图像识别sift+bow+svm
本文概述
利用SIFT特征进行简单的花朵识别
SIFT算法的特点有:
- SIFT特征是图像的局部特征,其对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性;
- SIFT算法提取的图像特征点数不是固定值,维度是统一的128维。
- 独特性(Distinctiveness)好,信息量丰富,适用于在海量特征数据库中进行快速、准确的匹配;
- 多量性,即使少数的几个物体也可以产生大量的SIFT特征向量;
- 高速性,经优化的SIFT匹配算法甚至可以达到实时的要求;
- 可扩展性,可以很方便的与其他形式的特征向量进行联合。
KMeans聚类获得视觉单词,构建视觉单词词典
现在得到的是所有图像的128维特征,每个图像的特征点数目还不一定相同(大多有差异)。现在要做的是构建一个描述图像的特征向量,也就是将每一张图像的特征点转换为特征向量。这儿用到了词袋模型,词袋模型源自文本处理,在这儿用在图像上,本质上是一样的。词袋的本质就是用一个袋子将所有维度的特征装起来,在这儿,词袋模型的维度需要我们手动指定,这个维度也就确定了视觉单词的聚类中心数。
将图像特征点映射到视觉单词上,得到图像的特征向量:
熟悉聚类算法的同学已经明白了,上面讲的簇就是通过聚类算法得到的,聚类算法将类别相近,属性相似的样本框起来,是一种无监督学习算法。在本文中,我使用了Kmeans算法来聚类得到视觉单词,通过聚类得到了聚类中心,通过聚类得到了表征词袋的特征点。
我们得到k个聚类中心(一个聚类中心表征了一个维度特征,k由自己手动设置)和先前SIFT得到的所有图片的特征点,现在就是要通过这两项来构造每一张图像的特征向量。
在本文中,构造的思路跟简单,就是比对特征点与所有聚类中心的距离,将特征点分配到距离最近的特征项,比如经计算某特征点距离leg这个聚类中心最近,那么这个图像中leg这个特征项+1。以此类推,每一张图像特征向量也就构造完毕。
pickle读取文件
pickle可以存储什么类型的数据呢?
所有python支持的原生类型:布尔值,整数,浮点数,复数,字符串,字节,None。
由任何原生类型组成的列表,元组,字典和集合。
函数,类,类的实例
pickle模块中常用的方法有:
1.pickle.dump(obj, file, protocol=None,)
必填参数obj表示将要封装的对象
必填参数file表示obj要写入的文件对象,file必须以二进制可写模式打开,即“wb”
可选参数protocol表示告知pickler使用的协议,支持的协议有0,1,2,3,默认的协议是添加在Python 3中的协议3
2.pickle.load(file,*,fix_imports=True,encoding="ASCII", errors="strict")
必填参数file必须以二进制可读模式打开,即“rb”,其他都为可选参数
支持向量机
支持向量机的两个参数(调参增大准确率)
SVM模型有两个非常重要的参数C与gamma。其中 C是惩罚系数,即对误差的宽容度。c越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差
gamma是选择RBF函数作为kernel后,该函数自带的一个参数。隐含地决定了数据映射到新的特征空间后的分布,gamma越大,支持向量越少,gamma值越小,支持向量越多。支持向量的个数影响训练与预测的速度。
此外大家注意RBF公式里面的sigma和gamma的关系如下:

这里面大家需要注意的就是gamma的物理意义,大家提到很多的RBF的幅宽,它会影响每个支持向量对应的高斯的作用范围,从而影响泛化性能。我的理解:如果gamma设的太大,会很小,很小的高斯分布长得又高又瘦, 会造成只会作用于支持向量样本附近,对于未知样本分类效果很差,存在训练准确率可以很高,(如果让无穷小,则理论上,高斯核的SVM可以拟合任何非线性数据,但容易过拟合)而测试准确率不高的可能,就是通常说的过训练;而如果设的过小,则会造成平滑效应太大,无法在训练集上得到特别高的准确率,也会影响测试集的准确率。
算法流程:
SIFT提取每幅图像的特征点:
import csv
import os
from sklearn.cluster import KMeans
import cv2
import numpy as np def knn_detect(file_list,cluster_nums, randomState = None):
content = []
input_x = []
labels=[]
features = []
count = 0
csv_file = csv.reader(open(file_list,'r'))
#读取csv文件
for line in csv_file:
if(line[2] !='label'):
subroot = 'F:\\train\\g' + str(line[2])
#路径拼接成绝对路径
filename =os.path.join(subroot, line[1])
sift = cv2.xfeatures2d.SIFT_create(200)
img = cv2.imdecode(np.fromfile(filename,dtype=np.uint8),-1)
#用np读图像,避免了opencv读取图像失败的问题
if img is not None: gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
kpG, desG = sift.detectAndCompute(gray, None)
#关键点描述符 if desG is None:
#关键点不存在就结束循环
continue
print(count)
count+=1
ll = np.array(line[2]).flatten()
labels.append(ll)
#得到标签
features.append(desG)
#得到图像的特征矩阵
input_x.extend(desG)
print(len(input_x))
return features,labels,input_x #训练集图片处理
des_list = []
labelG = []
input_x1 = []
des_list,labelG,input_x1 = knn_detect('E:\\py\\train.csv',50)
#测试机图片处理
festures_test = []
labels_test = []
input_x2 = []
features_test,labels_test,input_x2 = knn_detect('E:\\py\\test.csv',50)
结果截图:

保存中间变量:
#利用pickle保存中间变量
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import pickle output = open('input_x2.pkl', 'wb')
pickle.dump(input_x2, output)
output.close() output = open('features_test.pkl', 'wb')
pickle.dump(features_test, output)
output.close() output = open('labels_test.pkl', 'wb')
pickle.dump(labels_test, output)
output.close() output = open('input_x22.pkl', 'wb')
pickle.dump(input_x2, output,protocol=2)
output.close()
将图像特征点映射到视觉单词上,得到图像特征:
df=open('input_x2.pkl','rb')#注意此处是rb
#此处使用的是load(目标文件)
input_x1=pickle.load(df)
df.close()
kmeans = KMeans(n_clusters = 50, n_jobs =4,random_state = None).fit(input_x1)
#开四个线程加快计算
centers = kmeans.cluster_centers_
将图像特征点映射到视觉单词上,得到图像的特征向量:
def des2feature(des,num_words,centures):
'''
des:单幅图像的SIFT特征描述
num_words:视觉单词数/聚类中心数
centures:聚类中心坐标
计算特征矩阵中特征点离聚类中心最近的加1
return: feature vector 1*num_words
'''
img_feature_vec=np.zeros([num_words])
for fi in des:
diffMat = np.tile(fi, (50, 1)) - centers
sqSum = (diffMat**2).sum(axis=1)
dist = sqSum**0.5
sortedIndices = dist.argsort()
idx = sortedIndices[0] # index of the nearest center
#排序得到距离最近的聚类中心坐标的索引
img_feature_vec[idx] += 1
return img_feature_vec def get_all_features(des_list,num_words):
# 获取所有图片的特征向量
allvec=np.zeros((len(des_list),num_words),'float32')
for i in range(len(des_list)):
if des_list[i].any()!=None:
allvec[i]=des2feature(centures=centers,des=des_list[i],num_words=num_words)
return allvec df=open('des_list.pkl','rb')#注意此处是rb
#此处使用的是load(目标文件)
des_list=pickle.load(df)
df.close()
a =get_all_features(des_list,50)
print(len(a))
output = open('特征向量.pkl', 'wb')
pickle.dump(a, output)
output.close()
svm训练,查看准确率:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import pickle
from sklearn.preprocessing import StandardScaler
df=open('label_train.pkl','rb')#注意此处是rb
#此处使用的是load(目标文件)
label_train=pickle.load(df)
df.close()
df=open('label_test.pkl','rb')#注意此处是rb
#此处使用的是load(目标文件)
label_test =pickle.load(df)
df.close()
sc = StandardScaler()
X_train = sc.fit_transform(a)
X_test = sc.fit_transform(b) from sklearn.svm import SVC
classifier = SVC(C=15)
#适当调整参数,不是一个固定值
classifier.fit(X_train,label_train) y_pred = classifier.predict(X_test) print(classifier.score(X_train,label_train))
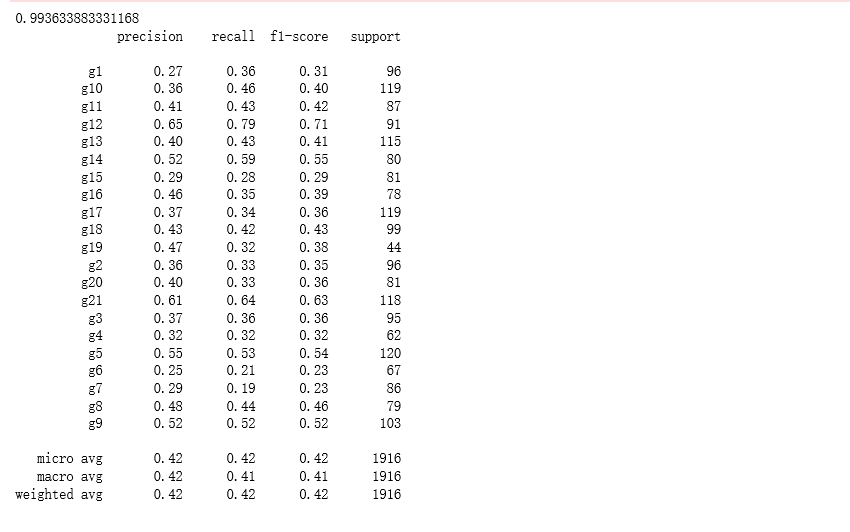
from sklearn.metrics import classification_report
print(classification_report(label_test,y_pred))
结果截图:
图像识别sift+bow+svm的更多相关文章
- 汽车检测SIFT+BOW+SVM
项目来源于 <opencv 3计算机视觉 python语言实现> 整个执行过程如下: 1)获取一个训练数据集. 2)创建BOW训练器并获得视觉词汇. 3)采用词汇训练SVM. 4)尝试对测 ...
- 第十九节、基于传统图像处理的目标检测与识别(词袋模型BOW+SVM附代码)
在上一节.我们已经介绍了使用HOG和SVM实现目标检测和识别,这一节我们将介绍使用词袋模型BOW和SVM实现目标检测和识别. 一 词袋介绍 词袋模型(Bag-Of-Word)的概念最初不是针对计算机视 ...
- BoW(SIFT/SURF/...)+SVM/KNN的OpenCV 实现
本文转载了文章(沈阳的博客),目的在于记录自己重复过程中遇到的问题,和更多的人分享讨论. 程序包:猛戳我 物体分类 物体分类是计算机视觉中一个很有意思的问题,有一些已经归类好的图片作为输入,对一些未知 ...
- SIFT+BOW 实现图像检索
原文地址:https://blog.csdn.net/silence2015/article/details/77374910 本文概述 图像检索是图像研究领域中一个重要的话题,广泛应用于医学,电子商 ...
- py4CV例子2汽车检测和svm算法
1.什么是汽车检测数据集: ) pos, neg = , ) matcher = cv2.FlannBasedMatcher(flann_params, {}) bow_kmeans_trainer ...
- Bag of Words/Bag of Features的Matlab源码发布
2010年11月19日 ⁄ 技术, 科研 ⁄ 共 1296字 ⁄ 评论数 26 ⁄ 被围观 4,150 阅读+ 由于自己以前发过一篇文章讲bow特征的matlab代码的优化的<Bag-Of-Wo ...
- OpenCV 学习笔记 07 目标检测与识别
目标检测与识别是计算机视觉中最常见的挑战之一.属于高级主题. 本章节将扩展目标检测的概念,首先探讨人脸识别技术,然后将该技术应用到显示生活中的各种目标检测. 1 目标检测与识别技术 为了与OpenCV ...
- Bag of word based image retrieval
主要参考维基百科Bag of Word 在DLP领域里,bow(bag of word)是一个稀疏的向量,向量的每个元素记录词的出现次数,相当于对每篇文章都关于词典做词的直方图统计.同样的道理用在co ...
- Bag of Features (BOF)图像检索算法
1.首先.我们用surf算法生成图像库中每幅图的特征点及描写叙述符. 2.再用k-means算法对图像库中的特征点进行训练,生成类心. 3.生成每幅图像的BOF.详细方法为:推断图像的每一个特征点与哪 ...
随机推荐
- Android零基础入门第44节:ListView数据动态更新
原文:Android零基础入门第44节:ListView数据动态更新 经过前面几期的学习,关于ListView的一些基本用法大概学的差不多了,但是你可能发现了,所有ListView里面要填充的数据都是 ...
- Docker笔记02-日志平台ELK搭建
OS: Centos7 准备工作: 虚拟机中安装Centos, 搭建Docker环境 ELK简介: 略 文档地址 https://elk-docker.readthedocs.io/ 需要注意的是在B ...
- Tensorflow数据读取机制
展示如何将数据输入到计算图中 Dataset可以看作是相同类型"元素"的有序列表,在实际使用时,单个元素可以是向量.字符串.图片甚至是tuple或dict. 数据集对象实例化: d ...
- xgboost参数及调参
常规参数General Parameters booster[default=gbtree]:选择基分类器,可以是:gbtree,gblinear或者dart.gbtree和draf基于树模型,而gb ...
- windows 下 php 实现在线预览附件(pdf)
(写的有点啰嗦,具体的实现方法只是粗体和代码就够了) 给市场部门用dede做个cms,需要附件在线查看.公司有个系统(就叫develop_cms吧)是已经实现的,本以为很容易,不过是下一个插件然后把附 ...
- Windows下搭建go语言开发环境 以及 开发IDE (附下载链接)
1.下载 并且 安装 Go安装包 =========================================================== 在CSDN上传了我的版本,供大家下载: = ...
- 转一个git的命令
Git远程操作详解 Git有很多优势,其中之一就是远程操作非常简便.本文详细介绍5个Git命令,它们的概念和用法,理解了这些内容,你就会完全掌握Git远程操作. git clone git rem ...
- PHP调用语音合成接口
百度TTS 语音合成 //百度文件转换成语音 private function toSpeech($text) { define('DEMO_CURL_VERBOSE', false); $obj=[ ...
- SYN591型 多功能数字面板表
SYN591型 多功能数字面板表 多功能数字面板表数字面板表使用说明视频链接: http://www.syn029.com/h-pd-248-0_310_44_-1.html 请将此链接复制到浏 ...
- 再说Java集合,subList之于ArrayList
上一章说了很多ArrayList相关的内容,但还有一块儿内容没说到,那就是subList方法.先看一段代码 public static void testSubList() { List<Str ...