[Spark] 08 - Structured Streaming
基本了解
响应更快,对过去的架构进行了全新的设计和处理。
核心思想:将实时数据流视为一张正在不断添加数据的表,参见Spark SQL's DataFrame。
一、微批处理(默认)
写日志操作 保证一致性。
因为要写入日志操作,每次进行微批处理之前,都要先把当前批处理的数据的偏移量要先写到日志里面去。
如此,就带来了微小的延迟。
数据到达 和 得到处理 并输出结果 之间的延时超过100毫秒。
二、持续批处理
例如:"欺诈检测",在100ms之内判断盗刷行为,并给予制止。
因为 “异步” 写入日志,所以导致:至少处理一次,不能保证“仅被处理一次”。
Spark SQL 只能处理静态处理。
Structured Streaming 可以处理数据流。
三、与spark streaming的区别
过去的方式,如下。Structured Streaming则采用统一的 spark.readStream.format()。
lines = ssc.textFileStream('file:///usr/local/spark/mycode/streaming/logfile') # <---- 这是文件夹!
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
inputStream = ssc.queueStream(rddQueue)
Structured Streaming 编程
一、基本步骤
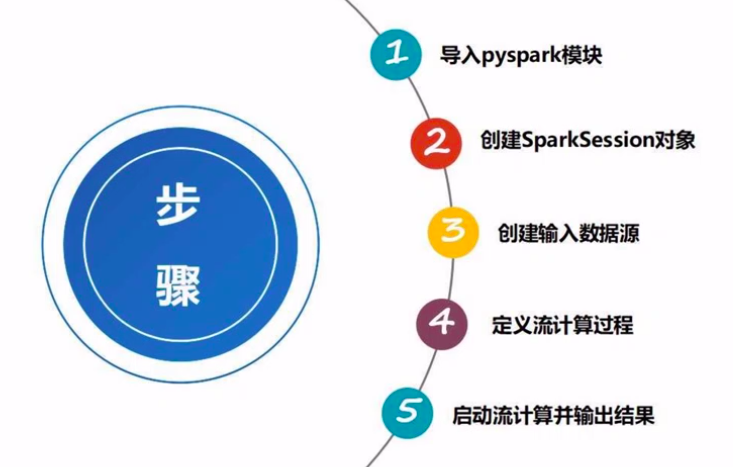
二、demo 示范
代码展示
统计每个单词出现的频率。
from pyspark.sql import SparkSession
from pyspark.sql.functions import split
from pyspark.sql.functions import explode if __name__ == "__main__":
spark = SparkSession.builder.appName("StructuredNetworkWordCount").getOrCreate()
spark.sparkContext.setLogLevel('WARN')
# 创建一个输入数据源,类似"套接子流",只是“类似”。
lines = spark.readStream.format("socket").option("host”, “localhost").option("port", 9999).load()
# Explode得到一个DataFrame,一个单词变为一行;
# 再给DataFrame这列的title设置为 "word";
# 根据word这一列进行分组词频统计,得到“每个单词到底出现了几次。
words = lines.select( explode( split( lines.value, " " ) ).alias("word") )
wordCounts = words.groupBy("word").count() # <--- 得到结果
# 启动流计算并输出结果
query = wordCounts.writeStream.outputMode("complete").format("console").trigger(processingTime="8 seconds").start()
query.awaitTermination()
程序要依赖于Hadoop HDFS。
$ cd /usr/local/hadoop
$ sbin/start-dfs.sh
新建”数据源“终端
$ nc -lk 9999
新建”流计算“终端
$ /usr/local/spark/bin/spark-submit StructuredNetworkWordCount.py
输入源
一、File 输入源
(1) 创建程序生成JSON格式的File源测试数据
例如,对Json格式文件进行内容统计。目录下面有1000 json files,格式如下:

(2) 创建程序对数据进行统计
import os
import shutil
from pprint import pprint from pyspark.sql import SparkSession
from pyspark.sql.functions import window, asc
from pyspark.sql.types import StructType, StructField
from pyspark.sql.types import TimestampType, StringType TEST_DATA_DIR_SPARK = 'file:///tmp/testdata/' if __name__ == "__main__": # 定义模式
schema = StructType([
StructField("eventTime" TimestampType(), True),
StructField("action", StringType(), True),
StructField("district", StringType(), True) ]) spark = SparkSession.builder.appName("StructuredEMallPurchaseCount").getOrCreate()
spark.sparkContext.setLogLevel("WARN") lines = spark.readStream.format("json").schema(schema).option("maxFilesPerTrigger", 100).load(TEST_DATA_DIR_SPARK) # 定义窗口
windowDuration = '1 minutes'
windowedCounts = lines.filter("action = 'purchase'") \
.groupBy('district', window('eventTime', windowDuration)) \
.count() \
.sort(asc('window''))
# 启动流计算
query = windowedCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.option('truncate', 'false') \
.trigger(processingTime = "10 seconds") \ # 每隔10秒,执行一次流计算
.start() query.awaitTermination()
(3) 测试运行程序
a. 启动 HDFS
$ cd /usr/local/hadoop
$ sbin/start-dfs.sh
b. 运行数据统计程序
/usr/local/spark/bin/spark-submit spark_ss_filesource.py
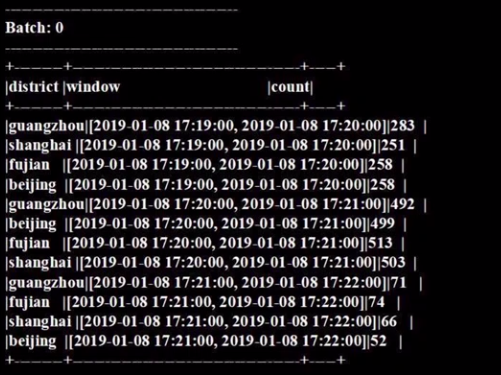
c. 运行结果
二、Socket源和 Rate源
(因为只能r&d,不能生产时间,故,这里暂时略)
一般不用于生产模式,实验测试模式倒是可以。
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("TestRateStreamSource").getOrCreate()
spark.sparkContext.setLogLevel('WARN')
紧接着是下面的程序:

# 每秒钟发送五行,属于rate源;
# query 代表了流计算启动模式;
运行程序
$ /usr/local/spark/bin/spark-submit spark_ss_rate.py
输出操作
一、启动流计算
writeStream()方法将会返回DataStreamWrite接口。
query = wordCounts.writeStream.outputMode("complete").format("console").trigger(processingTime="8 seconds").start()

输出 outputMode 模式

接收器 format 类型
系统内置的输出接收器包括:File, Kafka, Foreach, Console (debug), Memory (debug), etc。
生成parquet文件
可以考虑读取后转化为DataFrame;或者使用strings查看文件内容。
代码展示:StructuredNetworkWordCountFileSink.py
from pyspark.sql import SparkSession
from pyspark.sql.functions import split
from pyspark.sql.functions import explode
from pyspark.sql.functions import length

只要长度为5的dataframe,也就是单词长度都是5。

"数据源" 终端
# input string to simulate stream.
nc -lk 9999
"流计算" 终端
/usr/local/spark/bin/spark-submit StructuredNetworkWordCountFileSink.py
End.
[Spark] 08 - Structured Streaming的更多相关文章
- Spark之Structured Streaming
目录 Part V. Streaming Stream Processing Fundamentals Structured Streaming Basics Event-Time and State ...
- Structured Streaming Programming Guide结构化流编程指南
目录 Overview Quick Example Programming Model Basic Concepts Handling Event-time and Late Data Fault T ...
- Structured Streaming编程 Programming Guide
Structured Streaming编程 Programming Guide Overview Quick Example Programming Model Basic Concepts Han ...
- Spark Streaming揭秘 Day29 深入理解Spark2.x中的Structured Streaming
Spark Streaming揭秘 Day29 深入理解Spark2.x中的Structured Streaming 在Spark2.x中,Spark Streaming获得了比较全面的升级,称为St ...
- Spark Structured streaming框架(1)之基本使用
Spark Struntured Streaming是Spark 2.1.0版本后新增加的流计算引擎,本博将通过几篇博文详细介绍这个框架.这篇是介绍Spark Structured Streamin ...
- Spark Structured Streaming框架(2)之数据输入源详解
Spark Structured Streaming目前的2.1.0版本只支持输入源:File.kafka和socket. 1. Socket Socket方式是最简单的数据输入源,如Quick ex ...
- Spark2.3(四十二):Spark Streaming和Spark Structured Streaming更新broadcast总结(二)
本次此时是在SPARK2,3 structured streaming下测试,不过这种方案,在spark2.2 structured streaming下应该也可行(请自行测试).以下是我测试结果: ...
- Spark2.2(三十三):Spark Streaming和Spark Structured Streaming更新broadcast总结(一)
背景: 需要在spark2.2.0更新broadcast中的内容,网上也搜索了不少文章,都在讲解spark streaming中如何更新,但没有spark structured streaming更新 ...
- Spark2.2(三十八):Spark Structured Streaming2.4之前版本使用agg和dropduplication消耗内存比较多的问题(Memory issue with spark structured streaming)调研
在spark中<Memory usage of state in Spark Structured Streaming>讲解Spark内存分配情况,以及提到了HDFSBackedState ...
随机推荐
- 纯 CSS 实现绘制各种三角形(各种角度)
一.前言 三角形实现原理:宽度width为0:height为0:(1)有一条横竖边(上下左右)的设置为border-方向:长度 solid red,这个画的就是底部的直线.其他边使用border-方向 ...
- ajax提交的问题点记录
原始方式是这样的: var prId = $("#prId").val(); var prNumber = $("#prNumber").val(); var ...
- spring security中@PreAuthorize注解的使用
添加依赖<!-- oauth --><dependency> <groupId>org.springframework.cloud</groupId> ...
- DNS域名解析服务及其配置
一.背景 到 20 世纪 70 年代末,ARPAnet 是一个拥有几百台主机的很小很友好的网络.仅需要一个名为 HOSTS.TXT 的文件就能容纳所有需要了解的主机信息:它包含了所有连接到 ARPAn ...
- CRNN+CTC (基于CTPN 的end-to-end OCR)
1. https://zhuanlan.zhihu.com/p/43534801 (详细原理) 2. https://blog.csdn.net/forest_world/article/detai ...
- 三维动画形变算法(Gradient-Based Deformation)
将三角网格上的顶点坐标(x,y,z)看作3个独立的标量场,那么网格上每个三角片都存在3个独立的梯度场.该梯度场是网格的微分属性,相当于网格的特征,在形变过程中随控制点集的移动而变化.那么当用户拖拽网格 ...
- 去掉input框的数字箭头
input::-webkit-outer-spin-button,input::-webkit-inner-spin-button { -webkit-appearance: none;}input[ ...
- Libs - 颜色生成网站
介绍几个免费常用的颜色生成网站: 如下 对比色邻近色配色方案 http://www.peise.net/tools/web/ 渐变色方案 https://webgradients.com/ 随机搭配5 ...
- 洛谷P1217回文质数-Prime Palindrome回溯
P1217 [USACO1.5]回文质数 Prime Palindromes 题意:给定一个区间,输出其中的回文质数: 学习了洛谷大佬的回溯写法,感觉自己写回溯的能力不是很强: #include &l ...
- POJ 2643 Election map
POJ 2643 Election 第一次写博客,想通过写博客记录自己的ACM历程,也想解释下英文题目,写些自己的理解.也可以让自己以后找题目更加方便点嘛.ElectionTime Limit: 10 ...