【Redis】缓存穿透与缓存雪崩
一、缓存雪崩
1.1 缓存雪崩产生的原因
缓存雪崩通俗简单的理解就是:由于原有缓存失效(或者数据未加载到缓存中),新缓存未到期间(缓存正常从Redis中获取,如下图)所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机,造成系统的崩溃。
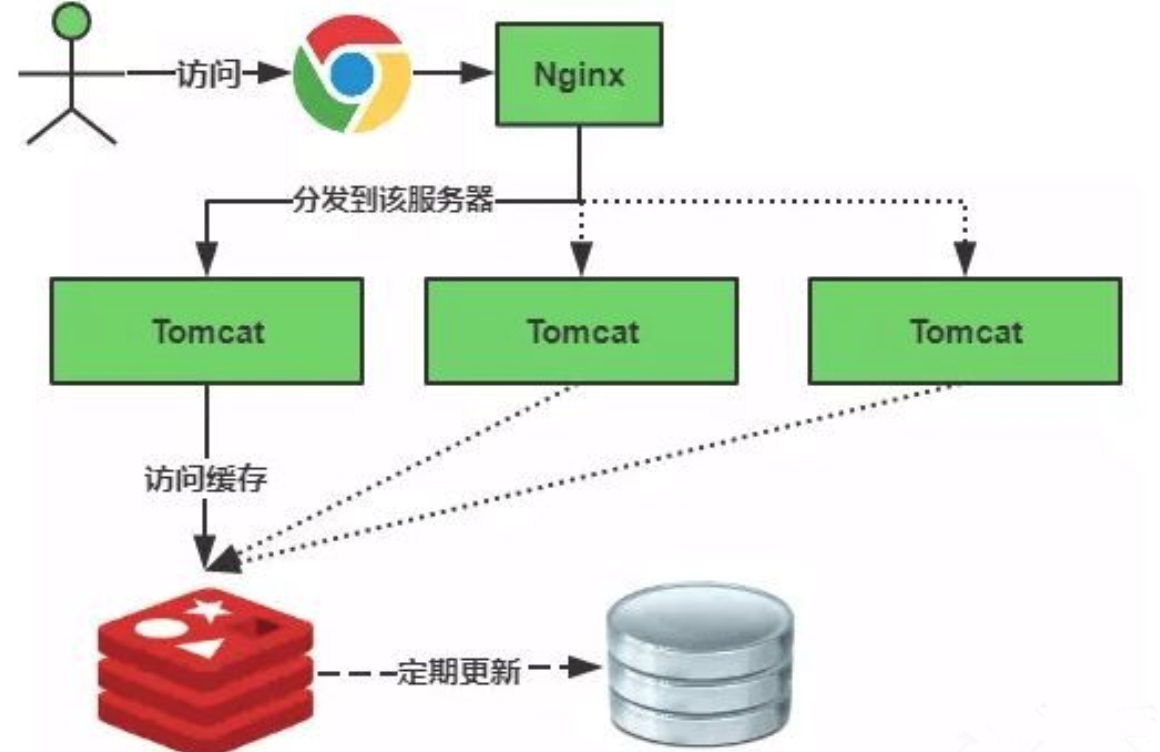

缓存失效的时候
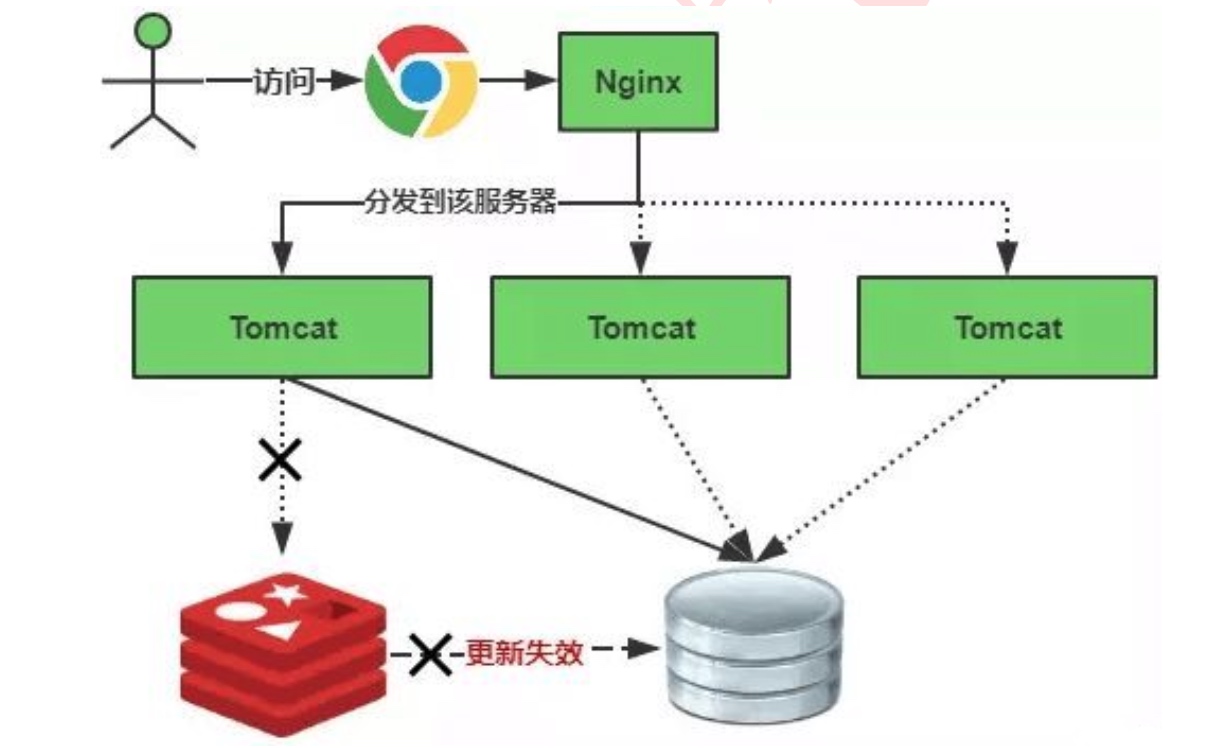

1.2 解决方案
缓存失效时的雪崩效应对底层系统的冲击非常可怕!那有什么办法来解决这个问题呢?基本解决思路如下:
- 分布式锁:大多数系统设计者考虑用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,避免缓存失效时对数据库造成太大的压力,虽然能够在一定的程度上缓解了数据库的压力但是与此同时又降低了系统的吞吐量。
- 使用消息中间件
- 一级和二级缓存(Redis+Ehcache)
- 均摊分配redis key的失效时间,分析用户的行为,尽量让缓存失效的时间均匀分布。
- 如果是因为某台缓存服务器宕机,可以考虑做主备,比如:redis主备,但是双缓存涉及到更新事务的问题,update可能读到脏数据,需要好好解决。
1.3 锁的方式
- 使用分布式锁(本地锁)解决学崩效应当突然有大量的请求到数据库的服务器的时候,进行对数据库服务请求限制。这个我们可以使用锁的机制,保证只有一个线程(请求)进行数据库的操作访问,否则情况直接排队等待。 (如果是集群服务器的话,那么就需要使用分布锁、单机版本可以使用本锁),确实可以解决服务雪崩效应,但是会减少服务器吞吐量问题。(适合于小项目)
- 在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
@RequestMapping("/getUsers")
public Users getByUsers(Long id) {
// 1.先查询redis
String key = this.getClass().getName() + "-" + Thread.currentThread().getStackTrace()[1].getMethodName()
+ "-id:" + id;
String userJson = redisService.getString(key);
if (!StringUtils.isEmpty(userJson)) {
Users users = JSONObject.parseObject(userJson, Users.class);
return users;
}
Users user = null;
try {
lock.lock();
// 查询db
user = userMapper.getUser(id);
redisService.setSet(key, JSONObject.toJSONString(user));
} catch (Exception e) {
} finally {
lock.unlock(); // 释放锁
}
return user;
}
- 注意:加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建期间key是锁着的,这是过来1000个请求999个都在阻塞的。同样会导致用户等待超时,这是个治标不治本的方法。
1.4 消息中间件
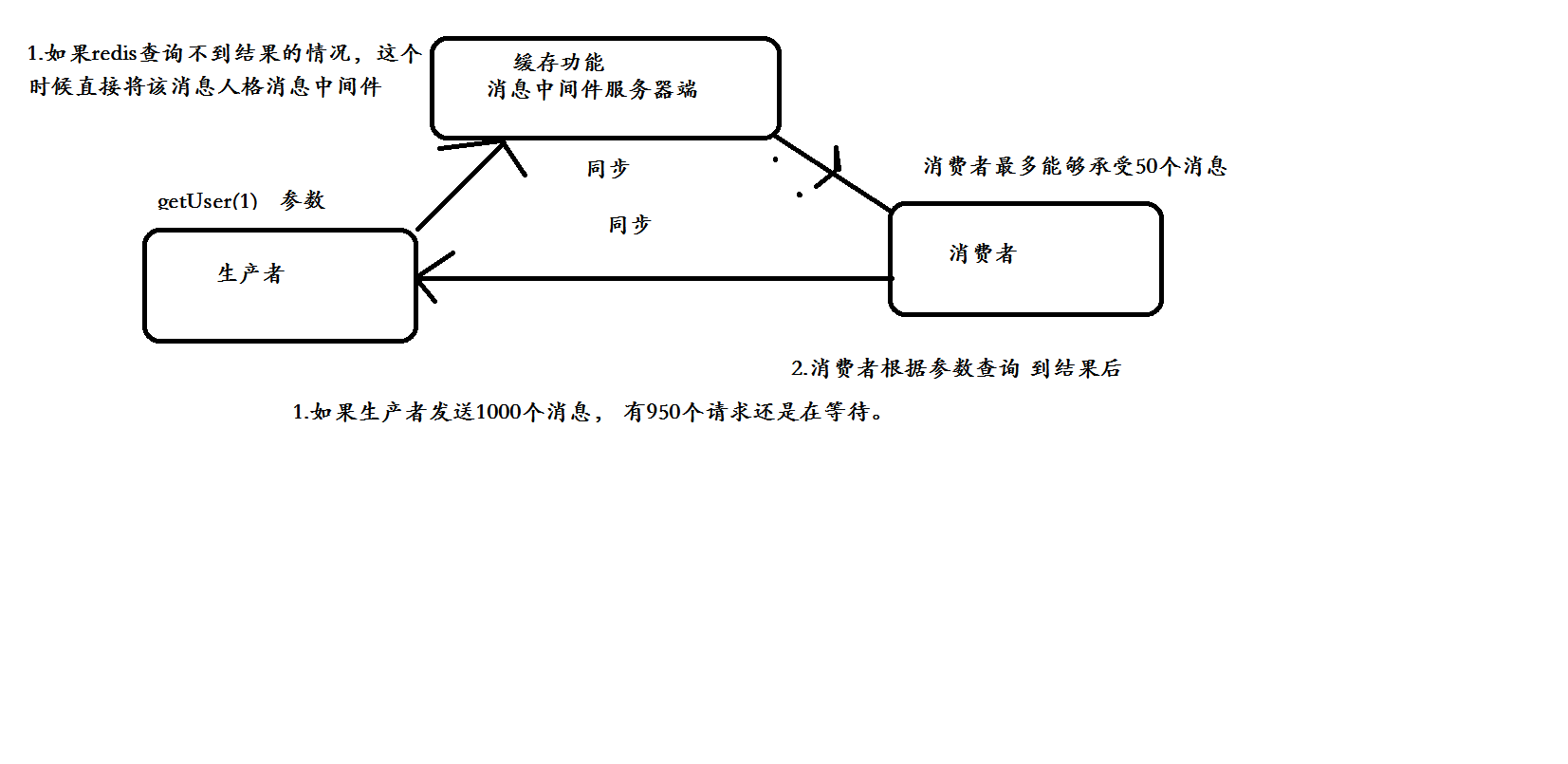

1.5 一级和二级缓存
做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期(此点为补充)
1.6 均摊分配redis key 失效时间
不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。Redis的数据失效时间不要设置为一致
二、缓存穿透
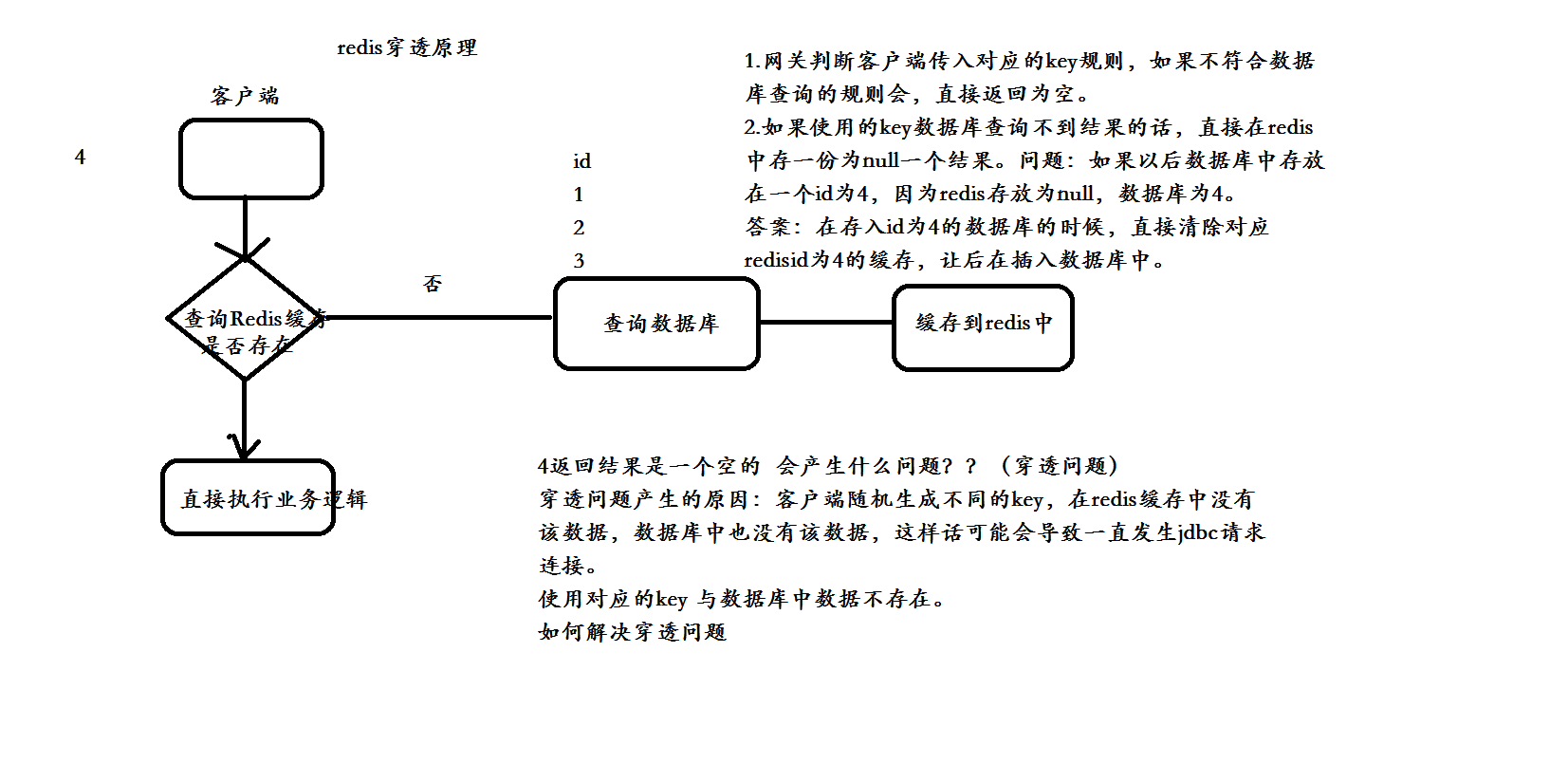

- 缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
- 解决的办法就是:如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。
- 把空结果,也给缓存起来,这样下次同样的请求就可以直接返回空了,即可以避免当查询的值为空时引起的缓存穿透。同时也可以单独设置个缓存区域存储空值,对要查询的key进行预先校验,然后再放行给后面的正常缓存处理逻辑。
private String SIGN_KEY = "${NULL}";
public String getByUsers2(Long id) {
// 1.先查询redis
String key = this.getClass().getName() + "-" + Thread.currentThread().getStackTrace()[1].getMethodName()
+ "-id:" + id;
String userName = redisService.getString(key);
if (!StringUtils.isEmpty(userName)) {
return userName;
}
System.out.println("######开始发送数据库DB请求########");
Users user = userMapper.getUser(id);
String value = null;
if (user == null) {
// 标识为null
value = SIGN_KEY;
} else {
value = user.getName();
}
redisService.setString(key, value);
return value;
}
- 把空结果,也给缓存起来,这样下次同样的请求就可以直接返回空了,即可以避免当查询的值为空时引起的缓存穿透。同时也可以单独设置个缓存区域存储空值,对要查询的key进行预先校验,然后再放行给后面的正常缓存处理逻辑。
- 注意:再给对应的ip存放真值的时候,需要先清除对应的之前的空缓存。
热点key
热点key:某个key访问非常频繁,当key失效的时候有打量线程来构建缓存,导致负载增加,系统崩溃。解决办法:
- 使用锁,单机用synchronized,lock等,分布式用分布式锁。
- 缓存过期时间不设置,而是设置在key对应的value里。如果检测到存的时间超过过期时间则异步更新缓存。
- 在value设置一个比过期时间t0小的过期时间值t1,当t1过期的时候,延长t1并做更新缓存操作。
【Redis】缓存穿透与缓存雪崩的更多相关文章
- Redis缓存穿透和缓存雪崩以及解决方案
Redis缓存穿透和缓存雪崩以及解决方案 Redis缓存穿透和缓存雪崩以及解决方案缓存穿透解决方案布隆过滤缓存空对象比较缓存雪崩解决方案保证缓存层服务高可用性依赖隔离组件为后端限流并降级数据预热缓存并 ...
- 预防Redis缓存穿透、缓存雪崩解决方案
最近面试中遇到redis缓存穿透.缓存雪崩等问题,特意了解下. redis缓存穿透: 缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有.这样就导致用户查询的时候,在缓存中找不到,每次都要去 ...
- Redis 缓存穿透,缓存击穿,缓存雪崩的解决方案分析
设计一个缓存系统,不得不要考虑的问题就是:缓存穿透.缓存击穿与失效时的雪崩效应. 一.什么样的数据适合缓存? 分析一个数据是否适合缓存,我们要从访问频率.读写比例.数据一致性等要求去分析. 二.什么 ...
- redis与mysql性能对比、redis缓存穿透、缓存雪崩
写在开始 redis是一个基于内存hash结构的缓存型db.其优势在于速读写能力碾压mysql.由于其为基于内存的db所以存储数据量是受限的. redis性能 redis读写性能测试redis官网测试 ...
- Redis缓存雪崩、缓存穿透、缓存击穿、缓存降级、缓存预热、缓存更新
Redis缓存能够有效地加速应用的读写速度,就DB来说,Redis成绩已经很惊人了,且不说memcachedb和Tokyo Cabinet之流,就说原版的memcached,速度似乎也只能达到这个级别 ...
- redis缓存穿透,缓存击穿,缓存雪崩原因+解决方案
一.前言 在我们日常的开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题,可是一旦涉及大数据量的需求,比如一些商品抢购的情景,或者是 ...
- SpringBoot微服务电商项目开发实战 --- Redis缓存雪崩、缓存穿透、缓存击穿防范
最近已经推出了好几篇SpringBoot+Dubbo+Redis+Kafka实现电商的文章,今天再次回到分布式微服务项目中来,在开始写今天的系列五文章之前,我先回顾下前面的内容. 系列(一):主要说了 ...
- redis缓存穿透,缓存击穿,缓存雪崩
概念解释 redis 缓存穿透 key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源.比如用一个不存在的用户id获取用户信息,不论缓存还是数据库 ...
- redis的缓存雪崩、缓存穿透和缓存击穿
缓存雪崩: 比如给缓存中的key设置了统一的过期时间,而在过期时间点,有大量的请求进来,这个时候redis中没有用户请求的资源,所以所有的请求会全部拥到数据库,如果数据库有报警监测的话,可能会报一下警 ...
- Redis缓存穿透,缓存击穿,缓存雪崩,热点Key
导读 使用Redis难免会遇到Redis缓存穿透,缓存击穿,缓存雪崩,热点Key的问题.有些同学可能只是会用Redis来存取,基本都是用项目里封装的工具类来操作.但是作为开发,我们使用Redis时可能 ...
随机推荐
- 分布式ID系列(2)——UUID适合做分布式ID吗
UUID的生成策略: UUID的方式能生成一串唯一随机32位长度数据,它是无序的一串数据,按照开放软件基金会(OSF)制定的标准计算,UUID的生成用到了以太网卡地址.纳秒级时间.芯片ID码和许多可能 ...
- .NET Core 3.0预览版7中的ASP.NET Core和Blazor更新
.NET Core 3.0 Preview 7现已推出,它包含一系列ASP.NET Core和Blazor的新更新. 以下是此预览中的新功能列表: 最新的Visual Studio预览包括.NET C ...
- Python 四大主流 Web 编程框架
Python 四大主流 Web 编程框架 目前Python的网络编程框架已经多达几十个,逐个学习它们显然不现实.但这些框架在系统架构和运行环境中有很多共通之处,本文带领读者学习基于Python网络框架 ...
- java并发编程(二十三)----(JUC集合)ConcurrentSkipListMap介绍
ConcurrentSkipListMap提供了一种线程安全的并发访问的排序映射表.内部是SkipList(跳表)结构实现,在理论上能够在O(log(n))时间内完成查找.插入.删除操作. 理解Ski ...
- Oracle中查看最近被修改过的表的方法
1.select uat.table_name from user_all_tables uat 该SQL可以获得所有用户表的名称 2.select object_name, created,last ...
- Python递归函数,二分查找算法
目录 一.初始递归 二.递归示例讲解 二分查找算法 一.初始递归 递归函数:在一个函数里在调用这个函数本身. 递归的最大深度:998 正如你们刚刚看到的,递归函数如果不受到外力的阻止会一直执行下去.但 ...
- 再次学习Git版本控制工具
Git 究竟是怎样的一个系统呢?为什么在SVN作为版本控制工具已经非常流行的时候,还有Git这样一个版本控制工具呢?Git和SVN的区别在哪儿呢?Git优势又在哪呢?下面PHP程序员雷雪松带你一起详细 ...
- 详解慢查询日志的相关设置及mysqldumpslow工具
概述 mysql慢查询日志是mysql提供的一种日志记录,它是用来记录在mysql中相应时间超过阈值的语句,就是指运行时间超过long_query_time值的sql,会被记录在慢查询日志中.long ...
- Elasticsearch由浅入深(一)
什么是Elasticsearch 什么是搜索 百度:我们比如说想找寻任何的信息的时候,就会上百度去搜索一下,比如说找一部自己喜欢的电影,或者说找一本喜欢的书,或者找一条感兴趣的新闻(提到搜索的第一印象 ...
- mave 笔记
有时maven在myeclipse配置不好用,可直接cmd到项目目录下执行下面命令,将maven包下载到当前文件夹的lib目录下 mvn dependency:copy-dependencies -D ...