Mysql - 高可用方案之MM+Keepalived
一、概述
本文将介绍mysql的MM+Keepalived方案。该方案由两个mysql服务器组成,这两个mysql互为主备。其中一台主作为写服务器,另一台主作为读服务器。通过keepalived软件管理写vip,当承担写服务器的mysql出现故障时,将写vip漂移到读服务器上,实现高可用。
二、节点介绍
本次实验采用2台虚拟机,操作系统版本Centos6.10,mysql版本5.7.25
node1 10.40.16.61 主库 提供写服务
node2 10.40.16.62 主库 提供读服务
还须预留1个vip,现在不用配置,这里先提一下,后面的安装步骤用得到
10.40.16.71 写vip
三、安装
1. 配置双主架构
安利一个自己写的mysql一键安装脚本https://www.cnblogs.com/ddzj01/p/10678296.html
mysql搭建完成后,就可以配置互为主备的架构了。
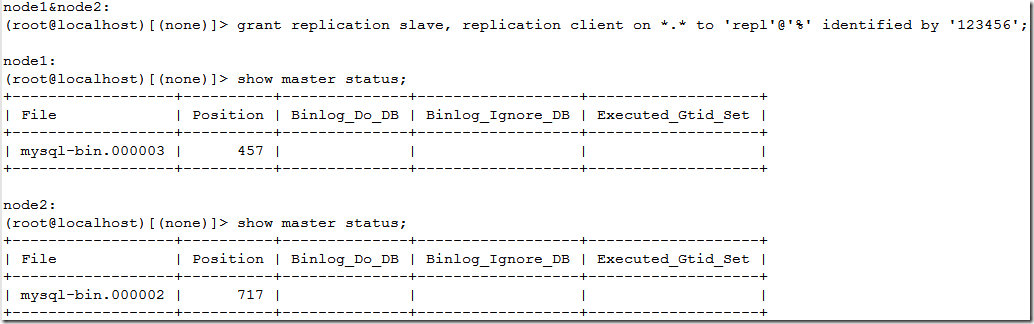
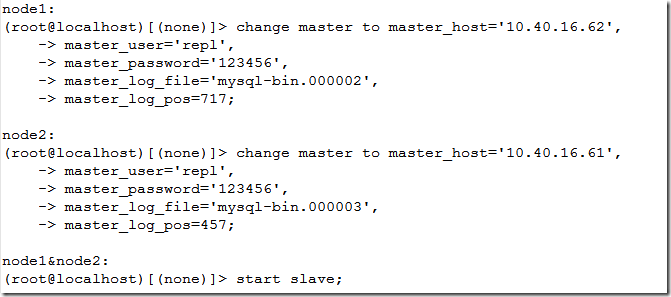
这样node1和node2就互为主备了
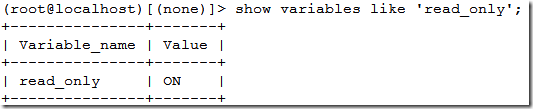
在node2上将数据库设置为只读模式
(root@localhost)[(none)]> set global read_only = 1;
2. 安装keepalive软件
node1&node2:
yum install -y keepalived
四、修改配置文件
1. node1
编辑配置文件/etc/keepalived/keepalived.conf
! Configuration File for keepalived
vrrp_script chk_mysql {
script "/etc/keepalived/check_mysql.sh" # 自定义检查脚本
interval 30 # 设置检查间隔时长,可自行设定
}
vrrp_instance VI_1 {
state BACKUP # BACKUP状态,具体意思后面介绍
interface eth0
virtual_router_id 51
priority 100
advert_int 1
nopreempt # 防止主库切换到从库后,主库恢复后自动切换回主库
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_mysql
}
virtual_ipaddress {
10.40.16.71/24 # vip
}
}
编辑检查mysql主库的脚本文件/etc/keepalived/check_mysql.sh
#!/bin/bash
source /root/.bash_profile
###填数据库相关信息###
DB_USER='root'
DB_PASSWD='root'
U_EMAIL='xxxx@163.com'
###################### ###判断如果上次检查的脚本还没执行完,则退出此次执行
if [ `ps -ef | grep -w "$0" | grep -v "grep" | wc -l` -gt 2 ]; then
exit 0
fi
mysql_con="mysql -u$DB_USER -p$DB_PASSWD"
error_log="/etc/keepalived/logs/check_mysql.err" ###如果error_log目录不存在则创建目录
if [ -d /etc/keepalived/logs ]; then
usleep
else
mkdir -p /etc/keepalived/logs
fi ###定义一个简单判断mysql是否可用的函数
function execute_query {
$mysql_con -e "select 1;" 2>> $error_log
} ###定义无法执行查询,且mysql服务异常时的处理函数
function service_error {
echo -e "`date "+%F %H:%M:%S"` ----mysql service error, now stop keepalived----" >> $error_log
service keepalived stop >> $error_log 2>&1
echo "master1 keepalived stopped" | mail -s "master1 keepalived stopped, please take notice!" $U_EMAIL 2>> $error_log
echo -e "\n---------------------------------------------------------\n" >> $error_log
} ###定义无法执行查询,但mysql服务正常的处理函数
function query_error {
echo -e "`date "+%F %H:%M:%S"` ----query error, but mysql service ok, retry after 30s----" >> $error_log
sleep 30
execute_query
if [ $? -ne 0 ]; then
echo -e "`date "+%F %H:%M:%S"` ----still can't execute query----" >> $error_log ###关闭本机mysql
echo -e "`date "+%F %H:%M:%S"` ----stop mysql service----" >> $error_log
service mysql stop &>> $error_log
sleep 2 ###给执行和缓冲时间 ###关闭本机keepalived
echo -e "`date "+%F %H:%M:%S"` ----stop keepalived----" >> $error_log
service keepalived stop &>> $error_log
echo "master1 keepalived stopped" | mail -s "master1 keepalived stopped, please take notice!" $U_EMAIL 2>> $error_log
echo -e "\n---------------------------------------------------------\n" >> $error_log
else
echo -e "`date "+%F %H:%M:%S"` ----query ok after 30s----" >> $error_log
echo -e "\n---------------------------------------------------------\n" >> $error_log
fi
} ###检查开始: 执行查询
execute_query
if [ $? -ne 0 ]; then
service mysql status &> /dev/null
if [ $? -ne 0 ]; then
service_error
else
query_error
fi
fi
chmod +x /etc/keepalived/check_mysql.sh
该脚本的作用有两个
a. mysql进程挂掉了,直接关闭keepalived服务
b. mysql进程正常,但是无法执行查询,比如进程卡死了等等原因。则同时关闭mysql和keepalived
2. node2
编辑配置文件/etc/keepalived/keepalived.conf
! Configuration File for keepalived
vrrp_instance VI_1 {
state BACKUP # BACKUP状态,具体意思后面介绍
interface eth0
virtual_router_id 51
priority 90 # 优先级设置为90,这个值设置比节点1低
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
notify_master /etc/keepalived/notify_master_mysql.sh
virtual_ipaddress {
10.40.16.71/24 # vip
}
}
编辑检查mysql从库的脚本文件/etc/keepalived/notify_master_mysql.sh
#!/bin/bash
source /root/.bash_profile
###当keepalived监测到本机转为MASTER状态时,执行该脚本
###填数据库相关信息###
DB_USER='root'
DB_PASSWD='root'
U_EMAIL='xxxx@163.com'
###################### change_log='/etc/keepalived/logs/state_change.log'
mysql_con="mysql -u$DB_USER -p$DB_PASSWD"
echo -e "`date "+%F %H:%M:%S"` ----master2 keepalived change to MASTER----" >> $change_log ###如果error_log目录不存在则创建目录
if [ -d /etc/keepalived/logs ]; then
usleep
else
mkdir -p /etc/keepalived/logs
fi slave_info() {
###检查从库状态
slave_stat=`$mysql_con -e "show slave status\G"`
Slave_IO_Running=`echo $slave_stat | egrep -w "Slave_IO_Running" | awk '{print $2}'`
Slave_SQL_Running=`echo $slave_stat | egrep -w "Slave_SQL_Running" | awk '{print $2}'`
Master_Log_File=`echo $slave_stat | egrep -w "Master_Log_File" | awk '{print $2}'`
Read_Master_Log_Pos=`echo $slave_stat | egrep -w "Read_Master_Log_Pos" | awk '{print $2}'`
Relay_Master_Log_File=`echo $slave_stat | egrep -w "Relay_Master_Log_File" | awk '{print $2}'`
Exec_Master_Log_Pos=`echo $slave_stat | egrep -w "Exec_Master_Log_Pos" | awk '{print $2}'`
} action() {
###解除read_only属性
echo -e "`date "+%F %H:%M:%S"` ----set read_only = 0 on master2----" >> $change_log
$mysql_con -e "set global read_only = 0;" 2>> $change_log
echo "master2 keepalived change to MASTER,线上数据库切换至master2" | mail -s "master2 keepalived change to MASTER" $U_EMAIL 2>> $change_log
echo -e "---------------------------------------------------------\n" >> $change_log
} slave_info
if [ $Slave_SQL_Running == 'Yes' ]; then
i=0 #一个计数器
###判断从master接收到的binlog是否全部在本地执行(这样仍无法完全确定从库已追上主库,因为无法完全保证io_thread没有延时(但由网络传输问题导致的从库落后的概率很小)
until [ $Master_Log_File == $Relay_Master_Log_File -a $Read_Master_Log_Pos == $Exec_Master_Log_Pos ]
do
if [ $i -lt 10 ]; then #将等待exec_pos追上read_pos的时间限制为20s
echo -e "`date "+%F %H:%M:%S"` ----Relay_Master_Log_File=$Relay_Master_Log_File, Exec_Master_Log_Pos=$Exec_Master_Log_Pos is behind Master_Log_File=$Master_Log_File, Read_Master_Log_Pos=$Read_Master_Log_Pos, wait......" >> $change_log #输出消息到日志,等待exec_pos=read_pos
i=$(($i+1))
sleep 2
slave_info
else
echo -e "The waits time is more than 20s,now force change. Master_Log_File=$Master_Log_File Read_Master_Log_Pos=$Read_Master_Log_Pos Relay_Master_Log_File=$Relay_Master_Log_File Exec_Master_Log_Pos=$Exec_Master_Log_Pos" >> $change_log
action
exit 0
fi
done
action
else
echo -e "master2's slave status is not running,now force change. Master_Log_File=$Master_Log_File Read_Master_Log_Pos=$Read_Master_Log_Pos Relay_Master_Log_File=$Relay_Master_Log_File Exec_Master_Log_Pos=$Exec_Master_Log_Pos" >> $change_log
action
fi
chmod +x /etc/keepalived/notify_master_mysql.sh
该脚本的作用有三个
a. slave sql线程没有运行,直接将从库只读关闭
c. slave sql线程正在运行,如果从库没有延迟,直接将从库只读关闭
b. slave sql线程正在运行,如果从库有延迟,等待一段时间(这个自己设置)再将从库只读关闭
这里解释下keepalived.conf的"state BACKUP"的意思,在Keepalived中有两种模式,分别是master->backup模式和backup->backup模式,这两种模式有什么区别呢?
在master->backup模式下,一旦主库宕掉,虚拟IP会自动漂移到从库,当主库修复后,keepalived启动后,还会把虚拟IP抢过来,即使你设置nopreempt(不抢占)的方式抢占IP的动作也会发生。
在backup->backup模式下,当主库宕掉后虚拟IP会自动漂移到从库上,当原主恢复之后重启keepalived服务,并不会抢占新主的虚拟IP,即使是原主优先级高于从库的优先级别,也不会抢占虚拟IP。
所以,为了减少虚拟IP的漂移次数,生产中我们通常是把修复好的主库当做新主库的备库。因而采用backup->backup模式居多。
五、启动Keepailived
node1&node2:
service keepalived start
注意因为我们使用的是backup->backup模式,所以启动keepalived的顺序需要先启动node1,再启动node2,这样vip才会在node1上。如果先启动node2,再启动node1,node1并不会把虚拟IP抢过来。
六、测试
1. 模拟主库宕机的情况
关闭node1的mysql数据库
service mysql stop
查看node1的keepalived日志/etc/keepalived/logs/check_mysql.err

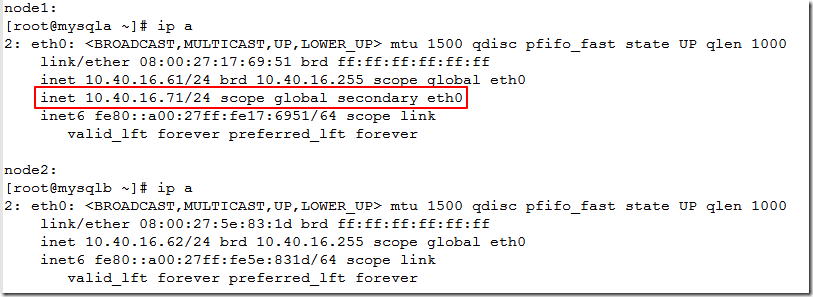
查看node1和node2的vip,发现vip已经转移到了node2
node2的read_only参数也变成了off

node2的切换日志可以查看/etc/keepalived/logs/state_change.log
看看有没有收到邮件,呵呵:-)
failover正常!
2. 模拟主库正常,但是无法查询
重新打开node1的mysql数据库和keepalived服务
service mysql start
service keepalived start
重启node2的keepalived服务
service keepalived restart
在node2上将数据库设置为只读模式
(root@localhost)[(none)]> set global read_only = 1;
这样就跟最初的状态一致了,主库是node1,从库是node2,vip在node1上。
在node1上将参数max_connections设置得足够小
(root@localhost)[(none)]> set global max_connections = 2;
在node1上然后多开几个连接,直到出现无法连接的情况。以此来模拟无法查询的情况。

查看node1的keepalived日志/etc/keepalived/logs/check_mysql.err

查看node1,发现keepalived和mysql服务都已经停止
[root@mysqla ~]# service mysql status
MySQL is not running
[root@mysqla ~]# service keepalived status
keepalived is stopped
node2的read_only参数也变成了off

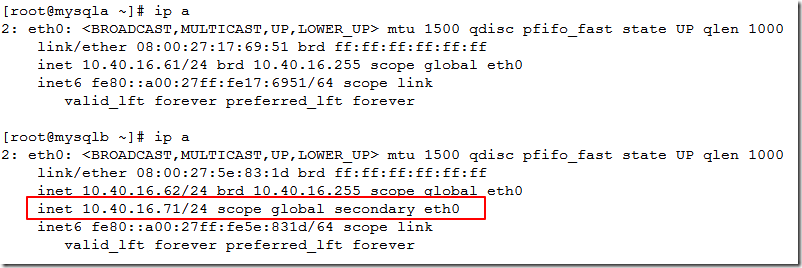
vip也已经漂移过来了
[root@mysqlb ~]# ip a

failover正常!
七、手动切换
还有一个场景就是,如何手工切换。举个例子,node2目前是主库,但是node1通过各种办法修复好了,我想让node1当主库。
重启node1的mysql服务
service mysql restart
这样node2是主库,node1是备库,vip在node2上
在node2上创建手工切换的脚本vi /etc/keepalived/manual_switch_to_master
#!/bin/bash
source /root/.bash_profile
###在master2上手动执行将主库切换回master1的操作
###填数据库相关信息###
DB_USER='root'
DB_PASSWD='root'
U_EMAIL='xxxx@163.com'
MASTER1='10.40.16.61'
MASTER2='10.40.16.62'
REPL_USER='repl'
REPL_PASSWD='123456'
MASTER1_MYSQL_PATH='/usr/local/mysql/bin'
###################### ###如果error_log目录不存在则创建目录
if [ -d /etc/keepalived/logs ]; then
usleep
else
mkdir -p /etc/keepalived/logs
fi mysql_con="mysql -u$DB_USER -p$DB_PASSWD" echo -e "`date "+%F %H:%M:%S"` ----change to BACKUP manually----" >> /etc/keepalived/logs/state_change.log
echo -e "`date "+%F %H:%M:%S"` ----set read_only = 1 on master2----" >> /etc/keepalived/logs/state_change.log
$mysql_con -e "set global read_only = 1;" >> /etc/keepalived/logs/state_change.log ###kill掉当前客户端连接
echo -e "`date "+%F %H:%M:%S"` ----kill current client thread----" >> /etc/keepalived/logs/state_change.log
if [ -e /tmp/kill.sql ]; then
rm -f /tmp/kill.sql &> /dev/null
fi
###这里其实是一个批量kill线程的小技巧
$mysql_con -e 'select concat("kill ",id,";") from information_schema.processlist where command="Query" or command="Execute" into outfile "/tmp/kill.sql";'
$mysql_con -e "source /tmp/kill.sql" 2>> /etc/keepalived/logs/state_change.log
sleep 2 ###给kill一个执行和缓冲时间 slave_info() {
###检查从库状态
slave_stat=`mysql -u$REPL_USER -p$REPL_PASSWD -h$MASTER1 -e "show slave status\G"`
Master_Log_File=`echo $slave_stat | egrep -w "Master_Log_File" | awk '{print $2}'`
Read_Master_Log_Pos=`echo $slave_stat | egrep -w "Read_Master_Log_Pos" | awk '{print $2}'`
Relay_Master_Log_File=`echo $slave_stat | egrep -w "Relay_Master_Log_File" | awk '{print $2}'`
Exec_Master_Log_Pos=`echo $slave_stat | egrep -w "Exec_Master_Log_Pos" | awk '{print $2}'`
} slave_info
until [ $Read_Master_Log_Pos = $Exec_Master_Log_Pos -a $Master_Log_File = $Relay_Master_Log_File ]
do
echo -e "`date "+%F %H:%M:%S"` ----Relay_Master_Log_File=$Relay_Master_Log_File, Exec_Master_Log_Pos=$Exec_Master_Log_Pos is behind Master_Log_File=$Master_Log_File, Read_Master_Log_Pos=$Read_Master_Log_Pos, wait......" >> /etc/keepalived/logs/state_change.log
sleep 2
slave_info
done ###然后解除master1的read_only属性并打开keepalived服务
echo -e "`date "+%F %H:%M:%S"` ----set read_only = 0 on master1----" >> /etc/keepalived/logs/state_change.log
ssh $MASTER1 "$MASTER1_MYSQL_PATH/mysql -u$DB_USER -p$DB_PASSWD -e 'set global read_only = 0;' && /etc/init.d/keepalived start" 2>> /etc/keepalived/logs/state_change.log ###重启master2的keepalived服务,使VIP漂移到master1
echo -e "`date "+%F %H:%M:%S"` ----make VIP move to master1----" >> /etc/keepalived/logs/state_change.log
/etc/init.d/keepalived restart &>> /etc/keepalived/logs/state_change.log
echo "master2 keepalived restart,vip change to master1" | mail -s "master2 keepalived change to BACKUP" $U_EMAIL 2>> /etc/keepalived/logs/state_change.log
echo -e "\n--------------------------------------------------\n" >> /etc/keepalived/logs/state_change.log
在node2上执行脚本
chmod +x /etc/keepalived/manual_switch_to_master
[root@mysqlb keepalived]# sh /etc/keepalived/manual_switch_to_master
在node2上查看ip,发现vip不见了

在node2上查看read_only参数
在node1上查看vip,发现vip已经漂移过来了

手工切换完成!
八、总结
mm+keepalive的配置简单,相对于传统的主从架构,能实现比较简单的写库故障转移。
文章参考:https://www.cnblogs.com/ivictor/p/5522383.html
Mysql - 高可用方案之MM+Keepalived的更多相关文章
- MySQL高可用方案 MHA之四 keepalived 半同步复制
主从架构(开启5.7的增强半同步模式)master: 10.150.20.90 ed3jrdba90slave: 10.150.20.97 ed3jrdba97 10.150.20.132 ...
- [转]MYSQL高可用方案探究(总结)
前言 http://blog.chinaunix.net/uid-20639775-id-3337432.htmlLvs+Keepalived+Mysql单点写入主主同步高可用方案 http://bl ...
- [转载] MySQL高可用方案选型参考
原文: http://imysql.com/2015/09/14/solutions-of-mysql-ha.shtml?hmsr=toutiao.io&utm_medium=toutiao. ...
- Heartbeat+DRBD+MySQL高可用方案【转】
转自Heartbeat+DRBD+MySQL高可用方案 - yayun - 博客园 http://www.cnblogs.com/gomysql/p/3674030.html 1.方案简介 本方案采用 ...
- MySQL高可用方案MHA的部署和原理
MHA(Master High Availability)是一套相对成熟的MySQL高可用方案,能做到在0~30s内自动完成数据库的故障切换操作,在master服务器不宕机的情况下,基本能保证数据的一 ...
- MySQL高可用方案--MHA部署及故障转移
架构设计及必要配置 主机环境 IP 主机名 担任角色 192.168.192.128 node_master MySQL-Master| ...
- MySQL高可用方案-PXC环境部署记录
之前梳理了Mysql+Keepalived双主热备高可用操作记录,对于mysql高可用方案,经常用到的的主要有下面三种: 一.基于主从复制的高可用方案:双节点主从 + keepalived 一般来说, ...
- 五大常见的MySQL高可用方案【转】
1. 概述 我们在考虑MySQL数据库的高可用的架构时,主要要考虑如下几方面: 如果数据库发生了宕机或者意外中断等故障,能尽快恢复数据库的可用性,尽可能的减少停机时间,保证业务不会因为数据库的故障而中 ...
- mysql高可用方案MHA介绍
mysql高可用方案MHA介绍 概述 MHA是一位日本MySQL大牛用Perl写的一套MySQL故障切换方案,来保证数据库系统的高可用.在宕机的时间内(通常10-30秒内),完成故障切换,部署MHA, ...
随机推荐
- linux下创建mysql用户和数据库,并绑定
Linux下输入命令: mysql -uroot -proot123 进入mysql后输入: 查看目前有哪些数据库存在:mysql> SHOW DATABASES; 创建数据库:create s ...
- 小白的springboot之路(二)、集成swagger
0-前言 现在的项目开发,基本都是前后端分离,后端专注于API接口开发,都需要编写和维护API接口文档.如果你还在用Word来编写接口文档,那你就out了,这个时候,当当当当~神兵利器swagger隆 ...
- java之--加密、解密算法
0.概述 在项目开发中,我们常需要用到加解密算法,加解密算法主要分为三大类: 1.对称加密算法,如:AES.DES.3DES 2.非对称加密算法,如:RSA.DSA.ECC 3.散列算法,如:MD5. ...
- 爬虫新宠requests_html 带你甄别2019虚假大学 #华为云·寻找黑马程序员#
python模块学习建议 学习python模块,给大家个我自己不专业的建议: 养成习惯,遇到一个模块,先去github上看看开发者们关于它的说明,而不是直接百度看别人写了什么东西.也许后者可以让你很快 ...
- composer install 或 update 速度慢的解决方案(composer加速)
我们在使用composer install和composer update时,有的时候安装和更新速度非常慢,我们可以通过下面的几个方法来解决这个问题. 首先查看一下当前的 composer 全局配置地 ...
- SpringBoot整合log4j2进行日志配置及防坑指南
写在前面 最近项目经理要求将原先项目中的日志配置logBack,修改为log4j2,据说是log4j2性能更优于logback,具体快多少,网上有说快10多倍,看来还是很快的,于是新的一波挑战又开始了 ...
- gitlab 命令使用
利用 rm -rf 误删除文件夹, 恢复的办法(注意 要 提前备份或提交 其他新改变的代码, 否则执行下面的命令会让之前的新代码全部消失): git status git reset HEAD \* ...
- 在Tinymce编辑器里,集成数学公式
在以前,需要在Web页面显示数学公式,常用的都是先制作成图片,然后插入到页面里.这使得后期对数学公式的修改变的麻烦,同时也不利于搜索引擎搜索. 本文将介绍如何在TinyMce编辑器里集成数学公式.先看 ...
- cf1119d Frets On Fire 前缀和+二分
题目:http://codeforces.com/problemset/problem/1119/D 题意:给一个数n,给出n个数组的第一个数(a[0]=m,a[1]=m+1,a[2]=m+2,... ...
- 关于spring boot项目配置文件的一些想法
一.springboot项目中有两种配置文件 springboot项目中有两种配置文件 bootstrap 和 application bootstrap是应用程序的父上下文,由父Spring App ...