python数据结构——线性表
线性表
线性表可以看作是一种线性结构(可以分为顺序线性结构,离散线性结构)
1. 线性表的种类:
顺序表
元素存储在一大块连续存储的地址中,首元素存入存储区的起始位置,其余元素顺序存放。 (元素之间的逻辑关系与物理地址上相邻的关系相同)
链接表:
将表元素存放在通过链接构造的一系列存储块中
(元素的物理位置不相邻)
2. 顺序表的实现
顺序表的实现
思路:
$$
Loc(e_i) = Loc(e_0)+c*i
$$
其中c为存储一个元素所需要的空间,即size
元素内置:下图左 元素外置:下图右

- 元素内置:
必须保证每个存储单元的大小相同,即同类型
- 元素外置:
本质上存储的是元素存储的真实地址(即将元素外置,通过存储的该元素的地址从而找到该元素),可以存储如列表等含有多 种类型数据的可迭代对象(存储不同类型的数据,占用的内存你大小是不一样的)
补充:
int类型 数据在内存中占4个字结(byte,32位)
char类型数据在内存中占1个字结
内存中从下为0开始计数,反人类的设计,本质上是记录的偏移量
顺序表的结构:包含 表头信息 ,数据区 两个部分
表头信息: 该顺序表的容量,当前已经存储元素个数
数据区:数据区如下图与表头的关系
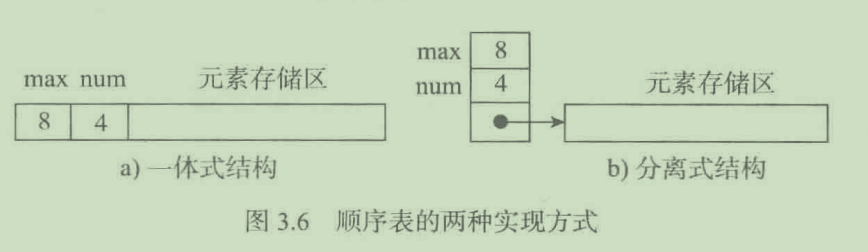
一体式:图左 分离式:图右
1. 分离式:便于顺序表的扩充,本质上是将原有第二段分表复制到一块内存区更大分表中,然后释放这个小的分表(通常使用分离式)
2. 一体式:顺序表的扩充本质上是复制到更大的内存块中,表头地址改变
元素存储区的扩充的策略问题(预留机制)
- 每次扩充增加固定的数目的存储(结省空间)
- 翻倍扩充法,每次扩充是上一次2倍或n倍(空间换时间)
3. 链表的实现
- 链表(链接表)的实现
特点:
1. 离散的进行存储,每次来一个数据申请一个数据空间
2. 采用手拉手的方式,让每个数据空间多出一块地址存放下一个数据空间的地址,即可以通过一个数据的数据空间可以找到与该数据直接相邻的数据空间(数据空间即结点)
3. 可以充分的利用计算机的存储空间
结点的构成: 数据区+链接区
单向链表
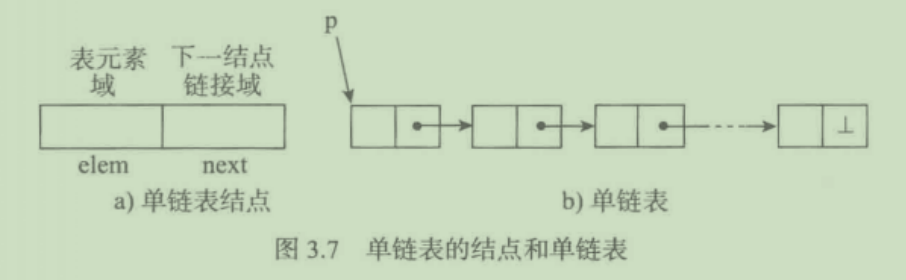
单向循环链表

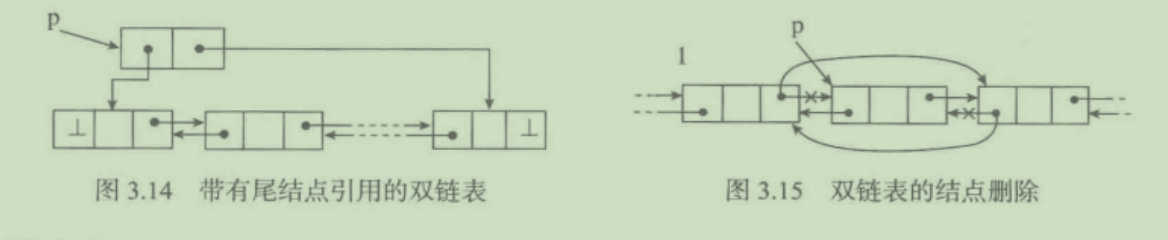
- 双向链表
4. 单向链表
只能从表头位置依次往后访问
头结点:第一个结点
尾结点:最后一个结点,链接区指向空
单向链表的常用操作
操作 含义 def init(self,node=None) 初始化单列表,设置头指针(头结点)指向第一个点解 def is_empty(self) 判断链表是都为空 def length(self) 返回链表长度(链表的结点数量) def traval(self) 遍历整个链表 def add(self,item) 头插法 向链表添加元素 def append(self,item) 尾插法 向链表添加数据区为item的结点 def insert(self,pos,item) 向链表的指定位置插入数据区为item的结点 def remove(self,item) 删除链表中的结点数据区的数据等于item的结点 def search(self,item) 查找链表中数据区为item的结点 时间复杂度的比较(单项列表与顺序表)
操作 单向链表 顺序表 查找元素 O(n) O(1) 插入元素 O(n) O(n) 修改元素 O(n) O(1) 删除元素 O(n) O(n) #注:单项链表与顺序表在存储元素时,主要区别如下
1. 单向链表能够从更加充分的利用计算机的存储空间(单向链表时离散存储,顺序表是顺序存储) 2. 单向链表存储与顺序表存储相同数量的元素时,单向链表耗费的内存空间更大(单向链表的每个结点除了需要开辟数据的存储空间,还开辟了存储下一个结点地址的存储空间,因而耗费存储空间更大) 3. 插入元素与删除元素时虽然者二者耗费的是时间复杂度相同,但本质意义不同:
单向链表的时间消耗主要耗费在结点的查询中
顺序表的时间消耗主要耗费在数据的移动中
5. 单向链表代码清单
#定义一个头结点
class Node(object):
def __init__(self,elem):
self.elem = elem
#初始状态next指向None
self.next = None
#定义单链表
#目标,需要把结点串联起来
#围绕增删改查的操作时针对链表的对象的方法
#因此对象方法此处定义的均为对象方法
class SingLinkList(object):
def __init__(self,node=None):
#这里定义的头结点相当于头指针指向第一个结点
self.__head = node
def is_empty(self):
#判断链表是都为空
return self.__head == None
def length(self):
"""链表长度"""
#cur游标遍历结点,与头指针一样指向头结点
cur = self.__head
#记录结点数量
count = 0
while cur != None:
count += 1
cur = cur.next
return count
def traval(self):
"""遍历整个链表"""
cur = self.__head
while cur != None:
print(cur.elem,end=' ')
cur = cur.next
#头插法
def add(self,item):
"""在头部添加元素(头插法)"""
node = Node(item)
node.next = self.__head
self.__head = node
#尾插法
def append(self,item):
"""在链表尾部添加(尾插法)"""
#先将传入的数据构造成结点
node = Node(item)
if self.is_empty():
#如果为空,则直接将node作为头结点加入
self.__head = node
else:
cur = self.__head
while cur.next != None:
cur = cur.next
cur.next = node
def insert(self,pos,item):
"""在指定位置添加元素
:param index 从0开始
"""
#构建pre指针,也指向头结点
if pos < 0:
self.add(item)
elif pos > linkList.length()-1:
self.append(item)
else:
pre = self.__head
count = 0
while count < (pos-1):
count+=1
pre = pre.next
#循环推出后,pre指向pos-1的位置
node = Node(item)
node.next = pre.next
pre.next = node
def remove(self,item):
"""删除结点"""
cur = self.__head
pre = None
while cur != None:
if cur.elem == item:
#先判断此结点是否为头结点
if cur == self.__head:
self.__head = cur.next
break
else:
pre = cur
cur = cur.next
def search(self,item):
"""查找结点是否存在"""
cur = self.__head
while cur != None:
if cur.elem == item:
return True
else:
cur = cur.next
return False
6. 双向链表
可以从前往后访问,也可以从后往前访问
双向链表的常用操作
参考单向链表,基本类似,只需要修改部分方法即可,在此不做过多赘述
修改部分方法的列表如下
操作 含义 def add(self,item) 双向链表的头插法 def append(self,item) 双向链表的尾插法 def insert(self,pos,item) 插入元素 def remove(self,item) 删除元素 #注:
1. 双向链表的实现与单项链基本相似,仅在单向链表的每个结点前加入了一个前驱游标(指针prev)
2. 实现方法中仅修改了四个关于元素添加和删除的方法,其余均与单向链表一致,详情见下面的代码清单
3. 方便代码重用性,减少代码量,可继承实现单向链表的类(此问题不在赘述,这里重点讨论数据结构如何实现)
7. 双向链表代码清单
#双向链表的结点重新定义,增加了前驱游标(指针)
class Node(object):
"""双向链表的结点"""
def __init__(self,item):
self.elem = item
self.next = None
self.prev = None
class DoubleLinkList(object):
"""双链表"""
def __init__(self,node=None):
#这里定义的头节点相当于头指针指向第一个节点
self.__head = node
#头插法
def add(self,item):
"""在头部添加元素(头插法)"""
node = Node(item)
node.next = self.__head
self.__head.prev = node
self.__head = node
#也可以一下方法,方法不唯一
# node.next.prev = node
#尾插法
def append(self,item):
"""在链表尾部添加(尾插法)"""
#先将传入的数据构造成节点
node = Node(item)
if self.is_empty():
#如果为空,则直接将node作为头节点加入
self.__head = node
else:
cur = self.__head
while cur.next != None:
cur = cur.next
cur.next = node
node.prev = cur
def insert(self,pos,item):
"""在指定位置添加元素
:param index 从0开始
"""
#构建pre指针,也指向头节点
if pos < 0:
self.add(item)
elif pos > self.length()-1:
self.append(item)
else:
cur = self.__head
count = 0
while count < (pos-1):
count+=1
cur = cur.next
#循环推出后,pre指向pos-1的位置
node = Node(item)
node.next = cur
node.prev = cur.prev
node.prev.next = node
cur.prev = node
def remove(self,item):
"""删除节点"""
cur = self.__head
while cur != None:
if cur.elem == item:
#先判断此节点是否为头节点
if cur == self.__head:
self.__head = cur.next
if cur.next:
#判断链表是否只有一个结点
cur.next.prev = None
else:
cur.prev.next = cur.next
if cur.next:
cur.next.prev = cur.prev
break
else:
cur = cur.next
8. 单向循环链表
也是在单向链表的基础上加以改进,与单向链表唯一的区别就是尾结点的next不在指向None,而是指向了第一个节点
考虑问题的思路:以单向循环链表为例,先考虑一般情况
在考虑特殊情况比如表头结点,表为节点,表是都为 空,表内只有一个节点等特殊情况,情况考虑完全,则代码实现后,该结构则实现的比较完全
单向循环链表的操作
操作 含义 def init(self,node=None) 初始化单列表,设置头指针(头结点)指向第一个点解 def is_empty(self) 判断链表是都为空 def length(self) 返回链表长度(链表的结点数量) def traval(self) 遍历整个链表 def add(self,item) 头插法 向链表添加元素 def append(self,item) 尾插法 向链表添加数据区为item的结点 def insert(self,pos,item) 向链表的指定位置插入数据区为item的结点 def remove(self,item) 删除链表中的结点数据区的数据等于item的结点 def search(self,item) 查找链表中数据区为item的结点 和单向链表情况基本类似,这里不再过多赘述,仅需要在单项链表的基础上考虑多种特殊情况,见下面的代码清单(已测试,无问题,此处省略测试代码,读者可自行测试)
9. 单向循环链表代码清单
#节点实现
class Node(object):
def __init__(self,elem):
self.elem = elem
#初始状态next指向None
self.next = None
#定义单向循环链表
class SingleCycleLinkList(object):
"""单向循环链表"""
def __init__(self,node=None):
#这里定义的头节点相当于头指针指向第一个节点
self.__head = node
if node:
node.next = node
def is_empty(self):
#判断链表是都为空
return self.__head == None
def length(self):
"""链表长度"""
if self.is_empty():
return 0
#cur游标遍历节点,与头指针一样指向头节点
cur = self.__head
#记录节点数量
count = 1
while cur.next != self.__head:
count += 1
cur = cur.next
return count
def traval(self):
"""遍历整个链表"""
if self.is_empty():
return
cur = self.__head
while cur.next!= self.__head:
print(cur.elem,end=' ')
cur = cur.next
#退出循环,cur指向尾结点,但是尾节点的元素未打印
print(cur.elem)
#头插法
def add(self,item):
"""在头部添加元素(头插法)"""
node = Node(item)
if self.is_empty():
self.__head = node
node.next = node
else:
# node.next = self.__head
cur = self.__head
#退出循环之后cur指向的就是尾结点
while cur.next != self.__head :
cur = cur.next
node.next = self.__head
cur.next = node
self.__head = node
#尾插法
def append(self,item):
"""在链表尾部添加(尾插法)"""
#先将传入的数据构造成节点
node = Node(item)
if self.is_empty():
#如果为空,则直接将node作为头节点加入
self.__head = node
node.next = node
else:
cur = self.__head
while cur.next != self.__head:
cur = cur.next
cur.next= node
node.next = self.__head
def insert(self,pos,item):
"""在指定位置添加元素
:param index 从0开始
"""
#构建pre指针,也指向头节点
if pos < 0:
self.add(item)
elif pos > linkList.length()-1:
self.append(item)
else:
pre = self.__head
count = 0
while count < (pos-1):
count+=1
pre = pre.next
#循环推出后,pre指向pos-1的位置
node = Node(item)
node.next = pre.next
pre.next = node
#这个方法改写代码较多,请着重查看
def remove(self,item):
"""删除节点"""
if self.__head == None:
return
cur = self.__head
#判断该链表是否只有一个结点
#若只有一个结点
if cur.next == self.__head:
#若该结点元素等于item,则删除该节结点
if cur.elem == item:
self.__head = None
return
#否则该链表没有与此元素相等的结点,直接返回
return
pre = None
while cur.next != self.__head:
if cur.elem == item:
#先判断此节点是否为头节点
if cur == self.__head:
#头节点情况
#寻找尾结点
rear = self.__head
while rear.next != self.__head:
rear = rear.next
self.__head = cur.next
rear.next = self.__head
else:
#中间结点删除
pre.next = cur.next
return
else:
pre = cur
cur = cur.next
#尾部节点
if cur.elem == item:
pre.next = cur.next
def search(self,item):
"""查找节点是否存在"""
if self.is_empty():
return False
cur = self.__head
while cur.next != self.__head:
if cur.elem == item:
return True
else:
cur = cur.next
if cur.elem ==item:
return True
return False
10. 其他扩展
双向链表可扩展至双向循环链表,此处时间不够,待日后补上
python数据结构——线性表的更多相关文章
- [从今天开始修炼数据结构]线性表及其实现以及实现有Itertor的ArrayList和LinkedList
一.线性表 1,什么是线性表 线性表就是零个或多个数据元素的有限序列.线性表中的每个元素只能有零个或一个前驱元素,零个或一个后继元素.在较复杂的线性表中,一个数据元素可以由若干个数据项组成.比如牵手排 ...
- [数据结构-线性表1.2] 链表与 LinkedList<T>(.NET 源码学习)
[数据结构-线性表1.2] 链表与 LinkedList<T> [注:本篇文章源码内容较少,分析度较浅,请酌情选择阅读] 关键词:链表(数据结构) C#中的链表(源码) 可空类 ...
- 数据结构线性表(js实现)
最近在复习数据结构的过程中,发现基本上数据结构都是用C来实现的,自己之前学习的时候也是用C去写的,由于目前对js更为熟悉一些,所以这里选择使用js去实现其中的某些算法和结构.实际上算法和语言关系不大, ...
- C# 数据结构 线性表(顺序表 链表 IList 数组)
线性表 线性表是最简单.最基本.最常用的数据结构.数据元素 1 对 1的关系,这种关系是位置关系. 特点 (1)第一个元素和最后一个元素前后是没有数据元素,线性表中剩下的元素是近邻的,前后都有元素. ...
- C#实现数据结构——线性表(下)
线性表链式存储结构 看了线性表的顺序存储,你肯定想线性表简是挺简单,但是我一开始怎么会知道有多少人排队?要分配多大的数组?而且插入和删除一个元素也太麻烦了,所有元素都要前移/后移,效率又低. 那怎么办 ...
- C#实现数据结构——线性表(上)
什么是线性表 数据结构中最常用也最简单的应该就是线性表,它是一种线性结构(废话,不是线性结构怎么会叫线性表?当然不是废话,古人公孙龙就说白马非马,现代生物学家也说鲸鱼不是鱼). 那什么是线性结构? 按 ...
- [置顶] ※数据结构※→☆线性表结构(queue)☆============循环队列 顺序存储结构(queue circular sequence)(十)
循环队列 为充分利用向量空间,克服"假溢出"现象的方法是:将向量空间想象为一个首尾相接的圆环,并称这种向量为循环向量.存储在其中的队列称为循环队列(Circular Queue). ...
- [置顶] ※数据结构※→☆线性表结构(queue)☆============优先队列 链式存储结构(queue priority list)(十二)
优先队列(priority queue) 普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除.在优先队列中,元素被赋予优先级.当访问元素时,具有最高优先级的元素最先删除.优先队列具有 ...
- [置顶] ※数据结构※→☆线性表结构(stack)☆============栈 序列表结构(stack sequence)(六)
栈(stack)在计算机科学中是限定仅在表尾进行插入或删除操作的线性表.栈是一种数据结构,它按照后进先出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据.栈 ...
随机推荐
- 监控LVS
监控LVS #!/usr/bin/python-2.6.6 #data 2017-10-17 #auth liuchao import commands,os,time #-------------- ...
- Java----面向对象(继承&多态)
一.继承 什么是继承 ? 让类与类之间产生了子父类关系 ; 继承的好处是: 提高代码的复用性和维护性 java中继承的特点是: 只支持单继承.不支持多继承,但是可以多层继承; 四种权限修饰符是 : p ...
- 你了解HTTPS,但你可能不了解X.509
世上根本就没有HTTPS协议,只有HTTP协议.——知乎某答友 某天,收到领导指示:学习一下X.509相关原理. 很多开发者可能和我一样觉得X.509这个词很陌生,但其实我们经常和它打交道,属于典型的 ...
- idea 2018.3.4安装破解
电脑环境:win10 64位 1.idea官网下载: 链接:https://www.jetbrains.com/idea/,如下图: 2.JDK官网下载: 链接:https://www.oracle. ...
- Mybatis获取代理对象
mybatis-config.xml里标签可以放置多个environment,这里可以切换test和develop数据源 databaseIdProvider提供多种数据库,在xml映射文件里选择da ...
- Qt基于sqlite数据库的管理小软件
闲来无事,写了一个基于sqlite的数据库管理小软件. 先上图 中心思想就是: 创建一个数据库 然后每一个分组对应一个数据表 然后遍历该数据表.将名字以treewidgetItem显示出来.添加删除实 ...
- SpringBoot 集成Jedis操作set
题外话: Redis是个有趣的东西,相信搞java的或多或少都会用到,面试时也总离不开问Redis,之前觉得redis只是用做缓存,飞快!也因为最初在封装底层的时候,使用Redisson,所以大部分都 ...
- 消息中间件-activemq安全机制
activemq作为消息中间件这样一个独立的个体存在,连通用户和服务器.如果没有一套完备的安全机制去设置用户权限设置消息分发机制可想后果是非常严重.ActiveMQ如果不加入安全机制的话,任何人只要知 ...
- element ui 退出功能
<template> <el-container class="home-wrapper"> <el-header> <el-row ty ...
- Spring.Net 依赖注入
一.Spring.Net概念 编程模型(Ioc,DI方式) IoC:控制反转 原来创建对象的权利由程序来控制就是new实例,IoC就是改由容器来创建,相当于一个工厂, DI:依赖注入 没有IoC就没有 ...