09. Go 语言并发
Go 语言并发
并发指在同一时间内可以执行多个任务。并发编程含义比较广泛,包含多线程编程、多进程编程及分布式程序等。本章讲解的并发含义属于多线程编程。
Go 语言通过编译器运行时(runtime),从语言上支持了并发的特性。Go 语言的并发通过 goroutine 特性完成。goroutine 类似于线程,但是可以根据需要创建多个 goroutine 并发工作。goroutine 是由 Go 语言的运行时调度完成,而线程是由操作系统调度完成。
Go 语言还提供 channel 在多个 goroutine 间进行通信。goroutine 和 channel 是 Go 语言秉承的 CSP(Communicating Sequential Process)并发模式的重要实现基础。本章中,将详细为大家讲解 goroutine 和 channel 及相关特性。
Go语言并发简述(并发的优势)
有人把Go语言比作 21 世纪的C语言,第一是因为Go语言设计简单,第二则是因为 21 世纪最重要的就是并发程序设计,而 Go 从语言层面就支持并发。同时实现了自动垃圾回收机制。
Go语言的并发机制运用起来非常简便,在启动并发的方式上直接添加了语言级的关键字就可以实现,和其他编程语言相比更加轻量。
下面来介绍几个概念:
进程/线程
进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。
线程是进程的一个执行实体,是 CPU 调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。
一个进程可以创建和撤销多个线程,同一个进程中的多个线程之间可以并发执行。
并发/并行
多线程程序在单核心的 cpu 上运行,称为并发;多线程程序在多核心的 cpu 上运行,称为并行。
并发与并行并不相同,并发主要由切换时间片来实现“同时”运行,并行则是直接利用多核实现多线程的运行,Go程序可以设置使用核心数,以发挥多核计算机的能力。
协程/线程
协程:独立的栈空间,共享堆空间,调度由用户自己控制,本质上有点类似于用户级线程,这些用户级线程的调度也是自己实现的。
线程:一个线程上可以跑多个协程,协程是轻量级的线程。
优雅的并发编程范式,完善的并发支持,出色的并发性能是Go语言区别于其他语言的一大特色。使用Go语言开发服务器程序时,就需要对它的并发机制有深入的了解。
Goroutine 介绍
goroutine 是一种非常轻量级的实现,可在单个进程里执行成千上万的并发任务,它是Go语言并发设计的核心。
说到底 goroutine 其实就是线程,但是它比线程更小,十几个 goroutine 可能体现在底层就是五六个线程,而且Go语言内部也实现了 goroutine 之间的内存共享。
使用 go 关键字就可以创建 goroutine,将 go 声明放到一个需调用的函数之前,在相同地址空间调用运行这个函数,这样该函数执行时便会作为一个独立的并发线程,这种线程在Go语言中则被称为 goroutine。
goroutine 的用法如下:
//go 关键字放在方法调用前新建一个 goroutine 并执行方法体
go GetThingDone(param1, param2);
//新建一个匿名方法并执行
go func(param1, param2) {
}(val1, val2)
//直接新建一个 goroutine 并在 goroutine 中执行代码块
go {
//do someting...
}因为 goroutine 在多核 cpu 环境下是并行的,如果代码块在多个 goroutine 中执行,那么我们就实现了代码的并行。
如果需要了解程序的执行情况,怎么拿到并行的结果呢?需要配合使用channel进行。
channel
channel 是Go语言在语言级别提供的 goroutine 间的通信方式。我们可以使用 channel 在两个或多个 goroutine 之间传递消息。
channel 是进程内的通信方式,因此通过 channel 传递对象的过程和调用函数时的参数传递行为比较一致,比如也可以传递指针等。如果需要跨进程通信,我们建议用分布式系统的方法来解决,比如使用 Socket 或者 HTTP 等通信协议。Go语言对于网络方面也有非常完善的支持。
channel 是类型相关的,也就是说,一个 channel 只能传递一种类型的值,这个类型需要在声明 channel 时指定。如果对 Unix 管道有所了解的话,就不难理解 channel,可以将其认为是一种类型安全的管道。
定义一个 channel 时,也需要定义发送到 channel 的值的类型,注意,必须使用 make 创建 channel,代码如下所示:
ci := make(chan int)
cs := make(chan string)
cf := make(chan interface{})回到在 Windows 和 Linux 出现之前的古老年代,在开发程序时并没有并发的概念,因为命令式程序设计语言是以串行为基础的,程序会顺序执行每一条指令,整个程序只有一个执行上下文,即一个调用栈,一个堆。
并发则意味着程序在运行时有多个执行上下文,对应着多个调用栈。我们知道每一个进程在运行时,都有自己的调用栈和堆,有一个完整的上下文,而操作系统在调度进程的时候,会保存被调度进程的上下文环境,等该进程获得时间片后,再恢复该进程的上下文到系统中。
从整个操作系统层面来说,多个进程是可以并发的,那么并发的价值何在?下面我们先看以下几种场景。
1) 一方面我们需要灵敏响应的图形用户界面,一方面程序还需要执行大量的运算或者 IO 密集操作,而我们需要让界面响应与运算同时执行。
2) 当我们的 Web 服务器面对大量用户请求时,需要有更多的“Web 服务器工作单元”来分别响应用户。
3) 我们的事务处于分布式环境上,相同的工作单元在不同的计算机上处理着被分片的数据,计算机的 CPU 从单内核(core)向多内核发展,而我们的程序都是串行的,计算机硬件的能力没有得到发挥。
4) 我们的程序因为 IO 操作被阻塞,整个程序处于停滞状态,其他 IO 无关的任务无法执行。
从以上几个例子可以看到,串行程序在很多场景下无法满足我们的要求。下面我们归纳了并发程序的几条优点,让大家认识到并发势在必行:
- 并发能更客观地表现问题模型;
- 并发可以充分利用 CPU 核心的优势,提高程序的执行效率;
- 并发能充分利用 CPU 与其他硬件设备固有的异步性。
Go语言goroutine(轻量级线程)
在编写 Socket 网络程序时,需要提前准备一个线程池为每一个 Socket 的收发包分配一个线程。开发人员需要在线程数量和 CPU 数量间建立一个对应关系,以保证每个任务能及时地被分配到 CPU 上进行处理,同时避免多个任务频繁地在线程间切换执行而损失效率。
虽然,线程池为逻辑编写者提供了线程分配的抽象机制。但是,如果面对随时随地可能发生的并发和线程处理需求,线程池就不是非常直观和方便了。能否有一种机制:使用者分配足够多的任务,系统能自动帮助使用者把任务分配到 CPU 上,让这些任务尽量并发运作。这种机制在 Go语言中被称为 goroutine。
goroutine 是 Go语言中的轻量级线程实现,由 Go 运行时(runtime)管理。Go 程序会智能地将 goroutine 中的任务合理地分配给每个 CPU。
Go 程序从 main 包的 main() 函数开始,在程序启动时,Go 程序就会为 main() 函数创建一个默认的 goroutine。
使用普通函数创建 goroutine
Go 程序中使用 go 关键字为一个函数创建一个 goroutine。一个函数可以被创建多个 goroutine,一个 goroutine 必定对应一个函数。
1) 格式
为一个普通函数创建 goroutine 的写法如下:
go 函数名( 参数列表 )函数名:要调用的函数名。
参数列表:调用函数需要传入的参数。
使用 go 关键字创建 goroutine 时,被调用函数的返回值会被忽略。
如果需要在 goroutine 中返回数据,请使用后面介绍的通道(channel)特性,通过通道把数据从 goroutine 中作为返回值传出。
2) 例子
使用 go 关键字,将 running() 函数并发执行,每隔一秒打印一次计数器,而 main 的 goroutine 则等待用户输入,两个行为可以同时进行。请参考下面代码:
package main
import (
"fmt"
"time"
)
func running() {
var times int
// 构建一个无限循环
for {
times++
fmt.Println("tick", times)
// 延时1秒
time.Sleep(time.Second)
}
}
func main() {
// 并发执行程序
go running()
// 接受命令行输入, 不做任何事情
var input string
fmt.Scanln(&input)
}命令行输出如下:
tick 1
tick 2
tick 3
tick 4
tick 5代码执行后,命令行会不断地输出 tick,同时可以使用 fmt.Scanln() 接受用户输入。两个环节可以同时进行。
代码说明如下:
第 12 行,使用 for 形成一个无限循环。
第 13 行,times 变量在循环中不断自增。
第 14 行,输出 times 变量的值。
第 17 行,使用 time.Sleep 暂停 1 秒后继续循环。
第 25 行,使用 go 关键字让 running() 函数并发运行。
第 29 行,接受用户输入,直到按 Enter 键时将输入的内容写入 input 变量中并返回,整个程序终止。
这段代码的执行顺序如下图所示。
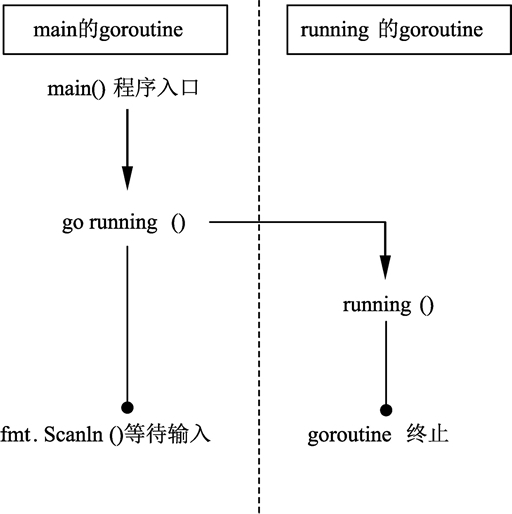
这个例子中,Go 程序在启动时,运行时(runtime)会默认为 main() 函数创建一个 goroutine。在 main() 函数的 goroutine 中执行到 go running 语句时,归属于 running() 函数的 goroutine 被创建,running() 函数开始在自己的 goroutine 中执行。此时,main() 继续执行,两个 goroutine 通过 Go 程序的调度机制同时运作。
使用匿名函数创建goroutine
go 关键字后也可以为匿名函数或闭包启动 goroutine。
1) 使用匿名函数创建goroutine的格式
使用匿名函数或闭包创建 goroutine 时,除了将函数定义部分写在 go 的后面之外,还需要加上匿名函数的调用参数,格式如下:
go func( 参数列表 ){
函数体
}( 调用参数列表 )其中:
参数列表:函数体内的参数变量列表。
函数体:匿名函数的代码。
调用参数列表:启动 goroutine 时,需要向匿名函数传递的调用参数。
2) 使用匿名函数创建goroutine的例子
在 main() 函数中创建一个匿名函数并为匿名函数启动 goroutine。匿名函数没有参数。代码将并行执行定时打印计数的效果。参见下面的代码:
package main
import (
"fmt"
"time"
)
func main() {
go func() {
var times int
for {
times++
fmt.Println("tick", times)
time.Sleep(time.Second)
}
}()
var input string
fmt.Scanln(&input)
}代码说明如下:
第 10 行,go 后面接匿名函数启动 goroutine。
第 12~19 行的逻辑与前面程序的 running() 函数一致。
第 21 行的括号的功能是调用匿名函数的参数列表。由于第 10 行的匿名函数没有参数,因此第 21 行的参数列表也是空的。
提示:所有 goroutine 在 main() 函数结束时会一同结束。
goroutine 虽然类似于线程概念,但是从调度性能上没有线程细致,而细致程度取决于 Go 程序的 goroutine 调度器的实现和运行环境。
终止 goroutine 的最好方法就是自然返回 goroutine 对应的函数。虽然可以用 golang.org/x/net/context 包进行 goroutine 生命期深度控制,但这种方法仍然处于内部试验阶段,并不是官方推荐的特性。
截止 Go 1.9 版本,暂时没有标准接口获取 goroutine 的 ID。
Go语言并发通信
通过上一节《Go语言goroutine》的学习,关键字 go 的引入使得在Go语言中并发编程变得简单而优雅,但我们同时也应该意识到并发编程的原生复杂性,并时刻对并发中容易出现的问题保持警惕。
事实上,不管是什么平台,什么编程语言,不管在哪,并发都是一个大话题。并发编程的难度在于协调,而协调就要通过交流,从这个角度看来,并发单元间的通信是最大的问题。
在工程上,有两种最常见的并发通信模型:共享数据和消息。
共享数据是指多个并发单元分别保持对同一个数据的引用,实现对该数据的共享。被共享的数据可能有多种形式,比如内存数据块、磁盘文件、网络数据等。在实际工程应用中最常见的无疑是内存了,也就是常说的共享内存。
先看看我们在C语言中通常是怎么处理线程间数据共享的,代码如下所示。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void *count();
pthread_mutex_t mutex1 = PTHREAD_MUTEX_INITIALIZER;
int counter = 0;
main()
{
int rc1, rc2;
pthread_t thread1, thread2;
/* 创建线程,每个线程独立执行函数functionC */
if((rc1 = pthread_create(&thread1, NULL, &add, NULL)))
{
printf("Thread creation failed: %d\n", rc1);
}
if((rc2 = pthread_create(&thread2, NULL, &add, NULL)))
{
printf("Thread creation failed: %d\n", rc2);
}
/* 等待所有线程执行完毕 */
pthread_join( thread1, NULL);
pthread_join( thread2, NULL);
exit(0);
}
void *count()
{
pthread_mutex_lock( &mutex1 );
counter++;
printf("Counter value: %d\n",counter);
pthread_mutex_unlock( &mutex1 );
}现在我们尝试将这段C语言代码直接翻译为Go语言代码,代码如下所示。
package main
import (
"fmt"
"runtime"
"sync"
)
var counter int = 0
func Count(lock *sync.Mutex) {
lock.Lock()
counter++
fmt.Println(counter)
lock.Unlock()
}
func main() {
lock := &sync.Mutex{}
for i := 0; i < 10; i++ {
go Count(lock)
}
for {
lock.Lock()
c := counter
lock.Unlock()
runtime.Gosched()
if c >= 10 {
break
}
}
}在上面的例子中,我们在 10 个 goroutine 中共享了变量 counter。每个 goroutine 执行完成后,会将 counter 的值加 1。因为 10 个 goroutine 是并发执行的,所以我们还引入了锁,也就是代码中的 lock 变量。每次对 n 的操作,都要先将锁锁住,操作完成后,再将锁打开。
在 main 函数中,使用 for 循环来不断检查 counter 的值(同样需要加锁)。当其值达到 10 时,说明所有 goroutine 都执行完毕了,这时主函数返回,程序退出。
事情好像开始变得糟糕了。实现一个如此简单的功能,却写出如此臃肿而且难以理解的代码。想象一下,在一个大的系统中具有无数的锁、无数的共享变量、无数的业务逻辑与错误处理分支,那将是一场噩梦。这噩梦就是众多 C/C++ 开发者正在经历的,其实 Java 和 C# 开发者也好不到哪里去。
Go语言既然以并发编程作为语言的最核心优势,当然不至于将这样的问题用这么无奈的方式来解决。Go语言提供的是另一种通信模型,即以消息机制而非共享内存作为通信方式。
消息机制认为每个并发单元是自包含的、独立的个体,并且都有自己的变量,但在不同并发单元间这些变量不共享。每个并发单元的输入和输出只有一种,那就是消息。这有点类似于进程的概念,每个进程不会被其他进程打扰,它只做好自己的工作就可以了。不同进程间靠消息来通信,它们不会共享内存。
Go语言提供的消息通信机制被称为 channel,关于 channel 的介绍将在后续的学习中为大家讲解。
Go语言竞争状态简述
有并发,就有资源竞争,如果两个或者多个 goroutine 在没有相互同步的情况下,访问某个共享的资源,比如同时对该资源进行读写时,就会处于相互竞争的状态,这就是并发中的资源竞争。
并发本身并不复杂,但是因为有了资源竞争的问题,就使得我们开发出好的并发程序变得复杂起来,因为会引起很多莫名其妙的问题。
下面的代码中就会出现竞争状态:
package main
import (
"fmt"
"runtime"
"sync"
)
var (
count int32
wg sync.WaitGroup
)
func main() {
wg.Add(2)
go incCount()
go incCount()
wg.Wait()
fmt.Println(count)
}
func incCount() {
defer wg.Done()
for i := 0; i < 2; i++ {
value := count
runtime.Gosched()
value++
count = value
}
}这是一个资源竞争的例子,大家可以将程序多运行几次,会发现结果可能是 2,也可以是 3,还可能是 4。这是因为 count 变量没有任何同步保护,所以两个 goroutine 都会对其进行读写,会导致对已经计算好的结果被覆盖,以至于产生错误结果。
代码中的 runtime.Gosched() 是让当前 goroutine 暂停的意思,退回执行队列,让其他等待的 goroutine 运行,目的是为了使资源竞争的结果更明显。
下面我们来分析一下程序的运行过程,将两个 goroutine 分别假设为 g1 和 g2:
- g1 读取到 count 的值为 0;
- 然后 g1 暂停了,切换到 g2 运行,g2 读取到 count 的值也为 0;
- g2 暂停,切换到 g1,g1 对 count+1,count 的值变为 1;
- g1 暂停,切换到 g2,g2 刚刚已经获取到值 0,对其 +1,最后赋值给 count,其结果还是 1;
- 可以看出 g1 对 count+1 的结果被 g2 给覆盖了,两个 goroutine 都 +1 而结果还是 1。
通过上面的分析可以看出,之所以出现上面的问题,是因为两个 goroutine 相互覆盖结果。
所以我们对于同一个资源的读写必须是原子化的,也就是说,同一时间只能允许有一个 goroutine 对共享资源进行读写操作。
共享资源竞争的问题,非常复杂,并且难以察觉,好在 Go 为我们提供了一个工具帮助我们检查,这个就是go build -race 命令。在项目目录下执行这个命令,生成一个可以执行文件,然后再运行这个可执行文件,就可以看到打印出的检测信息。
在go build命令中多加了一个-race 标志,这样生成的可执行程序就自带了检测资源竞争的功能,运行生成的可执行文件,效果如下所示:
==================
WARNING: DATA RACE
Read at 0x000000619cbc by goroutine 8:
main.incCount()
D:/code/src/main.go:25 +0x80
Previous write at 0x000000619cbc by goroutine 7:
main.incCount()
D:/code/src/main.go:28 +0x9f
Goroutine 8 (running) created at:
main.main()
D:/code/src/main.go:17 +0x7e
Goroutine 7 (finished) created at:
main.main()
D:/code/src/main.go:16 +0x66
==================
4
Found 1 data race(s)通过运行结果可以看出 goroutine 8 在代码 25 行读取共享资源value := count,而这时 goroutine 7 在代码 28 行修改共享资源count = value,而这两个 goroutine 都是从 main 函数的 16、17 行通过 go 关键字启动的。
锁住共享资源
Go语言提供了传统的同步 goroutine 的机制,就是对共享资源加锁。atomic 和 sync 包里的一些函数就可以对共享的资源进行加锁操作。
原子函数
原子函数能够以很底层的加锁机制来同步访问整型变量和指针,示例代码如下所示:
package main
import (
"fmt"
"runtime"
"sync"
"sync/atomic"
)
var (
counter int64
wg sync.WaitGroup
)
func main() {
wg.Add(2)
go incCounter(1)
go incCounter(2)
wg.Wait() //等待goroutine结束
fmt.Println(counter)
}
func incCounter(id int) {
defer wg.Done()
for count := 0; count < 2; count++ {
atomic.AddInt64(&counter, 1) //安全的对counter加1
runtime.Gosched()
}
}上述代码中使用了 atmoic 包的 AddInt64 函数,这个函数会同步整型值的加法,方法是强制同一时刻只能有一个 gorountie 运行并完成这个加法操作。当 goroutine 试图去调用任何原子函数时,这些 goroutine 都会自动根据所引用的变量做同步处理。
另外两个有用的原子函数是 LoadInt64 和 StoreInt64。这两个函数提供了一种安全地读和写一个整型值的方式。下面是代码就使用了 LoadInt64 和 StoreInt64 函数来创建一个同步标志,这个标志可以向程序里多个 goroutine 通知某个特殊状态。
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
var (
shutdown int64
wg sync.WaitGroup
)
func main() {
wg.Add(2)
go doWork("A")
go doWork("B")
time.Sleep(1 * time.Second)
fmt.Println("Shutdown Now")
atomic.StoreInt64(&shutdown, 1)
wg.Wait()
}
func doWork(name string) {
defer wg.Done()
for {
fmt.Printf("Doing %s Work\n", name)
time.Sleep(250 * time.Millisecond)
if atomic.LoadInt64(&shutdown) == 1 {
fmt.Printf("Shutting %s Down\n", name)
break
}
}
}上面代码中 main 函数使用 StoreInt64 函数来安全地修改 shutdown 变量的值。如果哪个 doWork goroutine 试图在 main 函数调用 StoreInt64 的同时调用 LoadInt64 函数,那么原子函数会将这些调用互相同步,保证这些操作都是安全的,不会进入竞争状态。
互斥锁
另一种同步访问共享资源的方式是使用互斥锁,互斥锁这个名字来自互斥的概念。互斥锁用于在代码上创建一个临界区,保证同一时间只有一个 goroutine 可以执行这个临界代码。
示例代码如下所示:
package main
import (
"fmt"
"runtime"
"sync"
)
var (
counter int64
wg sync.WaitGroup
mutex sync.Mutex
)
func main() {
wg.Add(2)
go incCounter(1)
go incCounter(2)
wg.Wait()
fmt.Println(counter)
}
func incCounter(id int) {
defer wg.Done()
for count := 0; count < 2; count++ {
//同一时刻只允许一个goroutine进入这个临界区
mutex.Lock()
{
value := counter
runtime.Gosched()
value++
counter = value
}
mutex.Unlock() //释放锁,允许其他正在等待的goroutine进入临界区
}
}同一时刻只有一个 goroutine 可以进入临界区。之后直到调用 Unlock 函数之后,其他 goroutine 才能进去临界区。当调用 runtime.Gosched 函数强制将当前 goroutine 退出当前线程后,调度器会再次分配这个 goroutine 继续运行。
Go语言GOMAXPROCS(调整并发的运行性能)
在 Go语言程序运行时(runtime)实现了一个小型的任务调度器。这套调度器的工作原理类似于操作系统调度线程,Go 程序调度器可以高效地将 CPU 资源分配给每一个任务。传统逻辑中,开发者需要维护线程池中线程与 CPU 核心数量的对应关系。同样的,Go 地中也可以通过 runtime.GOMAXPROCS() 函数做到,格式为:
runtime.GOMAXPROCS(逻辑CPU数量)这里的逻辑CPU数量可以有如下几种数值:
<1:不修改任何数值。
=1:单核心执行。
1:多核并发执行。
一般情况下,可以使用 runtime.NumCPU() 查询 CPU 数量,并使用 runtime.GOMAXPROCS() 函数进行设置,例如:
runtime.GOMAXPROCS(runtime.NumCPU())Go 1.5 版本之前,默认使用的是单核心执行。从 Go 1.5 版本开始,默认执行上面语句以便让代码并发执行,最大效率地利用 CPU。
GOMAXPROCS 同时也是一个环境变量,在应用程序启动前设置环境变量也可以起到相同的作用。
并发和并行的区别
在讲解并发概念时,总会涉及另外一个概念并行。下面让我们来了解并发和并行之间的区别。
并发(concurrency):把任务在不同的时间点交给处理器进行处理。在同一时间点,任务并不会同时运行。
并行(parallelism):把每一个任务分配给每一个处理器独立完成。在同一时间点,任务一定是同时运行。
并发不是并行。并行是让不同的代码片段同时在不同的物理处理器上执行。并行的关键是同时做很多事情,而并发是指同时管理很多事情,这些事情可能只做了一半就被暂停去做别的事情了。
在很多情况下,并发的效果比并行好,因为操作系统和硬件的总资源一般很少,但能支持系统同时做很多事情。这种“使用较少的资源做更多的事情”的哲学,也是指导 Go语言设计的哲学。
如果希望让 goroutine 并行,必须使用多于一个逻辑处理器。当有多个逻辑处理器时,调度器会将 goroutine 平等分配到每个逻辑处理器上。这会让 goroutine 在不同的线程上运行。不过要想真的实现并行的效果,用户需要让自己的程序运行在有多个物理处理器的机器上。否则,哪怕 Go语言运行时使用多个线程,goroutine 依然会在同一个物理处理器上并发运行,达不到并行的效果。
下图展示了在一个逻辑处理器上并发运行 goroutine 和在两个逻辑处理器上并行运行两个并发的 goroutine 之间的区别。调度器包含一些聪明的算法,这些算法会随着 Go语言的发布被更新和改进,所以不推荐盲目修改语言运行时对逻辑处理器的默认设置。如果真的认为修改逻辑处理器的数量可以改进性能,也可以对语言运行时的参数进行细微调整。
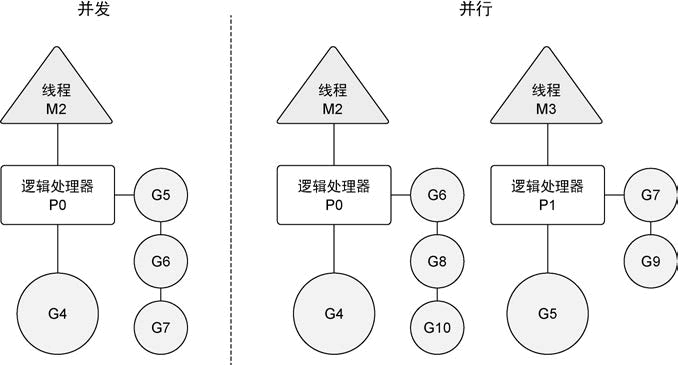
Go语言在 GOMAXPROCS 数量与任务数量相等时,可以做到并行执行,但一般情况下都是并发执行。
goroutine和coroutine的区别
C#、Lua、Python 语言都支持 coroutine 特性。coroutine 与 goroutine 在名字上类似,都可以将函数或者语句在独立的环境中运行,但是它们之间有两点不同:
- goroutine 可能发生并行执行;
- 但 coroutine 始终顺序执行。
goroutines 意味着并行(或者可以以并行的方式部署),coroutines 一般来说不是这样的,goroutines 通过通道来通信;coroutines 通过让出和恢复操作来通信,goroutines 比 coroutines 更强大,也很容易从 coroutines 的逻辑复用到 goroutines。
狭义地说,goroutine 可能发生在多线程环境下,goroutine 无法控制自己获取高优先度支持;coroutine 始终发生在单线程,coroutine 程序需要主动交出控制权,宿主才能获得控制权并将控制权交给其他 coroutine。
goroutine 间使用 channel 通信,coroutine 使用 yield 和 resume 操作。
goroutine 和 coroutine 的概念和运行机制都是脱胎于早期的操作系统。
coroutine 的运行机制属于协作式任务处理,早期的操作系统要求每一个应用必须遵守操作系统的任务处理规则,应用程序在不需要使用 CPU 时,会主动交出 CPU 使用权。如果开发者无意间或者故意让应用程序长时间占用 CPU,操作系统也无能为力,表现出来的效果就是计算机很容易失去响应或者死机。
goroutine 属于抢占式任务处理,已经和现有的多线程和多进程任务处理非常类似。应用程序对 CPU 的控制最终还需要由操作系统来管理,操作系统如果发现一个应用程序长时间大量地占用 CPU,那么用户有权终止这个任务。
Go语言通道(chan)——goroutine之间通信的管道
如果说 goroutine 是 Go语言程序的并发体的话,那么 channels 就是它们之间的通信机制。一个 channels 是一个通信机制,它可以让一个 goroutine 通过它给另一个 goroutine 发送值信息。每个 channel 都有一个特殊的类型,也就是 channels 可发送数据的类型。一个可以发送 int 类型数据的 channel 一般写为 chan int。
Go语言提倡使用通信的方法代替共享内存,当一个资源需要在 goroutine 之间共享时,通道在 goroutine 之间架起了一个管道,并提供了确保同步交换数据的机制。声明通道时,需要指定将要被共享的数据的类型。可以通过通道共享内置类型、命名类型、结构类型和引用类型的值或者指针。
这里通信的方法就是使用通道(channel),如下图所示。
在地铁站、食堂、洗手间等公共场所人很多的情况下,大家养成了排队的习惯,目的也是避免拥挤、插队导致的低效的资源使用和交换过程。代码与数据也是如此,多个 goroutine 为了争抢数据,势必造成执行的低效率,使用队列的方式是最高效的,channel 就是一种队列一样的结构。
通道的特性
Go语言中的通道(channel)是一种特殊的类型。在任何时候,同时只能有一个 goroutine 访问通道进行发送和获取数据。goroutine 间通过通道就可以通信。
通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。
声明通道类型
通道本身需要一个类型进行修饰,就像切片类型需要标识元素类型。通道的元素类型就是在其内部传输的数据类型,声明如下:
var 通道变量 chan 通道类型通道类型:通道内的数据类型。
通道变量:保存通道的变量。
chan 类型的空值是 nil,声明后需要配合 make 后才能使用。
创建通道
通道是引用类型,需要使用 make 进行创建,格式如下:
通道实例 := make(chan 数据类型)数据类型:通道内传输的元素类型。
通道实例:通过make创建的通道句柄。
请看下面的例子:
ch1 := make(chan int) // 创建一个整型类型的通道
ch2 := make(chan interface{}) // 创建一个空接口类型的通道, 可以存放任意格式
type Equip struct{ /* 一些字段 */ }
ch2 := make(chan *Equip) // 创建Equip指针类型的通道, 可以存放*Equip使用通道发送数据
通道创建后,就可以使用通道进行发送和接收操作。
1) 通道发送数据的格式
通道的发送使用特殊的操作符<-,将数据通过通道发送的格式为:
通道变量 <- 值通道变量:通过make创建好的通道实例。
值:可以是变量、常量、表达式或者函数返回值等。值的类型必须与ch通道的元素类型一致。
2) 通过通道发送数据的例子
使用 make 创建一个通道后,就可以使用<-向通道发送数据,代码如下:
// 创建一个空接口通道
ch := make(chan interface{})
// 将0放入通道中
ch <- 0
// 将hello字符串放入通道中
ch <- "hello"3) 发送将持续阻塞直到数据被接收
把数据往通道中发送时,如果接收方一直都没有接收,那么发送操作将持续阻塞。Go 程序运行时能智能地发现一些永远无法发送成功的语句并做出提示,代码如下:
package main
func main() {
// 创建一个整型通道
ch := make(chan int)
// 尝试将0通过通道发送
ch <- 0
}运行代码,报错:
fatal error: all goroutines are asleep - deadlock!报错的意思是:运行时发现所有的 goroutine(包括main)都处于等待 goroutine。也就是说所有 goroutine 中的 channel 并没有形成发送和接收对应的代码。
使用通道接收数据
通道接收同样使用<-操作符,通道接收有如下特性:
① 通道的收发操作在不同的两个 goroutine 间进行。
由于通道的数据在没有接收方处理时,数据发送方会持续阻塞,因此通道的接收必定在另外一个 goroutine 中进行。
② 接收将持续阻塞直到发送方发送数据。
如果接收方接收时,通道中没有发送方发送数据,接收方也会发生阻塞,直到发送方发送数据为止。
③ 每次接收一个元素。
通道一次只能接收一个数据元素。
通道的数据接收一共有以下 4 种写法。
1) 阻塞接收数据
阻塞模式接收数据时,将接收变量作为<-操作符的左值,格式如下:
data := <-ch执行该语句时将会阻塞,直到接收到数据并赋值给 data 变量。
2) 非阻塞接收数据
使用非阻塞方式从通道接收数据时,语句不会发生阻塞,格式如下:
data, ok := <-chdata:表示接收到的数据。未接收到数据时,data 为通道类型的零值。
ok:表示是否接收到数据。
非阻塞的通道接收方法可能造成高的 CPU 占用,因此使用非常少。如果需要实现接收超时检测,可以配合 select 和计时器 channel 进行,可以参见后面的内容。
3) 接收任意数据,忽略接收的数据
阻塞接收数据后,忽略从通道返回的数据,格式如下:
<-ch执行该语句时将会发生阻塞,直到接收到数据,但接收到的数据会被忽略。这个方式实际上只是通过通道在 goroutine 间阻塞收发实现并发同步。
使用通道做并发同步的写法,可以参考下面的例子:
package main
import (
"fmt"
)
func main() {
// 构建一个通道
ch := make(chan int)
// 开启一个并发匿名函数
go func() {
fmt.Println("start goroutine")
// 通过通道通知main的goroutine
ch <- 0
fmt.Println("exit goroutine")
}()
fmt.Println("wait goroutine")
// 等待匿名goroutine
<-ch
fmt.Println("all done")
}执行代码,输出如下:
wait goroutine
start goroutine
exit goroutine
all done代码说明如下:
第 10 行,构建一个同步用的通道。
第 13 行,开启一个匿名函数的并发。
第 18 行,匿名 goroutine 即将结束时,通过通道通知 main 的 goroutine,这一句会一直阻塞直到 main 的 goroutine 接收为止。
第 27 行,开启 goroutine 后,马上通过通道等待匿名 goroutine 结束。
4) 循环接收
通道的数据接收可以借用 for range 语句进行多个元素的接收操作,格式如下:
for data := range ch {
}通道 ch 是可以进行遍历的,遍历的结果就是接收到的数据。数据类型就是通道的数据类型。通过 for 遍历获得的变量只有一个,即上面例子中的 data。
遍历通道数据的例子请参考下面的代码。
使用 for 从通道中接收数据:
package main
import (
"fmt"
"time"
)
func main() {
// 构建一个通道
ch := make(chan int)
// 开启一个并发匿名函数
go func() {
// 从3循环到0
for i := 3; i >= 0; i-- {
// 发送3到0之间的数值
ch <- i
// 每次发送完时等待
time.Sleep(time.Second)
}
}()
// 遍历接收通道数据
for data := range ch {
// 打印通道数据
fmt.Println(data)
// 当遇到数据0时, 退出接收循环
if data == 0 {
break
}
}
}执行代码,输出如下:
3
2
1
0代码说明如下:
第 12 行,通过 make 生成一个整型元素的通道。
第 15 行,将匿名函数并发执行。
第 18 行,用循环生成 3 到 0 之间的数值。
第 21 行,将 3 到 0 之间的数值依次发送到通道 ch 中。
第 24 行,每次发送后暂停 1 秒。
第 30 行,使用 for 从通道中接收数据。
第 33 行,将接收到的数据打印出来。
第 36 行,当接收到数值 0 时,停止接收。如果继续发送,由于接收 goroutine 已经退出,没有 goroutine 发送到通道,因此运行时将会触发宕机报错。
示例:并发打印
前面的例子创建的都是无缓冲通道。使用无缓冲通道往里面装入数据时,装入方将被阻塞,直到另外通道在另外一个 goroutine 中被取出。同样,如果通道中没有放入任何数据,接收方试图从通道中获取数据时,同样也是阻塞。发送和接收的操作是同步完成的。
下面通过一个并发打印的例子,将 goroutine 和 channel 放在一起展示它们的用法。
package main
import (
"fmt"
)
func printer(c chan int) {
// 开始无限循环等待数据
for {
// 从channel中获取一个数据
data := <-c
// 将0视为数据结束
if data == 0 {
break
}
// 打印数据
fmt.Println(data)
}
// 通知main已经结束循环(我搞定了!)
c <- 0
}
func main() {
// 创建一个channel
c := make(chan int)
// 并发执行printer, 传入channel
go printer(c)
for i := 1; i <= 10; i++ {
// 将数据通过channel投送给printer
c <- i
}
// 通知并发的printer结束循环(没数据啦!)
c <- 0
// 等待printer结束(搞定喊我!)
<-c
}运行代码,输出如下:
1
2
3
4
5
6
7
8
9
10代码说明如下:
第 10 行,创建一个无限循环,只有当第 16 行获取到的数据为 0 时才会退出循环。
第 13 行,从函数参数传入的通道中获取一个整型数值。
第 21 行,打印整型数值。
第 25 行,在退出循环时,通过通道通知 main() 函数已经完成工作。
第 32 行,创建一个整型通道进行跨 goroutine 的通信。
第 35 行,创建一个 goroutine,并发执行 printer() 函数。
第 37 行,构建一个数值循环,将 1~10 的数通过通道传送给 printer 构造出的 goroutine。
第 44 行,给通道传入一个 0,表示将前面的数据处理完成后,退出循环。
第 47 行,在数据发送过去后,因为并发和调度的原因,任务会并发执行。这里需要等待 printer 的第 25 行返回数据后,才可以退出 main()。
本例的设计模式就是典型的生产者和消费者。生产者是第 37 行的循环,而消费者是 printer() 函数。整个例子使用了两个 goroutine,一个是 main(),一个是通过第 35 行 printer() 函数创建的 goroutine。两个 goroutine 通过第 32 行创建的通道进行通信。这个通道有下面两重功能。
数据传送:第 40 行中发送数据和第 13 行接收数据。
控制指令:类似于信号量的功能。同步 goroutine 的操作。功能简单描述为:
第 44 行:“没数据啦!”
第 25 行:“我搞定了!”
第 47 行:“搞定喊我!”
Go语言单向通道——通道中的单行道
Go语言的类型系统提供了单方向的 channel 类型,顾名思义,单向 channel 只能用于发送或者接收数据。channel 本身必然是同时支持读写的,否则根本没法用。
假如一个 channel 真的只能读,那么肯定只会是空的,因为你没机会往里面写数据。同理,如果一个 channel 只允许写,即使写进去了,也没有丝毫意义,因为没有机会读取里面的数据。所谓的单向 channel 概念,其实只是对 channel 的一种使用限制。
单向通道的声明格式
我们在将一个 channel 变量传递到一个函数时,可以通过将其指定为单向 channel 变量,从而限制该函数中可以对此 channel 的操作,比如只能往这个 channel 写,或者只能从这个 channel 读。
单向 channel 变量的声明非常简单,只能发送的通道类型为chan<-,只能接收的通道类型为<-chan,格式如下:
var 通道实例 chan<- 元素类型 // 只能发送通道
var 通道实例 <-chan 元素类型 // 只能接收通道元素类型:通道包含的元素类型。
通道实例:声明的通道变量。
单向通道的使用例子
示例代码如下:
ch := make(chan int)
// 声明一个只能发送的通道类型, 并赋值为ch
var chSendOnly chan<- int = ch
//声明一个只能接收的通道类型, 并赋值为ch
var chRecvOnly <-chan int = ch上面的例子中,chSendOnly 只能发送数据,如果尝试接收数据,将会出现如下报错:
invalid operation: <-chSendOnly (receive from send-only type chan<- int)同理,chRecvOnly 也是不能发送的。
当然,使用 make 创建通道时,也可以创建一个只发送或只读取的通道:
ch := make(<-chan int)
var chReadOnly <-chan int = ch
<-chReadOnly上面代码编译正常,运行也是正确的。但是,一个不能填充数据(发送)只能读取的通道是毫无意义的。
time包中的单向通道
time 包中的计时器会返回一个 timer 实例,代码如下:
timer := time.NewTimer(time.Second)timer的Timer类型定义如下:
type Timer struct {
C <-chan Time
r runtimeTimer
}第 2 行中 C 通道的类型就是一种只能接收的单向通道。如果此处不进行通道方向约束,一旦外部向通道发送数据,将会造成其他使用到计时器的地方逻辑产生混乱。
因此,单向通道有利于代码接口的严谨性。
关闭 channel
关闭 channel 非常简单,直接使用 Go语言内置的 close() 函数即可:
close(ch)在介绍了如何关闭 channel 之后,我们就多了一个问题:如何判断一个 channel 是否已经被关闭?我们可以在读取的时候使用多重返回值的方式:
x, ok := <-ch这个用法与 map 中的按键获取 value 的过程比较类似,只需要看第二个 bool 返回值即可,如果返回值是 false 则表示 ch 已经被关闭。
Go语言无缓冲的通道
Go语言中无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何值的通道。这种类型的通道要求发送 goroutine 和接收 goroutine 同时准备好,才能完成发送和接收操作。
如果两个 goroutine 没有同时准备好,通道会导致先执行发送或接收操作的 goroutine 阻塞等待。这种对通道进行发送和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个操作单独存在。
阻塞指的是由于某种原因数据没有到达,当前协程(线程)持续处于等待状态,直到条件满足才解除阻塞。
同步指的是在两个或多个协程(线程)之间,保持数据内容一致性的机制。
下图展示两个 goroutine 如何利用无缓冲的通道来共享一个值。
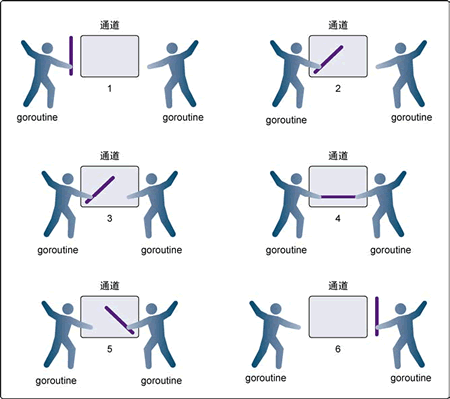
图:使用无缓冲的通道在 goroutine 之间同步
在第 1 步,两个 goroutine 都到达通道,但哪个都没有开始执行发送或者接收。在第 2 步,左侧的 goroutine 将它的手伸进了通道,这模拟了向通道发送数据的行为。这时,这个 goroutine 会在通道中被锁住,直到交换完成。
在第 3 步,右侧的 goroutine 将它的手放入通道,这模拟了从通道里接收数据。这个 goroutine 一样也会在通道中被锁住,直到交换完成。在第 4 步和第 5 步,进行交换,并最终在第 6 步,两个 goroutine 都将它们的手从通道里拿出来,这模拟了被锁住的 goroutine 得到释放。两个 goroutine 现在都可以去做别的事情了。
为了讲得更清楚,让我们来看两个完整的例子。这两个例子都会使用无缓冲的通道在两个 goroutine 之间同步交换数据。
【示例 1】在网球比赛中,两位选手会把球在两个人之间来回传递。选手总是处在以下两种状态之一,要么在等待接球,要么将球打向对方。可以使用两个 goroutine 来模拟网球比赛,并使用无缓冲的通道来模拟球的来回,代码如下所示。
// 这个示例程序展示如何用无缓冲的通道来模拟
// 2 个goroutine 间的网球比赛
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
// wg 用来等待程序结束
var wg sync.WaitGroup
func init() {
rand.Seed(time.Now().UnixNano())
}
// main 是所有Go 程序的入口
func main() {
// 创建一个无缓冲的通道
court := make(chan int)
// 计数加 2,表示要等待两个goroutine
wg.Add(2)
// 启动两个选手
go player("Nadal", court)
go player("Djokovic", court)
// 发球
court <- 1
// 等待游戏结束
wg.Wait()
}
// player 模拟一个选手在打网球
func player(name string, court chan int) {
// 在函数退出时调用Done 来通知main 函数工作已经完成
defer wg.Done()
for {
// 等待球被击打过来
ball, ok := <-court
if !ok {
// 如果通道被关闭,我们就赢了
fmt.Printf("Player %s Won\n", name)
return
}
// 选随机数,然后用这个数来判断我们是否丢球
n := rand.Intn(100)
if n%13 == 0 {
fmt.Printf("Player %s Missed\n", name)
// 关闭通道,表示我们输了
close(court)
return
}
// 显示击球数,并将击球数加1
fmt.Printf("Player %s Hit %d\n", name, ball)
ball++
// 将球打向对手
court <- ball
}
}运行这个程序,输出结果如下所示。
Player Nadal Hit 1
Player Djokovic Hit 2
Player Nadal Hit 3
Player Djokovic Missed
Player Nadal Won代码说明如下:
第 22 行,创建了一个 int 类型的无缓冲的通道,让两个 goroutine 在击球时能够互相同步。
第 28 行和第 29 行,创建了参与比赛的两个 goroutine。在这个时候,两个 goroutine 都阻塞住等待击球。
第 32 行,将球发到通道里,程序开始执行这个比赛,直到某个 goroutine 输掉比赛。
第 43 行可以找到一个无限循环的 for 语句。在这个循环里,是玩游戏的过程。
第 45 行,goroutine 从通道接收数据,用来表示等待接球。这个接收动作会锁住 goroutine,直到有数据发送到通道里。通道的接收动作返回时。
第 46 行会检测 ok 标志是否为 false。如果这个值是 false,表示通道已经被关闭,游戏结束。
第 53 行到第 60 行,会产生一个随机数,用来决定 goroutine 是否击中了球。
第 58 行如果某个 goroutine 没有打中球,关闭通道。之后两个 goroutine 都会返回,通过 defer 声明的 Done 会被执行,程序终止。
第 64 行,如果击中了球 ball 的值会递增 1,并在第 67 行,将 ball 作为球重新放入通道,发送给另一位选手。在这个时刻,两个 goroutine 都会被锁住,直到交换完成。
【示例 2】用不同的模式,使用无缓冲的通道,在 goroutine 之间同步数据,来模拟接力比赛。在接力比赛里,4 个跑步者围绕赛道轮流跑。第二个、第三个和第四个跑步者要接到前一位跑步者的接力棒后才能起跑。比赛中最重要的部分是要传递接力棒,要求同步传递。在同步接力棒的时候,参与接力的两个跑步者必须在同一时刻准备好交接。代码如下所示。
// 这个示例程序展示如何用无缓冲的通道来模拟
// 4 个goroutine 间的接力比赛
package main
import (
"fmt"
"sync"
"time"
)
// wg 用来等待程序结束
var wg sync.WaitGroup
// main 是所有Go 程序的入口
func main() {
// 创建一个无缓冲的通道
baton := make(chan int)
// 为最后一位跑步者将计数加1
wg.Add(1)
// 第一位跑步者持有接力棒
go Runner(baton)
// 开始比赛
baton <- 1
// 等待比赛结束
wg.Wait()
}
// Runner 模拟接力比赛中的一位跑步者
func Runner(baton chan int) {
var newRunner int
// 等待接力棒
runner := <-baton
// 开始绕着跑道跑步
fmt.Printf("Runner %d Running With Baton\n", runner)
// 创建下一位跑步者
if runner != 4 {
newRunner = runner + 1
fmt.Printf("Runner %d To The Line\n", newRunner)
go Runner(baton)
}
// 围绕跑道跑
time.Sleep(100 * time.Millisecond)
// 比赛结束了吗?
if runner == 4 {
fmt.Printf("Runner %d Finished, Race Over\n", runner)
wg.Done()
return
}
// 将接力棒交给下一位跑步者
fmt.Printf("Runner %d Exchange With Runner %d\n",
runner,
newRunner)
baton <- newRunner
}运行这个程序,输出结果如下所示。
Runner 1 Running With Baton
Runner 1 To The Line
Runner 1 Exchange With Runner 2
Runner 2 Running With Baton
Runner 2 To The Line
Runner 2 Exchange With Runner 3
Runner 3 Running With Baton
Runner 3 To The Line
Runner 3 Exchange With Runner 4
Runner 4 Running With Baton
Runner 4 Finished, Race Over代码说明如下:
第 17 行,创建了一个无缓冲的 int 类型的通道 baton,用来同步传递接力棒。
第 20 行,我们给 WaitGroup 加 1,这样 main 函数就会等最后一位跑步者跑步结束。
第 23 行创建了一个 goroutine,用来表示第一位跑步者来到跑道。
第 26 行,将接力棒交给这个跑步者,比赛开始。
第 29 行,main 函数阻塞在 WaitGroup,等候最后一位跑步者完成比赛。
第 37 行,goroutine 对 baton 通道执行接收操作,表示等候接力棒。
第 46 行,一旦接力棒传了进来,就会创建一位新跑步者,准备接力下一棒,直到 goroutine 是第四个跑步者。
第 50 行,跑步者围绕跑道跑 100 ms。
第 55 行,如果第四个跑步者完成了比赛,就调用 Done,将 WaitGroup 减 1,之后 goroutine 返回。
第 64 行,如果这个 goroutine 不是第四个跑步者,接力棒会交到下一个已经在等待的跑步者手上。在这个时候,goroutine 会被锁住,直到交接完成。
在这两个例子里,我们使用无缓冲的通道同步 goroutine,模拟了网球和接力赛。代码的流程与这两个活动在真实世界中的流程完全一样,这样的代码很容易读懂。
现在知道了无缓冲的通道是如何工作的,下一节我们将为大家介绍带缓冲的通道。
Go语言带缓冲的通道
Go语言中有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个值的通道。这种类型的通道并不强制要求 goroutine 之间必须同时完成发送和接收。通道会阻塞发送和接收动作的条件也会不同。只有在通道中没有要接收的值时,接收动作才会阻塞。只有在通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞。
这导致有缓冲的通道和无缓冲的通道之间的一个很大的不同:无缓冲的通道保证进行发送和接收的 goroutine 会在同一时间进行数据交换;有缓冲的通道没有这种保证。
在无缓冲通道的基础上,为通道增加一个有限大小的存储空间形成带缓冲通道。带缓冲通道在发送时无需等待接收方接收即可完成发送过程,并且不会发生阻塞,只有当存储空间满时才会发生阻塞。同理,如果缓冲通道中有数据,接收时将不会发生阻塞,直到通道中没有数据可读时,通道将会再度阻塞。
无缓冲通道保证收发过程同步。无缓冲收发过程类似于快递员给你电话让你下楼取快递,整个递交快递的过程是同步发生的,你和快递员不见不散。但这样做快递员就必须等待所有人下楼完成操作后才能完成所有投递工作。如果快递员将快递放入快递柜中,并通知用户来取,快递员和用户就成了异步收发过程,效率可以有明显的提升。带缓冲的通道就是这样的一个“快递柜”。
创建带缓冲通道
如何创建带缓冲的通道呢?参见如下代码:
通道实例 := make(chan 通道类型, 缓冲大小)通道类型:和无缓冲通道用法一致,影响通道发送和接收的数据类型。
缓冲大小:决定通道最多可以保存的元素数量。
通道实例:被创建出的通道实例。
下面通过一个例子中来理解带缓冲通道的用法,参见下面的代码:
package main
import "fmt"
func main() {
// 创建一个3个元素缓冲大小的整型通道
ch := make(chan int, 3)
// 查看当前通道的大小
fmt.Println(len(ch))
// 发送3个整型元素到通道
ch <- 1
ch <- 2
ch <- 3
// 查看当前通道的大小
fmt.Println(len(ch))
}代码输出如下:
0
3代码说明如下:
第 8 行,创建一个带有 3 个元素缓冲大小的整型类型的通道。
第 11 行,查看当前通道的大小。带缓冲的通道在创建完成时,内部的元素是空的,因此使用 len() 获取到的返回值为 0。
第 14~16 行,发送 3 个整型元素到通道。因为使用了缓冲通道。即便没有 goroutine 接收,发送者也不会发生阻塞。
第 19 行,由于填充了 3 个通道,此时的通道长度变为 3。
阻塞条件
带缓冲通道在很多特性上和无缓冲通道是类似的。无缓冲通道可以看作是长度永远为 0 的带缓冲通道。因此根据这个特性,带缓冲通道在下面列举的情况下依然会发生阻塞:
带缓冲通道被填满时,尝试再次发送数据时发生阻塞。
带缓冲通道为空时,尝试接收数据时发生阻塞。
为什么Go语言对通道要限制长度而不提供无限长度的通道?
我们知道通道(channel)是在两个 goroutine 间通信的桥梁。使用 goroutine 的代码必然有一方提供数据,一方消费数据。当提供数据一方的数据供给速度大于消费方的数据处理速度时,如果通道不限制长度,那么内存将不断膨胀直到应用崩溃。因此,限制通道的长度有利于约束数据提供方的供给速度,供给数据量必须在消费方处理量+通道长度的范围内,才能正常地处理数据。
Go语言channel超时机制
Go语言没有提供直接的超时处理机制,所谓超时可以理解为当我们上网浏览一些网站时,如果一段时间之后不作操作,就需要重新登录。
那么我们应该如何实现这一功能呢,这时就可以使用 select 来设置超时。
虽然 select 机制不是专门为超时而设计的,却能很方便的解决超时问题,因为 select 的特点是只要其中有一个 case 已经完成,程序就会继续往下执行,而不会考虑其他 case 的情况。
超时机制本身虽然也会带来一些问题,比如在运行比较快的机器或者高速的网络上运行正常的程序,到了慢速的机器或者网络上运行就会出问题,从而出现结果不一致的现象,但从根本上来说,解决死锁问题的价值要远大于所带来的问题。
select 的用法与 switch 语言非常类似,由 select 开始一个新的选择块,每个选择条件由 case 语句来描述。
与 switch 语句相比,select 有比较多的限制,其中最大的一条限制就是每个 case 语句里必须是一个 IO 操作,大致的结构如下:
select {
case <-chan1:
// 如果chan1成功读到数据,则进行该case处理语句
case chan2 <- 1:
// 如果成功向chan2写入数据,则进行该case处理语句
default:
// 如果上面都没有成功,则进入default处理流程
}在一个 select 语句中,Go语言会按顺序从头至尾评估每一个发送和接收的语句。
如果其中的任意一语句可以继续执行(即没有被阻塞),那么就从那些可以执行的语句中任意选择一条来使用。
如果没有任意一条语句可以执行(即所有的通道都被阻塞),那么有如下两种可能的情况:
- 如果给出了 default 语句,那么就会执行 default 语句,同时程序的执行会从 select 语句后的语句中恢复;
- 如果没有 default 语句,那么 select 语句将被阻塞,直到至少有一个通信可以进行下去。
示例代码如下所示:
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int)
quit := make(chan bool)
//新开一个协程
go func() {
for {
select {
case num := <-ch:
fmt.Println("num = ", num)
case <-time.After(3 * time.Second):
fmt.Println("超时")
quit <- true
}
}
}() //别忘了()
for i := 0; i < 5; i++ {
ch <- i
time.Sleep(time.Second)
}
<-quit
fmt.Println("程序结束")
}运行结果如下:
num = 0
num = 1
num = 2
num = 3
num = 4
超时
程序结束Go语言通道的多路复用——同时处理接收和发送多个通道的数据
多路复用是通信和网络中的一个专业术语。多路复用通常表示在一个信道上传输多路信号或数据流的过程和技术。
提示:报话机同一时刻只能有一边进行收或者发的单边通信,报话机需要遵守的通信流程如下:
- 说话方在完成时需要补上一句“完毕”,随后放开通话按钮,从发送切换到接收状态,收听对方说话。
- 收听方在听到对方说“完毕”时,按下通话按钮,从接收切换到发送状态,开始说话。
电话可以在说话的同时听到对方说话,所以电话是一种多路复用的设备,一条通信线路上可以同时接收或者发送数据。同样的,网线、光纤也都是基于多路复用模式来设计的,网线、光纤不仅可支持同时收发数据,还支持多个人同时收发数据。
在使用通道时,想同时接收多个通道的数据是一件困难的事情。通道在接收数据时,如果没有数据可以接收将会发生阻塞。虽然可以使用如下模式进行遍历,但运行性能会非常差。
for{
// 尝试接收ch1通道
data, ok := <-ch1
// 尝试接收ch2通道
data, ok := <-ch2
// 接收后续通道
…
}Go语言中提供了 select 关键字,可以同时响应多个通道的操作。select 的用法与 switch 语句非常类似,由 select 开始一个新的选择块,每个选择条件由 case 语句来描述。
与 switch 语句可以选择任何可使用相等比较的条件相比,select 有比较多的限制,其中最大的一条限制就是每个 case 语句里必须是一个 IO 操作,大致结构如下:
select{
case 操作1:
响应操作1
case 操作2:
响应操作2
…
default:
没有操作情况
}操作1、操作2:包含通道收发语句,请参考下表。
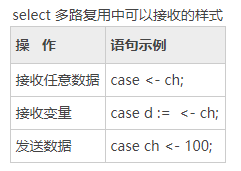
响应操作1、响应操作2:当操作发生时,会执行对应 case 的响应操作。
default:当没有任何操作时,默认执行 default 中的语句。
可以看出,select 不像 switch,后面并不带判断条件,而是直接去查看 case 语句。每个 case 语句都必须是一个面向 channel 的操作。
基于此功能,我们可以实现一个有趣的程序:
ch := make(chan int, 1)
for {
select {
case ch <- 0:
case ch <- 1:
}
i := <-ch
fmt.Println("Value received:", i)
}能看明白这段代码的含义吗?其实很简单,这个程序实现了一个随机向 ch 中写入一个 0 或者 1 的过程。当然,这是个死循环。关于 select 的详细使用方法,请参考下节的示例。
Go语言RPC(模拟远程过程调用)
服务器开发中会使用RPC(Remote Procedure Call,远程过程调用)简化进程间通信的过程。RPC 能有效地封装通信过程,让远程的数据收发通信过程看起来就像本地的函数调用一样。
本例中,使用通道代替 Socket 实现 RPC 的过程。客户端与服务器运行在同一个进程,服务器和客户端在两个 goroutine 中运行。
我们先给出完整代码,然后再详细分析每一个部分。
package main
import (
"errors"
"fmt"
"time"
)
// 模拟RPC客户端的请求和接收消息封装
func RPCClient(ch chan string, req string) (string, error) {
// 向服务器发送请求
ch <- req
// 等待服务器返回
select {
case ack := <-ch: // 接收到服务器返回数据
return ack, nil
case <-time.After(time.Second): // 超时
return "", errors.New("Time out")
}
}
// 模拟RPC服务器端接收客户端请求和回应
func RPCServer(ch chan string) {
for {
// 接收客户端请求
data := <-ch
// 打印接收到的数据
fmt.Println("server received:", data)
// 反馈给客户端收到
ch <- "roger"
}
}
func main() {
// 创建一个无缓冲字符串通道
ch := make(chan string)
// 并发执行服务器逻辑
go RPCServer(ch)
// 客户端请求数据和接收数据
recv, err := RPCClient(ch, "hi")
if err != nil {
// 发生错误打印
fmt.Println(err)
} else {
// 正常接收到数据
fmt.Println("client received", recv)
}
}客户端请求和接收封装
下面的代码封装了向服务器请求数据,等待服务器返回数据,如果请求方超时,该函数还会处理超时逻辑。
模拟 RPC 的代码:
// 模拟RPC客户端的请求和接收消息封装
func RPCClient(ch chan string, req string) (string, error) {
// 向服务器发送请求
ch <- req
// 等待服务器返回
select {
case ack := <-ch: // 接收到服务器返回数据
return ack, nil
case <-time.After(time.Second): // 超时
return "", errors.New("Time out")
}
}代码说明如下:
第 5 行,模拟 socket 向服务器发送一个字符串信息。服务器接收后,结束阻塞执行下一行。
第 8 行,使用 select 开始做多路复用。注意,select 虽然在写法上和 switch 一样,都可以拥有 case 和 default。但是 select 关键字后面不接任何语句,而是将要复用的多个通道语句写在每一个 case 上,如第 9 行和第 11 行所示。
第 11 行,使用了 time 包提供的函数 After(),从字面意思看就是多少时间之后,其参数是 time 包的一个常量,time.Second 表示 1 秒。time.After 返回一个通道,这个通道在指定时间后,通过通道返回当前时间。
第 12 行,在超时时,返回超时错误。
RPCClient() 函数中,执行到 select 语句时,第 9 行和第 11 行的通道操作会同时开启。如果第 9 行的通道先返回,则执行第 10 行逻辑,表示正常接收到服务器数据;如果第 11 行的通道先返回,则执行第 12 行的逻辑,表示请求超时,返回错误。
服务器接收和反馈数据
服务器接收到客户端的任意数据后,先打印再通过通道返回给客户端一个固定字符串,表示服务器已经收到请求。
// 模拟RPC服务器端接收客户端请求和回应
func RPCServer(ch chan string) {
for {
// 接收客户端请求
data := <-ch
// 打印接收到的数据
fmt.Println("server received:", data)
//向客户端反馈已收到
ch <- "roger"
}
}代码说明如下:
第 3 行,构造出一个无限循环。服务器处理完客户端请求后,通过无限循环继续处理下一个客户端请求。
第 5 行,通过字符串通道接收一个客户端的请求。
第 8 行,将接收到的数据打印出来。
第 11 行,给客户端反馈一个字符串。
运行整个程序,客户端可以正确收到服务器返回的数据,客户端 RPCClient() 函数的代码按下面代码中加粗部分的分支执行。
// 等待服务器返回
select {
case ack := <-ch: // 接收到服务器返回数据
return ack, nil
case <-time.After(time.Second): // 超时
return "", errors.New("Time out")
}程序输出如下:
server received: hi
client received roger模拟超时
上面的例子虽然有客户端超时处理,但是永远不会触发,因为服务器的处理速度很快,也没有真正的网络延时或者“服务器宕机”的情况。因此,为了展示 select 中超时的处理,在服务器逻辑中增加一条语句,故意让服务器延时处理一段时间,造成客户端请求超时,代码如下:
// 模拟RPC服务器端接收客户端请求和回应
func RPCServer(ch chan string) {
for {
// 接收客户端请求
data := <-ch
// 打印接收到的数据
fmt.Println("server received:", data)
// 通过睡眠函数让程序执行阻塞2秒的任务
time.Sleep(time.Second * 2)
// 反馈给客户端收到
ch <- "roger"
}
}第 11 行中,time.Sleep() 函数会让 goroutine 执行暂停 2 秒。使用这种方法模拟服务器延时,造成客户端超时。客户端处理超时 1 秒时通道就会返回:
// 等待服务器返回
select {
case ack := <-ch: // 接收到服务器返回数据
return ack, nil
case <-time.After(time.Second): // 超时
return "", errors.New("Time out")
}上面代码中,加黑部分的代码就会被执行。
主流程
主流程中会创建一个无缓冲的字符串格式通道。将通道传给服务器的 RPCServer() 函数,这个函数并发执行。使用 RPCClient() 函数通过 ch 对服务器发出 RPC 请求,同时接收服务器反馈数据或者等待超时。参考下面代码:
func main() {
// 创建一个无缓冲字符串通道
ch := make(chan string)
// 并发执行服务器逻辑
go RPCServer(ch)
// 客户端请求数据和接收数据
recv, err := RPCClient(ch, "hi")
if err != nil {
// 发生错误打印
fmt.Println(err)
} else {
// 正常接收到数据
fmt.Println("client received", recv)
}
}代码说明如下:
第 4 行,创建无缓冲的字符串通道,这个通道用于模拟网络和 socke t概念,既可以从通道接收数据,也可以发送。
第 7 行,并发执行服务器逻辑。服务器一般都是独立进程的,这里使用并发将服务器和客户端逻辑同时在一个进程内运行。
第 10 行,使用 RPCClient() 函数,发送“hi”给服务器,同步等待服务器返回。
第 13 行,如果通信过程发生错误,打印错误。
第 16 行,正常接收时,打印收到的数据。
示例:使用通道响应计时器的事件
Go语言中的 time 包提供了计时器的封装。由于 Go语言中的通道和 goroutine 的设计,定时任务可以在 goroutine 中通过同步的方式完成,也可以通过在 goroutine 中异步回调完成。这里将分两种用法进行例子展示。
一段时间之后(time.After)
延迟回调:
package main
import (
"fmt"
"time"
)
func main() {
// 声明一个退出用的通道
exit := make(chan int)
// 打印开始
fmt.Println("start")
// 过1秒后, 调用匿名函数
time.AfterFunc(time.Second, func() {
// 1秒后, 打印结果
fmt.Println("one second after")
// 通知main()的goroutine已经结束
exit <- 0
})
// 等待结束
<-exit
}代码说明如下:
第 10 行,声明一个退出用的通道,往这个通道里写数据表示退出。
第 16 行,调用 time.AfterFunc() 函数,传入等待的时间和一个回调。回调使用一个匿名函数,在时间到达后,匿名函数会在另外一个 goroutine 中被调用。
第 22 行,任务完成后,往退出通道中写入数值表示需要退出。
第 26 行,运行到此处时持续阻塞,直到 1 秒后第 22 行被执行后结束阻塞。
time.AfterFunc() 函数是在 time.After 基础上增加了到时的回调,方便使用。
而 time.After() 函数又是在 time.NewTimer() 函数上进行的封装,下面的例子展示如何使用 timer.NewTimer() 和 time.NewTicker()。
定点计时
计时器(Timer)的原理和倒计时闹钟类似,都是给定多少时间后触发。打点器(Ticker)的原理和钟表类似,钟表每到整点就会触发。这两种方法创建后会返回 time.Ticker 对象和 time.Timer 对象,里面通过一个 C 成员,类型是只能接收的时间通道(<-chan Time),使用这个通道就可以获得时间触发的通知。
下面代码创建一个打点器,每 500 毫秒触发一起;创建一个计时器,2 秒后触发,只触发一次。
计时器:
package main
import (
"fmt"
"time"
)
func main() {
// 创建一个打点器, 每500毫秒触发一次
ticker := time.NewTicker(time.Millisecond * 500)
// 创建一个计时器, 2秒后触发
stopper := time.NewTimer(time.Second * 2)
// 声明计数变量
var i int
// 不断地检查通道情况
for {
// 多路复用通道
select {
case <-stopper.C: // 计时器到时了
fmt.Println("stop")
// 跳出循环
goto StopHere
case <-ticker.C: // 打点器触发了
// 记录触发了多少次
i++
fmt.Println("tick", i)
}
}
// 退出的标签, 使用goto跳转
StopHere:
fmt.Println("done")
}代码说明如下:
第 11 行,创建一个打点器,500 毫秒触发一次,返回 time.Ticker 类型变量。
第 14 行,创建一个计时器,2 秒后返回,返回 time.Timer 类型变量。
第 17 行,声明一个变量,用于累计打点器触发次数。
第 20 行,每次触发后,select 会结束,需要使用循环再次从打点器返回的通道中获取触发通知。
第 23 行,同时等待多路计时器信号。
第 24 行,计时器信号到了。
第 29 行,通过 goto 跳出循环。
第 31 行,打点器信号到了,通过i自加记录触发次数并打印。
Go语言关闭通道后继续使用通道
通道是一个引用对象,和 map 类似。map 在没有任何外部引用时,Go语言程序在运行时(runtime)会自动对内存进行垃圾回收(Garbage Collection, GC)。类似的,通道也可以被垃圾回收,但是通道也可以被主动关闭。
格式
使用 close() 来关闭一个通道:
close(ch)关闭的通道依然可以被访问,访问被关闭的通道将会发生一些问题。
给被关闭通道发送数据将会触发 panic
被关闭的通道不会被置为 nil。如果尝试对已经关闭的通道进行发送,将会触发宕机,代码如下:
package main
import "fmt"
func main() {
// 创建一个整型的通道
ch := make(chan int)
// 关闭通道
close(ch)
// 打印通道的指针, 容量和长度
fmt.Printf("ptr:%p cap:%d len:%d\n", ch, cap(ch), len(ch))
// 给关闭的通道发送数据
ch <- 1
}代码运行后触发宕机:
panic: send on closed channel代码说明如下:
第 7 行,创建一个整型通道。
第 10 行,关闭通道,注意 ch 不会被 close 设置为 nil,依然可以被访问。
第 13 行,打印已经关闭通道的指针、容量和长度。
第 16 行,尝试给已经关闭的通道发送数据。
提示触发宕机的原因是给一个已经关闭的通道发送数据。
从已关闭的通道接收数据时将不会发生阻塞
从已经关闭的通道接收数据或者正在接收数据时,将会接收到通道类型的零值,然后停止阻塞并返回。
操作关闭后的通道:
package main
import "fmt"
func main() {
// 创建一个整型带两个缓冲的通道
ch := make(chan int, 2)
// 给通道放入两个数据
ch <- 0
ch <- 1
// 关闭缓冲
close(ch)
// 遍历缓冲所有数据, 且多遍历1个
for i := 0; i < cap(ch)+1; i++ {
// 从通道中取出数据
v, ok := <-ch
// 打印取出数据的状态
fmt.Println(v, ok)
}
}代码运行结果如下:
0 true
1 true
0 false代码说明如下:
第 7 行,创建一个能保存两个元素的带缓冲的通道,类型为整型。
第 10 行和第11行,给这个带缓冲的通道放入两个数据。这时,通道装满了。
第 14 行,关闭通道。此时,带缓冲通道的数据不会被释放,通道也没有消失。
第 17 行,cap() 函数可以获取一个对象的容量,这里获取的是带缓冲通道的容量,也就是这个通道在 make 时的大小。虽然此时这个通道的元素个数和容量都是相同的,但是 cap 取出的并不是元素个数。这里多遍历一个元素,故意造成这个通道的超界访问。
第 20 行,从已关闭的通道中获取数据,取出的数据放在 v 变量中,类型为 int。ok 变量的结果表示数据是否获取成功。
第 23 行,将 v 和 ok 变量打印出来。
运行结果前两行正确输出带缓冲通道的数据,表明缓冲通道在关闭后依然可以访问内部的数据。
运行结果第三行的“0 false”表示通道在关闭状态下取出的值。0 表示这个通道的默认值,false 表示没有获取成功,因为此时通道已经空了。我们发现,在通道关闭后,即便通道没有数据,在获取时也不会发生阻塞,但此时取出数据会失败。
Go语言多核并行化
Go语言具有支持高并发的特性,可以很方便地实现多线程运算,充分利用多核心 cpu 的性能。
众所周知服务器的处理器大都是单核频率较低而核心数较多,对于支持高并发的程序语言,可以充分利用服务器的多核优势,从而降低单核压力,减少性能浪费。
Go语言实现多核多线程并发运行是非常方便的,下面举个例子:
package main
import (
"fmt"
)
func main() {
for i := 0; i < 5; i++ {
go AsyncFunc(i)
}
}
func AsyncFunc(index int) {
sum := 0
for i := 0; i < 10000; i++ {
sum += 1
}
fmt.Printf("线程%d, sum为:%d\n", index, sum)
}运行结果如下:
线程0, sum为:10000
线程2, sum为:10000
线程3, sum为:10000
线程1, sum为:10000
线程4, sum为:10000在执行一些昂贵的计算任务时,我们希望能够尽量利用现代服务器普遍具备的多核特性来尽量将任务并行化,从而达到降低总计算时间的目的。此时我们需要了解 CPU 核心的数量,并针对性地分解计算任务到多个 goroutine 中去并行运行。
下面我们来模拟一个完全可以并行的计算任务:计算 N 个整型数的总和。我们可以将所有整型数分成 M 份,M 即 CPU 的个数。让每个 CPU 开始计算分给它的那份计算任务,最后将每个 CPU 的计算结果再做一次累加,这样就可以得到所有 N 个整型数的总和:
type Vector []float64
// 分配给每个CPU的计算任务
func (v Vector) DoSome(i, n int, u Vector, c chan int) {
for ; i < n; i++ {
v[i] += u.Op(v[i])
}
c <- 1 // 发信号告诉任务管理者我已经计算完成了
}
const NCPU = 16 // 假设总共有16核
func (v Vector) DoAll(u Vector) {
c := make(chan int, NCPU) // 用于接收每个CPU的任务完成信号
for i := 0; i < NCPU; i++ {
go v.DoSome(i*len(v)/NCPU, (i+1)*len(v)/NCPU, u, c)
}
// 等待所有CPU的任务完成
for i := 0; i < NCPU; i++ {
<-c // 获取到一个数据,表示一个CPU计算完成了
}
// 到这里表示所有计算已经结束
}这两个函数看起来设计非常合理,其中 DoAll() 会根据 CPU 核心的数目对任务进行分割,然后开辟多个 goroutine 来并行执行这些计算任务。
是否可以将总的计算时间降到接近原来的 1/N 呢?答案是不一定。如果掐秒表,会发现总的执行时间没有明显缩短。再去观察 CPU 运行状态,你会发现尽管我们有 16 个 CPU 核心,但在计算过程中其实只有一个 CPU 核心处于繁忙状态,这是会让很多Go语言初学者迷惑的问题。
官方给出的答案是,这是当前版本的 Go 编译器还不能很智能地去发现和利用多核的优势。虽然我们确实创建了多个 goroutine,并且从运行状态看这些 goroutine 也都在并行运行,但实际上所有这些 goroutine 都运行在同一个 CPU 核心上,在一个 goroutine 得到时间片执行的时候,其他 goroutine 都会处于等待状态。从这一点可以看出,虽然 goroutine 简化了我们写并行代码的过程,但实际上整体运行效率并不真正高于单线程程序。
虽然Go语言还不能很好的利用多核心的优势,我们可以先通过设置环境变量 GOMAXPROCS 的值来控制使用多少个 CPU 核心。具体操作方法是通过直接设置环境变量 GOMAXPROCS 的值,或者在代码中启动 goroutine 之前先调用以下这个语句以设置使用 16 个 CPU 核心:
runtime.GOMAXPROCS(16)到底应该设置多少个 CPU 核心呢,其实 runtime 包中还提供了另外一个 NumCPU() 函数来获取核心数,示例代码如下:
package main
import (
"fmt"
"runtime"
)
func main() {
cpuNum := runtime.NumCPU() //获得当前设备的cpu核心数
fmt.Println("cpu核心数:", cpuNum)
runtime.GOMAXPROCS(cpuNum) //设置需要用到的cpu数量
}运行结果如下:
cpu核心数: 4Go语言Telnet回音服务器——TCP服务器的基本结构
Telnet 协议是 TCP/IP 协议族中的一种。它允许用户(Telnet 客户端)通过一个协商过程与一个远程设备进行通信。本例将使用一部分 Telnet 协议与服务器进行通信。
服务器的网络库为了完整展示自己的代码实现了完整的收发过程,一般比较倾向于使用发送任意封包返回原数据的逻辑。这个过程类似于对着大山高喊,大山把你的声音原样返回的过程。也就是回音(Echo)。本节使用 Go语言中的 Socket、goroutine 和通道编写一个简单的 Telnet 协议的回音服务器。
回音服务器的代码分为 4 个部分,分别是接受连接、会话处理、Telnet 命令处理和程序入口。
接受连接
回音服务器能同时服务于多个连接。要接受连接就需要先创建侦听器,侦听器需要一个侦听地址和协议类型。就像你想卖东西,需要先确认卖什么东西,卖东西的类型就是协议类型,然后需要一个店面,店面位于街区的某个位置,这就是侦听器的地址。一个服务器可以开启多个侦听器,就像一个街区可以有多个店面。街区上的编号对应的就是地址中的端口号,如下图所示。
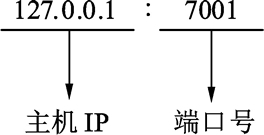
主机 IP:一般为一个 IP 地址或者域名,127.0.0.1 表示本机地址。
端口号:16 位无符号整型值,一共有 65536 个有效端口号。
通过地址和协议名创建侦听器后,可以使用侦听器响应客户端连接。响应连接是一个不断循环的过程,就像到银行办理业务时,一般是排队处理,前一个人办理完后,轮到下一个人办理。
我们把每个客户端连接处理业务的过程叫做会话。在会话中处理的操作和接受连接的业务并不冲突可以同时进行。就像银行有 3 个窗口,喊号器会将用户分配到不同的柜台。这里的喊号器就是 Accept 操作,窗口的数量就是 CPU 的处理能力。因此,使用 goroutine 可以轻松实现会话处理和接受连接的并发执行。
如下图清晰地展现了这一过程。
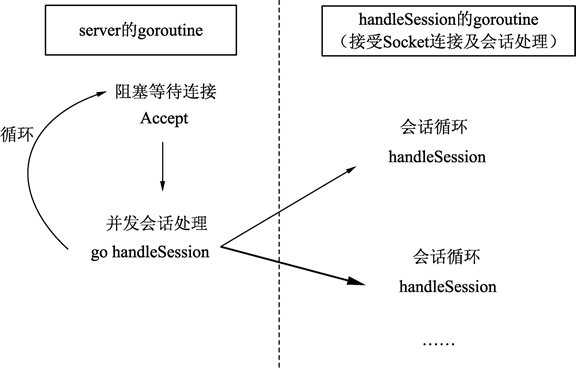
图:Socket 处理过程
Go语言中可以根据实际会话数量创建多个 goroutine,并自动的调度它们的处理。
telnet 服务器处理:
package main
import (
"fmt"
"net"
)
// 服务逻辑, 传入地址和退出的通道
func server(address string, exitChan chan int) {
// 根据给定地址进行侦听
l, err := net.Listen("tcp", address)
// 如果侦听发生错误, 打印错误并退出
if err != nil {
fmt.Println(err.Error())
exitChan <- 1
}
// 打印侦听地址, 表示侦听成功
fmt.Println("listen: " + address)
// 延迟关闭侦听器
defer l.Close()
// 侦听循环
for {
// 新连接没有到来时, Accept是阻塞的
conn, err := l.Accept()
// 发生任何的侦听错误, 打印错误并退出服务器
if err != nil {
fmt.Println(err.Error())
continue
}
// 根据连接开启会话, 这个过程需要并行执行
go handleSession(conn, exitChan)
}
}代码说明如下:
第 9 行,接受连接的入口,address 为传入的地址,退出服务器使用 exitChan 的通道控制。往 exitChan 写入一个整型值时,进程将以整型值作为程序返回值来结束服务器。
第 12 行,使用 net 包的 Listen() 函数进行侦听。这个函数需要提供两个参数,第一个参数为协议类型,本例需要做的是 TCP 连接,因此填入“tcp”;address 为地址,格式为“主机:端口号”。
第 15 行,如果侦听发生错误,通过第 17 行,往 exitChan 中写入非 0 值结束服务器,同时打印侦听错误。
第 24 行,使用 defer,将侦听器的结束延迟调用。
第 27 行,侦听开始后,开始进行连接接受,每次接受连接后需要继续接受新的连接,周而复始。
第 30 行,服务器接受了一个连接。在没有连接时,Accept() 函数调用后会一直阻塞。连接到来时,返回 conn 和错误变量,conn 的类型是 *tcp.Conn。
第 33 行,某些情况下,连接接受会发生错误,不影响服务器逻辑,这时重新进行新连接接受。
第 39 行,每个连接会生成一个会话。这个会话的处理与接受逻辑需要并行执行,彼此不干扰。
会话处理
每个连接的会话就是一个接收数据的循环。当没有数据时,调用 reader.ReadString 会发生阻塞,等待数据的到来。一旦数据到来,就可以进行各种逻辑处理。
回音服务器的基本逻辑是“收到什么返回什么”,reader.ReadString 可以一直读取 Socket 连接中的数据直到碰到期望的结尾符。这种期望的结尾符也叫定界符,一般用于将 TCP 封包中的逻辑数据拆分开。下例中使用的定界符是回车换行符(“\r\n”),HTTP 协议也是使用同样的定界符。使用 reader.ReadString() 函数可以将封包简单地拆分开。
如下图所示为 Telnet 数据处理过程。
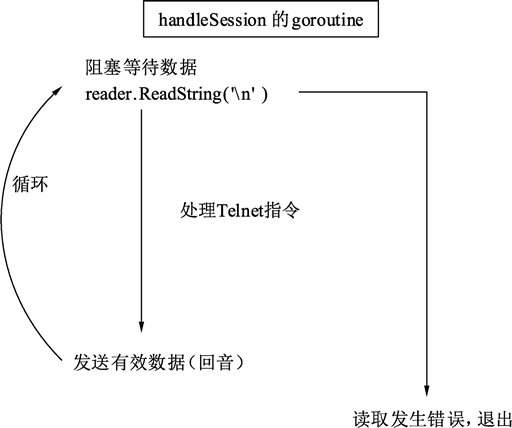
图:Telnet 数据处理过程
回音服务器需要将收到的有效数据通过 Socket 发送回去。
Telnet会话处理:
package main
import (
"bufio"
"fmt"
"net"
"strings"
)
// 连接的会话逻辑
func handleSession(conn net.Conn, exitChan chan int) {
fmt.Println("Session started:")
// 创建一个网络连接数据的读取器
reader := bufio.NewReader(conn)
// 接收数据的循环
for {
// 读取字符串, 直到碰到回车返回
str, err := reader.ReadString('\n')
// 数据读取正确
if err == nil {
// 去掉字符串尾部的回车
str = strings.TrimSpace(str)
// 处理Telnet指令
if !processTelnetCommand(str, exitChan) {
conn.Close()
break
}
// Echo逻辑, 发什么数据, 原样返回
conn.Write([]byte(str + "\r\n"))
} else {
// 发生错误
fmt.Println("Session closed")
conn.Close()
break
}
}
}代码说明如下:
第 11 行是会话入口,传入连接和退出用的通道。handle Session() 函数被并发执行。
第 16 行,使用 bufio 包的 NewReader() 方法,创建一个网络数据读取器,这个 Reader 将输入数据的读取过程进行封装,方便我们迅速获取到需要的数据。
第 19 行,会话处理开始时,从 Socket 连接,通过 reader 读取器读取封包,处理封包后需要继续读取从网络发送过来的下一个封包,因此需要一个会话处理循环。
第 22 行,使用 reader.ReadString() 方法进行封包读取。内部会自动处理粘包过程,直到下一个回车符到达后返回数据。这里认为封包来自 Telnet,每个指令以回车换行符(“\r\n”)结尾。
第 25 行,数据读取正常时,返回 err 为 nil。如果发生连接断开、接收错误等网络错误时,err 就不是 nil 了。
第 28 行,reader.ReadString 读取返回的字符串尾部带有回车符,使用 strings.TrimSpace() 函数将尾部带的回车和空白符去掉。
第 31 行,将 str 字符串传入 Telnet 指令处理函数 processTelnetCommand() 中,同时传入退出控制通道 exitChan。当这个函数返回 false 时,表示需要关闭当前连接。
第 32 行和第 33 行,关闭当前连接并退出会话接受循环。
第 37 行,将有效数据通过 conn 的 Write() 方法写入,同时在字符串尾部添加回车换行符(“\r\n”),数据将被 Socket 发送给连接方。
第 41~43 行,处理当 reader.ReadString() 函数返回错误时,打印错误信息并关闭连接,退出会话并接收循环。
Telnet命令处理
Telnet 是一种协议。在操作系统中可以在命令行使用 Telnet 命令发起 TCP 连接。我们一般用 Telnet 来连接 TCP 服务器,键盘输入一行字符回车后,即被发送到服务器上。
在下例中,定义了以下两个特殊控制指令,用以实现一些功能:
- 输入“@close”退出当前连接会话。
- 输入“@shutdown”终止服务器运行。
Telnet命令处理:
package main
import (
"fmt"
"strings"
)
func processTelnetCommand(str string, exitChan chan int) bool {
// @close指令表示终止本次会话
if strings.HasPrefix(str, "@close") {
fmt.Println("Session closed")
// 告诉外部需要断开连接
return false
// @shutdown指令表示终止服务进程
} else if strings.HasPrefix(str, "@shutdown") {
fmt.Println("Server shutdown")
// 往通道中写入0, 阻塞等待接收方处理
exitChan <- 0
// 告诉外部需要断开连接
return false
}
// 打印输入的字符串
fmt.Println(str)
return true
}代码说明如下:
第 8 行,处理 Telnet 命令的函数入口,传入有效字符并退出通道。
第 11~16 行,当输入字符串中包含“@close”前缀时,在第 16 行返回 false,表示需要关闭当前会话。
第 19~27 行,当输入字符串中包含“@shutdown”前缀时,第 24 行将 0 写入 exitChan,表示结束服务器。
第 31 行,没有特殊的控制字符时,打印输入的字符串。
程序入口
Telnet 回音处理主流程:
package main
import (
"os"
)
func main() {
// 创建一个程序结束码的通道
exitChan := make(chan int)
// 将服务器并发运行
go server("127.0.0.1:7001", exitChan)
// 通道阻塞, 等待接收返回值
code := <-exitChan
// 标记程序返回值并退出
os.Exit(code)
}代码说明如下:
第 10 行,创建一个整型的无缓冲通道作为退出信号。
第 13 行,接受连接的过程可以并发操作,使用 go 将 server() 函数开启 goroutine。
第 16 行,从 exitChan 中取出返回值。如果取不到数据就一直阻塞。
第 19 行,将程序返回值传入 os.Exit() 函数中并终止程序。
编译所有代码并运行,命令行提示如下:
listen: 127.0.0.1:7001此时,Socket 侦听成功。在操作系统中的命令行中输入:
telnet 127.0.0.1 7001尝试连接本地的 7001 端口。接下来进入测试服务器的流程。
测试输入字符串
在 Telnet 连接后,输入字符串 hello,Telnet 命令行显示如下:
$ telnet 127.0.0.1 7001
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
hello
hello服务器显示如下:
listen: 127.0.0.1:7001
Session started:
hello客户端输入的字符串会在服务器中显示,同时客户端也会收到自己发给服务器的内容,这就是一次回音。
测试关闭会话
当输入 @close 时,Telnet 命令行显示如下:
@close
Connection closed by foreign host服务器显示如下:
Session closed此时,客户端 Telnet 与服务器断开连接。
测试关闭服务器
当输入 @shutdown 时,Telnet 命令行显示如下:
@shutdown
Connection closed by foreign host服务器显示如下:
Server shutdown此时服务器会自动关闭。
Go语言竞态检测——检测代码在并发环境下可能出现的问题
Go语言程序可以使用通道进行多个 goroutine 间的数据交换,但这仅仅是数据同步中的一种方法。通道内部的实现依然使用了各种锁,因此优雅代码的代价是性能。在某些轻量级的场合,原子访问(atomic包)、互斥锁(sync.Mutex)以及等待组(sync.WaitGroup)能最大程度满足需求。
本节只讲解原子访问,互斥锁和等待组将在接下来的两节中讲解。
当多线程并发运行的程序竞争访问和修改同一块资源时,会发生竞态问题。
下面的代码中有一个 ID 生成器,每次调用生成器将会生成一个不会重复的顺序序号,使用 10 个并发生成序号,观察 10 个并发后的结果。
竞态检测的具体代码:
package main
import (
"fmt"
"sync/atomic"
)
var (
// 序列号
seq int64
)
// 序列号生成器
func GenID() int64 {
// 尝试原子的增加序列号
atomic.AddInt64(&seq, 1)
return seq
}
func main() {
//生成10个并发序列号
for i := 0; i < 10; i++ {
go GenID()
}
fmt.Println(GenID())
}代码说明如下:
第 10 行,序列号生成器中的保存上次序列号的变量。
第 17 行,使用原子操作函数 atomic.AddInt64() 对 seq() 函数加 1 操作。不过这里故意没有使用 atomic.AddInt64() 的返回值作为 GenID() 函数的返回值,因此会造成一个竞态问题。
第 25 行,循环 10 次生成 10 个 goroutine 调用 GenID() 函数,同时忽略 GenID() 的返回值。
第 28 行,单独调用一次 GenID() 函数。
在运行程序时,为运行参数加入-race参数,开启运行时(runtime)对竞态问题的分析,命令如下:
go run -race racedetect.go代码运行发生宕机,输出信息如下:
==================
WARNING: DATA RACE
Write at 0x000000f52f40 by goroutine 7:
sync/atomic.AddInt64()
C:/Go/src/runtime/race_amd64.s:276 +0xb
main.GenID()
racedetect.go:17 +0x4a
Previous read at 0x000000f52f40 by goroutine 6:
main.GenID()
racedetect.go:18 +0x5a
Goroutine 7 (running) created at:
main.main()
racedetect.go:25 +0x5a
Goroutine 6 (finished) created at:
main.main()
racedetect.go:25 +0x5a
==================
10
Found 1 data race(s)
exit status 66根据报错信息,第 18 行有竞态问题,根据 atomic.AddInt64() 的参数声明,这个函数会将修改后的值以返回值方式传出。下面代码对加粗部分进行了修改:
func GenID() int64 {
// 尝试原子的增加序列号
return atomic.AddInt64(&seq, 1)
}再次运行:
go run -race main.go代码输出如下:
10没有发生竞态问题,程序运行正常。
本例中只是对变量进行增减操作,虽然可以使用互斥锁(sync.Mutex)解决竞态问题,但是对性能消耗较大。在这种情况下,推荐使用原子操作(atomic)进行变量操作。
Go语言互斥锁(sync.Mutex)和读写互斥锁(sync.RWMutex)
Go语言包中的 sync 包提供了两种锁类型:sync.Mutex 和 sync.RWMutex。
Mutex 是最简单的一种锁类型,同时也比较暴力,当一个 goroutine 获得了 Mutex 后,其他 goroutine 就只能乖乖等到这个 goroutine 释放该 Mutex。
RWMutex 相对友好些,是经典的单写多读模型。在读锁占用的情况下,会阻止写,但不阻止读,也就是多个 goroutine 可同时获取读锁(调用 RLock() 方法;而写锁(调用 Lock() 方法)会阻止任何其他 goroutine(无论读和写)进来,整个锁相当于由该 goroutine 独占。从 RWMutex 的实现看,RWMutex 类型其实组合了 Mutex:
type RWMutex struct {
w Mutex
writerSem uint32
readerSem uint32
readerCount int32
readerWait int32
}对于这两种锁类型,任何一个 Lock() 或 RLock() 均需要保证对应有 Unlock() 或 RUnlock() 调用与之对应,否则可能导致等待该锁的所有 goroutine 处于饥饿状态,甚至可能导致死锁。锁的典型使用模式如下:
package main
import (
"fmt"
"sync"
)
var (
// 逻辑中使用的某个变量
count int
// 与变量对应的使用互斥锁
countGuard sync.Mutex
)
func GetCount() int {
// 锁定
countGuard.Lock()
// 在函数退出时解除锁定
defer countGuard.Unlock()
return count
}
func SetCount(c int) {
countGuard.Lock()
count = c
countGuard.Unlock()
}
func main() {
// 可以进行并发安全的设置
SetCount(1)
// 可以进行并发安全的获取
fmt.Println(GetCount())
}代码说明如下:
第 10 行是某个逻辑步骤中使用到的变量,无论是包级的变量还是结构体成员字段,都可以。
第 13 行,一般情况下,建议将互斥锁的粒度设置得越小越好,降低因为共享访问时等待的时间。这里笔者习惯性地将互斥锁的变量命名为以下格式:
变量名+Guard以表示这个互斥锁用于保护这个变量。
第 16 行是一个获取 count 值的函数封装,通过这个函数可以并发安全的访问变量 count。
第 19 行,尝试对 countGuard 互斥量进行加锁。一旦 countGuard 发生加锁,如果另外一个 goroutine 尝试继续加锁时将会发生阻塞,直到这个 countGuard 被解锁。
第 22 行使用 defer 将 countGuard 的解锁进行延迟调用,解锁操作将会发生在 GetCount() 函数返回时。
第 27 行在设置 count 值时,同样使用 countGuard 进行加锁、解锁操作,保证修改 count 值的过程是一个原子过程,不会发生并发访问冲突。
在读多写少的环境中,可以优先使用读写互斥锁(sync.RWMutex),它比互斥锁更加高效。sync 包中的 RWMutex 提供了读写互斥锁的封装。
我们将互斥锁例子中的一部分代码修改为读写互斥锁,参见下面代码:
var (
// 逻辑中使用的某个变量
count int
// 与变量对应的使用互斥锁
countGuard sync.RWMutex
)
func GetCount() int {
// 锁定
countGuard.RLock()
// 在函数退出时解除锁定
defer countGuard.RUnlock()
return count
}代码说明如下:
第 6 行,在声明 countGuard 时,从 sync.Mutex 互斥锁改为 sync.RWMutex 读写互斥锁。
第 12 行,获取 count 的过程是一个读取 count 数据的过程,适用于读写互斥锁。在这一行,把 countGuard.Lock() 换做 countGuard.RLock(),将读写互斥锁标记为读状态。如果此时另外一个 goroutine 并发访问了 countGuard,同时也调用了 countGuard.RLock() 时,并不会发生阻塞。
第 15 行,与读模式加锁对应的,使用读模式解锁。
Go语言等待组(sync.WaitGroup)
Go语言中除了可以使用通道(channel)和互斥锁进行两个并发程序间的同步外,还可以使用等待组进行多个任务的同步,等待组可以保证在并发环境中完成指定数量的任务
在 sync.WaitGroup(等待组)类型中,每个 sync.WaitGroup 值在内部维护着一个计数,此计数的初始默认值为零。
等待组有下面几个方法可用,如下表所示。

对于一个可寻址的 sync.WaitGroup 值 wg:
- 我们可以使用方法调用 wg.Add(delta) 来改变值 wg 维护的计数。
- 方法调用 wg.Done() 和 wg.Add(-1) 是完全等价的。
- 如果一个 wg.Add(delta) 或者 wg.Done() 调用将 wg 维护的计数更改成一个负数,一个恐慌将产生。
- 当一个协程调用了 wg.Wait() 时,
- 如果此时 wg 维护的计数为零,则此 wg.Wait() 此操作为一个空操作(noop);
- 否则(计数为一个正整数),此协程将进入阻塞状态。当以后其它某个协程将此计数更改至 0 时(一般通过调用 wg.Done()),此协程将重新进入运行状态(即 wg.Wait() 将返回)。
等待组内部拥有一个计数器,计数器的值可以通过方法调用实现计数器的增加和减少。当我们添加了 N 个并发任务进行工作时,就将等待组的计数器值增加 N。每个任务完成时,这个值减 1。同时,在另外一个 goroutine 中等待这个等待组的计数器值为 0 时,表示所有任务已经完成。
下面的代码演示了这一过程:
package main
import (
"fmt"
"net/http"
"sync"
)
func main() {
// 声明一个等待组
var wg sync.WaitGroup
// 准备一系列的网站地址
var urls = []string{
"http://www.github.com/",
"https://www.qiniu.com/",
"https://www.golangtc.com/",
}
// 遍历这些地址
for _, url := range urls {
// 每一个任务开始时, 将等待组增加1
wg.Add(1)
// 开启一个并发
go func(url string) {
// 使用defer, 表示函数完成时将等待组值减1
defer wg.Done()
// 使用http访问提供的地址
_, err := http.Get(url)
// 访问完成后, 打印地址和可能发生的错误
fmt.Println(url, err)
// 通过参数传递url地址
}(url)
}
// 等待所有的任务完成
wg.Wait()
fmt.Println("over")
}代码说明如下:
第 12 行,声明一个等待组,对一组等待任务只需要一个等待组,而不需要每一个任务都使用一个等待组。
第 15 行,准备一系列可访问的网站地址的字符串切片。
第 22 行,遍历这些字符串切片。
第 25 行,将等待组的计数器加1,也就是每一个任务加 1。
第 28 行,将一个匿名函数开启并发。
第 31 行,在匿名函数结束时会执行这一句以表示任务完成。wg.Done() 方法等效于执行 wg.Add(-1)。
第 34 行,使用 http 包提供的 Get() 函数对 url 进行访问,Get() 函数会一直阻塞直到网站响应或者超时。
第 37 行,在网站响应和超时后,打印这个网站的地址和可能发生的错误。
第 40 行,这里将 url 通过 goroutine 的参数进行传递,是为了避免 url 变量通过闭包放入匿名函数后又被修改的问题。
第 44 行,等待所有的网站都响应或者超时后,任务完成,Wait 就会停止阻塞。
Go语言死锁、活锁和饥饿概述
前面的部分都是关于程序正确性的讨论,如果这些问题得到正确的处理,那我们的程序将永远不会给出错误的答案。不幸的是,即使成功处理了这些问题,还有另一类问题需要解决:死锁、活锁和饥饿。所有这些问题都与你的程序密切相关,它们保证了你的程序在任何时候都在做着一些真正有用的事。如果没有正确处理,程序可能会进入一种完全停止正常工作的状态。
死锁
死锁程序是所有并发进程彼此等待的程序。在这种情况下,如果没有外界的干预,这个程序将永远无法恢复。
这听起来很严峻,那是因为的确如此!Go语言的运行时会尽其所能,检测一些死锁(所有的 goroutine 必须被阻塞,或者“asleep”),但是这对于防止死锁并没有太多的帮助。
为了帮助理解死锁是什么,我们先来看一个例子。同样,忽略任何你不知道的类型,函数,方法或是你不知道的包,只理解什么是死锁即可。
type value struct {
mu sync.Mutex
value int
}
var wg sync.WaitGroup
printSum := func(v1, v2 *value) {
defer wg.Done()
v1.mu.Lock() //在这里,我们尝试进入临界区来传入一个值。
defer v1.mu.Unlock() //在这里,我们使用defer语句在printSum返回之前退出临界区。
time.Sleep(2*time.Second) //在这里,我们休眠了一段时间来模拟一些工作(并触发死锁)
v2.mu.Lock()
defer v2.mu.Unlock()
fmt.Printf("sum=%v\n", v1.value + v2.value)
}
var a, b value
wg.Add(2)
go printSum(&a, &b)
go printSum(&b, &a)
wg.Wait()如果尝试运行此代码,可能会看到:
fatal error: all goroutines are asleep - deadlock!为什么呢?如果仔细观察,就可以在此代码中看到时机问题。以下是运行时的图形表示。这些框表示函数,水平线表示调用这些函数,竖线表示图形头部的函数生存时间,如下图所示。
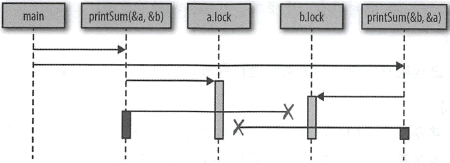
图 :一个因时间问题导致死锁的演示
本质上,我们创建了两个不能转动的齿轮:第一次调用 printSum 锁定 a,然后试图锁定 b ,但在此期间,第二次调用 printSum 己锁定 b 并试图锁定 a。这两个 goroutine 都无限地等待着。
以图形的方式展示为什么会出现死锁似乎很明确,但是更严格的定义会给我们带来更多的好处。事实证明,出现死锁有几个必要条件。1971 年,Edgar Coffman 在一篇论文中列举了这些条件。这些条件现在被称为 Coffman 条件,是帮助检测、防止和纠正死锁的技术依据。
Coffman 条件如下:
- 相互排斥:井发进程同时拥有资源的独占权。
- 等待条件:并发进程必须同时拥有一个资源,并等待额外的资源。
- 没有抢占:并发进程拥有的资掘只能被该进程释放,即可满足这个条件。
- 循环等待:一个并发进程(P1)必须等待一系列其他井发进程(P2),这些并发进程同时也在等待进程(P2),这样便满足了这个最终条件。
注意:我们实际上并不能保证 goroutines 的运行顺序,或者需妥多长时间才能启动。虽然不太可能,但是一个 goroutine 可以在另一个 goroutine 开始之前获得和释放锁,从而避免死锁,这是有道理的。
来看看我们设计的程序,并确定它是否符合所有四个条件:
- printSum 函数确实需要 a 和 b 的独占权,所以它满足了这个条件。
- 因为 printSum 持有 a 或 b 并正在等待另一个,所以它满足这个条件。
- 我们没有任何办怯让我们的 goroutine 被抢占。
- 我们第一次调用 printSum 正在等待我们的第二次调用;反之亦然。
是的,我们写出来的无疑是一个死锁了。
这些规则也帮助我们防止死锁。如果确保至少有一个条件不成立,我们可以防止发生死锁。不幸的是,实际上这些条件很难推理,因此很难预防。网络上散布着诸如你和我这样的开发者的疑问,他们想知道为什么一小段代码是死锁的。通常情况下,一旦有人指出,这是非常明显的,但往往需要另一双眼睛。
活锁
店锁是正在主动执行并发操作的程序,但是这些操作无战向前推进程序的状态。
你曾经在走廊走向另一个人吗?她移动到一边让你通过,但你也做了同样的事情。所以你转到另一边,但她也是这样做的。想象一下这个情形永远持续下去,你就明白了活锁。
我们实际上编写一些代码来演示这种情况。首先,我们将设置一些辅助函数来简化示例。为了有一个可以工作的例子,这里的代码利用了我们尚未涉及的几个主题。不建议试图了解它的细节,直到有把握可以使用好 sync 包。相反,建议遵循代码标注来理解强调的部分,然后将注意力转向包含示例核心的第二个代码块。
cadence := sync.NewCond(&sync.Mutex{})
go func () {
for range time.Tick(1*time.Millisecond) {
cadence.Broadcast()
}
}()
takeStep := func() {
cadence.L.Lock()
cadence.Wait()
cadence.L.Unlock()
}
//tryDir 允许一个人尝试向一个方向移动,并返回是否成功。dir,每个方向都表示为试图朝这个方向移动的人数。
tryDir := func(dirName string, dir *int32, out *bytes.Buffer) bool {
fmt.Fprintf(out, " %v", dirName)
//首先,我们宣布将要向这个方向移动一个距离。现在,只需要知道这个包的操作是原子操作。
atomic.Addint32(dir, 1)
//为了演示活锁,每个人都必须以相同的速度或节奏移动。takeStep 模拟所有对象之间的一个不变的节奏。
takeStep()
if atomic.LoadInt32(dir) == 1 {
fmt.Fprint(out, ". Success!")
return true
}
takeStep()
//这里的人意识到他们不能向这个方向走而放弃。我们通过把这个方向减 1 来表示。
atomic.AddInt32(dir, -1)
return false
}
var left, right int32
tryLeft := func(out *bytes.Buffer) bool { return tryDir("left", &left, out)}
tryRight := func(out *bytes.Buffer) bool { return tryDir("right", &right, out)}
walk := func(walking *sync.WaitGroup, name string) {
var out bytes.Buffer
defer func() {fmt.Println(out.String()) }()
defer walking.Done()
fmt.Fprintf(&out, "%v is trying to scoot:", name)
//对尝试次数进行了人为限制,以便此程序能结束。在一个有活锁的程序中,可能没有这个限制,这就是为什么它是一个问题!
for i:=O; i<5; i++{
//首先,这个人会试图向左走,如果失败了,他们会尝试向右走
if tryLeft(&out) || tryRight(&out) {
return
}
}
fmt.Fprintf(&out, "\n%v tosses her hands up in exasperation!", name)
}
//这个变量为程序提供了一个等待直到两个人都能够相互通过或放弃的方式
var peopleInHallway sync.WaitGroup
peopleInHallway.Add(2)
go walk(&peopleInHallway, "Alice")
go walk(&peopleInHallway, "Barbara")
peopleInHallway.Wait()输出如下:
Alice is trying to scoot: left right left right left right left right left right
Alice tosses her hands up in exasperation!
Barbara is trying to scoot: left right left right left right left right
left right
Barbara tosses her hands up in exasperation!可以看到, Alice 和 Barbara 在最终退出之前,会持续竞争。
这个例子横示了使用活锁的一个卡分常见的原因:两个或两个以上的并发进程试图在没有协调的情况下防止死锁。这就好比,如果走廊里的人都同意,只有一个人会移动,那就不会有活锁:一个人会站着不动,另一个人会移到另一边,他们就会继续移动。
在我看来,活锁要比死锁更复杂,因为它看起来程序好像在工作。如果一个活锁程序在你的机器上运行,那可以通过查看 CPU 利用率来确定它是否在做处理某些逻辑,大家可能会认为它确实是在工作。根据活锁的不同,它甚至可能发出其他信号,让大家认为它在工作。然而,程序将会一直上演“hallway-shuffle”的循环游戏。
活锁是一组被称为“饥饿”的更大问题的子集。
饥饿
饥饿是在任何情况下,并发进程都无法获得执行工作所需的所有资源。
当我们讨论活锁时,每个 goroutine 的资源是一个共享锁。
活锁保证讨论与饥饿是无关的,因为在活锁中,所有并发进程都是相同的,并且没有完成工作。更广泛地说,饥饿通常意味着有一个或多个贪婪的并发进程,它们不公平地阻止一个或多个井发进程,以尽可能有效地完成工作,或者阻止全部并发进程。
这里有一个程序的例子,有一个贪婪的 goroutine 和一个平和的 goroutine:
var wg sync.WaitGroup
var sharedLock sync.Mutex
const runtime = 1*time.Second
greedyWorker := func() {
defer wg.Done()
var count int
for begin := time.Now(); time.Since(begin) <= runtime; {
sharedLock.Lock()
time.Sleep(3*time.Nanosecond)
sharedLock.Unlock()
count++
}
fmt.Printf("Greedy worker was able to execute %v work loops\n", count)
}
politeWorker := func() {
defer wg .Done ()
var count int
for begin := time.Now(); time.Since(begin) <= runtime; {
sharedLock.Lock()
time.Sleep(1*time.Nanosecond)
sharedLock.Unlock()
sharedLock.Lock()
time.Sleep(1*time.Nanosecond)
sharedLock.Unlock()
sharedLock.Lock()
time.Sleep(1*time.Nanosecond)
sharedLock.Unlock()
count++
}
fmt.Printf ("Polite worker was able to execute %v work loops.\n", count)
}
wg.Add(2)
go greedyWorker()
go politeWorker()
wg.Wait()输出如下:
Polite worker was able to execute 289777 work loops.
Greedy worker was able to execute 471287 work loops.贪婪的 worker 会贪婪地抢占共享锁,以完成整个工作循环,而平和的 worker 则试图只在需要时锁定。两种 worker 都做同样多的模拟工作(sleeping 时间为 3ns),但是你可以看到,在同样的时间里,贪婪的 worker 工作量几乎是平和的 worker 工作量的两倍!
假设两种 worker 都有同样大小的临界区,而不是认为贪婪的 worker 的算法更有效(或调用 Lock 和 Unlock 的时候,它们也不是缓慢的),我们得出这样的结论,贪婪的 worker 不必要地扩大其持有共享锁上的临界区,井阻止(通过饥饿)平和的 worker 的 goroutine 高效工作。
请注意,我们这里的技术用于识别饥饿:一个 metric。饥饿会为记录和取样提供一个很好的 metric。一个发现和解决饥饿的方曲是,通过记录来确定进程工作速度是否和你预期的一样高。
值得一提的是,前面的代码示例还可以作为内存访问同步的性能影响的示例。因为同步访问内存是昂贵的,所以将我们的锁扩展到临界段之外是有利的。另一方面,这样做我们将冒着饿死其他并发进程的风险。
如果使用了内存访问同步,将不得不在扭拉皮同步和细粒反同步之间找到一个平衡点。当需要对应用程序进行性能调优时,强烈建议只将内存访问同步限制在关键部分;如果同步成为性能问题,可以一直扩展范围。走另一条路妥难得多。
所以,饥饿会导致你的程序表现不佳或不正确。前面的示例演示了低效场景,但是如果你有一个非常贪婪的并发进程,以至于完全阻止另一个并发进程完成工作,那么你就会遇到一个更大的问题。
我们还应该考虑到来自于外部过程的饥饿。请记住,饥饿也可以应用于 CPU、内存、文件句柄、数据库连接:任何必须共享的资源都是饥饿的候选者。
示例:封装qsort快速排序函数
qsort 快速排序函数是 C语言的高阶函数,支持用于自定义排序比较函数,可以对任意类型的数组进行排序。本节我们尝试基于 C语言的 qsort 函数封装一个 Go语言版本的 qsort 函数。
认识 qsort 函数
qsort 快速排序函数有 <stdlib.h> 标准库提供,函数的声明如下:
void qsort(
void* base, size_t num, size_t size,
int (*cmp)(const void*, const void*)
);其中 base 参数是要排序数组的首个元素的地址,num 是数组中元素的个数,size 是数组中每个元素的大小。最关键是 cmp 比较函数,用于对数组中任意两个元素进行排序。
cmp 排序函数的两个指针参数分别是要比较的两个元素的地址,如果第一个参数对应元素大于第二个参数对应的元素将返回结果大于 0,如果两个元素相等则返回 0,如果第一个元素小于第二个元素则返回结果小于 0。
下面的代码是用 C语言的 qsort 对一个 int 类型的数组进行排序:
#include <stdio.h>
#include <stdlib.h>
#define DIM(x) (sizeof(x)/sizeof((x)[0]))
static int cmp(const void* a, const void* b) {
const int* pa = (int*)a;
const int* pb = (int*)b;
return *pa - *pb;
}
int main() {
int values[] = { 42, 8, 109, 97, 23, 25 };
int i;
qsort(values, DIM(values), sizeof(values[0]), cmp);
for(i = 0; i < DIM(values); i++) {
printf ("%d ",values[i]);
}
return 0;
}其中 DIM(values) 宏用于计算数组元素的个数, sizeof(values[0]) 用于计算数组元素的大小。cmp 是用于排序时比较两个元素大小的回调函数。为了避免对全局名字空间的污染,我们将 cmp 回调函数定义为仅当前文件内可访问的静态函数。
将 qsort 函数从 Go 包导出
为了方便 Go语言的非 CGO 用户使用 qsort 函数,我们需要将 C语言的 qsort 函数包装为一个外部可以访问的 Go函数。
用 Go语言将 qsort 函数重新包装为 qsort.Sort 函数:
package qsort
//typedef int (*qsort_cmp_func_t)(const void* a, const void* b);
import "C"
import "unsafe"
func Sort(
base unsafe.Pointer, num, size C.size_t,
cmp C.qsort_cmp_func_t,
) {
C.qsort(base, num, size, cmp)
}因为 Go语言的 CGO 语言不好直接表达 C语言的函数类型,因此在 C语言空间将比较函数类型重新定义为一个 qsort_cmp_func_t 类型。
虽然 Sort 函数已经导出了,但是对于 qsort 包之外的用户依然不能直接使用该函数——Sort 函数的参数还包含了虚拟的 C 包提供的类型。 在虚拟的 C 包下的任何名称其实都会被映射为包内的私有名字。比如 C.size_t 会被展开为 _Ctype_size_t,C.qsort_cmp_func_t 类型会被展开为 _Ctype_qsort_cmp_func_t 。
被 CGO 处理后的 Sort 函数的类型如下:
func Sort(
base unsafe.Pointer, num, size _Ctype_size_t,
cmp _Ctype_qsort_cmp_func_t,
)这样将会导致包外部用于无法构造 _Ctype_size_t 和 _Ctype_qsort_cmp_func_t 类型的参数而无法使用 Sort 函数。因此,导出的 Sort 函数的参数和返回值要避免对虚拟 C 包的依赖。
重新调整 Sort 函数的参数类型和实现如下:
/*
#include <stdlib.h>
typedef int (*qsort_cmp_func_t)(const void* a, const void* b);
*/
import "C"
import "unsafe"
type CompareFunc C.qsort_cmp_func_t
func Sort(base unsafe.Pointer, num, size int, cmp CompareFunc) {
C.qsort(base, C.size_t(num), C.size_t(size), C.qsort_cmp_func_t(cmp))
}我们将虚拟 C 包中的类型通过 Go语言类型代替,在内部调用 C 函数时重新转型为 C 函数需要的类型。因此外部用户将不再依赖 qsort 包内的虚拟 C 包。
以下代码展示了 Sort 函数的使用方式:
package main
//extern int go_qsort_compare(void* a, void* b);
import "C"
import (
"fmt"
"unsafe"
qsort "."
)
//export go_qsort_compare
func go_qsort_compare(a, b unsafe.Pointer) C.int {
pa, pb := (*C.int)(a), (*C.int)(b)
return C.int(*pa - *pb)
}
func main() {
values := []int32{42, 9, 101, 95, 27, 25}
qsort.Sort(unsafe.Pointer(&values[0]),
len(values), int(unsafe.Sizeof(values[0])),
qsort.CompareFunc(C.go_qsort_compare),
)
fmt.Println(values)
}为了使用 Sort 函数,我们需要将 Go语言的切片取首地址、元素个数、元素大小等信息作为调用参数,同时还需要提供一个 C语言规格的比较函数。其中 go_qsort_compare 是用 Go语言实现的,并导出到 C语言空间的函数,用于 qsort 排序时的比较函数。
目前已经实现了对 C语言的 qsort 初步包装,并且可以通过包的方式被其它用户使用。但是 qsort.Sort 函数已经有很多不便使用之处:用户要提供 C语言的比较函数,这对许多 Go语言用户是一个挑战。
下一步我们将继续改进 qsort 函数的包装函数,尝试通过闭包函数代替 C语言的比较函数。消除用户对 CGO 代码的直接依赖。
改进:闭包函数作为比较函数
在改进之前我们先回顾下 Go语言 sort 包自带的排序函数的接口:
func Slice(slice interface{}, less func(i, j int) bool)标准库的 sort.Slice 因为支持通过闭包函数指定比较函数,对切片的排序非常简单:
import "sort"
func main() {
values := []int32{42, 9, 101, 95, 27, 25}
sort.Slice(values, func(i, j int) bool {
return values[i] < values[j]
})
fmt.Println(values)
}我们也尝试将 C语言的 qsort 函数包装为以下格式的 Go语言函数:
package qsort
func Sort(base unsafe.Pointer, num, size int, cmp func(a, b unsafe.Pointer) int)闭包函数无法导出为 C语言函数,因此无法直接将闭包函数传入 C语言的 qsort 函数。为此我们可以用 Go 构造一个可以导出为 C语言的代理函数,然后通过一个全局变量临时保存当前的闭包比较函数。
代码如下所示:
var go_qsort_compare_info struct {
fn func(a, b unsafe.Pointer) int
sync.Mutex
}
//export _cgo_qsort_compare
func _cgo_qsort_compare(a, b unsafe.Pointer) C.int {
return C.int(go_qsort_compare_info.fn(a, b))
}其中导出的 C语言函数 _cgo_qsort_compare 是公用的 qsort 比较函数,内部通过 go_qsort_compare_info.fn 来调用当前的闭包比较函数。
新的 Sort 包装函数实现如下:
/*
#include <stdlib.h>
typedef int (*qsort_cmp_func_t)(const void* a, const void* b);
extern int _cgo_qsort_compare(void* a, void* b);
*/
import "C"
func Sort(base unsafe.Pointer, num, size int, cmp func(a, b unsafe.Pointer) int) {
go_qsort_compare_info.Lock()
defer go_qsort_compare_info.Unlock()
go_qsort_compare_info.fn = cmp
C.qsort(base, C.size_t(num), C.size_t(size),
C.qsort_cmp_func_t(C._cgo_qsort_compare),
)
}每次排序前,对全局的 go_qsort_compare_info 变量加锁,同时将当前的闭包函数保存到全局变量,然后调用 C语言的 qsort 函数。
基于新包装的函数,我们可以简化之前的排序代码:
func main() {
values := []int32{42, 9, 101, 95, 27, 25}
qsort.Sort(unsafe.Pointer(&values[0]), len(values), int(unsafe.Sizeof(values[0])),
func(a, b unsafe.Pointer) int {
pa, pb := (*int32)(a), (*int32)(b)
return int(*pa - *pb)
},
)
fmt.Println(values)
}现在排序不再需要通过 CGO 实现 C语言版本的比较函数了,可以传入 Go语言闭包函数作为比较函数。但是导入的排序函数依然依赖 unsafe 包,这是违背 Go语言编程习惯的。
改进:消除用户对 unsafe 包的依赖
前一个版本的 qsort.Sort 包装函数已经比最初的 C语言版本的 qsort 易用很多,但是依然保留了很多 C语言底层数据结构的细节。现在我们将继续改进包装函数,尝试消除对 unsafe 包的依赖,并实现一个类似标准库中 sort.Slice 的排序函数。
新的包装函数声明如下:
package qsort
func Slice(slice interface{}, less func(a, b int) bool)首先,我们将 slice 作为接口类型参数传入,这样可以适配不同的切片类型。然后切片的首个元素的地址、元素个数和元素大小可以通过 reflect 反射包从切片中获取。
为了保存必要的排序上下文信息,我们需要在全局包变量增加要排序数组的地址、元素个数和元素大小等信息,比较函数改为 less:
var go_qsort_compare_info struct {
base unsafe.Pointer
elemnum int
elemsize int
less func(a, b int) bool
sync.Mutex
}同样比较函数需要根据元素指针、排序数组的开始地址和元素的大小计算出元素对应数组的索引下标,然后根据 less 函数的比较结果返回 qsort 函数需要格式的比较结果。
//export _cgo_qsort_compare
func _cgo_qsort_compare(a, b unsafe.Pointer) C.int {
var (
// array memory is locked
base = uintptr(go_qsort_compare_info.base)
elemsize = uintptr(go_qsort_compare_info.elemsize)
)
i := int((uintptr(a) - base) / elemsize)
j := int((uintptr(b) - base) / elemsize)
switch {
case go_qsort_compare_info.less(i, j): // v[i] < v[j]
return -1
case go_qsort_compare_info.less(j, i): // v[i] > v[j]
return +1
default:
return 0
}
}新的 Slice 函数的实现如下:
func Slice(slice interface{}, less func(a, b int) bool) {
sv := reflect.ValueOf(slice)
if sv.Kind() != reflect.Slice {
panic(fmt.Sprintf("qsort called with non-slice value of type %T", slice))
}
if sv.Len() == 0 {
return
}
go_qsort_compare_info.Lock()
defer go_qsort_compare_info.Unlock()
defer func() {
go_qsort_compare_info.base = nil
go_qsort_compare_info.elemnum = 0
go_qsort_compare_info.elemsize = 0
go_qsort_compare_info.less = nil
}()
// baseMem = unsafe.Pointer(sv.Index(0).Addr().Pointer())
// baseMem maybe moved, so must saved after call C.fn
go_qsort_compare_info.base = unsafe.Pointer(sv.Index(0).Addr().Pointer())
go_qsort_compare_info.elemnum = sv.Len()
go_qsort_compare_info.elemsize = int(sv.Type().Elem().Size())
go_qsort_compare_info.less = less
C.qsort(
go_qsort_compare_info.base,
C.size_t(go_qsort_compare_info.elemnum),
C.size_t(go_qsort_compare_info.elemsize),
C.qsort_cmp_func_t(C._cgo_qsort_compare),
)
}首先需要判断传入的接口类型必须是切片类型。然后通过反射获取 qsort 函数需要的切片信息,并调用 C语言的 qsort 函数。
基于新包装的函数我们可以采用和标准库相似的方式排序切片:
import (
"fmt"
qsort "."
)
func main() {
values := []int64{42, 9, 101, 95, 27, 25}
qsort.Slice(values, func(i, j int) bool {
return values[i] < values[j]
})
fmt.Println(values)
}为了避免在排序过程中,排序数组的上下文信息 go_qsort_compare_info 被修改,我们进行了全局加锁。因此目前版本的 qsort.Slice 函数是无法并发执行的,读者可以自己尝试改进这个限制。
Go语言CSP:通信顺序进程简述
当进行和 Go语言有关讨论的时候,经常听到人们抛出 CSP 这个缩写。在某些环境下 CSP 经常被赞美成 Go语言成功的原因以及并发编程的“万能钥匙”。它让不知道 CSP 的人开始认为计算机科学已经发现了一些可以像变魔术一样的方法让编写一个并发程序像编写一个串行程序一样简单。
虽然 CSP 确实使这些变得更加简单,让程序变得更加健壮,但不幸的是它并不是一个奇迹。所以,CSP 到底是什么?为什么把大家都弄的如此兴奋?
CSP 即“Communicating Sequential Processes”(通信顺序进程),既是一个技术名词,也是介绍这种技术的论文的名字。在 1978 年,Charles Antony Richard Hoare 在 Association for Computing Machinery(一般被称作 ACM)中发表的论文。
在这篇论文里,Hoare 认为输入与输出是两个被忽略的编程原语,尤其是在并发代码中。在 Hoare 写作这篇论文的同时,关于如何架构程序的相关研究还在进行中,但是大部分的研究都是针对编写顺序代码的方能:goto 语句的使用正在被讨论,面向对象范型正在成为编程的基石。
并发操作并没有被给予过多的思考。Hoare 开始纠正这个现象,所以,关于 CSP 的这篇论文就横空出世了。
在 1978 年的论文中,CSP 仅是一个完全用来展示通信顺序进程的能力的一个简单的编程语言。事实上,他甚至在论文中写道:因此,本文介绍的概念和符号应该······不被认为适合作为一种编程语言,无论是抽象的还是具体的编程。
Hoare 深深的忧虑所展示的技术对未来的关于并发编程的研究没有任何作用,这种技术也许没有语言会真的按照他的想怯来实现。在接下来的 6 年里,关于 CSP 的想法被提炼成了一个叫做“进程微积分”的正式名称来将 CSP 的想也投入到并发编程的实践。
进程微积分是一种对并发系统进行数学化建模的方式,并且提供了代数也则来进行这些系统的变换来分析它们不同的属性,例如:并发与效率。而且正是因为 CSP 的原始论文以及从论文中进化而来的原语正是 Go语言并发模型的主要灵感,而这正是我们接下来所要聚焦的。
用来支撑他关于输入与输出需要被按照语言的原话来考虑,Hoare 的 CSP 编程语言包含用来建模输入与输出,或者说“在进程间正确通信”(这就是论文名字的由来)的原语。Hoare 将进程这个术语运用到任何包含需要输入来运行且产生其他进程将会消费的输出的逻辑片段。Hoare 可能应该使用“函数”这个词汇,而不是在他写论文时在社区中关于如何构建程序的辩论。
为了在进程之间进行通信,Hoare 创造了输入与输出的命令:! 代表发送输入到一个进程,? 代表读取一个进程的输出。每一个指令都需要指定具体是一个输出变量(从一个进程中读取一个变量的情况),还是一个目的地(将输入发送到一个进程的情况)。
有时,这两种方怯会引用相同的东西,在这种情况下,这两个过程会被认为是相对应的。换言之,一个进程的输出应该直接流向另一个进程的输入。下表给我们展示了 Hoare 的 CSP 论文申一些例子的摘录。

示例与 Go语言的 channel 的相似性是显而易见的。注意最后一个示例中 west 的输出被送到一个变量 c,然后 east 的输入也是从相同的变量中接收的。这两个过程是相同的。
在 Hoare 关于 CSP 的第一篇论文中,进程只能通过命名的源与目的进行通信。他承认这会让代码像一个函数库一样被嵌入到逻辑中,因为这段代码的消费者必须知道输入与输出的命名。他随意地提出将输入输出的名字注册成他称作“端口名”的可能性,也就是说,在并行命令的头部,需要声明名字,也就是我们大概可以认为是命名的参数与命名的返回值。
这种语言同时利用了一个所谓的守护命令,也就是 Edgar Dijkstra 在一篇之前在 1974 年所写的论文中介绍的,“Guarded commands, nondeterminacy and formal derivation of programs”。一个有守护的命令仅仅是一个带有左和右倾向的语句,由 → 来分割。
左侧服务是有运行条件的,或者是守护右侧服务,如果左侧服务运行失败,或者在一个命令执行后,返回 false 或者退出,右侧服务永远不会被执行。将这些与 Hoare 的 I/O 命令组合起来,为 Hoare 的通信过程奠定了基础,从而实现了 channel。
使用这些原语, Hoare 运行了几个示例,并演示了如何以最佳的方式支持建模通信,从而使解决问题变得更简单、更容易理解。他使用的一些符号是简短的(Perl 程序员可能不同意),并且提出的问题有非常清晰的解决方案。类似的解决方案比较长一些,但也很清晰。
经验判断 Hoare 的建议是正确的,然而,有趣的是,在 Go语言发布之前,很少有语言能够真正地为这些原语提供支持。大多数流行的语言都支持共享和内存访问同步到 CSP 的消息传递样式。
当然也有例外,但不幸的是,这些都局限于没有广泛采用的语言。Go语言是最早将 CSP 的原则纳入其核心的语言之一,并将这种并发编程风格引人到大众中。它的成功也使得其他语言尝试添加这些原语。
在 Go语言中,甚至有时共享内存在某些情况下是合适的。但是,共享内存模型很难正确地使用,特别是在大型或复杂的程序中。正是由于这个原因,并发被认为是 Go语言的优势之一,它从一开始就建立在 CSP 的原则之上,因此很容易阅读、编写和推理。
示例:聊天服务器
本节将带领大家结合咱们前面所学的知识开发一个聊天的小程序,它可以在几个用户之间相互广播文本消息。这个程序里包含 4 个 goroutine。主 goroutine 和广播(broadcaster)goroutine,每一个连接里面有一个连接处理(handleConn)goroutine 和一个客户写入(clientwriter)goroutine。
广播器(broadcaster)是关于如何使用 select 的一个规范说明,因为它需要对三种不同的消息进行响应。
如下所示,主 goroutine 的工作是监听端口,接受连接客户端的网络连接。对每一个连接,它创建一个新的 handleConn goroutine。
package main
import (
"bufio"
"fmt"
"log"
"net"
)
func main() {
listener, err := net.Listen("tcp", "localhost:8000")
if err != nil {
log.Fatal(err)
}
go broadcaster()
for {
conn, err := listener.Accept()
if err != nil {
log.Print(err)
continue
}
go handleConn(conn)
}
}下一个是广播器,它使用局部变量 clients 来记录当前连接的客户集合。每个客户唯一被记录的信息是其对外发送消息通道的 ID,下面是细节:
type client chan<- string // 对外发送消息的通道
var (
entering = make(chan client)
leaving = make(chan client)
messages = make(chan string) // 所有连接的客户端
)
func broadcaster() {
clients := make(map[client]bool) // all connected clients
for {
select {
case msg := <-messages:
// 把所有接收到的消息广播给所有客户端
// 发送消息通道
for cli := range clients {
cli <- msg
}
case cli := <-entering:
clients[cli] = true
case cli := <-leaving:
delete(clients, cli)
close(cli)
}
}
}广播者监听两个全局的通道 entering 和 leaving,通过它们通知客户的到来和离开,如果它从其中一个接收到事件,它将更新 clients 集合。如果客户离开,那么它关闭对应客户对外发送消息的通道。
广播者也监听来自 messages 通道的事件,所有的客户都将消息发送到这个通道。当广播者接收到其中一个事件时,它把消息广播给所有客户。
现在来看一下每个客户自己的 goroutine。handleConn 函数创建一个对外发送消息的新通道,然后通过 entering 通道通知广播者新客户到来。
接着,它读取客户发来的每一行文本,通过全局接收消息通道将每一行发送给广播者,发送时在每条消息前面加上发送者 ID 作为前缀。一旦从客户端读取完毕消息,handleConn 通过 leaving 通道通知客户离开,然后关闭连接。
func handleConn(conn net.Conn) {
ch := make(chan string) // 对外发送客户消息的通道
go clientWriter(conn, ch)
who := conn.RemoteAddr().String()
ch <- "You are " + who
messages <- who + " has arrived"
entering <- ch
input := bufio.NewScanner(conn)
for input.Scan() {
messages <- who + ": " + input.Text()
}
// 注意:忽略 input.Err() 中可能的错误
leaving <- ch
messages <- who + " has left"
conn.Close()
}
func clientWriter(conn net.Conn, ch <-chan string) {
for msg := range ch {
fmt.Fprintln(conn, msg) // 注意:忽略网络层面的错误
}
}另外,handleConn 函数还为每一个客户创建了写入(clientwriter)goroutine,它接收消息,广播到客户的发送消息通道中,然后将它们写到客户的网络连接中。客户写入者的循环在广播者收到 leaving 通知并且关闭客户的发送消息通道后终止。
下面的信息展示了同一个机器上的一个服务器和两个客户端,它们使用 netcat 程序来聊天:
$ go build gopl.io/ch8/main
$ go build gopl.io/ch8/netcat
$ ./main &
$ ./netcat
You are 127.0.0.1:64208 $ ./netcat
127.0.0.1:64211 has arrived You are 127.0.0.1:64211
Hi!
127.0.0.1:64208: Hi! 127.0.0.1:64208: Hi!
Hi yourself.
127.0.0.1:64211: Hi yourself. 127.0.0.1:64211: Hi yourself.
^C
127.0.0.1:64208 has left
$ ./netcat
You are 127.0.0.1:64216 127.0.0.1:64216 has arrived
Welcome.
127.0.0.1:64211: Welcome. 127.0.0.1:64211: Welcome.
^C
127.0.0.1:64211 has leftnetcat 的完整代码如下所示:
// netcat.go
// netcat是一个简单的TCP服务器读/写客户端
package main
import (
"io"
"log"
"net"
"os"
)
func main() {
conn, err := net.Dial("tcp", "localhost:8000")
if err != nil {
log.Fatal(err)
}
done := make(chan struct{})
go func() {
io.Copy(os.Stdout, conn) // 注意:忽略错误
log.Println("done")
done <- struct{}{} // 向主Goroutine发出信号
}()
mustCopy(conn, os.Stdin)
conn.Close()
<-done // 等待后台goroutine完成
}
func mustCopy(dst io.Writer, src io.Reader) {
if _, err := io.Copy(dst, src); err != nil {
log.Fatal(err)
}
}当有 n 个客户 session 在连接的时候,程序并发运行着 2n+2 个相互通信的 goroutine,它不需要隐式的加锁操作。clients map 限制在广播器这一个 goroutine 中被访问,所以不会并发访问它。唯一被多个 goroutine 共享的变量是通道以及 net.Conn 的实例,它们又都是并发安全的。
09. Go 语言并发的更多相关文章
- MIT 6.824学习笔记3 Go语言并发解析
之前看过一个go语言并发的介绍:https://www.cnblogs.com/pdev/p/10936485.html 但这个太简略啦.下面看点深入的 还记得https://www.cnblog ...
- Go语言并发编程示例 分享(含有源代码)
GO语言并发示例分享: ppt http://files.cnblogs.com/files/yuhan-TB/GO%E8%AF%AD%E8%A8%80.pptx 代码, 实际就是<<Go ...
- Go语言并发与并行学习笔记(三)
转:http://blog.csdn.net/kjfcpua/article/details/18265475 Go语言并发的设计模式和应用场景 以下设计模式和应用场景来自Google IO上的关于G ...
- (转)Go语言并发模型:使用 context
转载自:https://segmentfault.com/a/1190000006744213 context golang 简介 在 Go http包的Server中,每一个请求在都有一个对应的 g ...
- Go语言 并发编程
Go语言 并发编程 作者:Eric 微信:loveoracle11g 1.创建goroutine // 并行 是两个队列同时使用两台咖啡机 // 并发 是两个队列交替使用一台咖啡机 package m ...
- 融云开发漫谈:你是否了解Go语言并发编程的第一要义?
2007年诞生的Go语言,凭借其近C的执行性能和近解析型语言的开发效率,以及近乎完美的编译速度,席卷全球.Go语言相关书籍也如雨后春笋般涌现,前不久,一本名为<Go语言并发之道>的书籍被翻 ...
- go语言之进阶篇并行和并发的区别与go语言并发优势
1.并行和并发的概念 并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行. 并发(concurrency):指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在 ...
- Go语言并发
Go语言并发机制初探 Go 语言相比Java等一个很大的优势就是可以方便地编写并发程序.Go 语言内置了 goroutine 机制,使用goroutine可以快速地开发并发程序, 更好的利用多核处 ...
- Go语言-并发模式-资源池实例(pool)
Go语言并发模式 利用goroutine和channel进行go的并发模式,实现一个资源池实例(<Go语言实战>书中实例稍作修改) 资源池可以存储一定数量的资源,用户程序从资源池获取资源进 ...
随机推荐
- CS5642-V3与OV5642-FPC通过icamera测试方向的对比图
有朋友会有如此的疑问:CS5642-V3与OV5642-FPC在采集板上通过icamera测试图像方向是一样吗?通过本文您会找到答案 测试:CS5642-V3与OV5642-FPC的管脚在上 以下 ...
- windows10查看电脑已经保存的wifi密码
1,打开windows的命令窗口,输入 netsh wlan show profiles,如下图,这个命令仅仅只是查看一下电脑保存的所有的wifi名字 2,需要查看密码的话,则需要输入这个命令, ...
- CCF-CSP题解 201604-4 游戏
bfs #include <bits/stdc++.h> const int maxn = 100; using namespace std; int n, m, t; bool hasD ...
- 《Java基础知识》Java正则表达式
正则表达式定义了字符串的模式. 正则表达式可以用来搜索.编辑或处理文本. 正则表达式并不仅限于某一种语言,但是在每种语言中有细微的差别. 正则表达式实例 一个字符串其实就是一个简单的正则表达式,例如 ...
- 【转载】Opening Robot Framework log failed
问题: 两种方法可以解决: 1.临时解决方案 jenkins系统管理—>运行命令行,在文本里输入 System.setProperty("hudson.model.DirectoryB ...
- STT-MRMA技术优点
到目前为止,设计人员可以使用的存储技术是易变的,这意味着在断电后,存储器中的数据内容会丢失.但是,随着Everspin Technologies推出256Mb STT-MRAM,系统现在可以拥有像DR ...
- unittest---unittest封装方法
前面我们写了一个关于查询歌曲的接口测试,但是代码重复性比较大,进行一次简单的优化 封装方法 在编写自动化脚本的时候,都要求代码简介,上一篇unittest---unittest断言中代码重复性比较多, ...
- cinder安装与配置
cinder是openstack中提供块存储服务的组件,主要是为虚拟机实例提供虚拟磁盘. 通过某种协议(SAS,SCSI,SAN,iSCSI等)挂接裸硬盘,然后分区.格式化创建的文件,或者直接使用裸硬 ...
- 查看python版本多少位的
正常我们在cmd终端输入python之后,如果有安装python,就会在回车之后出来关于你安装的python版本信息,几版本,多少位的,但是还有一种,像我这样只显示了python版本是3.7.5,并没 ...
- Vue 04
目录 创建Vue项目 Vue项目环境搭建 Vue项目创建 pycharm配置并启动vue项目 vue项目目录结构分析 项目生命周期 添加组件-路由映射关系 文件式组件结构 配置全局css样式 子组件的 ...