【新手必学】Python爬虫之多线程实战

1.先附上没有用多线程的包图网爬虫的代码
import requests
from lxml import etreeimport osimport timestart_time = time.time()#记录开始时间for i in range(1,7):#1.请求包图网拿到整体数据response = requests.get("https://ibaotu.com/shipin/7-0-0-0-0-%s.html" %str(i))#2.抽取 视频标题、视频链接html = etree.HTML(response.text)tit_list = html.xpath('//span[@class="video-title"]/text()')#获取视频标题src_list = html.xpath('//div[@class="video-play"]/video/@src')#获取视频链接for tit,src in zip(tit_list,src_list):#3.下载视频response = requests.get("http:" + src)#给视频链接头加上http头,http快但是不一定安全,https安全但是慢#4.保存视频if os.path.exists("video1") == False:#判断是否有video这个文件夹os.mkdir("video1")#没有的话创建video文件夹fileName = "video1\\" + tit + ".mp4"#保存在video文件夹下,用自己的标题命名,文件格式是mp4#有特殊字符的话需要用\来注释它,\是特殊字符所以这里要用2个\\print("正在保存视频文件: " +fileName)#打印出来正在保存哪个文件with open (fileName,"wb") as f:#将视频写入fileName命名的文件中f.write(response.content)end_time = time.time()#记录结束时间print("耗时%d秒"%(end_time-start_time))#输出用了多少时间
2.将上述代码套用多线程,先创建多线程
data_list = []#设置一个全局变量的列表# 创建多线程class MyThread(threading.Thread):def __init__(self, q):threading.Thread.__init__(self)self.q = q#调用get_index()def run(self) -> None:self.get_index()#拿到网址后获取所需要的数据并存入全局变量data_list中def get_index(self):url = self.q.get()try:resp = requests.get(url)# 访问网址# 将返回的数据转成lxml格式,之后使用xpath进行抓取html = etree.HTML(resp.content)tit_list = html.xpath('//span[@class="video-title"]/text()') # 获取视频标题src_list = html.xpath('//div[@class="video-play"]/video/@src') # 获取视频链接for tit, src in zip(tit_list, src_list):data_dict = {}#设置一个存放数据的字典data_dict['title'] = tit#往字典里添加视频标题data_dict['src'] = src#往字典里添加视频链接# print(data_dict)data_list.append(data_dict)#将这个字典添加到全局变量的列表中except Exception as e:# 如果访问超时就打印错误信息,并将该条url放入队列,防止出错的url没有爬取self.q.put(url)print(e)
3.用队列queue,queue模块主要是多线程,保证线程安全使用的
def main():# 创建队列存储urlq = queue.Queue()for i in range(1,6):# 将url的参数进行编码后拼接到urlurl = 'https://ibaotu.com/shipin/7-0-0-0-0-%s.html'%str(i)# 将拼接好的url放入队列中q.put(url)# 如果队列不为空,就继续爬while not q.empty():# 创建3个线程ts = []for count in range(1,4):t = MyThread(q)ts.append(t)for t in ts:t.start()for t in ts:t.join()
4.创建存储方法,如果你学习遇到问题找不到人解答,可以点我进裙,里面大佬解决问题及Python教.程下载和一群上进的人一起交流!
#提取data_list的数据并保存def save_index(data_list):if data_list:for i in data_list:# 下载视频response = requests.get("http:" + i['src'])# 给视频链接头加上http头,http快但是不安全,https安全但是慢# 保存视频if os.path.exists("video") == False: # 判断是否有video这个文件夹os.mkdir("video") # 没有的话创建video文件夹fileName = "video\\" + i['title'] + ".mp4" # 保存在video文件夹下,用自己的标题命名,文件格式是mp4# 有特殊字符的话需要用\来注释它,\是特殊字符所以这里要用2个\\print("正在保存视频文件: " + fileName) # 打印出来正在保存哪个文件with open(fileName, "wb") as f: # 将视频写入fileName命名的文件中f.write(response.content)
5.最后就是调用函数了
if __name__ == '__main__':start_time = time.time()# 启动爬虫main()save_index(data_list)end_time = time.time()print("耗时%d"%(end_time-start_time))
6.附上完整的多线程代码
import requestsfrom lxml import etreeimport osimport queueimport threadingimport timedata_list = []#设置一个全局变量的列表# 创建多线程class MyThread(threading.Thread):def __init__(self, q):threading.Thread.__init__(self)self.q = q#调用get_index()def run(self) -> None:self.get_index()#拿到网址后获取所需要的数据并存入全局变量data_list中def get_index(self):url = self.q.get()try:resp = requests.get(url)# 访问网址# 将返回的数据转成lxml格式,之后使用xpath进行抓取html = etree.HTML(resp.content)tit_list = html.xpath('//span[@class="video-title"]/text()') # 获取视频标题src_list = html.xpath('//div[@class="video-play"]/video/@src') # 获取视频链接for tit, src in zip(tit_list, src_list):data_dict = {}#设置一个存放数据的字典data_dict['title'] = tit#往字典里添加视频标题data_dict['src'] = src#往字典里添加视频链接# print(data_dict)data_list.append(data_dict)#将这个字典添加到全局变量的列表中except Exception as e:# 如果访问超时就打印错误信息,并将该条url放入队列,防止出错的url没有爬取self.q.put(url)print(e)def main():# 创建队列存储urlq = queue.Queue()for i in range(1,7):# 将url的参数进行编码后拼接到urlurl = 'https://ibaotu.com/shipin/7-0-0-0-0-%s.html'%str(i)# 将拼接好的url放入队列中q.put(url)# 如果队列不为空,就继续爬while not q.empty():# 创建3个线程ts = []for count in range(1,4):t = MyThread(q)ts.append(t)for t in ts:t.start()for t in ts:t.join()#提取data_list的数据并保存def save_index(data_list):if data_list:for i in data_list:# 下载视频response = requests.get("http:" + i['src'])# 给视频链接头加上http头,http快但是不安全,https安全但是慢# 保存视频if os.path.exists("video") == False: # 判断是否有video这个文件夹os.mkdir("video") # 没有的话创建video文件夹fileName = "video\\" + i['title'] + ".mp4" # 保存在video文件夹下,用自己的标题命名,文件格式是mp4# 有特殊字符的话需要用\来注释它,\是特殊字符所以这里要用2个\\print("正在保存视频文件: " + fileName) # 打印出来正在保存哪个文件with open(fileName, "wb") as f: # 将视频写入fileName命名的文件中f.write(response.content)if __name__ == '__main__':start_time = time.time()# 启动爬虫main()save_index(data_list)end_time = time.time()print("耗时%d"%(end_time-start_time))
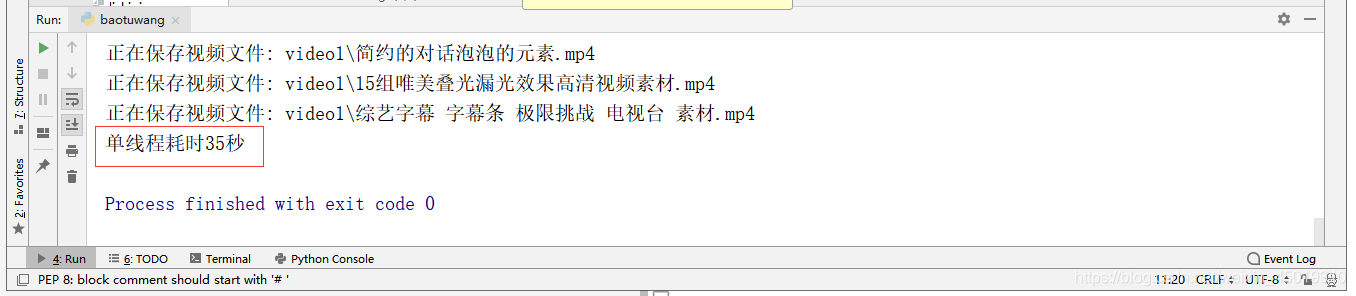
7.这2个爬虫我都设置了开始时间和结束时间,可以用(结束时间-开始时间)来计算比较两者的效率。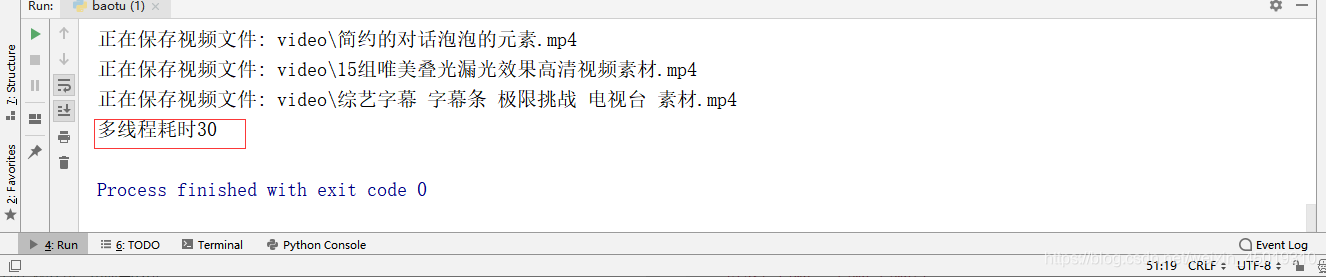
【新手必学】Python爬虫之多线程实战的更多相关文章
- Python爬虫工程师必学——App数据抓取实战 ✌✌
Python爬虫工程师必学——App数据抓取实战 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 爬虫分为几大方向,WEB网页数据抓取.APP数据抓取.软件系统 ...
- Python爬虫工程师必学APP数据抓取实战✍✍✍
Python爬虫工程师必学APP数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
- Python爬虫工程师必学——App数据抓取实战
Python爬虫工程师必学 App数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
- 小白学 Python 爬虫(16):urllib 实战之爬取妹子图
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(23):解析库 pyquery 入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(4):前置准备(三)Docker基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(11):urllib 基础使用(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- 宋宝华:Linux设备驱动框架里的设计模式之——模板方法(Template Method)
本文系转载,著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 作者: 宋宝华 来源: 微信公众号linux阅码场(id: linuxdev) 前言 <设计模式>这本经典 ...
- python3.7.1安装Scrapy爬虫框架
python3.7.1安装Scrapy爬虫框架 环境:win7(64位), Python3.7.1(64位) 一.安装pyhthon 详见Python环境搭建:http://www.runoob.co ...
- 星际争霸2 AI开发(持续更新)
准备 我的环境是python3.6,sc2包0.11.1 机器学习包下载链接:pysc2 地图下载链接maps pysc2是DeepMind开发的星际争霸Ⅱ学习环境. 它是封装星际争霸Ⅱ机器学习API ...
- 深入理解Kafka必知必会(2)
Kafka目前有哪些内部topic,它们都有什么特征?各自的作用又是什么? __consumer_offsets:作用是保存 Kafka 消费者的位移信息 __transaction_state:用来 ...
- 在VMware通过挂载系统光盘搭建本地yum仓库
1.首先需要有一个VMware虚拟机: 2.进去虚拟机(这里用Linux下deCentOS进行演示): 3.用root账号进行登录,否则在根目录下没有一些操作权限: 4.打开终端: 5,输入命令“cd ...
- Redux中间件Redux-thunk的配置
当做固定写法吧 截图里少一个括号,已代码为主 import {createStore,applyMiddleware,compose} from 'redux' import thunk from ' ...
- IO流之ZipInputStream和ZipOutputStream的认识及使用
转载https://blog.csdn.net/weixin_39723544/article/details/80611810 工具类 import java.io.*;import java.ut ...
- 【Flink】Flink基础之WordCount实例(Java与Scala版本)
简述 WordCount(单词计数)作为大数据体系的标准示例,一直是入门的经典案例,下面用java和scala实现Flink的WordCount代码: 采用IDEA + Maven + Flink 环 ...
- Github远程库与Git本地库连接
Github远程库与Git本地库连接 以下有任何[]符号只是将内容扩起,输入命令不需要将[]加入 创建SSH Key 用户主目录有.ssh->id_rsa和id_rae.pub->直接跳过 ...
- 2019-9-17:基础学习,windows server 2008 r2,搭建web服务器和FTP服务器
一.信息服务iis管理器安装 1,点击打开“服务器管理器”-->选择“角色”-->选择“添加角色”,打开“添加角色向导” 2,点击“下一步”-->勾选“web服务器(IIS)”--& ...