
- 镜像环境里的一台独立服务器
- 172.16.***.53

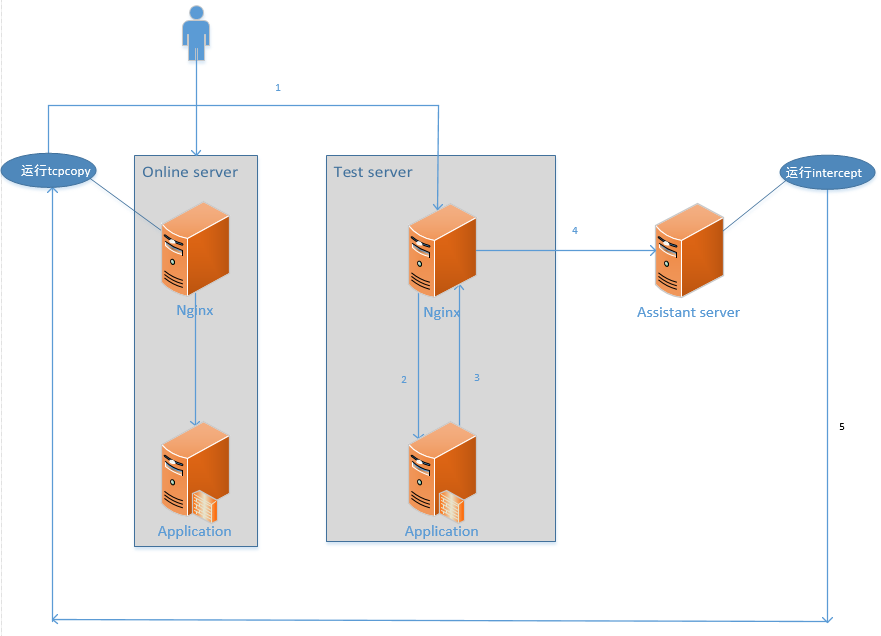



- TCPcopy 从数据链路层 copy 端口请求,然后更改目的 ip 和目的端口。
- 将修改过的数据包传送给数据链路层,并且保持 tcp 连接请求。
- 通过数据链路层从 online server 发送到 test server。
- 在数据链路层解封装后到达 nginx 响应的服务端口。
- 等用户请求的数据返回结果后,回包走数据链路层。
- 通过数据链路层将返回的结果从 test server 发送到 assistant server。注:test server 只有一条默认路由指向 assistant server。
- 数据到达 assistant server 后被 intercept 进程截获。
- 过滤相关信息将请求状态发送给 online server 的 tcpcopy,关闭 tcp 连接。
3)离线重放
本次仿真测试,没有试验成功第二种工作模式,留待以后进一步研究。
- Java 工程的访问次数,响应时间,平均响应时间,调用成功或失败,Web端口连接数;
- Web容器的 thread、memory 等情况;
- 虚拟机的 CPU-usage、Load-avg、io-usage 等;
- memcached/redis 等缓存集群的命中率等;

真刀真枪压测:基于TCPCopy的仿真压测方案的更多相关文章
- 基于TCPCopy的仿真压测方案
一.tcpcopy工具介绍 tcpcopy 是一个分布式在线压力测试工具,可以将线上流量拷贝到测试机器,实时的模拟线上环境,达到在程序不上线的情况下实时承担线上流量的效果,尽早发现 bug,增加上线信 ...
- 案例 | 荔枝微课基于 kubernetes 搭建分布式压测系统
王诚强,荔枝微课基础架构负责人.热衷于基础技术研发推广,致力于提供稳定高效的基础架构,推进了荔枝微课集群化从0到1的发展,云原生架构持续演进的实践者. 本文根据2021年4月10日深圳站举办的[腾讯云 ...
- 压测2.0:云压测 + APM = 端到端压测解决方案
从压力测试说起 压力测试是确立系统稳定性的一种测试方法,通常在系统正常运作范围之外进行,以考察其功能极限和隐患.与功能测试不同,压测是以软件响应速度为测试目标的,尤其是针对在较短时间内大量并发用户的访 ...
- 基于Python——实现解压文件夹中的.zip文件
[背景]当一个文件夹里存好好多.zip文件需要解压时,手动一个个解压再给文件重命名是一件很麻烦的事情,基于此,今天介绍一种使用python实现批量解压文件夹中的压缩文件并给文件重命名的方法—— [代码 ...
- [Linux] 解压tar.gz文件,解压部分文件
遇到数据库无法查找问题原因,只能找日志,查找日志的时候发现老的日志都被压缩了,只能尝试解压了 数据量比较大,只能在生产解压了,再进行查找 文件名为*.tar.gz,自己博客以前记录过解压方法: h ...
- linux下tar压缩/解压的使用(tar) 压缩/解压
压缩: tar -zcvf 压缩后文件名.tar.gz 被压缩文件 解压: tar -zxvf 被解压文件 具体的可以在linux环境下 用 tar --help 查看详细说明格式:ta ...
- 【译】基于主机的卡仿真(Host-based Card Emulation)
基于主机的卡仿真(Host-based Card Emulation) 能提供NFC功能很多Android手机已经支持NFC卡模拟.在大多数情况下,该卡是由设备中的单独的芯片仿真,所谓的安全元件.由无 ...
- 基于AgileEAS.NET企业应用平台实现基于SOA架构的应用整合方案-开篇
开篇 系统架构的文章,准备在这段时间好好的梳理和整理一下,然后发布基于AgileEAS.NET平台之上的企业级应用架构实践,结合具体的案例来说明AgileEAS.NET平 台之上如何进行系统的逻辑架构 ...
- 尝试asp.net mvc 基于controller action 方式权限控制方案可行性
微软在推出mvc框架不久,短短几年里,版本更新之快,真是大快人心,微软在这种优秀的框架上做了大量的精力投入,是值得赞同的,毕竟程序员驾驭在这种框架上,能够强力的精化代码,代码层次也更加优雅,扩展较为方 ...
随机推荐
- SQL Server遍历表的几种方法
在数据库开发过程中,我们经常会碰到要遍历数据表的情形,一提到遍历表,我们第一印象可能就想到使用游标,使用游标虽然直观易懂,但是它不符合面向集合操作的原则,而且性能也比面向集合低.当然,从面向集合操作的 ...
- 大熊君JavaScript插件化开发------(实战篇之DXJ UI ------ ItemSelector重构完结版)
一,开篇分析 Hi,大家好!大熊君又和大家见面了,还记得上一篇文章吗.主要讲述了以“jQuery的方式如何开发插件”,以及过程化设计与面向对象思想设计相结合的方式是 如何设计一个插件的,两种方式各有利 ...
- 关于当传过来的值转换成string类型报错的问题
有时候直接写 string str=request.param["str"].tostring;会报错,是因为接受到的值可能是空的 这个时候就可以这样写 string _actio ...
- godaddy域名使用DNSPod做DNS解析图文教程
考虑到很多朋友看到英文就很头痛,在godaddy解析域名也不怎么方便,我们需要把在godaddy注册的域名,使用国内的DNS服务器,全部都是免费的哦. 首先打开www.dnspod.cn 用自己的常 ...
- 用C语言,如何判断主机是 大端还是小端(字节序)
所谓大端就是指高位值在内存中放低位地址,所谓小端是指低位值在内存中放低位地址.比如 0x12345678 在大端机上是 12345678,在小端机上是 78564312,而一个主机是大端还是小端要看C ...
- iOS开发——高级篇——二维码的生产和读取
一.二维码的生成 从iOS7开始集成了二维码的生成和读取功能此前被广泛使用的zbarsdk目前不支持64位处理器 生成二维码的步骤:导入CoreImage框架通过滤镜CIFilter生成二维码 二维码 ...
- Unity3D 摄像机的Transform通过摇杆输出的方向
要解决的问题是:摄像机的方向不固定,当摇杆向前(0,1)推时,主角要往摄像机的朝向(忽略Y方向)走,当摇杆往右(1,0)推的时,主角朝摄像机的右方向 /// <summary> /// 摄 ...
- objccn-图片格式
图像格式存储:位图和矢量图像.位图把值存在阵列中,矢量格式存储的是绘图图像的指令.还有混合格式PostScript能够排布字母甚至位图,使其成为了一个非常灵活的方式.衍生格式pdf. xcdoe6已经 ...
- Effective Python2 读书笔记2
Item 14: Prefer Exceptions to Returning None Functions that returns None to indicate special meaning ...
- ionic扩展插件
1.ionic-timepicker 时间选择 https://github.com/rajeshwarpatlolla/ionic-timepicker 2.ionic-datepicker 日 ...