MapReduce与Yarn 的详细工作流程分析
MapReduce详细工作流程之Map阶段
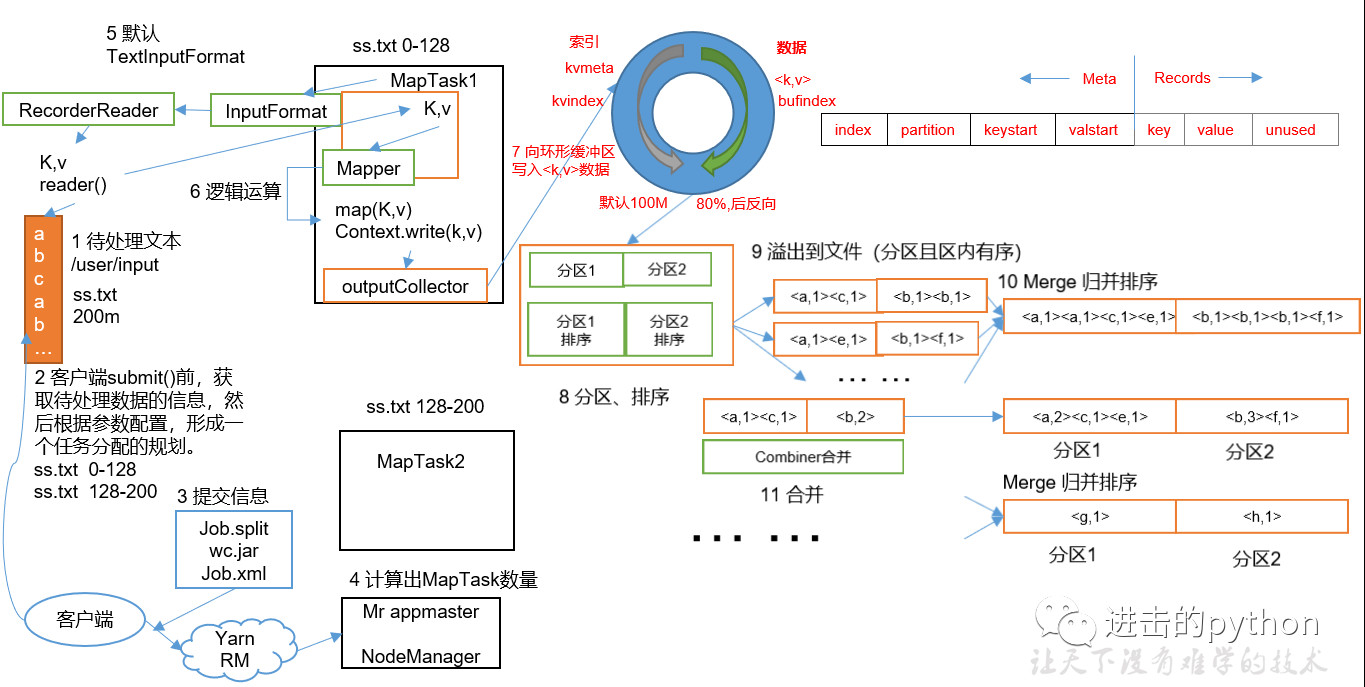
如上图所示
- 首先有一个200M的待处理文件
- 切片:在客户端提交之前,根据参数配置,进行任务规划,将文件按128M每块进行切片
- 提交:提交可以提交到本地工作环境或者Yarn工作环境,本地只需要提交切片信息和xml配置文件,Yarn环境还需要提交jar包;本地环境一般只作为测试用
- 提交时会将每个任务封装为一个job交给Yarn来处理(详细见后边的Yarn工作流程介绍),计算出MapTask数量(等于切片数量),每个MapTask并行执行
- MapTask中执行Mapper的map方法,此方法需要k和v作为输入参数,所以会首先获取kv值;
- 首先调用InputFormat方法,默认为TextInputFormat方法,在此方法调用createRecoderReader方法,将每个块文件封装为k,v键值对,传递给map方法
- map方法首先进行一系列的逻辑操作,执行完成后最后进行写操作
- map方法如果直接写给reduce的话,相当于直接操作磁盘,太多的IO操作,使得效率太低,所以在map和reduce中间还有一个shuffle操作
- map处理完成相关的逻辑操作之后,首先通过outputCollector向环形缓冲区写入数据,环形缓冲区主要两部分,一部分写入文件的元数据信息,另一部分写入文件的真实内容
- 环形缓冲区的默认大小是100M,当缓冲的容量达到默认大小的80%时,进行反向溢写
- 在溢写之前会将缓冲区的数据按照指定的分区规则进行分区和排序,之所以反向溢写是因为这样就可以边接收数据边往磁盘溢写数据
- 在分区和排序之后,溢写到磁盘,可能发生多次溢写,溢写到多个文件
- 对所有溢写到磁盘的文件进行归并排序
- 在9到10步之间还可以有一个Combine合并操作,意义是对每个MapTask的输出进行局部汇总,以减少网络传输量
- Map阶段的进程数比Reduce阶段要多,所以放在Map阶段处理效率更高
- Map阶段合并之后,传递给Reduce的数据就会少很多
- 但是Combiner能够应用的前提是不能影响最终的业务逻辑,而且Combiner的输出kv要和Reduce的输入kv类型对应起来
整个MapTask分为Read阶段,Map阶段,Collect阶段,溢写(spill)阶段和combine阶段
- Read阶段:MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value
- Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value
- Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中
- Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作
MapReduce详细工作流程之Reduce阶段
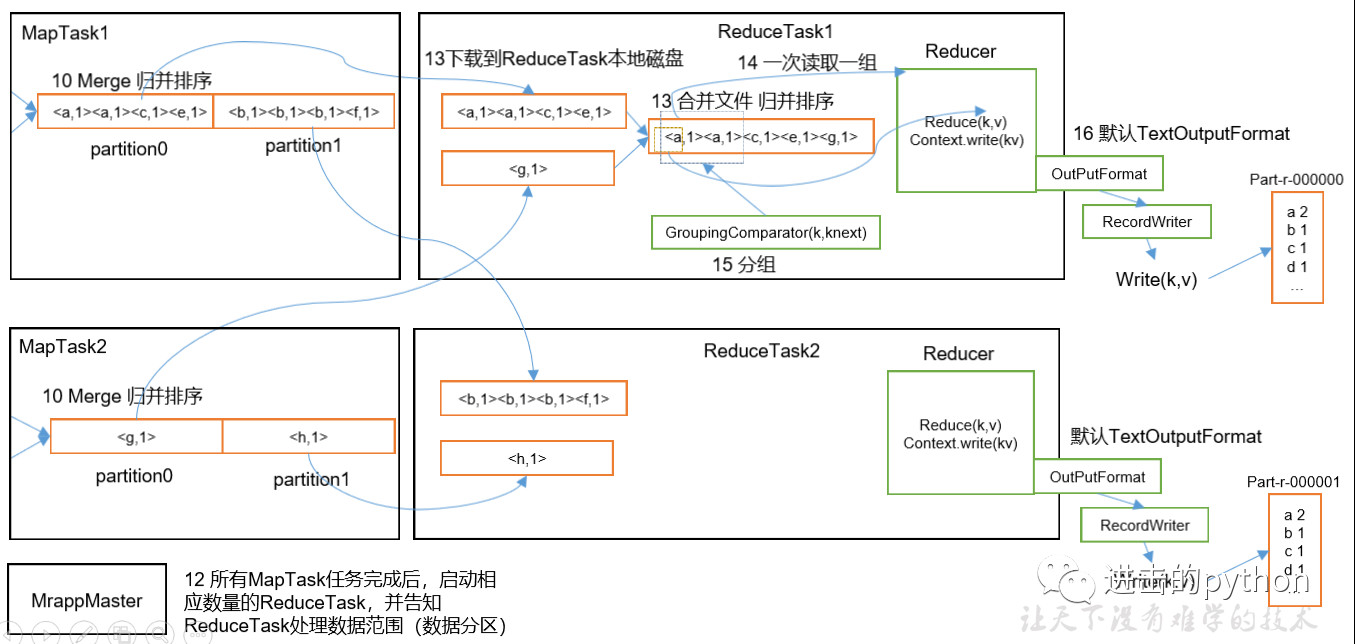
如上图所示
- 所有的MapTask任务完成后,启动相应数量的ReduceTask(和分区数量相同),并告知ReduceTask处理数据的范围
- ReduceTask会将MapTask处理完的数据拷贝一份到磁盘中,并合并文件和归并排序
- 最后将数据传给reduce进行处理,一次读取一组数据
- 最后通过OutputFormat输出
整个ReduceTask分为Copy阶段,Merge阶段,Sort阶段(Merge和Sort可以合并为一个),Reduce阶段。
- Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中
- Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多
- Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可
- Reduce阶段:reduce()函数将计算结果写到HDFS上
Shuffle机制
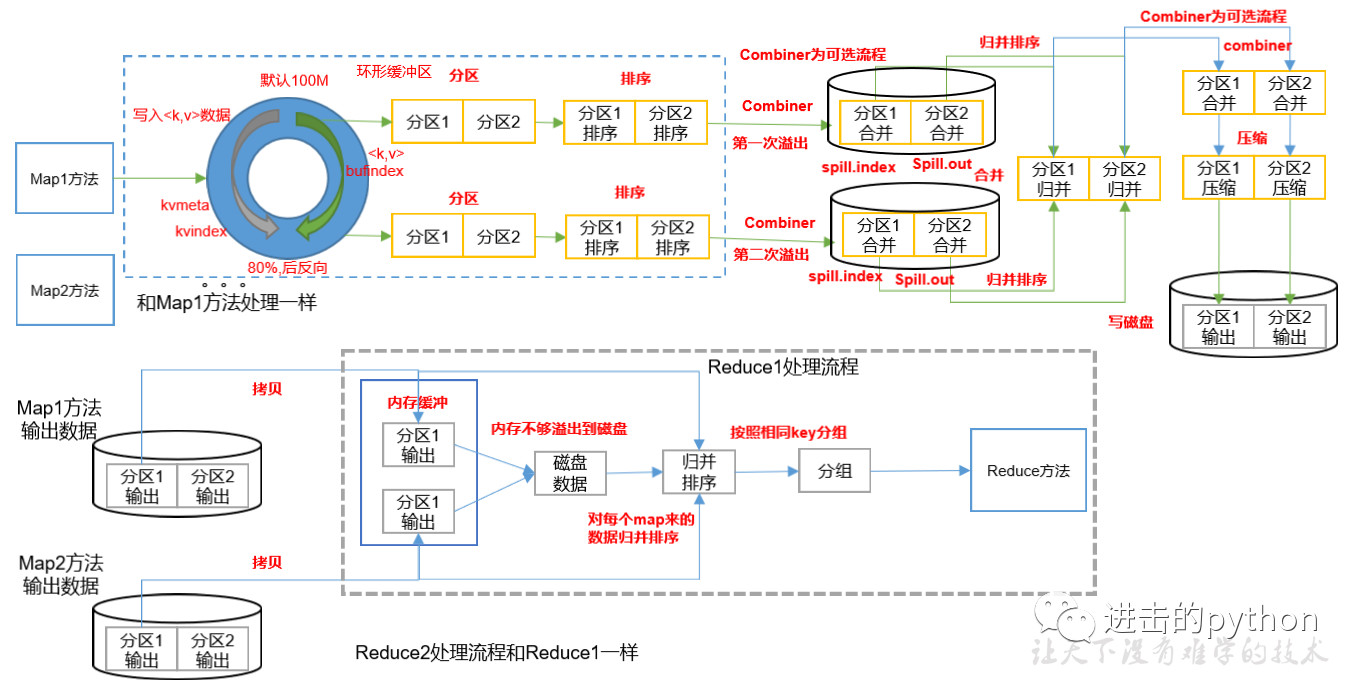
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。shuffle流程详解如下:
- MapTask收集map()方法输出的kv对,放到环形缓冲区中
- 从环形缓冲区不断溢出到本地磁盘文件,可能会溢出多个文件
- 多个溢出文件会被合并成大的溢出文件
- 在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
- ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
- ReduceTask将取到的来自同一个分区不同MapTask的结果文件进行归并排序
- 合并成大文件后,shuffle过程也就结束了,进入reduce方法
Yarn工作机制
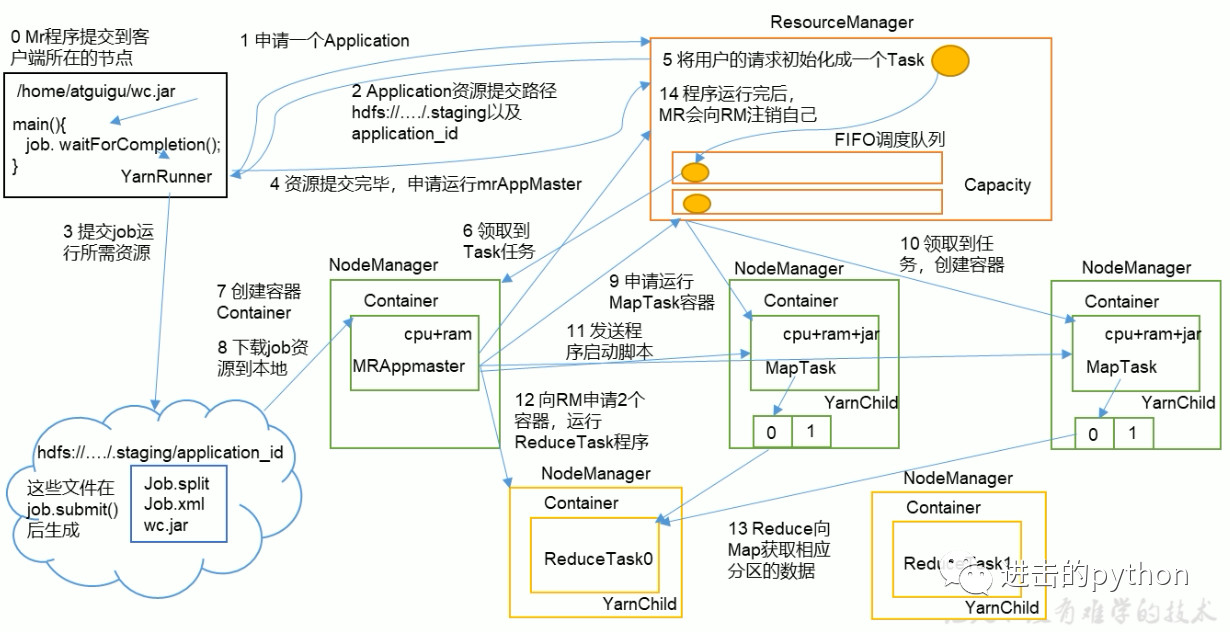
job提交全过程
- MR程序提交到客户端所在的节点,YarnRunner向ResourceManager申请一个Application
- RM将该Application的资源路径和作业id返回给YarnRunner
- YarnRunner将运行job所需资源提交到HDFS上
- 程序资源提交完毕后,申请运行mrAppMaster
- RM将用户的请求初始化成一个Task
- 其中一个NodeManager领取到Task任务
- 该NodeManager创建容器Container,并产生MRAppmaster
- Container从HDFS上拷贝资源到本地
- MRAppmaster向RM 申请运行MapTask资源
- RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器
- MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序
- MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask
- ReduceTask向MapTask获取相应分区的数据
- 程序运行完毕后,MR会向RM申请注销自己
进度和状态更新:
YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户
作业完成:
除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查
欢迎关注下方公众号,获取更多文章信息

MapReduce与Yarn 的详细工作流程分析的更多相关文章
- MapRedue详细工作流程
MapRedue详细工作流程 简述 (1)客户端submit之前获取待处理的数据信息,根据参数配置,形成一个任务分配的规划. (2)提交切片信息到YARN(split.xml,job.split,wc ...
- 第2章 rsync算法原理和工作流程分析
本文通过示例详细分析rsync算法原理和rsync的工作流程,是对rsync官方技术报告和官方推荐文章的解释. 以下是本文的姊妹篇: 1.rsync(一):基本命令和用法 2.rsync(二):ino ...
- rsync算法原理和工作流程分析
本文通过示例详细分析rsync算法原理和rsync的工作流程,是对rsync官方技术报告和官方推荐文章的解释.本文不会介绍如何使用rsync命令(见rsync基本用法),而是详细解释它如何实现高效的增 ...
- Yarn框架和工作流程研究
一.概述 将公司集群升级到Yarn已经有一段时间,自己也对Yarn也研究了一段时间,现在开始记录一下自己在研究Yarn过程中的一些笔记.这篇blog主要主要从大体上说说Yarn的基本架构以及其 ...
- rsync(三)算法原理和工作流程分析
在开始分析算法原理之前,简单说明下rsync的增量传输功能. 假设待传输文件为A,如果目标路径下没有文件A,则rsync会直接传输文件A,如果目标路径下已存在文件A,则发送端视情况决定是否要传输文件A ...
- 【转】Hostapd工作流程分析
[转]Hostapd工作流程分析 转自:http://blog.chinaunix.net/uid-30081165-id-5290531.html Hostapd是一个运行在用户态的守护进程,可以通 ...
- [国嵌笔记][030][U-Boot工作流程分析]
uboot工作流程分析 程序入口 1.打开顶层目录的Makefile,找到目标smdk2440_config的命令中的第三项(smdk2440) 2.进入目录board/samsung/smdk244 ...
- nodejs的Express框架源码分析、工作流程分析
nodejs的Express框架源码分析.工作流程分析 1.Express的编写流程 2.Express关键api的使用及其作用分析 app.use(middleware); connect pack ...
- Mysql工作流程分析
Mysql工作流程图 工作流程分析 1. 所有的用户连接请求都先发往连接管理器 2. 连接管理器 (1)一直处于侦听状态 (2)用于侦听用户请求 3. 线程管理器 (1)因为每个用户 ...
随机推荐
- java-jsp特殊字符处理
str = str.replaceAll("'", "''").replaceAll("\"", ""&quo ...
- SCRUM的四大支柱
转自:http://www.scrumcn.com/agile/scrum-knowledge-library/scrum.html#tab-id-9 迭代开发 在Scrum的开发模式下,我们将开发周 ...
- win8调出右侧菜单栏
1.快捷键:win+c 2.鼠标放在右下角1s
- CodeForces 86 D Powerful array 莫队
Powerful array 题意:求区间[l, r] 内的数的出现次数的平方 * 该数字. 题解:莫队离线操作, 然后加减位置的时候直接修改答案就好了. 这个题目中发现了一个很神奇的事情,本来数组开 ...
- codeforces E. Mahmoud and Ehab and the function(二分+思维)
题目链接:http://codeforces.com/contest/862/problem/E 题解:水题显然利用前缀和考虑一下然后就是二分b的和与-ans_a最近的数(ans_a表示a的前缀和(奇 ...
- POJ 2230 Watchcow 欧拉图
Watchcow Time Limit: 3000MS Memory Limit: 65536K Total Submissions: 8800 Accepted: 3832 Specia ...
- hud 1633 Orchard Trees 点是否在三角形内模板 *
Orchard Trees Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Tot ...
- css 元素实际宽高
首先定义一个div. 然后稍微装修一下 下面开始区分 一.clientWidth和clientHeigh . clientTop和clientLeft 1,clientWidth的实际宽度 clien ...
- redis数据库学习
0 使用理由 0.1 高性能 纯内存操作,比在硬盘操作数据的速度有极大提升 0.2 高并发 承受请求比直接操作数据库大得多 0.3 单线程 至于redis单线程的原因.有点意思.CPU不是Redis的 ...
- IPv6地址存储
import java.util.Arrays; /** * @author: 何其有静 * @date: 2019/4/2 * @description: IPv6地址存储 * https://mp ...