基于python语言使用余弦相似性算法进行文本相似度分析
编写此脚本的目的:
本人从事软件测试工作,近两年发现项目成员总会提出一些内容相似的问题,导致开发抱怨。一开始想搜索一下是否有此类工具能支持查重的工作,但并没找到,因此写了这个工具。通过从纸上谈兵到着手实践,还是发现很多大大小小的问题(一定要动手去做喔!),总结起来就是理解清楚参考资料、按需设计、多角度去解决问题。
脚本进行相似度分析的基本过程:
1、获取Bug数据。读取excel表,获取到“BugID”和“Bug内容”
2、获取指定格式的Bug关键字集合。使用“jieba包”,采用“搜索模式”,对Bug内容进行分词,获取到分词表后,使用“正则表达式”过滤,拿到词语(词语长度>=2),提出掉单个字、符号、数字等非关键字
3、计算词频(TF)。在步骤2中获取到关键字总量,在本步骤,则对筛选后的关键字进行频率统计,最后得出“TF值(关键字出现频率/总词数)”
4、获取词逆文档频率(IDF)(也可以理解为权重)。在本步骤,有个重要的前提就是“语料库”,这里我没有使用开放、通用的语料库,而是使用本项目的“测试用例步骤、约束条件”等内容,唯一的原因就是“很适应Bug内容的语言场景”,在此模块,也是采用分词,然后利用参考资料中的计算公式,获取到每个“关键词”的IDF值,并存至名称为“get_IDF_value.txt”的文件中(一开始没放到这里,导致出现重复、多次进行本步骤计算,几kb的文本内容还能接受,几百kb的就......当时跑了一夜都没完!)
5、获取TF_IDF值,并据此对Bug关键字进行倒序排列,然后硬性截取所有Bug排位前50%的关键字,并形成集合,然后以冒泡的形式,从第一个Bug开始,进行“相似度计算”(公式见参考资料),最终将相似度大于阀值的Bug,以形式“Bug编号_1(被比对对象)-Bug编号_2(比对对象)”打印到名称为“bug_compare_result.xls”的Excel表中
过程中一些特殊点的处理:
1、“所有Bug排位前50%的关键字,并形成集合”之所以创建该列表是为减少单个列表或字典在多个函数使用的频率,肯定是可以减少脚本问题频率的。
2、语料库的选择是为适应使用需求
3、得到TF_IDF值的目的只是为了获取到“排位前50%的Bug关键字”
4、逆文档频率(IDF)值会存储至“get_IDF_value.txt”文件中,每次运行脚本时会提醒是否更改语料库
说明:
1、代码友好性差,技术能力有限。当然可塑性很高 ~ ~
2、出于练习的目的,独立编写“IDF计算”的脚本,并放到另一路径下
源码:(纯生肉,通过代码注释还是能看到本人设计过程的心态)
sameText.py
--------------------sameText.py--------------------------
#-*- coding:utf-8 -*-
import jieba
import re
import CorpusDatabase.getIDF as getIDF
import math
import xlrd
import xlwt
import time
#######获取原始bug数据
re_rule_getTF = re.compile(r"^([\u4e00-\u9fa5]){2,20}")#选择中文开头,且文字长度为2-20,一定要记住哇
Top_List = []#将分词的列表和TF_IDF值前50%的列表合于此处
Compare_CosResult = []#相似度大于??(可调整)的问题号
BugID_List = []#用于存放BugID
getIDF_get_IDF_value = {}#存储语料库中各关键词的权重
xiangsidu = 0.8
###########
def read_Originalbase(filename):
Original_Bug_Dict = {}
book = xlrd.open_workbook(filename)
sheet_name = book.sheet_by_index(0)
nrows = sheet_name.nrows
for i in range(nrows):
Original_Bug_Dict[sheet_name.row_values(i)[0]] = sheet_name.row_values(i)[1]
return Original_Bug_Dict ###########词频统计###################
def get_TF_value(test_String_one):
word_counts = 0#统计除空、单字、符号以外的总词数
counts = {}
counts_two = {}
words_re_TF = []
words = jieba.lcut_for_search(test_String_one)
#这边得加段正则表达式的,筛除掉words非中文且单字的内容,并构建words_re_TF
for i in words:
if re.match(re_rule_getTF,i):
words_re_TF.append(i)
#统计每个分词的出现次数,即总词数量counts
Top_List.append(words_re_TF)#全局的作用列表,很关键
for word in words_re_TF:
word_counts = word_counts + 1
counts[word] = counts.get(word,0) + 1#为关键字出现次数进行统计,从0开始,get中第一个为key,0为赋给其对应的value
#获取每个关键字在整句话中出现的频率,即最终词频
for count in counts:
counts_two[count] = counts_two.get(count,(counts[count]/float(word_counts)))
return counts_two
###########获取TF_TDF值,并向量化#############
def get_TF_IDF_Key(test_String_two):
global getIDF_get_IDF_value
TestString_TF_value = {}
TF_IDF_value = {}
The_Last_TF_IDF_List = []
Corpus_weight_value = getIDF_get_IDF_value#此部分直接定义一个存储语料库权重的全局变量吧
TestString_TF_value = get_TF_value(test_String_two)
for i in TestString_TF_value:
balance_value = 1
for j in Corpus_weight_value:
if i == j:
TF_IDF_value[i] = float(TestString_TF_value[i]) * float(Corpus_weight_value[j])
elif i != j and balance_value != len(Corpus_weight_value):#遍历列表过程中,判断是否与TF的值一样,且是否遍历到最后一个元素了
balance_value = balance_value + 1#计算遍历次数
continue
else:
TF_IDF_value[i] = float(TestString_TF_value[i]) * 1#对于语料库中不存在的词,权重默认为1
The_Last_TF_IDF_List = sorted(TF_IDF_value,key = TF_IDF_value.__getitem__,reverse=True)
The_Last_TF_IDF_List = The_Last_TF_IDF_List[0:int((len(The_Last_TF_IDF_List)/2) + 0.5)]#默认取一半关键字
Top_List.append(The_Last_TF_IDF_List)#全局的作用列表,很关键
return The_Last_TF_IDF_List
def cosine_result(the_Top_List):#计算余弦相似度
global Compare_CosResult
global BugID_List
global xiangsidu
cos_result = 0.0
keymix = []
compare_one = []
compare_two = []
control_i = 0
for i in range(0,len(the_Top_List) - 1,2):
control_j = control_i + 1
for j in range(i + 2,len(the_Top_List) - 1,2):
keymix = list(set(the_Top_List[i+1] + the_Top_List[j+1]))#去掉重复的关键字
compare_one = the_Top_List[i]
compare_two = the_Top_List[j]
compare_one_dict = {}
compare_two_dict = {}
fenzi_value = 0.0
fenmu_value = 1.0
fenmu_value_1 = 0.0
fenmu_value_2 = 0.0
for word_one in compare_one:
for unit_keymix_one in keymix:
if unit_keymix_one == word_one:
compare_one_dict[unit_keymix_one] = compare_one_dict.get(unit_keymix_one,0) + 1
else:
compare_one_dict[unit_keymix_one] = compare_one_dict.get(unit_keymix_one,0) + 0
for word_two in compare_two:
for unit_keymix_two in keymix:
if unit_keymix_two == word_two:
compare_two_dict[unit_keymix_two] = compare_two_dict.get(unit_keymix_two,0) + 1
else:
compare_two_dict[unit_keymix_two] = compare_two_dict.get(unit_keymix_two,0) + 0
###########计算余弦相似度##################
for k in compare_one_dict:
fenzi_value = fenzi_value + compare_one_dict[k] * compare_two_dict[k]
fenmu_value_1 = fenmu_value_1 + math.pow(compare_one_dict[k],2)
fenmu_value_2 = fenmu_value_2 + math.pow(compare_two_dict[k],2)
fenmu_value = math.sqrt(fenmu_value_1) * math.sqrt(fenmu_value_2)
cos_result = fenzi_value / fenmu_value
if cos_result >= xiangsidu:#调控值
Compare_CosResult.append(str(int(BugID_List[control_i])) + '-' + str(int(BugID_List[control_j])))#浮点数转整数再转字符串
control_j = control_j + 1
control_i = control_i + 1
return 0
#########将最终结果写入到新的xls文件中#########
def write_BugBase(bug_base,CosResult_list):
global xiangsidu
key_list = list(bug_base.keys())
value_list = list(bug_base.values())
newbook = xlwt.Workbook(encoding = "utf-8", style_compression = 0)
sheet_name = newbook.add_sheet('sheet1',cell_overwrite_ok = True)
for i in range(0,len(key_list)):
bug_com_key_list = []
if i == 0:
sheet_name.write(i,0,key_list[i])
sheet_name.write(i,1,value_list[i])
sheet_name.write(i,2,u"相似问题(相似度大于%.1f)"%(xiangsidu))
else:
re_CosResult = re.compile(r"^((%s)-\d{0,3}$)"%str(int(key_list[i])))
sheet_name.write(i,0,key_list[i])
sheet_name.write(i,1,value_list[i])
for bug_com_key in CosResult_list:
if re.match(re_CosResult,bug_com_key):########
bug_com_key_list.append(bug_com_key)########
else:
continue
for j in range(len(bug_com_key_list)):
sheet_name.write(i,j + 2,bug_com_key_list[j] + "\n")#重复写入
newbook.save("bug_compare_result.xls") def main():
global getIDF_get_IDF_value
user_message = input("是否更改了语料库,请输入 Y or N:")
starttime = time.time()
if str(user_message) == "Y" or str(user_message) == "y":
getIDF_get_IDF_value = getIDF.get_IDF_value()
getIDF_file = open('get_IDF_value.txt','w')
getIDF_file.write(str(getIDF_get_IDF_value))
getIDF_file.close()
else:
getIDF_file = open('get_IDF_value.txt','r')
getIDF_get_IDF_value = eval(getIDF_file.read())
getIDF_file.close()
##########
Bug_base = read_Originalbase('bug.xls')
for main_key_value_1 in Bug_base.keys():
if main_key_value_1 == "Bug编号":
continue
else:
BugID_List.append(main_key_value_1)
for main_key_value_2 in Bug_base.values():
if main_key_value_2 == "Bug标题":
continue
else:
get_TF_IDF_Key(main_key_value_2)#字符串
cosine_result(Top_List)
write_BugBase(Bug_base,Compare_CosResult)
endtime = time.time()
print("共用时:%d秒!"%(endtime - starttime)) if __name__ == '__main__':
main()
-----------------------------------------------------------------
getIDF.py
---------------------getIDF.py-------------------------------
#-*- coding:utf-8 -*-
import os
import re
import jieba
import math
import re
######正则表达式规则######
re_rule_getIDF = re.compile(r"^([\u4e00-\u9fa5]){2,20}")#选择中文开头,且文字长度为2-20,一定要记住哇
#读取语料库,并计算出语料库中所有关键词的权重
def get_IDF_value():
Corpus_file_list = []#获取所有语料库文件,以列表形式保存
Corpus_text_list = []
words_re_IDF = []
Corpus_word_counts = 0
Corpus_counts = {}
Corpus_counts_two = {}
for root,dirs,files in os.walk('.',topdown=False):
for name in files:
str_value = ""
str_value = os.path.join(root,name)
Corpus_file_list.append(str_value)
for i in Corpus_file_list:
if i == '.\\CorpusDatabase\\__pycache__\\getIDF.cpython-36.pyc' or i == '.\\CorpusDatabase\\__pycache__\\__init__.cpython-36.pyc' or i == '.\\CorpusDatabase\\getIDF.py' or i == '.\\CorpusDatabase\\getIDF.pyc' or i == '.\\CorpusDatabase\\__init__.py' or i == '.\\CorpusDatabase\\__init__.pyc' or i == '.\\sameText.py' or i == '.\\bug.xls' or i == '.\\bug_compare_result.xls' or i == '.\\get_IDF_value.txt':
continue
else:
file_object = open(i,'r',encoding = 'UTF-8')#避免出现编码问题,open文件时使用UTF-8编码
file_content = file_object.readlines()
for j in file_content:
Corpus_text_list.append(j)
#对语料库进行分词,统计总词数和每个词出现频率,最终计算出权重
for split_words in Corpus_text_list:
words = jieba.lcut_for_search(split_words)
#这边得加段正则表达式的,筛除掉words非中文、单个汉字的内容,并构建words_re_IDF
for k in words:
if re.match(re_rule_getIDF,k):
words_re_IDF.append(k)
for word in words_re_IDF:
Corpus_word_counts = Corpus_word_counts + 1
Corpus_counts[word] = Corpus_counts.get(word,0) + 1
for count in Corpus_counts:
Corpus_counts_two[count] = Corpus_counts_two.get(count,(math.log(Corpus_word_counts / (float(Corpus_counts[count] + 1)))))
return Corpus_counts_two
-------------------------------------------------------
文档结构:
NLP为主文件名,文件中包括:
——bug.xls(存有BugID和Bug内容的原始文件)
——bug_compare_result.xls(存储比对结果的文件,由程序生成)
——get_IDF_value.txt(存储IDF值的文件)
——sameText.py(主脚本文件)
——CorpusDatabase
——__init__.py(空脚本文件)
——getIDF.py(计算IDF值的文件)
——OAcase.txt(语料库)
——__pycache__(程序自动生成,不用关注)

Bug原文件样式:
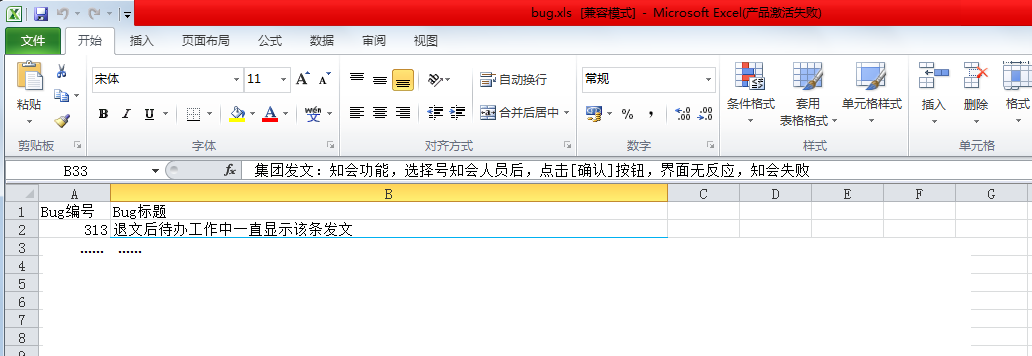
最终结果:
相似的问题会从第3列开始写入


参考资料:
http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
基于python语言使用余弦相似性算法进行文本相似度分析的更多相关文章
- 关于《selenium2自动测试实战--基于Python语言》
关于本书的类型: 首先在我看来技术书分为两类,一类是“思想”,一类是“操作手册”. 对于思想类的书,一般作者有很多年经验积累,这类书需要细读与品位.高手读了会深有体会,豁然开朗.新手读了不止所云,甚至 ...
- 《Selenium2自动化测试实战--基于Python语言》 --即将面市
发展历程: <selenium_webdriver(python)第一版> 将本博客中的这个系列整理为pdf文档,免费. <selenium_webdriver(python)第 ...
- 基于python语言的tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
基于python语言的tensorflow的‘端到端’的字符型验证码识别 1 Abstract 验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的 ...
- 关于《Selenium3自动化测试实战--基于python语言》
2016年1月,机缘巧合下我出版了<Selenium2自动化测试实战--基于python语言>这本书,当时写书的原因是,大部分讲Selenium的书并不讲编程语言和单元测试框,如果想在项目 ...
- selenium2自动化测试实战--基于Python语言
自动化测试基础 一. 软件测试分类 1.1 根据项目流程阶段划分软件测试 1.1.1 单元测试 单元测试(或模块测试)是对程序中的单个子程序或具有独立功能的代码段进行测试的过程. 1.1.2 集成测试 ...
- selenium2环境搭建----基于python语言
selenium支持多种语言如java.c#.Python.PHP等,这里基于python语言,所以这里搭建环境时需做俩步操作: ----1.Python环境的搭建 ----2.selenium的安装 ...
- 《Selenium 2自动化测试实战 基于Python语言》中发送最新邮件无内容问题的解决方法
虫师的<Selenium 2自动化测试实战 基于Python语言>是我自动化测试的启蒙书 也是我推荐的自动化测试入门必备书,但是书中有一处明显的错误,会误导很多读者,这处错误就是第8章自动 ...
- Python实现的选择排序算法原理与用法实例分析
Python实现的选择排序算法原理与用法实例分析 这篇文章主要介绍了Python实现的选择排序算法,简单描述了选择排序的原理,并结合实例形式分析了Python实现与应用选择排序的具体操作技巧,需要的朋 ...
- 文本相似度分析(基于jieba和gensim)
基础概念 本文在进行文本相似度分析过程分为以下几个部分进行, 文本分词 语料库制作 算法训练 结果预测 分析过程主要用两个包来实现jieba,gensim jieba:主要实现分词过程 gensim: ...
随机推荐
- 玲珑OJ 1082:XJT Loves Boggle(爆搜)
http://www.ifrog.cc/acm/problem/1082 题意:给出的单词要在3*3矩阵里面相邻连续(相邻包括对角),如果不行就输出0,如果可行就输出对应长度的分数. 思路:爆搜,但是 ...
- top命令输出详解
前言 Linux下的top命令我相信大家都用过,自从我接触Linux以来就一直用top查看进程的CPU和MEM排行榜.但是top命令的其他输出结果我都没有了解,这些指标都代表什么呢,什么情况下需要关注 ...
- oracle group by 显示其他字段
原先用 select key,max(value) from tbl group by key 查询出的结果,但是我要再多加一个TEST字段 根据网友的语句结合起来,以下是可以显示其他字段,并且考虑排 ...
- vue组件间通信六种方式(完整版)
本文总结了vue组件间通信的几种方式,如props. $emit/ $on.vuex. $parent / $children. $attrs/ $listeners和provide/inject,以 ...
- Hash的应用
思路:此题比较简单,直接贴代码 #include <stdio.h> int main(){ int N; ){ ]={}; ;i<N;i++){ int x; scanf(&quo ...
- 跟着大彬读源码 - Redis 4 - 服务器的事件驱动有什么含义?(上)
众所周知,Redis 服务器是一个事件驱动程序.那么事件驱动对于 Redis 而言有什么含义?源码中又是如何实现事件驱动的呢?今天,我们一起来认识下 Redis 服务器的事件驱动. 对于 Redis ...
- shell的用处到底大不大
我曾在智联招聘等网站上搜寻有关shell脚本员的职位,与C++.JAVA等热门语言相比,冷清很多.看上去似乎招shell程序员的公司比较少.是不是公司不重视或者是很少用到shell这个东东呢? ...
- 20131214-HTML基础-第二十一天
[1]表单练习 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www ...
- py+selenium 无法定位ShowModalDialog模态窗口【已解决】
问题:无法定位弹出的模态窗口. 前瞻: 模态窗口:关闭之前,无法操作其他窗口. 但是selenium无法定位到这类窗口,百度说是目前selenium不支持处理模态窗口. 目标:定位到窗口里面的元素,完 ...
- elasticsearch5.4集群超时
四个节点,有两个是新增加的节点,两个老节点间组成集群没有问题,新增加了两个节点,无论是四个组成集群 # --------------------------------- Discovery ---- ...