通过livy向CDH集群的spark提交任务
场景
产品中需要通过前端界面选择执行某种任务(spark任务),然后通过livy 的restful api 提交集群的spark任务
简单介绍下livy,翻译自官网:
Livy是基于Apache许可的一个服务,它可以让远程应用通过REST API比较方便的与Spark集群交互。通过简单的REST接口或RPC客户端库,它可以让你轻松的提交Spark作业或者Spark代码片段,同步或者异步的结果检索,以及SparkContext管理。Livy还简化了Spark和应用程序服务器之间的交互,从而为web/mobile应用简化Spark架构。
主要功能有:
1.由多个客户端为多个Spark作业使用长时间运行的SparkContexts。
2.同时管理多个SparkContexts,让它们在集群中(YARN/Mesos)运行,从而实现很好的容错和并发,而不是在Livy服务上运行。
3.预编译的jars,代码片段或者Java/Scala客户端API都可以用来提交作业。
4.安全认证的通信。(比如kerberos)
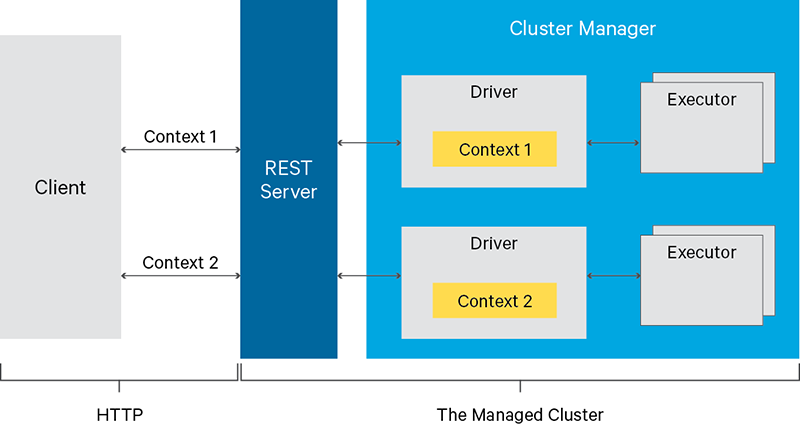
livy的rest api比较多(参考链接),这里介绍其中一种
代码如下:
<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.4</version> </dependency> <!-- https://mvnrepository.com/artifact/com.alibaba/fastjson --> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.47</version> </dependency>
package cn.com.dtmobile.livy;
import java.io.BufferedReader;
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
public class HttpUtils {
public static HttpURLConnection init(HttpURLConnection conn){
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setRequestProperty("charset","utf-8");
conn.setRequestProperty("Content-Type","application/json");
return conn;
}
/**
* HttpGET请求
*/
public static JSONObject getAccess(String urlStr) {
HttpURLConnection conn = null;
BufferedReader in = null;
StringBuilder builder = null;
JSONObject response = null;
try {
URL url = new URL(urlStr);
conn = init((HttpURLConnection) url.openConnection());
conn.setRequestMethod("GET");
conn.connect();
in = new BufferedReader(new InputStreamReader(conn.getInputStream(), "utf-8"));
String line = "";
builder = new StringBuilder();
while((line = in.readLine()) != null){
builder.append(line);
}
response = JSON.parseObject(builder.toString());
}catch (Exception e){
e.printStackTrace();
}finally {
if (conn!=null)
conn.disconnect();
try {
if (in != null)
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return response;
}
/**
* HttpDelete请求
*/
public static Boolean deleteAccess(String urlStr) {
HttpURLConnection conn = null;
try {
URL url = new URL(urlStr);
conn = init((HttpURLConnection) url.openConnection());
conn.setRequestMethod("DELETE");
conn.connect();
conn.getInputStream().close();
conn.disconnect();
}catch (Exception e){
e.printStackTrace();
return false;
}
return true;
}
/**
* HttpPost请求
*/
public static String postAccess(String urlStr, JSONObject data) {
HttpURLConnection conn = null;
BufferedReader in = null;
StringBuilder builder = null;
DataOutputStream out = null;
try {
URL url = new URL(urlStr);
conn = init((HttpURLConnection) url.openConnection());
conn.setRequestMethod("POST");
conn.connect();
out = new DataOutputStream(conn.getOutputStream());
out.write(data.toString().getBytes("utf8"));
out.flush();
in = new BufferedReader(new InputStreamReader(conn.getInputStream(), "utf-8"));
String line = "";
builder = new StringBuilder();
while((line = in.readLine()) != null){
builder.append(line);
}
}catch (Exception e){
e.printStackTrace();
}finally {
if (conn!= null)
conn.disconnect();
try {
if (in!=null)
in.close();
if (out!=null)
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (builder != null)
return builder.toString();
return "";
}
}
package cn.com.dtmobile.livy;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONException;
import com.alibaba.fastjson.JSONObject;
public class LivyApp {
static String host = "http://172.xx.x.xxx:8998";
public static int submitJob() throws JSONException {
JSONObject data = new JSONObject();
JSONObject conf = new JSONObject();
conf.put("spark.master","yarn-cluster");
data.put("conf",conf);
data.put("proxyUser","etluser");
data.put("file","/kong/data/jar/your_jar.jar");// 指定执行的spark jar (hdfs路径)
data.put("jars",new String[]{"/kong/data/jar/dbscan-on-spark_2.11-0.2.0-SNAPSHOT.jar"});//指定spark jar依赖的外部jars
data.put("className", "cn.com.dtmobile.spark.App");
data.put("name","jonitsiteplan");
data.put("executorCores",3);
data.put("executorMemory","2g");
data.put("driverCores",1);
data.put("driverMemory","4g");
data.put("numExecutors",6);
data.put("queue","default");
data.put("args",new String[]{"杭州","yj_hangzhou","2019041719"});//传递参数
String res = HttpUtils.postAccess(host + "/batches", data);
JSONObject resjson = JSON.parseObject(res);
System.out.println("id:"+resjson.getIntValue("id"));
return resjson.getIntValue("id");
}
public static void getJobInfo(int id){
// JSONObject response = HttpUtils.getAccess(host + "/batches/3");
// System.out.print(response.toString(1));
// JSONObject log = HttpUtils.getAccess(host + "/batches/3/log");
// System.out.print(log.toString(1));
JSONObject state = HttpUtils.getAccess(host + "/batches/"+id+"/state");
System.out.println(state.getString("state"));
}
public static void killJob(int id){
// 可以直接kill掉spark任务
if(HttpUtils.deleteAccess(host+"/batches/"+id)) {
System.out.println("kill spark job success");
}
}
public static void main(String[] args) {
int id = submitJob();
while(true) {
try {
getJobInfo(id);
Thread.sleep(10000);
} catch (InterruptedException e) {
}
}
// killJob(9);
}
}
执行提交以后,可以在livy的UI界面上任务的状态,也可以通过api轮询的获取任务状态,以及任务的输出日志

yarn界面

通过livy向CDH集群的spark提交任务的更多相关文章
- CDH集群安装&测试总结
0.绪论 之前完全没有接触过大数据相关的东西,都是书上啊,媒体上各种吹嘘啊,我对大数据,集群啊,分布式计算等等概念真是高山仰止,充满了仰望之情,觉得这些东西是这样的: 当我搭建的过程中,发现这些东西是 ...
- CDH集群中YARN的参数配置
CDH集群中YARN的参数配置 前言:Hadoop 2.0之后,原先的MapReduce不在是简单的离线批处理MR任务的框架,升级为MapReduceV2(Yarn)版本,也就是把资源调度和任务分发两 ...
- CentOS7安装CDH 第七章:CDH集群Hadoop的HA配置
相关文章链接 CentOS7安装CDH 第一章:CentOS7系统安装 CentOS7安装CDH 第二章:CentOS7各个软件安装和启动 CentOS7安装CDH 第三章:CDH中的问题和解决方法 ...
- 相同版本的CDH集群间迁移hdfs以及hbase
前言 由于项目数据安全的需要,这段时间看了下hadoop的distcp的命令使用,不断的纠结的问度娘,度娘告诉我的结果也让我很纠结,都是抄来抄去, 还好在牺牲大量的时间的基础上还终于搞出来了,顺便写这 ...
- 朝花夕拾之--大数据平台CDH集群离线搭建
body { border: 1px solid #ddd; outline: 1300px solid #fff; margin: 16px auto; } body .markdown-body ...
- CDH集群频繁告警(host频繁swapping)
最近CDH集群频繁告警,原因是某些host频繁swapping,极大影响了集群的性能. 后来发现有个设置(/proc/sys/vm/swappiness)需要修改,默认值60 Setting the ...
- Cloudera Manager安装_搭建CDH集群
2017年2月22日, 星期三 Cloudera Manager安装_搭建CDH集群 cpu 内存16G 内存12G 内存8G 默认单核单线 CDH1_node9 Server || Agent ...
- CDH集群搭建部署
1. 硬件准备 使用了五台机器,其中两台8c16g,三台4c8g.一台4c8g用于搭建cmServer和NFS服务端,另外4台作为cloudera-manager agent部署CDH集群. ...
- Spark集群模式&Spark程序提交
Spark集群模式&Spark程序提交 1. 集群管理器 Spark当前支持三种集群管理方式 Standalone-Spark自带的一种集群管理方式,易于构建集群. Apache Mesos- ...
随机推荐
- python实现DFA模拟程序(附java实现代码)
DFA(确定的有穷自动机) 一个确定的有穷自动机M是一个五元组: M=(K,∑,f,S,Z) K是一个有穷集,它的每个元素称为一个状态. ∑是一个有穷字母表,它的每一个元素称为一个输入符号,所以也陈∑ ...
- python基础知识二 列表、元组、range
3.6.2 列表 1.列表 -- list 有序,可变,支持索引,用于存储数据(字符串,数字,bool,列表,字典,集合,元组,). list1 = [] list1 = ['alex',12,T ...
- HIVE之 DDL 数据定义 & DML数据操作
DDL数据库定义 创建数据库 1)创建一个数据库,数据库在 HDFS 上的默认存储路径是/user/hive/warehouse/*.db. hive (default)> create dat ...
- Netty(DotNetty)原理解析
一.背景介绍 DotNetty是微软的Azure团队,使用C#实现的Netty的版本发布.不但使用了C#和.Net平台的技术特点,并且保留了Netty原来绝大部分的编程接口.让我们在使用时,完全可以依 ...
- springboot启动不设置端口
非web工程 在服务架构中,有些springboot工程只是简单的作为服务,并不提供web服务 这个时候不需要依赖 <dependency> <groupId>org.spri ...
- ASP.NET Core 中的管道机制
首先,很感谢在上篇文章 C# 管道式编程 中给我有小额捐助和点赞的朋友们,感谢你们的支持与肯定.希望我的每一次分享都能让彼此获得一些收获,当然如果我有些地方叙述的不正确或不当,还请不客气的指出.好了, ...
- Linux操作系统和Windows操作系统的区别
1.免费与收费 在中国,windows和linux都是免费的,至少对个人用户是如此,如果那天国内windows真的严打盗版了,那linux的春天就到了!但现在linux依然是任重道远,前路漫漫. 2. ...
- Linux学习(一)--VMware下Linux安装和配置
本片随便将给大家讲述linux在VM虚拟机上安装及终端的安装和配置 一.Linux介绍 Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和UNIX的多用户.多任务.支持多线 ...
- Scrapy框架安装失败解决办法
安装报错信息 正常安装: pip3 install scrapy 出现报错信息如下: 两种解决办法 第一种方法 最根本得解决办法 需要我们安装 Microsoft Visual C++ 14.0 ...
- MySql性能优化读书比较<一> 数据类型
一,选择优化的数据类型 1.更小的通常更好. 更小的数据类型通常占用更少的磁盘,内存和cpu缓存,通常更快. 2.简单就好 简单的数据类型操作,通常需要更少的CPU周期. 3.尽量避免NULL值 列可 ...