Spark安装与部署
1.首先安装scala(找到合适版本的具体地址下载)
wget https://www.scala-lang.org/download/****
2.安装spark
wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
tar -zxvf spark-2.4.-bin-hadoop2..tgz
rm spark-2.4.-bin-hadoop2..tgz
3.配置环境变量
vim /etc/profile
4.刷新环境变量
source /etc/profile
5.复制配置文件
cp slaves.template slaves
cp spark-env.sh.template spark-env.sh
6.接着进行以下配置
vim /etc/profile(查看其它配置文件直接复制即可)
vim ./spark-2.4.-bin-hadoop2./conf
vim spark-env.sh
7.启动spark环境
1)先启动Hadoop环境
/usr/local/hadoop-2.7./sbin/start-all.sh
2) 启动Spark环境
/usr/local/spark-2.4.-bin-hadoop2./sbin/start-all.sh
8.查看spark的web控制界面

9.查看Hadoop的web端界面
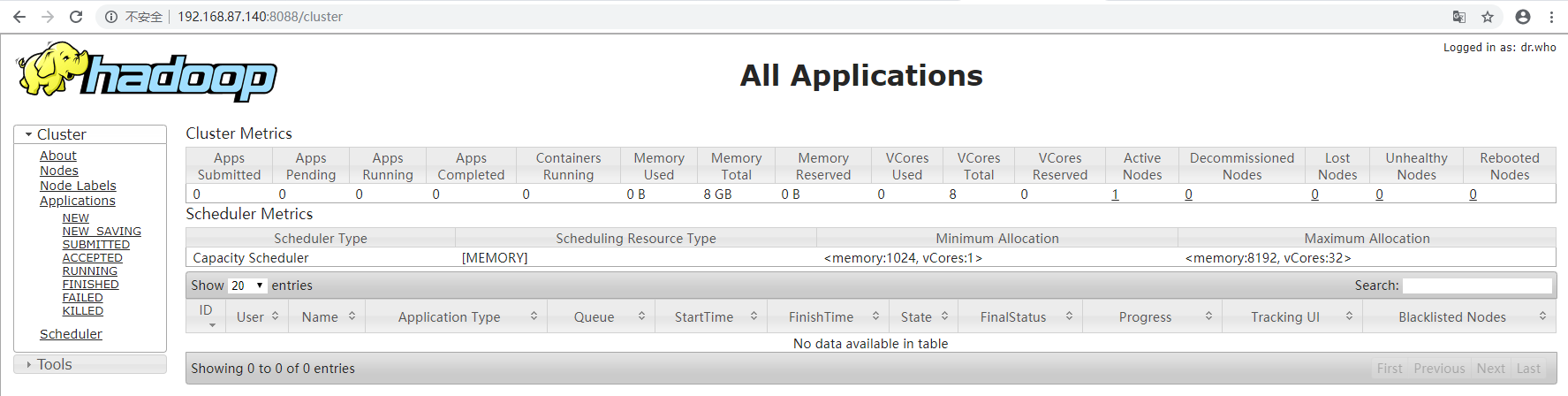
10.验证Spark是否安装成功
bin/run-example SparkPi

bin/run-example SparkPi >& | grep "Pi is"

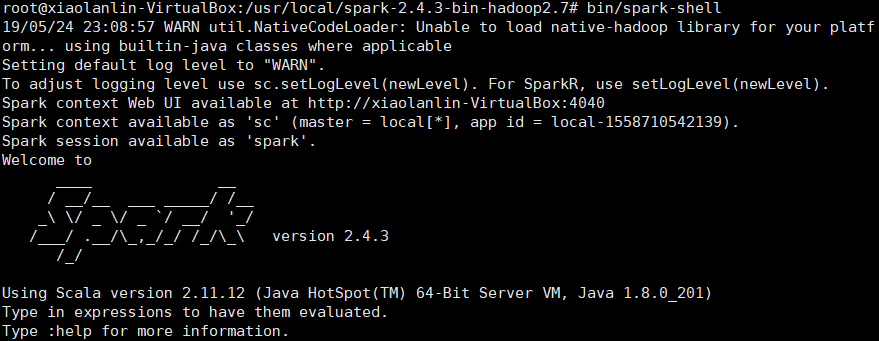
11.使用Spark Shell编写代码
1)启动Spark Shell
bin/spark-shell
2)加载text文件
3)简单RDD操作
scala> textFile.first() // 获取RDD文件textFile的第一行内容
scala> textFile.count() // 获取RDD文件textFile的所有项的计数

scala> val lineWithSpark=textFile.filter(line=>line.contains("Spark"))// 抽取含有“Spark”的行,返回一个新的RDD

scala> lineWithSpark.count() //统计新的RDD的行数

4)可以通过组合RDD操作进行组合,可以实现简易MapReduce操作
scala> textFile.map(line=>line.split(" ").size).reduce((a,b)=>if(a>b) a else b) //找出文本中每行的最多单词数

5)退出Spark shell
:quit

Spark安装与部署的更多相关文章
- Spark入门实战系列--2.Spark编译与部署(中)--Hadoop编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Hadooop 1.1 搭建环境 1.1.1 安装并设置maven 1. 下载mave ...
- Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Spark .时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 ...
- Spark安装部署(local和standalone模式)
Spark运行的4中模式: Local Standalone Yarn Mesos 一.安装spark前期准备 1.安装java $ sudo tar -zxvf jdk-7u67-linux-x64 ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Spark 安装部署与快速上手
Spark 介绍 核心概念 Spark 是 UC Berkeley AMP lab 开发的一个集群计算的框架,类似于 Hadoop,但有很多的区别. 最大的优化是让计算任务的中间结果可以存储在内存中, ...
- spark-2.2.0安装和部署——Spark集群学习日记
前言 在安装后hadoop之后,接下来需要安装的就是Spark. scala-2.11.7下载与安装 具体步骤参见上一篇博文 Spark下载 为了方便,我直接是进入到了/usr/local文件夹下面进 ...
- Spark学习(一) -- Spark安装及简介
标签(空格分隔): Spark 学习中的知识点:函数式编程.泛型编程.面向对象.并行编程. 任何工具的产生都会涉及这几个问题: 现实问题是什么? 理论模型的提出. 工程实现. 思考: 数据规模达到一台 ...
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
[注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用 ...
- Spark on Mesos部署
一.Mesos的安装和部署 1.下载mesos源码和依赖包 部署环境 centOS 6.6 mesos-0.21.0 spark-1.4.1 因为mesos官方只提供源码,所以必须要自己进行编译安装使 ...
随机推荐
- spring的jar包的下载、说明
spring的jar包官方下载地址:完整链接:https://repo.spring.io/webapp/#/artifacts/browse/tree/General/libs-release-lo ...
- Java的Hook线程及捕获线程执行异常
import java.io.IOException; import java.nio.file.Files; import java.nio.file.Path; import java.nio.f ...
- Excel公式中问题-记住不要忽略空格!
总结一下之前犯得愚蠢的小问题: 程序:每日报表:从DB下载数据填充到excel,包括3个sheet,sheet1:总结<模板,公式填充,数据源为sheet2,sheet3>;sheet2: ...
- openstack-neutron基本的网络类型以及分析
[概述] Neutron是OpenStack中负责提供网络服务的组件,基于软件定义网络的思想,实现了网络虚拟化下的资源管理,即:网络即服务. [功能] ·二层交换 Neutron支持多种虚拟交换机,一 ...
- vs2010 安装项目完成桌面快捷方式无法定位程序文件夹 解决方法
本文转载自http://www.cnblogs.com/jasonxuvip/archive/2012/07/13/2589952.html 软件打包工具有很多种,让人不知道选那个方便自己使用,Tig ...
- 从0系统学Android--1.3创建你的第一个 Android 项目
1.3 创建你的第一个 Android 项目 环境搭建完成后,我们就可以写下我们的第一个项目了. 1.3.1 创建 HelloWorld 项目 在 Android Studio 的欢迎页面点击 Sta ...
- Storm 实时读取本地文件操作(模拟分析网络日志)
WebLogProduct 产生日志类 package top.wintp.weblog; import java.io.FileNotFoundException; import java.io.F ...
- C#3.0新增功能09 LINQ 基础01 语言集成查询
连载目录 [已更新最新开发文章,点击查看详细] 语言集成查询 (LINQ) 是一系列直接将查询功能集成到 C# 语言的技术统称. 数据查询历来都表示为简单的字符串,没有编译时类型检查或 Inte ...
- [leetcode] 55. Jump Game (Medium)
原题 题目意思即 每一格代表你当前最多能再往后跳几次,从第一格开始,如果能跳到最后一格返回true,反之为false. 思路:用一个下标记录当前最多能跳到哪一格,遍历一遍 --> 如果当前格子不 ...
- [02] HEVD 内核漏洞之栈溢出
作者:huity出处:http://www.cnblogs.com/huity35/版权:本文版权归作者所有.文章在看雪.博客园.个人博客同时发布.转载:欢迎转载,但未经作者同意,必须保留此段声明:必 ...