一条简单的更新语句,MySQL是如何加锁的?
看如下一条sql语句:
# table T (id int, name varchar())
delete from T where id = ;
MySQL在执行的过程中,是如何加锁呢?
在看下面这条语句:
select * from T where id = 10;
那这条语句呢?其实这其中包含太多知识点了。要回答这两个问题,首先需要了解一些知识。
相关知识介绍
多版本并发控制
在MySQL默认存储引擎InnoDB中,实现的是基于多版本的并发控制协议——MVCC(Multi-Version Concurrency Control)(注:与MVVC相对的,是基于锁的并发控制,Lock-Based Concurrency Control)。其中MVCC最大的好处是:读不加锁,读写不冲突。在读多写少的OLTP应用中,读写不冲突是非常重要的,极大的提高了系统的并发性能,在现阶段,几乎所有的RDBMS,都支持MVCC。其实,MVCC就一句话总结:同一份数据临时保存多个版本的一种方式,进而实现并发控制。
当前读和快照读
在MVCC并发控制中,读操作可以分为两类:快照读与当前读。
快照读(简单的select操作):读取的是记录中的可见版本(可能是历史版本),不用加锁。这你就知道第二个问题的答案了吧。
当前读(特殊的select操作、insert、delete和update):读取的是记录中最新版本,并且当前读返回的记录都会加上锁,这样保证了了其他事务不会再并发修改这条记录。
聚集索引
也叫做聚簇索引。在InnoDB中,数据的组织方式就是聚簇索引:完整的记录,储存在主键索引中,通过主键索引,就可以获取记录中所有的列。
最左前缀原则
也就是最左优先,这条原则针对的是组合索引和前缀索引,理解:
1、在MySQL中,进行条件过滤时,是按照向右匹配直到遇到范围查询(>,<,between,like)就停止匹配,比如说a = 1 and b = 2 and c > 3 and d = 4 如果建立(a, b, c, d)顺序的索引,d是用不到索引的,如果建立(a, b, d, c)索引就都会用上,其中a,b,d的顺序可以任意调整。
2、= 和 in 可以乱序,比如 a = 1 and b = 2 and c = 3 建立(a, b, c)索引可以任意顺序,MySQL的查询优化器会优化索引可以识别的形式。
两阶段锁
传统的RDMS加锁的一个原则,就是2PL(Two-Phase Locking,二阶段锁)。也就是说锁操作分为两个阶段:加锁阶段和解锁阶段,并且保证加锁阶段和解锁阶段不想交。也就是说在一个事务中,不管有多少条增删改,都是在加锁阶段加锁,在 commit 后,进入解锁阶段,才会全部解锁。
隔离级别
MySQL/InnoDB中,定义了四种隔离级别:
Read Uncommitted:可以读取未提交记录。此隔离级别不会使用。
Read Committed(RC):针对当前读,RC隔离级别保证了对读取到的记录加锁(记录锁),存在幻读现象。
Repeatable Read(RR):针对当前读,RR隔离级别保证对读取到的记录加锁(记录锁),同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入(间隙锁),不存在幻读现象。
Serializable:从MVCC并发控制退化为基于锁的并发控制。不区别快照读和当前读,所有的读操作都是当前读,读加读锁(S锁),写加写锁(X锁)。在该隔离级别下,读写冲突,因此并发性能急剧下降,在MySQL/InnoDB中不建议使用。
Gap锁和Next-Key锁
在InnoDB中完整行锁包含三部分:
记录锁(Record Lock):记录锁锁定索引中的一条记录。
间隙锁(Gap Lock):间隙锁要么锁住索引记录中间的值,要么锁住第一个索引记录前面的值或最后一个索引记录后面的值。
Next-Key Lock:Next-Key锁时索引记录上的记录锁和在记录之前的间隙锁的组合。
进行分析
了解完以上的小知识点,我们开始分析第一个问题。当看到这个问题的时候,你可能会毫不犹豫的说,加写锁啊。这答案也错也对,因为已知条件太少。那么有那些需要已知的前提条件呢?
- 前提一:id列是不是主键?
- 前提二:当前系统的隔离级别是什么?
- 前提三:id列如果不是主键,那么id列上有没有索引呢?
- 前提四:id列上如果有二级索引,那么是唯一索引吗?
- 前提五:SQL执行计划是什么?索引扫描?还是全表扫描
根据上面的前提条件,可以有九种组合,当然还没有列举完全。
- id列是主键,RC隔离级别
- id列是二级唯一索引,RC隔离级别
- id列是二级不唯一索引,RC隔离级别
- id列上没有索引,RC隔离级别
- d列是主键,RR隔离级别
- id列是二级唯一索引,RR隔离级别
- id列是二级不唯一索引,RR隔离级别
- id列上没有索引,RR隔离级别
组合一:id主键 + RC
这个组合是分析最简单的,到执行该语句时,只需要将主键id = 10的记录加上X锁。如下图所示:
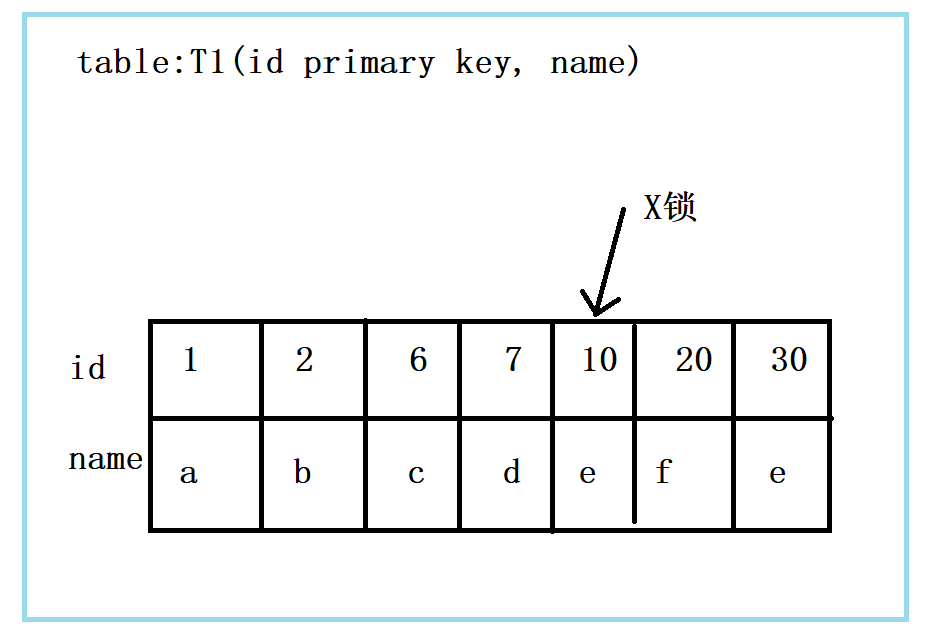
结论:id是主键是,此SQL语句只需要在id = 10这条记录上加上X锁即可。
组合二:id唯一索引 + RC
这个组合,id不是主键,而是一个Unique的二级索引键值。在RC隔离级别下,是怎么加锁的呢?看下图:

由于id是Unique索引,因此delete语句会选择走id列的索引进行where条件过滤,在找到id = 10的记录后,首先会将Unique索引上的id = 10的记录加上X锁,同时,会根据读取到的name列,回到主键索引(聚簇索引),然后将聚簇索引上的name = 'e' 对应的主键索引项加X锁。
结论:若id列是Unique列,其上有Unique索引,那么SQL需要加两个X锁,一个对应于id Unique索引上的id = 10的记录,另一把锁对应于聚簇索引上的(name = 'e', id = 10)的记录。
组合三:id不唯一索引+RC
该组合中,id列不在唯一,而是个普通索引,那么当执行sql语句时,MySQL又是如何加锁呢?看下图:
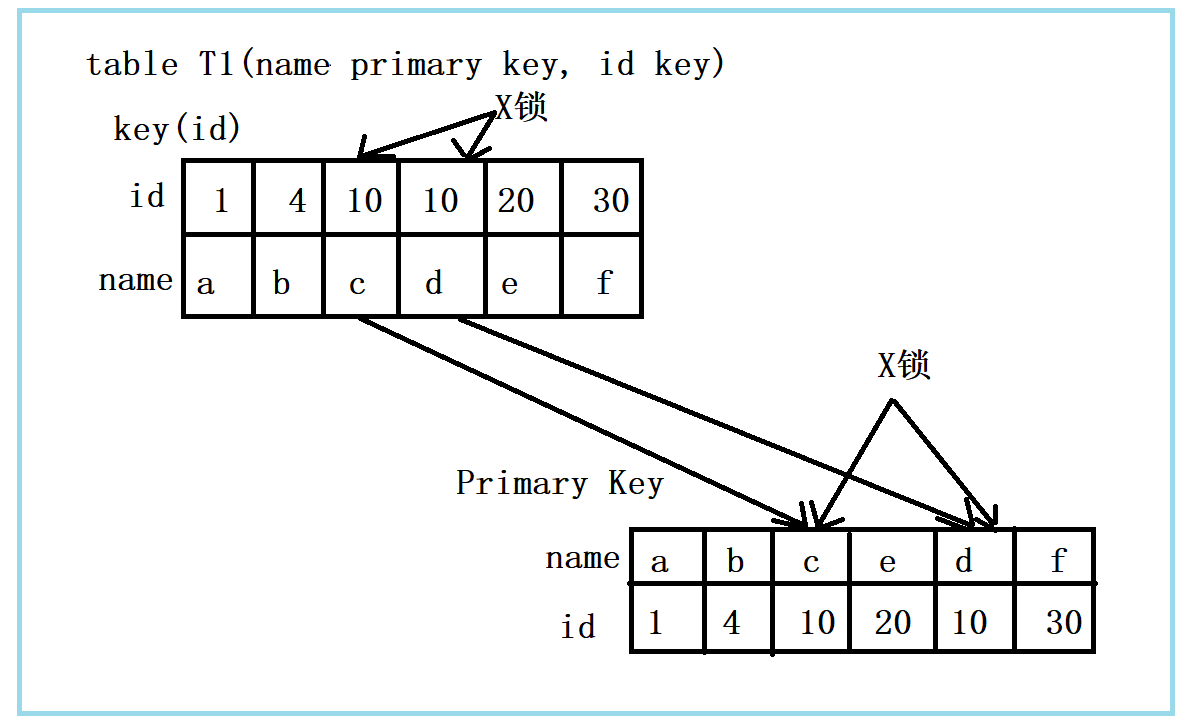
由上图可以看出,首先,id列索引上,满足id = 10查询的记录,均加上X锁。同时,这些记录对应的主键索引上的记录也加上X锁。与组合er的唯一区别,组合二最多只有一个满足条件的记录,而在组合三中会将所有满足条件的记录全部加上锁。
结论:若id列上有非唯一索引,那么对应的所有满足SQL查询条件的记录,都会加上锁。同时,这些记录在主键索引上也会加上锁。
组合四:id无索引+RC
相对于前面的组合,该组合相对特殊,因为id列上无索引,所以在 where id = 10 这个查询条件下,没法通过索引来过滤,因此只能全表扫描做过滤。对于该组合,MySQL又会进行怎样的加锁呢?看下图:
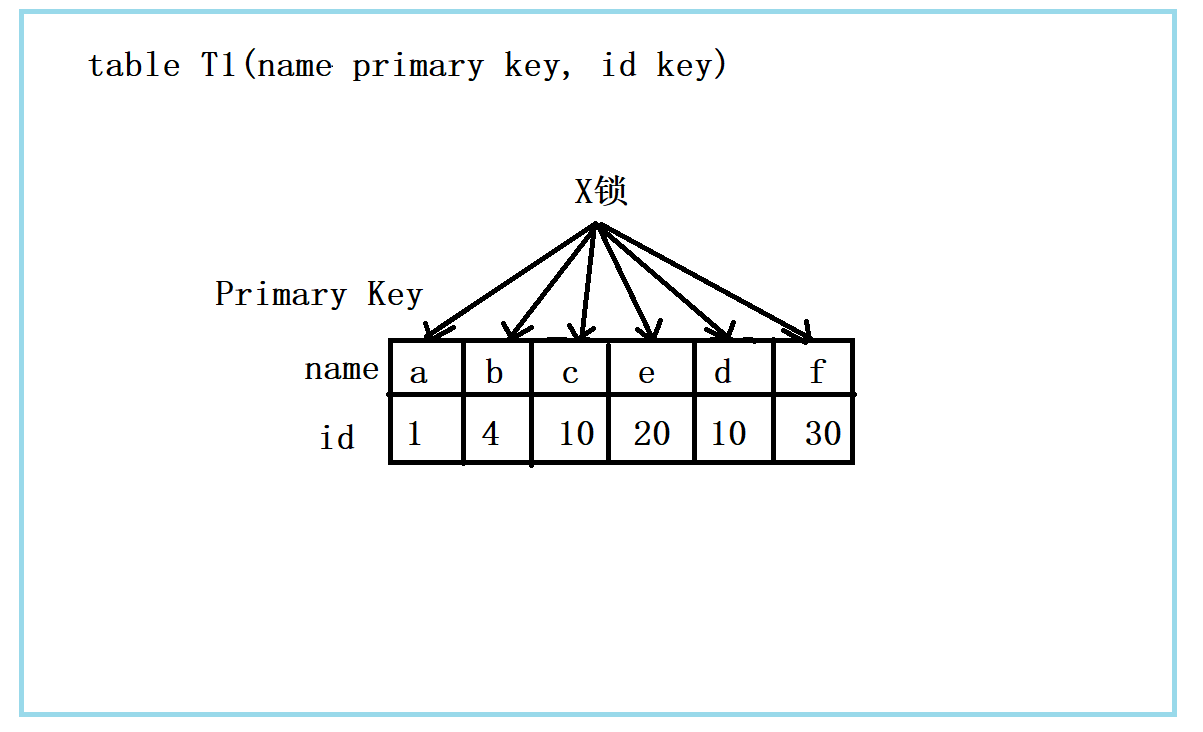
由于id列上无索引,因此只能走聚簇索引,进行全表扫描。由图可以看出满足条件的记录只有两条,但是,聚簇索引上的记录都会加上X锁。但在实际操作中,MySQL进行了改进,在进行过滤条件时,发现不满足条件后,会调用 unlock_row 方法,把不满足条件的记录放锁(违背了2PL原则)。这样做,保证了最后满足条件的记录加上锁,但是每条记录的加锁操作是不能省略的。
结论:若id列上没有索引,MySQL会走聚簇索引进行全表扫描过滤。由于是在MySQl Server层面进行的。因此每条记录无论是否满足条件,都会加上X锁,但是,为了效率考虑,MySQL在这方面进行了改进,在扫描过程中,若记录不满足过滤条件,会进行解锁操作。同时优化违背了2PL原则。
组合五:id主键+RR
该组合为id是主键,Repeatable Read隔离级别,针对于上述的SQL语句,加锁过程和组合一(id主键+RC)一致。
组合六:id唯一索引+RR
该组合与组合二的加锁过程一致。
组合七:id不唯一索引+RR
在组合一到组合四中,隔离级别是Read Committed下,会出现幻读情况,但是在该组合Repeatable Read级别下,不会出现幻读情况,这是怎么回事呢?而MySQL又是如何给上述语句加锁呢?看下图:
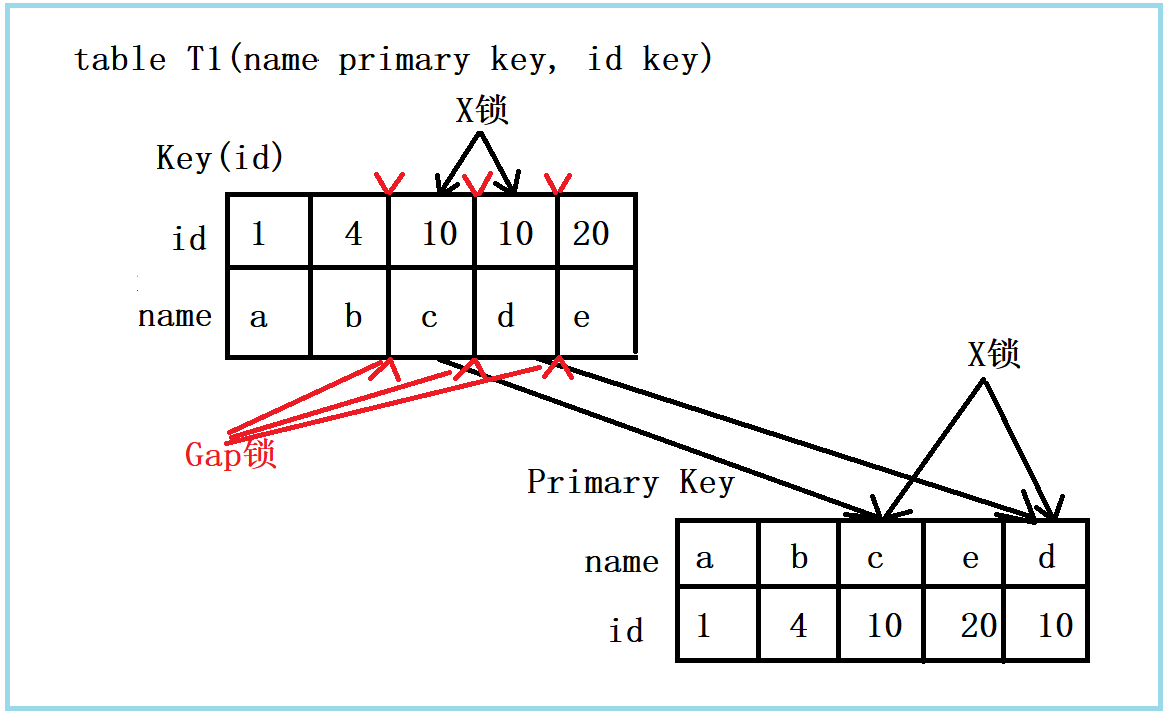
该组合和组合三看起来很相似,但差别很大,在改组合中加入了一个间隙锁(Gap锁)。这个Gap锁就是相对于RC级别下,RR级别下不会出现幻读情况的关键。实质上,Gap锁不是针对于记录本身的,而是记录之间的Gap。所谓幻读,就是同一事务下,连续进行多次当前读,且读取一个范围内的记录(包括直接查询所有记录结果或者做聚合统计), 发现结果不一致(标准档案一般指记录增多, 记录的减少应该也算是幻读)。
那么该如何解决这个问题呢?如何保证多次当前读返回一致的记录,那么就需要在多个当前读之间,其他事务不会插入新的满足条件的记录并提交。为了实现该结果,Gap锁就应运而生。
如图所示,有些位置可以插入新的满足条件的记录,考虑到B+树的有序性,满足条件的记录一定是具有连续性的。因此会在 [4, b], [10, c], [10, d], [20, e] 之间加上Gap锁。
Insert操作时,如insert(10, aa),首先定位到 [4, b], [10, c]间,然后插入在插入之前,会检查该Gap是否加锁了,如果被锁上了,则Insert不能加入记录。因此通过第一次当前读,会把满足条件的记录加上X锁,还会加上三把Gap锁,将可能插入满足条件记录的3个Gap锁上,保证后续的Insert不能插入新的满足 id = 10 的记录,也就解决了幻读问题。
而在组合五,组合六中,同样是RR级别,但是不用加上Gap锁,在组合五中id是主键,组合六中id是Unique键,都能保证唯一性。一个等值查询,最多只能返回一条满足条件的记录,而且新的相同取值的记录是无法插入的。
结论:在RR隔离级别下,id列上有非唯一索引,对于上述的SQL语句;首先,通过id索引定位到第一条满足条件的记录,给记录加上X锁,并且给Gap加上Gap锁,然后在主键聚簇索引上满足相同条件的记录加上X锁,然后返回;之后读取下一条记录重复进行。直至第一条出现不满足条件的记录,此时,不需要给记录加上X锁,但是需要给Gap加上Gap锁吗,最后返回结果。
组合八:id无索引+RR
该组合中,id列上无索引,只能进行全表扫描,那么该如何加锁,看下图:
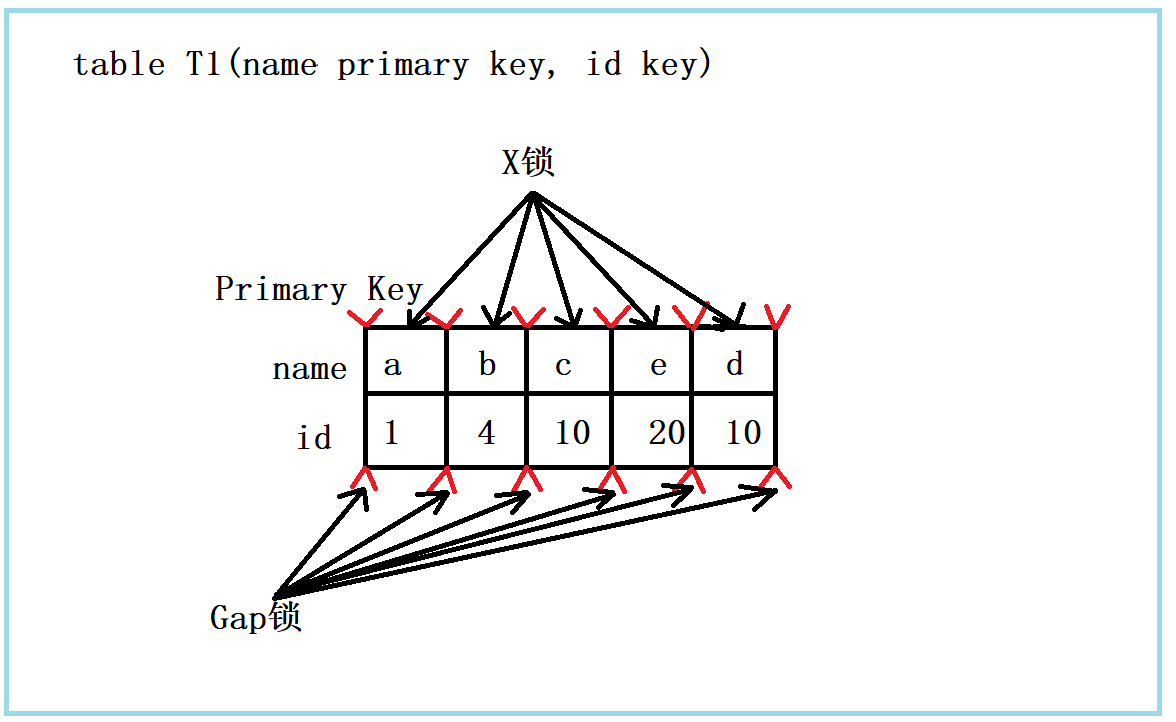
如图,可以看出这是一个很恐怖的事情,全表每条记录要加X锁,每个Gap加上Gap锁,如果表上存在大量数据时,又是什么情景呢?这种情况下,这个表,除了不加锁的快照读,其他任何加锁的并发SQL,均不能执行,不能更新,删除,插入,这样,全表锁死。
当然,和组合四一样,MySQL进行了优化,就是semi-consistent read。semi-consistent read开启的情况下,对于不满足条件的记录,MySQL会提前放锁,同时Gap锁也会释放。而semi-consistent read是如何触发:要么在Read Committed隔离级别下;要么在Repeatable Read隔离级别下,设置了 innodb_locks_unsafe_for_binlog 参数。
结论:在Repeatable Read隔离级别下,如果进行全表扫描的当前读,那么会锁上表上的所有记录,并且所有的Gap加上Gap锁,杜绝所有的 delete/update/insert 操作。当然在MySQL中,可以触发 semi-consistent read来缓解锁开销与并发影响,但是semi-consistent read本身也会带来其他的问题,不建议使用。
组合九:Serializable
在最后组合中,对于上诉的删除SQL语句,加锁过程和组合八一致。但是,对于查询语句(比如select * from T1 where id = 10)来说,在RC,RR隔离级别下,都是快照读,不加锁。在Serializable隔离级别下,无论是查询语句也会加锁,也就是说快照读不存在了,MVCC降级为Lock-Based CC。
结论:在MySQL/InnoDB中,所谓的读不加锁,并不适用于所有的情况,而是和隔离级别有关。在Serializable隔离级别下,所有的操作都会加锁。
一条简单的删除语句加锁情况也就分析完成了,但是学习不止于此,还在继续,对于复杂SQL语句又是如何加锁的呢?MySQL中的索引的分析又是怎样的呢?性能分析、性能优化这些又是怎么呢?请看后续。
一条简单的更新语句,MySQL是如何加锁的?的更多相关文章
- 2 日志系统:一条sql更新语句是如何执行的?
2 日志系统:一条sql更新语句是如何执行的? 前面了解了一个查询语句的执行流程,并介绍了执行过程中涉及的处理模块,一条查询语句的执行过程一般是经过连接器.分析器.优化器.执行器等功能模块,最后达到e ...
- mysql实战45讲读书笔记(二) 一条SQL更新语句是如何执行的 极客时间
前面我们系统了解了一个查询语句的执行流程,并介绍了执行过程中涉及的处理模块.相信你还记得,一条查询语句的执行过程一般是经过连接器.分析器.优化器.执行器等功能模块,最后到达存储引擎. 那么,一条更新语 ...
- 《Mysql 一条 SQL 更新语句是如何执行的?(Redo log)》
一:更新流程 - 对于更新来说,也同样会根据 SQL 的执行流程进行. - - 连接器 - 连接数据库,具体的不做赘述. - 查询缓存 - 在一个表上有更新的时候,跟这个表有关的查询缓存会失效. - ...
- MySQL中一条更新语句是如何执行的
1.创建表的语句和更新的语句 这个表的创建语句,这个表有一个主键ID和一个整型字段c: mysql> create table T(ID int primary key, c int); 如果要 ...
- MySQL:一条更新语句是如何执行的
目录 引言 更新流程图 更新流程说明 第一步:更新数据 数据页内存 Change Buffer 第二步:缓存日志内容 redo log buffer binlog cache 第三步:日志写入磁盘 两 ...
- 【MySQL 读书笔记】当我们在执行更新语句的时候我们在做什么
该篇其实重点涉及两个日志的使用和处理. 一个是 server 层的 binlog 一个是服务器层的 redolog. 首先还是根据主线来介绍当我们在执行更新语句的时候我们在做什么 Redo Log M ...
- 日志系统:一条sql更新语句是如何执行的?--Mysql45讲笔记记录 打卡day2
下面是一个表的创建语句,这个表有一个主键id和一个整型字段c: create table t(id int primary key,c int); 如果要将 id = 2 这一行的值加 1,sql语句 ...
- 02 | 日志系统:一条SQL更新语句是如何执行的?
前面我们系统了解了一个查询语句的执行流程,并介绍了执行过程中涉及的处理模块.相信你还记得,一条查询语句的执行过程一般是经过连接器.分析器.优化器.执行器等功能模块,最后到达存储引擎. 那么,一条更新语 ...
- MySQL笔记(6)-- SQL更新语句日志系统流程
一.背景 在上一篇[MySQL笔记(5)-- SQL执行流程,MySQL体系结构]中讲述了select查询语句在MySQL体系中的运行流程,从连接器开始,到分析器.优化器.执行器等,最后到达存储引擎. ...
随机推荐
- LightOJ1284 Lights inside 3D Grid (概率DP)
You are given a 3D grid, which has dimensions X, Y and Z. Each of the X x Y x Z cells contains a lig ...
- 小M的魔术表演
Description 小M听说会变魔术的男生最能吸引女生注意啦~所以小M费了九牛二虎之力终于学会了一个魔术:首先在桌面上放N张纸片,每张纸片上都写有一个数字.小M每次请女生给出一个数字x,然后划定任 ...
- ARTS-S anaconda常用命令
建新的环境 conda create --name py36 python=3.6 显示所有环境 conda info --envs 一键安装 wget https://repo.anaconda.c ...
- Dubbo一致性哈希负载均衡的源码和Bug,了解一下?
本文是对于Dubbo负载均衡策略之一的一致性哈希负载均衡的详细分析.对源码逐行解读.根据实际运行结果,配以丰富的图片,可能是东半球讲一致性哈希算法在Dubbo中的实现最详细的文章了. 文中所示源码,没 ...
- 【HTTP】402- 深入理解http2.0协议,看这篇就够了!
本文字数:3825字 预计阅读时间:20分钟 导读 http2.0是一种安全高效的下一代http传输协议.安全是因为http2.0建立在https协议的基础上,高效是因为它是通过二进制分帧来进行数据传 ...
- 【MySQL】ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
问题现象: ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES) 拒绝访问root用户 ...
- VS编译命令
一.前言 由于公司要求项目需要走CI构建平台,抛弃掉之前的人工编译打包方式,所以需要调研一下项目怎么通过命令行编译出产物. 二.准备工作 在构建机器上安装vs(本文示例为vs2017) 将代码上传版本 ...
- Kubernetes基本概念和术语之《Master和Node》
Kubernetes中的大部分概念如Node.Pod.Replication Controller.Service等都可以看作一种“资源对象”,几乎所有的资源对象都可以通过Kubernetes提供的k ...
- ACM-ICPC 2018 徐州赛区网络预赛 H. Ryuji doesn't want to study (线段树)
Ryuji is not a good student, and he doesn't want to study. But there are n books he should learn, ea ...
- 聊一聊JS输出为[object,object]是怎么回事
JS输出为[object object] 今天在学习ES6中的 Symbol 数据类型时,在写demo时控制台输出为 Symbol[object object] ,当时有点疑惑,查阅了相关资料后搞清楚 ...