机器学习预测时label错位对未来数据做预测
前言
这篇文章时承继上一篇机器学习经典模型使用归一化的影响。这次又有了新的任务,通过将label错位来对未来数据做预测。
实验过程
使用不同的归一化方法,不同得模型将测试集label错位,计算出MSE的大小;
不断增大错位的数据的个数,并计算出MSE,并画图。通过比较MSE(均方误差,mean-square error)的大小来得出结论
过程及结果
数据处理(和上一篇的处理方式相同):
test_sort_data = sort_data[:]
test_sort_target = sort_target[:] sort_data1 = _sort_data[:]
sort_data2 = _sort_data[:]
sort_target1 = _sort_target[:]
sort_target2 = _sort_target[:]
完整数据处理代码:
#按时间排序
sort_data = data.sort_values(by = 'time',ascending = True) sort_data.reset_index(inplace = True,drop = True)
target = data['T1AOMW_AV']
sort_target = sort_data['T1AOMW_AV']
del data['T1AOMW_AV']
del sort_data['T1AOMW_AV'] from sklearn.model_selection import train_test_split
test_sort_data = sort_data[:]
test_sort_target = sort_target[:] _sort_data = sort_data[:]
_sort_target = sort_target[:] from sklearn.model_selection import train_test_split
test_sort_data = sort_data[:]
test_sort_target = sort_target[:] sort_data1 = _sort_data[:]
sort_data2 = _sort_data[:]
sort_target1 = _sort_target[:]
sort_target2 = _sort_target[:] import scipy.stats as stats
dict_corr = {
'spearman' : [],
'pearson' : [],
'kendall' : [],
'columns' : []
} for i in data.columns:
corr_pear,pval = stats.pearsonr(sort_data[i],sort_target)
corr_spear,pval = stats.spearmanr(sort_data[i],sort_target)
corr_kendall,pval = stats.kendalltau(sort_data[i],sort_target) dict_corr['pearson'].append(abs(corr_pear))
dict_corr['spearman'].append(abs(corr_spear))
dict_corr['kendall'].append(abs(corr_kendall)) dict_corr['columns'].append(i) # 筛选新属性
dict_corr =pd.DataFrame(dict_corr)
dict_corr.describe()
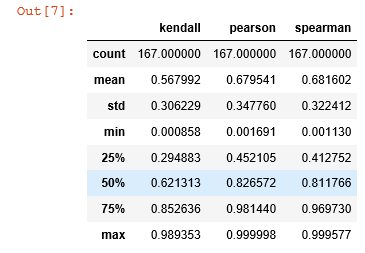
选取25%以上的;
new_fea = list(dict_corr[(dict_corr['pearson']>0.41) & (dict_corr['spearman']>0.45) & (dict_corr['kendall']>0.29)]['columns'].values)
包含下面的用来画图:
import matplotlib.pyplot as plt
lr_plt=[]
ridge_plt=[]
svr_plt=[]
RF_plt=[]
正常的计算mse(label没有移动):
from sklearn.linear_model import LinearRegression,Lasso,Ridge
from sklearn.preprocessing import MinMaxScaler,StandardScaler,MaxAbsScaler
from sklearn.metrics import mean_squared_error as mse
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
#最大最小归一化
mm = MinMaxScaler() lr = Lasso(alpha=0.5)
lr.fit(mm.fit_transform(sort_data1[new_fea]), sort_target1)
lr_ans = lr.predict(mm.transform(sort_data2[new_fea]))
lr_mse=mse(lr_ans,sort_target2)
lr_plt.append(lr_mse)
print('lr:',lr_mse) ridge = Ridge(alpha=0.5)
ridge.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
ridge_ans = ridge.predict(mm.transform(sort_data2[new_fea]))
ridge_mse=mse(ridge_ans,sort_target2)
ridge_plt.append(ridge_mse)
print('ridge:',ridge_mse) svr = SVR(kernel='rbf',C=,epsilon=0.1).fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
svr_ans = svr.predict(mm.transform(sort_data2[new_fea]))
svr_mse=mse(svr_ans,sort_target2)
svr_plt.append(svr_mse)
print('svr:',svr_mse) estimator_RF = RandomForestRegressor().fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
predict_RF = estimator_RF.predict(mm.transform(sort_data2[new_fea]))
RF_mse=mse(predict_RF,sort_target2)
RF_plt.append(RF_mse)
print('RF:',RF_mse) bst = xgb.XGBRegressor(learning_rate=0.1, n_estimators=, max_depth=, min_child_weight=, seed=,
subsample=0.7, colsample_bytree=0.7, gamma=0.1, reg_alpha=, reg_lambda=)
bst.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
bst_ans = bst.predict(mm.transform(sort_data2[new_fea]))
print('bst:',mse(bst_ans,sort_target2))
先让label移动5个:
change_sort_data2 = sort_data2.shift(periods=,axis=)
change_sort_target2 = sort_target2.shift(periods=-,axis=)
change_sort_data2.dropna(inplace=True)
change_sort_target2.dropna(inplace=True)
让label以5的倍数移动:
mm = MinMaxScaler() for i in range(,,):
print(i)
lr = Lasso(alpha=0.5)
lr.fit(mm.fit_transform(sort_data1[new_fea]), sort_target1)
lr_ans = lr.predict(mm.transform(change_sort_data2[new_fea]))
lr_mse=mse(lr_ans,change_sort_target2)
lr_plt.append(lr_mse)
print('lr:',lr_mse) ridge = Ridge(alpha=0.5)
ridge.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
ridge_ans = ridge.predict(mm.transform(change_sort_data2[new_fea]))
ridge_mse=mse(ridge_ans,change_sort_target2)
ridge_plt.append(ridge_mse)
print('ridge:',ridge_mse) svr = SVR(kernel='rbf',C=,epsilon=0.1).fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
svr_ans = svr.predict(mm.transform(change_sort_data2[new_fea]))
svr_mse=mse(svr_ans,change_sort_target2)
svr_plt.append(svr_mse)
print('svr:',svr_mse) estimator_RF = RandomForestRegressor().fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
predict_RF = estimator_RF.predict(mm.transform(change_sort_data2[new_fea]))
RF_mse=mse(predict_RF,change_sort_target2)
RF_plt.append(RF_mse)
print('RF:',RF_mse) # bst = xgb.XGBRegressor(learning_rate=0.1, n_estimators=, max_depth=, min_child_weight=, seed=,
# subsample=0.7, colsample_bytree=0.7, gamma=0.1, reg_alpha=, reg_lambda=)
# bst.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
# bst_ans = bst.predict(mm.transform(change_sort_data2[new_fea]))
# print('bst:',mse(bst_ans,change_sort_target2)) change_sort_target2=change_sort_target2.shift(periods=-,axis=)
change_sort_target2.dropna(inplace=True)
change_sort_data2 = change_sort_data2.shift(periods=,axis=)
change_sort_data2.dropna(inplace=True)
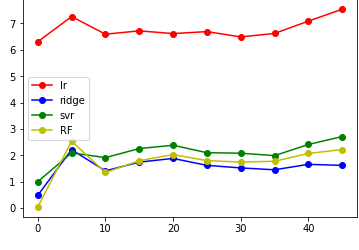
结果如图:
然后就是画图了;
plt.plot(x,lr_plt,label='lr',color='r',marker='o')
plt.plot(x,ridge_plt,label='ridge',color='b',marker='o')
plt.plot(x,svr_plt,label='svr',color='g',marker='o')
plt.plot(x,RF_plt,label='RF',color='y',marker='o')
plt.legend()
plt.show()
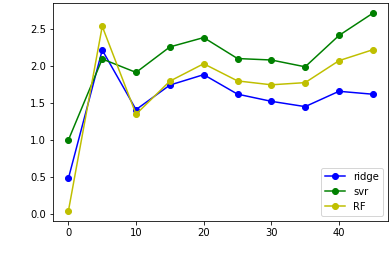
舍去lr,并扩大纵坐标:
#plt.plot(x,lr_plt,label='lr',color='r',marker='o')
plt.plot(x,ridge_plt,label='ridge',color='b',marker='o')
plt.plot(x,svr_plt,label='svr',color='g',marker='o')
plt.plot(x,RF_plt,label='RF',color='y',marker='o')
plt.legend()
plt.show()
其他模型只需将MinMaxScaler改为MaxAbsScaler,standarScaler即可;
总的来说,label的移动会使得mse增加,大约在label=10时候差异最小,结果最理想;
机器学习预测时label错位对未来数据做预测的更多相关文章
- 机器学习数据处理时label错位对未来数据做预测
这篇文章继上篇机器学习经典模型简单使用及归一化(标准化)影响,通过将测试集label(行)错位,将部分数据作为对未来的预测,观察其效果. 实验方式 以不同方式划分数据集和测试集 使用不同的归一化(标准 ...
- 好未来数据中台 Node.js BFF实践(一):基础篇
好未来数据中台 Node.js BFF实践系列文章列表: 基础篇 实战篇(TODO) 进阶篇(TODO) 好未来数据中台的Node.js中间层从7月份开始讨论可行性,截止到9月已经支持了4个平台,其中 ...
- kaggle——分销商产品未来销售情况预测
分销商产品未来销售情况预测 介绍 前面的几个实验中,都是根据提供的数据特征来构建模型,也就是说,数据集中会含有许多的特征列.本次将会介绍如何去处理另一种常见的数据,即时间序列数据.具体来说就是如何根据 ...
- 用$.getJSON() 和$.post()获取第三方数据做页面 ——惠品折页面(1)
用$.getJSON() 和$.post()获取第三方数据做页面 首页 index.html 页面 需要jquery 和 template-web js文件 可以直接在官网下载 中间导航条的固 ...
- 使用FormData数据做图片上传: new FormData() canvas实现图片压缩
使用FormData数据做图片上传: new FormData() canvas实现图片压缩 ps: 千万要使用append不要用set 苹果ios有兼容问题导致数据获取不到,需要后台 ...
- 【机器学习PAI实战】—— 玩转人工智能之商品价格预测
摘要: 我们经常思考机器学习,深度学习,以至于人工智能给我们带来什么?在数据相对充足,足够真实的情况下,好的学习模型可以发现事件本身的内在规则,内在联系.我们去除冗余的信息,可以通过最少的特征构建最简 ...
- 机器学习实战笔记(一)- 使用SciKit-Learn做回归分析
一.简介 这次学习的书籍主要是Hands-on Machine Learning with Scikit-Learn and TensorFlow(豆瓣:https://book.douban.com ...
- 机器学习可解释性系列 - 是什么&为什么&怎么做
机器学习可解释性分析 可解释性通常是指使用人类可以理解的方式,基于当前的业务,针对模型的结果进行总结分析: 一般来说,计算机通常无法解释它自身的预测结果,此时就需要一定的人工参与来完成可解释性工作: ...
- 背水一战 Windows 10 (20) - 绑定: DataContextChanged, UpdateSourceTrigger, 对绑定的数据做自定义转换
[源码下载] 背水一战 Windows 10 (20) - 绑定: DataContextChanged, UpdateSourceTrigger, 对绑定的数据做自定义转换 作者:webabcd 介 ...
随机推荐
- 使用ASP.NET Core 3.x 构建 RESTful API - 3.1 资源命名
之前讲了RESTful API的统一资源接口这个约束,里面提到了资源是通过URI来进行识别的,每个资源都有自己的URI.URI里还涉及到资源的名称,而针对资源的名称却没有一个标准来进行规范,但是业界还 ...
- ESP8266 使用AT指令
ESP8266 使用AT指令 问题:串口调试工具输入AT指令没返回结果 分析板子有两种模式 下载模式(默认) 运行模式 解决办法: 方法一:按下板子上的 RST 键位 方法二:使用 [安信可串口调试工 ...
- poj 3461 Oulipo(KMP)
Oulipo Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 49378 Accepted: 19617 Descript ...
- Python标准类型的分类
Python有3种不同的模型可以帮助对基本类型进行分类,这些类型更好的理解类型之间的相互关系以及他们的工作原理. 1 存储模型 能保存单个字面对象的类型,称为原子或标量存储: 能保存多个对 ...
- C语言程序设计100例之(17):百灯判亮
例17 百灯判亮 问题描述 有序号为1.2.3.….99.100的100盏灯从左至右排成一横行,且每盏灯各由一个拉线开关控制着,最初它们全呈关闭状态.有100个小朋友,第1位走过来把凡是序号为1的 ...
- epoll介绍及使用
小程序功能:简单的父子进程之间的通讯,子进程负责每隔1s不断发送"message"给父进程,不需要跑多个应用实例,不需要用户输入. 首先上代码 #include<assert ...
- GeoServer 查询sql视图
说明: 最近项目中遇到一个需求,需要统计管网的长度,但管网数据量非常大,前端用openlayers接口统计直接就奔溃了. 后尝试使用调后台接口查数据库的方式,虽然可行但是又要多一层与后台交互的工作. ...
- nslookup命令查找域名
了解 DNS 域名服务 熟悉使用 nslookup 查找 DNS 服务器上登记的域名,记录几次查询的结果, 及服务器的 ip. 1. 某个子域下的一部分主机的名字- IP 地址对应关系,如 flame ...
- 新闻实时分析系统Hive与HBase集成进行数据分析 Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- [翻译] 使用 Serverless 和 .NET Core 构建飞速发展的架构
原文:Fast growing architectures with serverless and .NET Core 作者:Samuele Resca Serverless 技术为开发人员提供了一种 ...