Java微服务(二):负载均衡、序列化、熔断
本文接着上一篇写的《Java微服务(二):服务消费者与提供者搭建》,上一篇文章主要讲述了消费者与服务者的搭建与简单的实现。其中重点需要注意配置文件中的几个坑。
本章节介绍一些零散的内容:服务的负载均衡,序列化和熔断
1.服务负载均衡
负载均衡可分为软件负载均衡和硬件负载均衡。在我们日常开发中,一般很难接触到硬件负载均衡。但软件负载均衡还是可以接触到的,比如 Nginx。dubbo提供的也是软负载。
详细内容可以阅读dubbo官网关于负载均衡的介绍,这里总结下负载均衡的方式:
- 权重随机算法的 RandomLoadBalance
RandomLoadBalance 是加权随机算法的具体实现,它的算法思想很简单。假设我们有一组服务器 servers = [A, B, C],他们对应的权重为 weights = [5, 3, 2],权重总和为10。那么就有5/10的请求达到A服务器上,3/10和2/10分别达到B和C上。只要随机数生成器产生的随机数分布性很好,在经过多次选择后,每个服务器被选中的次数比例接近其权重比例。当调用次数比较少时,Random 产生的随机数可能会比较集中,此时多数请求会落到同一台服务器上。
- 最少活跃调用数算法的 LeastActiveLoadBalance
每个服务提供者对应一个活跃数 active。初始情况下,所有服务提供者活跃数均为0。每收到一个请求,活跃数加1,完成请求后则将活跃数减1,在服务运行一段时间后,性能好的服务提供者处理请求的速度更快,因此活跃数下降的也越快,此时这样的服务提供者能够优先获取到新的服务请求、这就是最小活跃数负载均衡算法的基本思想,目前此算法还引入了权重值。
- 基于 hash 一致性的 ConsistentHashLoadBalance
首先根据 ip 或者其他的信息为缓存节点生成一个 hash,并将这个 hash 投射到 [0, 232 - 1] 的圆环上。当有查询或写入请求时,则为缓存项的 key 生成一个 hash 值。然后查找第一个大于或等于该 hash 值的缓存节点,并到这个节点中查询或写入缓存项。如果当前节点挂了,则在下一次查询或写入缓存时,为缓存项查找另一个大于其 hash 值的缓存节点即可。
- 基于加权轮询算法的 RoundRobinLoadBalance
所谓轮询是指将请求轮流分配给每台服务器。举个例子,我们有三台服务器 A、B、C。我们将第一个请求分配给服务器 A,第二个请求分配给服务器 B,第三个请求分配给服务器 C,第四个请求再次分配给服务器 A。这个过程就叫做轮询。轮询是一种无状态负载均衡算法,实现简单,适用于每台服务器性能相近的场景下。加权轮询是将服务器赋一个权值,然后按照该权值进行轮训。
代码构建,本例使用轮训算法做demo
直接在yml配置文件中添加loadbalance注解就可以

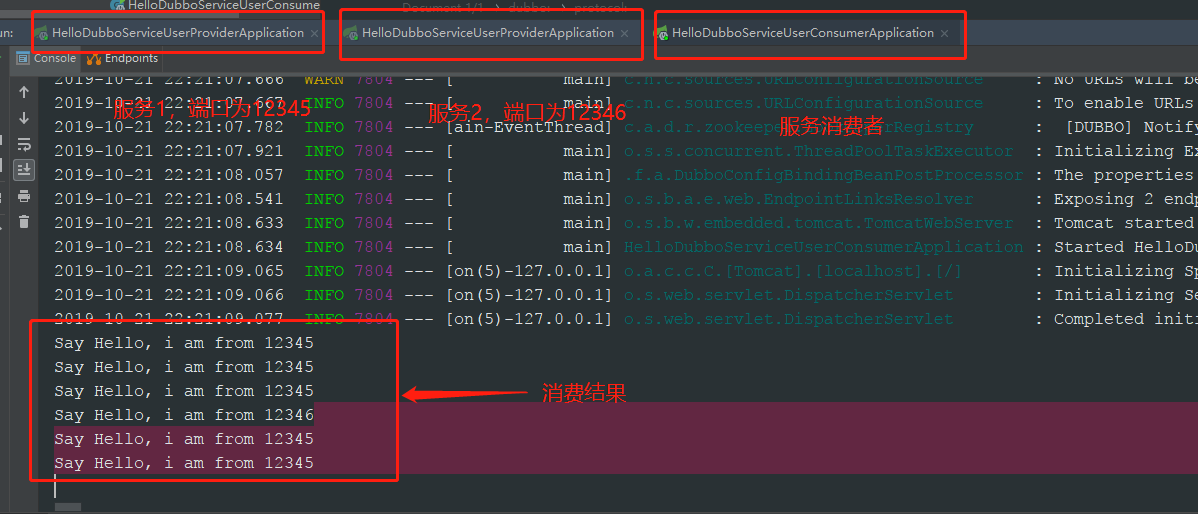
开启2个服务提供者,并且使用服务消费者消费,查看日志
2.序列化
Dubbo 中支持的序列化方式:
- dubbo 序列化:阿里尚未开发成熟的高效 java 序列化实现,阿里不建议在生产环境使用它
- hessian2 序列化:hessian 是一种跨语言的高效二进制序列化方式。但这里实际不是原生的 hessian2 序列化,而是阿里修改过的 hessian lite,它是 dubbo RPC 默认启用的序列化方式
- json 序列化:目前有两种实现,一种是采用的阿里的 fastjson 库,另一种是采用 dubbo 中自己实现的简单 json 库,但其实现都不是特别成熟,而且 json 这种文本序列化性能一般不如上面两种二进制序列化。
- java 序列化:主要是采用 JDK 自带的 Java 序列化实现,性能很不理想。
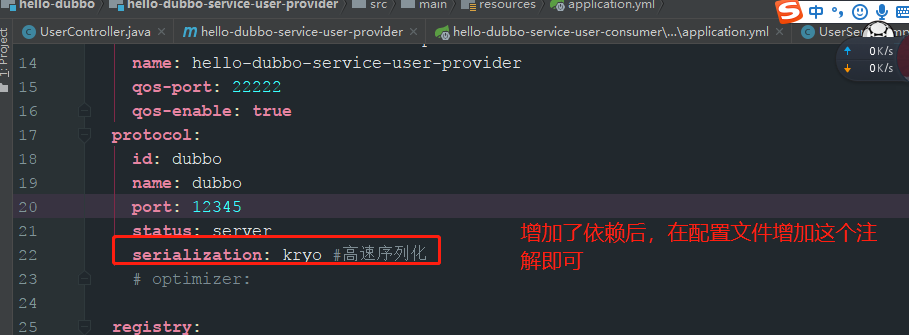
dubbo自带的序列化方式不成熟,而json和java序列化性能不理想。dubbo可以使用hessian2序列化,但是hessian2是跨语言的,没有单独对java语言做优化,所以很多单独给java提供优化的工具性能比hessian2要好。我们为 dubbo 引入 Kryo 和 FST 这两种高效 Java 序列化实现,来逐步取代 hessian2。
dubbo有关序列化的实例如下:

代码构建,首先增加依赖
<dependency>
<groupId>de.javakaffee</groupId>
<artifactId>kryo-serializers</artifactId>
<version>0.42</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-hystrix -->
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-netflix-hystrix -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
<version>2.0.1.RELEASE</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-netflix-hystrix-dashboard -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
<version>2.0.1.RELEASE</version>
</dependency>
在配置文件中增加配置的属性即可:
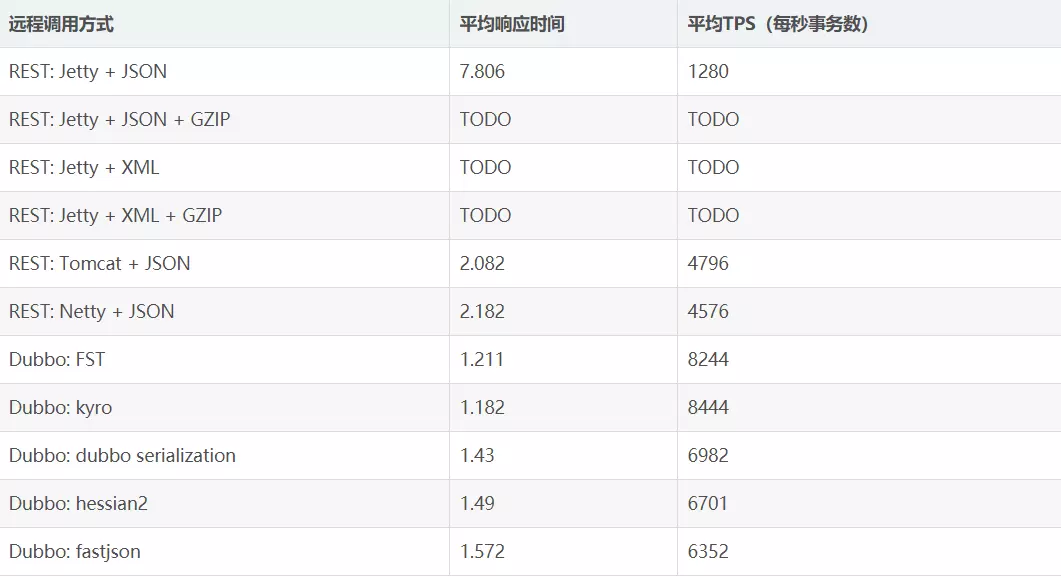
此时序列化配置完成,以下总结了常见序列化方式的性能
3.熔断
由于网络和自身的原因,RPC之间的调用并不能保证100%可用,如果服务器产生了宕机,同时又有大量的请求过来,就会出现雪崩,为了解决此问题,业界提出了熔断。熔断器打开后,为了避免连锁故障,通过 fallback 方法可以直接返回一个固定值。此时fallback中可以做很多逻辑处理,比喻日志或者邮件通过开发人员,及时对服务器进行问题排查,降低风险度。
代码构建,首先增加依赖
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-hystrix -->
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-netflix-hystrix -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
<version>2.0.1.RELEASE</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-netflix-hystrix-dashboard -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
<version>2.0.1.RELEASE</version>
</dependency>
其中第二个依赖是在熔断仪表盘中使用的。具体代码和相关解释如下如下:

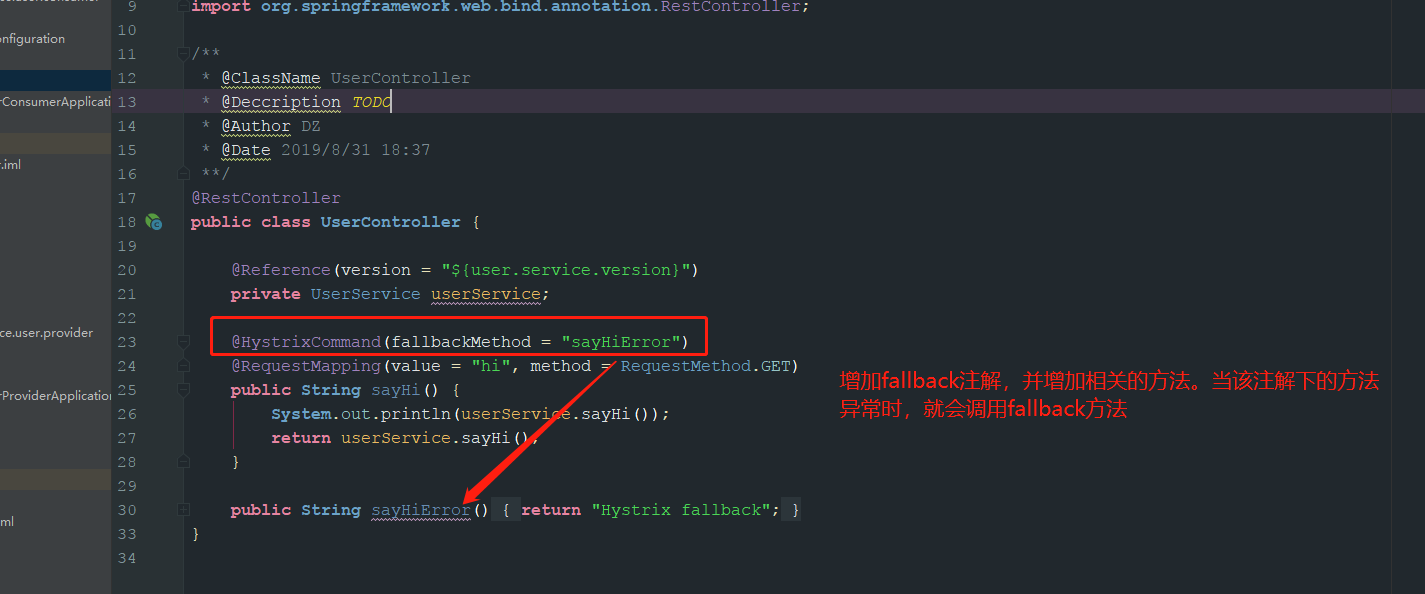
熔断仪表盘的配置,这里需要注意spring boot2和1的配置是有区别的,具体可以参考官网文档
package com.edu.hello.dubbo.service.user.consumer.config; import com.netflix.hystrix.contrib.metrics.eventstream.HystrixMetricsStreamServlet;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration; /**
* @ClassName HystrixDashboardConfiguration
* @Deccription TODO
* @Author DZ
* @Date 2019/9/3 23:10
**/
@Configuration
public class HystrixDashboardConfiguration {
@Bean
public ServletRegistrationBean getServlet() {
HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);
registrationBean.setLoadOnStartup(1);
registrationBean.addUrlMappings("/hystrix.stream");
registrationBean.setName("HystrixMetricsStreamServlet");
return registrationBean;
}
}
启动服务,查看结果。这里只启动了服务消费者,没有启动服务提供者,制造服务超时。

访问http://localhost:9090/hystrix查看熔断界面,其他详细信息可以查看详细信息,其中仪表盘的访问地址是来自于config中,仪表盘如下:
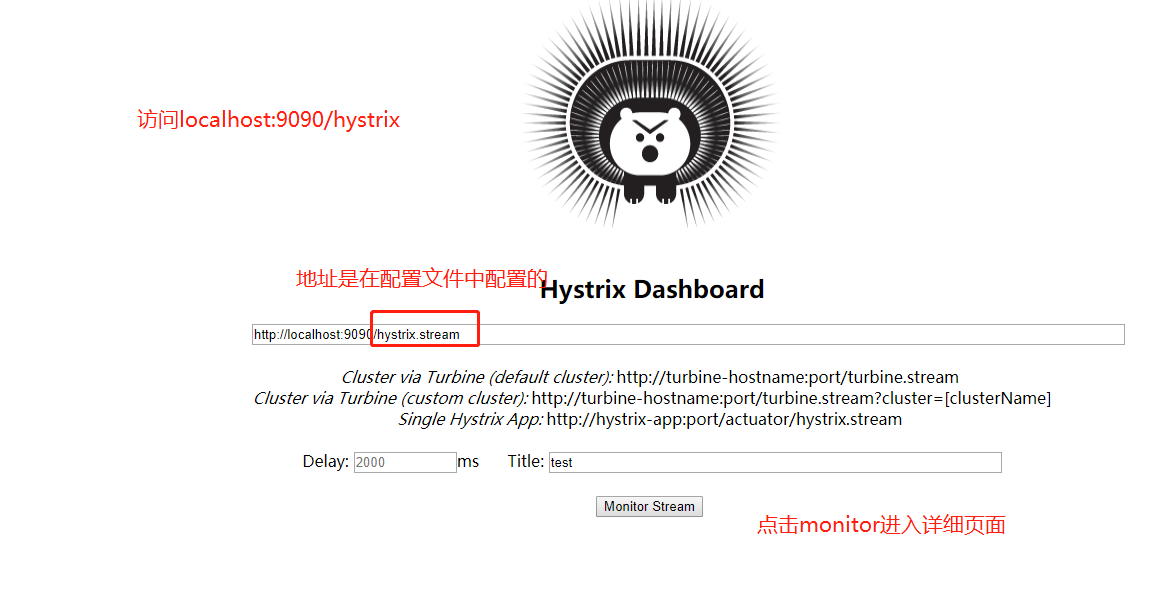
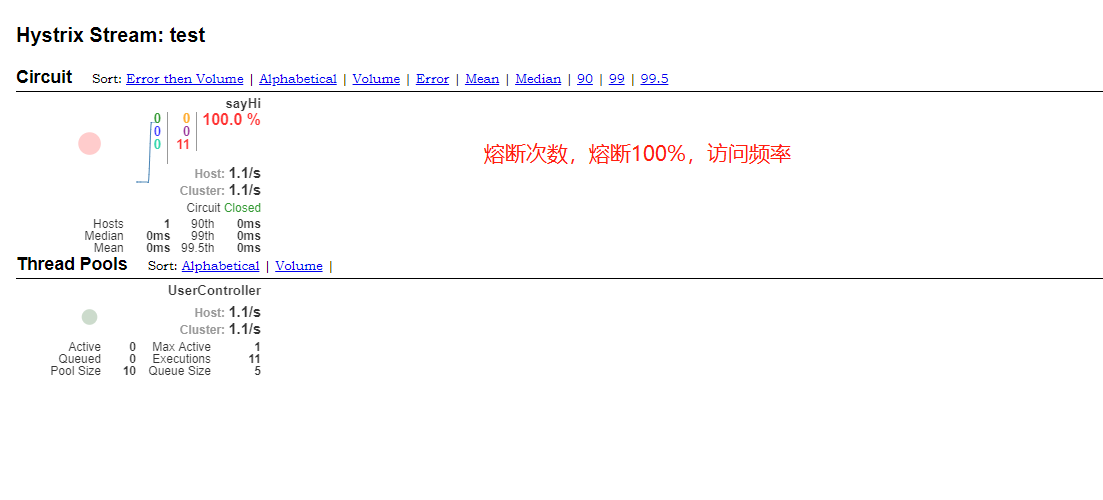
访问http://localhost:9090/hystrix.stream查看熔断仪表盘界面,更加详细查看熔断相关的信息
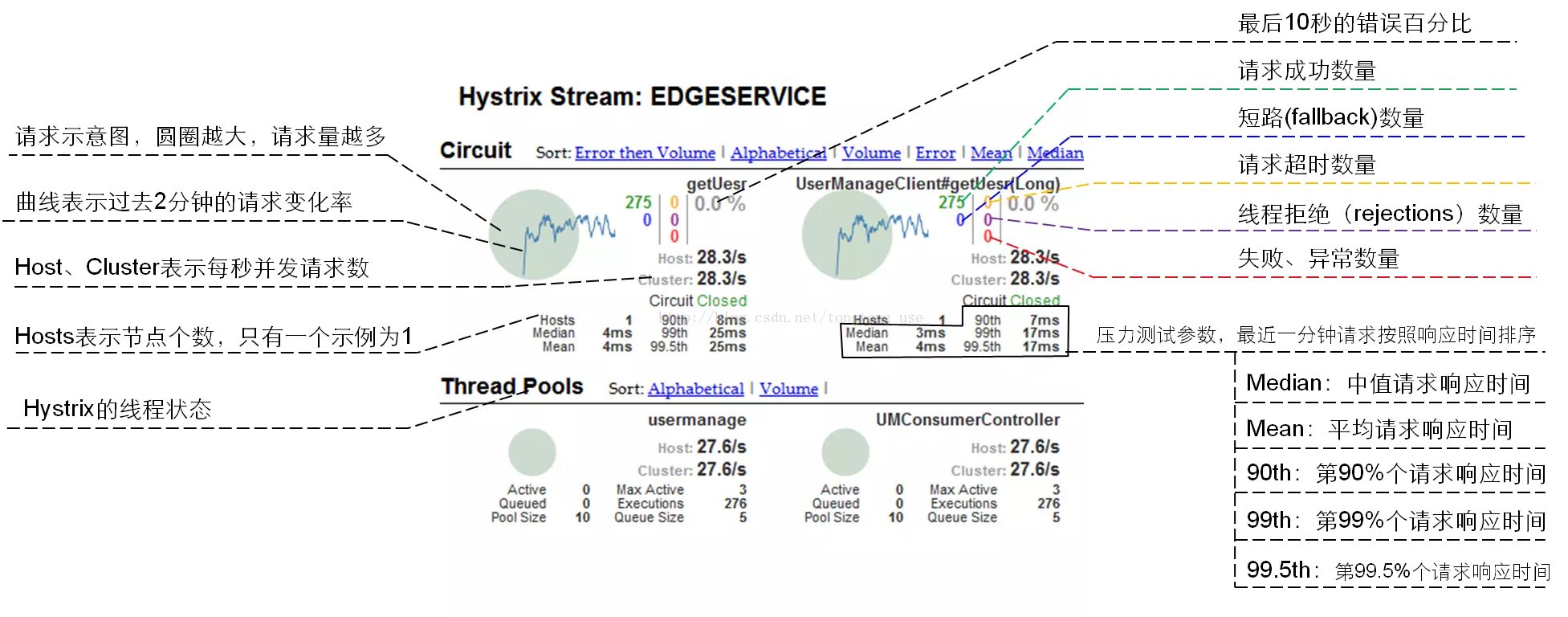
仪表盘中相关参数解释如下:
Java微服务(二):负载均衡、序列化、熔断的更多相关文章
- SpringCloud与微服务Ⅵ --- Ribbon负载均衡
一.Ribbon是什么 Sping Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的工具. 简单的说,Ribbon是Netflix发布的开源项目,主要功能是提供客户 ...
- SpringCloud与微服务Ⅶ --- Feign负载均衡
官方文档:https://projects.spring.io/spring-cloud/spring-cloud.html#spring-cloud-feign 一.Feign是什么 Feign是一 ...
- Spring Cloud微服务Ribbon负载均衡/Zuul网关使用
客户端负载均衡,当服务节点出现问题时进行调节或是在正常情况下进行 服务调度.所谓的负载均衡,就是当服务提供的数量和调用方对服务进行 取舍的调节问题,在spring cloud中是通过Ribbon来解决 ...
- Java微服务(二):服务消费者与提供者搭建
本文接着上一篇写的<Java微服务(一):dubbo-admin控制台的使用>,上篇文章介绍了docker,zookeeper环境的安装,并参考dubbo官网演示了dubbo-admin控 ...
- .net core grpc consul 实现服务注册 服务发现 负载均衡(二)
在上一篇 .net core grpc 实现通信(一) 中,我们实现的grpc通信在.net core中的可行性,但要在微服务中真正使用,还缺少 服务注册,服务发现及负载均衡等,本篇我们将在 .net ...
- .Net Core Grpc Consul 实现服务注册 服务发现 负载均衡
本文是基于..net core grpc consul 实现服务注册 服务发现 负载均衡(二)的,很多内容是直接复制过来的,..net core grpc consul 实现服务注册 服务发现 负载均 ...
- .NET Core微服务二:Ocelot API网关
.NET Core微服务一:Consul服务中心 .NET Core微服务二:Ocelot API网关 .NET Core微服务三:polly熔断与降级 本文的项目代码,在文章结尾处可以下载. 本文使 ...
- 搭建服务与负载均衡的客户端-Spring Cloud学习第二天(非原创)
文章大纲 一.Eureka中的核心概念二.Spring RestTemplate详解三.代码实战服务与负载均衡的客户端四.项目源码与参考资料下载五.参考文章 一.Eureka中的核心概念 1. 服务提 ...
- 一起来学Spring Cloud | 第三章:服务消费者 (负载均衡Ribbon)
一.负载均衡的简介: 负载均衡是高可用架构的一个关键组件,主要用来提高性能和可用性,通过负载均衡将流量分发到多个服务器,多服务器能够消除单个服务器的故障,减轻单个服务器的访问压力. 1.服务端负载均衡 ...
随机推荐
- apache ignite系列(五):分布式计算
ignite分布式计算 在ignite中,有传统的MapReduce模型的分布式计算,也有基于分布式存储的并置计算,当数据分散到不同的节点上时,根据提供的并置键,计算会传播到数据所在的节点进行计算,再 ...
- HBase WAL原理学习
1.概述 客户端往RegionServer端提交数据的时候,会写WAL日志,只有当WAL日志写成功以后,客户端才会被告诉提交数据成功,如果写WAL失败会告知客户端提交失败,换句话说这其实是一个数据落地 ...
- List<Object> 多条件去重
上一篇将到根据某一条件去重List<Object> 对象链表.本文章根据多条件去重List<Object>去重 private List<StaingMD0010> ...
- js 事件委托获取子元素下标
html:部分 <ul> <li>第一个</li> <li>第二个</li> <li>第三个</li> <li ...
- Java第二次作业第四题
文本行输入学生姓名,下来框选择课程名称,文本行输入课程成绩:点击"录入"按钮,相关信息显示在文本区:点击"统计"按钮,将所有录入的成绩的平均成绩显示在另一个文本 ...
- 由 [SDOI2012]Longge的问题 探讨欧拉函数和莫比乌斯函数的一些性质和关联
本题题解 题目传送门:https://www.luogu.org/problem/P2303 给定一个整数\(n\),求 \[ \sum_{i=1}^n \gcd(n,i) \] 蒟蒻随便yy了一下搞 ...
- Pytorch的基础数据类型
引言 本篇介绍Pytorch的基础数据类型,判断方式以及常用向量 基础数据类型 torch.Tensor是一种包含单一数据类型元素的多维矩阵. 目前在1.2版本中有9种类型. 同python相比,py ...
- 跟我学SpringCloud | 第十九章:Spring Cloud 组件 Docker 化
前面的文章<跟我学SpringCloud | 第十八篇:微服务 Docker 化之基础环境>我们介绍了基础环境系统和 JRE 的容器化,这一节我们介绍 Spring Cloud 组件的容器 ...
- ASP.NET Core 3.0 gRPC 双向流
目录 ASP.NET Core 3.0 使用gRPC ASP.NET Core 3.0 gRPC 双向流 ASP.NET Core 3.0 gRPC 认证授权 一.前言 在前一文 <ASP.NE ...
- 回顾TCP的三次握手过程
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接.第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认: SYN:同 ...