刚开始搞爬虫的时候听到有人说爬虫是一场攻坚战,听的时候也没感觉到特别,但是经过了一段时间的练习之后,深以为然,每个网站不一样,每次爬取都是重新开始,所以,爬之前谁都不敢说会有什么结果。
前两天,应几个小朋友的邀请,动心思玩了一下大众点评的数据爬虫,早就听说大众点评的反爬方式不一般,貌似是难倒了一片英雄好汉,当然也成就了网上的一众文章,专门讲解如何爬取大众点评的数据,笔者一边阅读这些文章寻找大众点评的破解思路,一边为大众点评的程序员小哥哥们鸣不平,辛辛苦苦写好的加密方式,你们这些爬虫写手们这是闹哪样?破解也就算了,还发到网上去,还发这么多~
笔者在阅读完这些文章之后,自信心瞬间爆棚,有如此多的老师,还有爬不了的网站,于是,笔者信誓旦旦的开始了爬大众点评之旅,结果,一上手就被收拾了,各个大佬们给出的爬虫方案中竟然有手动构建对照表的过程,拜托,如果我想手动,还要爬虫做什么?别说手动,半自动都不行。
大家看到这里或许头上有些雾水了,什么手动?什么半自动?还对照表?大佬,你这是什么梗?再不解释一些我就要弃剧了,葛优都拉不回来~
大家先不要着急,静一静,对照表后面会讲,这里只需要知道我遇到困难了,就可以了,不过咨询了几个大佬之后,好在解决了,革命的路上虽有羁绊,终归还是有同志的
好,现在开始入正题,点评的程序员哥哥请不要寄刀片:
大众点评的数据爬虫开始还是很正常的,各个题目、菜单基本上都可以搞下来:
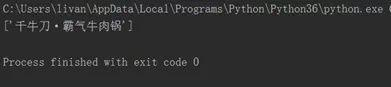
#!/usr/bin/env python # _*_ UTF-8 _*_ import requests from lxml import etree header = {"Accept":"application/json, text/javascript", "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8", "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36", "Cookie":"cy=1; cye=shanghai; _lxsdk_cuid=16ca41d3344c8-050eb4ac8f1741-4d045769-1fa400-16ca41d3345c8; _lxsdk=16ca41d3344c8-050eb4ac8f1741-4d045769-1fa400-16ca41d3345c8; _hc.v=38ae2e43-608f-1198-11ff-38a36dc160a4.1566121473; _lxsdk_s=16ce7f63e0d-91a-867-5a%7C%7C20; s_ViewType=10" } url = 'http://www.dianping.com/beijing/ch10/g34060o2' response = requests.get(url, headers=header) data = etree.HTML(response.text) title = data.xpath('//*[@id="shop-all-list"]/ul/li[1]/div[2]/div[1]/a/@title') print(title)
按照常规的套路,爬虫可以说是写成了。但是,现在的网站大多使用了反爬,一方面担心自己的服务器会被爬虫搞的超负荷,另一方面也为了保护自己的数据不被其他人获取。
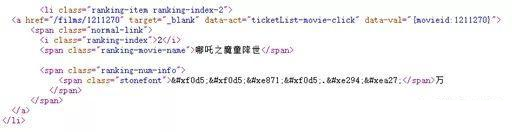
大众点评就是众多带反爬的网站中的佼佼者,使用了比较高级的反爬手法,他们把页面上的关键数字隐藏了起来,增加了爬虫难度,不信~你看:
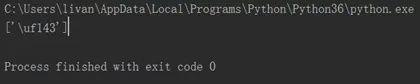
data = etree.HTML(response.text) title = data.xpath('//*[@id="shop-all-list"]/ul/li[1]/div[2]/div[2]/a[1]/b/svgmtsi[1]/text()') print(title)
<svgmtsi></svgmtsi>
我们发现了网上一直在讨论的svgmtsi标签,这个标签是矢量图的标签,基本上意思就是显示在这里的文字是一个矢量图,解析这个矢量图需要到另外一个地方找一个对照表,通过对照表将编码内容翻译成人类可以识别的数字。
我们先记录下标签中的class值:shopNum(为什么记录,先不要着急,后面会讲到),然后在源代码中查找svg,我们发现了如下内容:
这好像是个链接,我们点击一下,发现页面跳转到了一个全新的水月洞天:
这真是个伟大的发现,他预示着我们的爬虫找到了门路,我们在这个页面上查找刚才class中的值shopNum,然后,我们看到了如下内容:
.shopNum{font-family: 'PingFangSC-Regular-shopNum';}@font-face{font-family:
"PingFangSC-Regular-reviewTag";
在这段代码中距离shopNum最近的地方,我们找到一个woff文件。
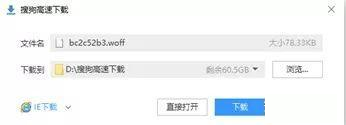
同样的思路,这是一个网址,我们可以把他下载下来,把这个网址复制到浏览器的地址栏中,点回车,会跳出如下快乐的界面。
下载完成后,我们在浏览器中打开woff的翻译工具:
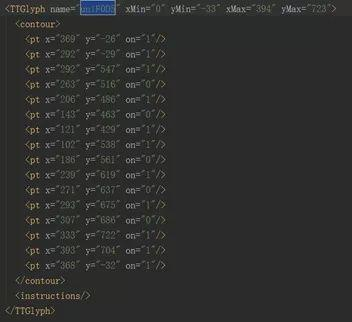
我们把前面的&#x去掉并替换成uni,后面的;去掉,得到字段为:unif784。
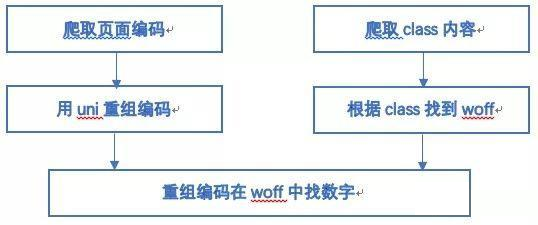
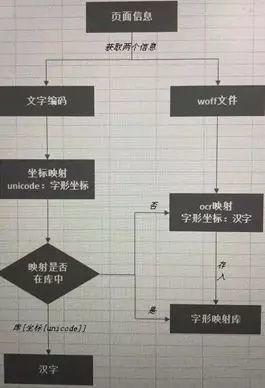
事情到这里其实就可以画个句号了,因为接下来的思路就变的非常简单了,我们用上面的通用爬虫下载下网站上所有编码和对应的class值,然后根据class值找到对应的woff文件,再在woff文件中确定编码对应的数字或汉字就可以。
1)如何读取出woff文件中的数字,大众点评有多个woff文件,怎么对照读取呢?难不成要一个个写出来?根据前面网站里的文章来讲,对的,你猜的很准,这就是我文章一开始写的半自动,崩溃了吧,好在笔者找到了新的方法,取代了半自动的问题,这个新的方法就是OCR识别,后面我会仔细讲解。
2)页面的编码是变动的,你没有看错,这个值是会变的,好在这个事件没有发生在大众点评中,但是汽车之家、猫眼等网站使用的CSS加密会随页面的刷新发生变动,有没有惊到你?
如果你只需要大众点评,第二个问题几乎可以不用考虑了,但是笔者认为要做一个有理想的爬虫,尽量多的获取知识点才是正确的,所以,笔者研究了汽车之家、猫眼、天眼等几个用CSS加密的网站,找到了一个通用的方法,下面我们来介绍一下这个通用方法。
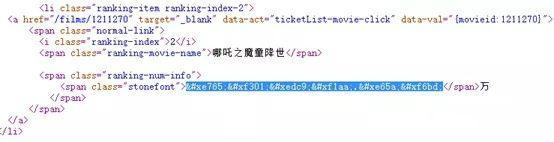
我们先找到一个加密编码,把他复制出来,看到的编码如下:
针对这一变化,笔者心中产生了一个疑惑,如果说编码会变,那浏览器是怎么获取到准确的值的呢?说明一定存在一个统一的方法供浏览器调用,于是,笔者重新研究了编码的调用方式,惊奇的发现了其中的秘密:
这两个字段都是表示数字中的1,那他们有什么规律呢?
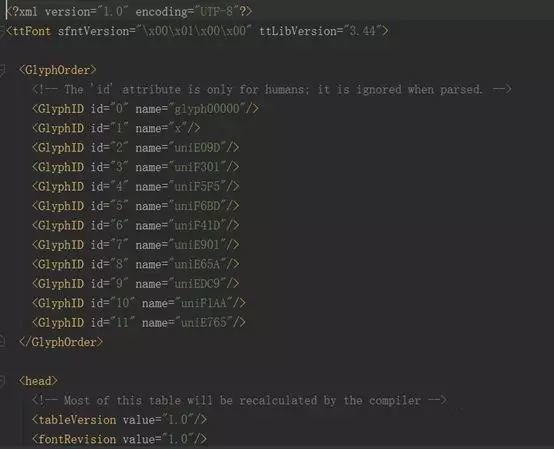
from fontTools.ttLib import TTFont font = TTFont('e765.woff') font.saveXML('e765.xml')
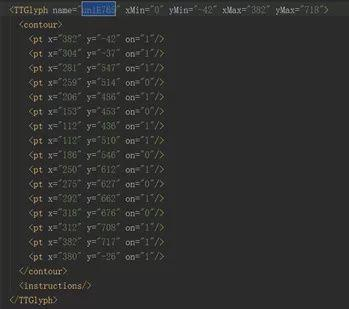
这一串代码是字形坐标,浏览器就是根据这个字形坐标翻译出我们能够识别的汉字:1
同样的思路,我们再去解析unif0d5的值,得到如下图:
我们惊奇的发现,这两个竟然一样,是不是所有的值对应的字形坐标都是唯一的呢,答案是肯定的,变化的只是上图name中的编码,坐标与数字之间是一对一的,所以,我们的思路来了,我们只需要找到编码所对应的字形坐标,然后想办法解析出这个字形坐标所对应的数字就可以了。
问题展示基本上清楚了,我们接下来看一下怎么自动化解决上面两个问题:
这是在excel里面画的,大家可以只关注内容,忽略掉背景线。
首先:我们从页面上获取到文字编码和woff文件,注意,这里的字形编码和woff文件一定要一起获取,因为每个编码对应一个woff文件,一旦刷新页面,编码在woff文件中的对应关系就会变化,找不到对应的字形坐标。
data = etree.HTML(response.text) title = data.xpath('//*[@id="shop-all-list"]/ul/li[1]/div[2]/div[2]/a[1]/b/svgmtsi[1]/text()') print(title)
其次:我们把字形编码转化成uni开头的编码,并获取到woff文件中的字形坐标。
from fontTools.ttLib import TTFont font = TTFont('f0d5.woff') coordinate = font['glyf']['uniF0D5'].coordinates print(coordinate)
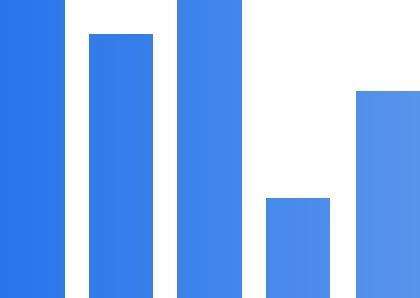
第三:用matplotlib解析这一坐标,并保存成图片。
#!/usr/bin/env python # _*_ UTF-8 _*_ from fontTools.ttLib import TTFont import matplotlib.pyplot as plt font = TTFont('f0d5.woff') coordinate = font['glyf']['uniF0D5'].coordinates coordinate = list(coordinate) fig, ax = plt.subplots() x = [i[0] for i in coordinate] y = [i[1] for i in coordinate] plt.fill(x, y, color="k", alpha=1) # 取消边框 for key, spine in ax.spines.items(): if key == 'right' or key == 'top' or key == 'bottom' or key == 'left': spine.set_visible(False) plt.plot(x, y) # 取消坐标: plt.axis('off') plt.savefig('uniF0D5.png') plt.show()
# 图片转化成string: try: from PIL import Image except ImportError: import Image import pytesseract captcha = Image.open(r'uniF0D5.png') print(captcha) result = pytesseract.image_to_string(captcha, lang='eng', config='--psm 6 --oem 3 -c tessedit_char_whitelist=0123456789').strip() print(result)
自此,我们的文字就可以直接识别出来了,我们就再也不需要用半自动的小米加步枪了,我们可以直接使用冲锋枪了
不过需要注意的是使用OCR解码文字需要一定的时间,耗时还是比较长的,如果经常使用这一思路,建议可以构建一个“字形坐标:文字”的数据库表,下次使用时解析出字形坐标,直接到数据库里匹配对应的文字就可以了。
- [Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息
[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息 2018-07-21 23:53:02 larger5 阅读数 4123更多 分类专栏: 网络爬虫 版权声明: ...
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下) 自动使用cookie的方法,告别手动拷贝cookie http模块包含一些关于cookie的模块,通过他们我们可以自动的使用co ...
- Python爬虫实战(2):爬取京东商品列表
1,引言 在上一篇<Python爬虫实战:爬取Drupal论坛帖子列表>,爬取了一个用Drupal做的论坛,是静态页面,抓取比较容易,即使直接解析html源文件都可以抓取到需要的内容.相反 ...
- Python爬虫教程-12-爬虫使用cookie爬取登录后的页面(人人网)(上)
Python爬虫教程-12-爬虫使用cookie(上) 爬虫关于cookie和session,由于http协议无记忆性,比如说登录淘宝网站的浏览记录,下次打开是不能直接记忆下来的,后来就有了cooki ...
- Python爬虫个人记录(三)爬取妹子图
这此教程可能会比较简洁,具体细节可参考我的第一篇教程: Python爬虫个人记录(一)豆瓣250 Python爬虫个人记录(二)fishc爬虫 一.目的分析 获取煎蛋妹子图并下载 http://jan ...
- 爬虫--反爬--css反爬---大众点评爬虫
大众点评爬虫分析,,大众点评 的爬虫价格利用css的矢量图偏移,进行加密 只要拦截了css 解析以后再写即可 # -*- coding: utf- -*- """ Cre ...
- Python爬虫学习笔记——防豆瓣反爬虫
开始慢慢测试爬虫以后会发现IP老被封,原因应该就是单位时间里面访问次数过多,虽然最简单的方法就是降低访问频率,但是又不想降低访问频率怎么办呢?查了一下最简单的方法就是使用转轮代理IP,网上找了一些方法 ...
- Python爬虫入门教程: 27270图片爬取
今天继续爬取一个网站,http://www.27270.com/ent/meinvtupian/ 这个网站具备反爬,so我们下载的代码有些地方处理的也不是很到位,大家重点学习思路,有啥建议可以在评论的 ...
- python爬虫(三) 用request爬取拉勾网职位信息
request.Request类 如果想要在请求的时候添加一个请求头(增加请求头的原因是,如果不加请求头,那么在我们爬取得时候,可能会被限制),那么就必须使用request.Request类来实现,比 ...
- Python爬虫入门教程 6-100 蜂鸟网图片爬取之一
1. 蜂鸟网图片--简介 国庆假日结束了,新的工作又开始了,今天我们继续爬取一个网站,这个网站为 http://image.fengniao.com/ ,蜂鸟一个摄影大牛聚集的地方,本教程请用来学习, ...
随机推荐
- Jedis & spring-data-redis
当我们了解了redis的五大数据类型,手动去敲一敲每个数据类型对应的命令,无论是再来看jedis,还是spring-data-redis都是很轻松的,他们提供的API都是基于原生的redis命令,可读 ...
- javaWeb核心技术第十二篇之分页和条件
分页:limit ?,? 参数1 : startIndex 开始索引. 参数2 : pageSize 每页显示的个数 n 表示第几页 给定一个特殊的单词 pageNumber select * fro ...
- WinForms项目升级.Net Core 3.0之后,没有WinForm设计器?
目录 .NET Conf 2019 Window Forms 设计器 .NET Conf 2019 2019 9.23-9.25召开了 .NET Conf 2019 大会,大会宣布了 .Net Cor ...
- JVM从入门开始深入每一个底层细节
1 官网 1.1 寻找JDK文档过程 www.oracle.com -> 右下角Product Documentation -> 往下拉选择Java -> Java SE docum ...
- oracle产销存的写法
with TEMP as (select sum(MMT.TRANSACTION_QUANTITY) QTY_QC, MMT.INVENTORY_ITEM_ID --,CAH.Legal_Entity ...
- Java实现命令行中的进度条功能
前言 最近在写一个命令行中的下载工具,既然是下载文件用的,那么实时显示下载进度是非常有必要的.因此,就有了这里对进度条的实现尝试. 预览图 还是先预览下效果图吧. 这里是cmd里面的效果,总体看着还行 ...
- Python xlwt 写Excel相关操作记录
1.安装xlwt pip install xlwt 2.写Excel必要的几步 import xlwt book = xlwt.Workbook() #创建一个workbook,无编码设置编码book ...
- 个人的一点小愚见,java有什么优点和缺点
java是一种面向对象的编程语言,优点是可移植性比较高,最初设计时就是本着一次编写到处执行设计的.可以开发各种应用程序和游戏,不过速度没有c++快,所以一般是不用java来编写应用程序和电脑游戏. j ...
- SSL握手中win xp和SNI的那点事
SSL握手中win xp和SNI的那点事 一.背景需求server1-3使用不同的域名对外提供https服务,用nginx作为前端负载均衡器并负责https集中解密工作(以用户访问的域名为依据进行流量 ...
- WebScraper for Mac(网站数据抓取软件) 4.10.2
WebScraper Mac版是一款Mac平台上通过使用将数据导出为JSON或CSV的简约应用程序,WebScraper Mac版可以快速提取与某个网页(包括文本内容)相关的信息.WebScraper ...