Openmp多线程编程练习
环境配置
一般使用Visual Studio2019来作为openmp的编程环境
调试-->属性-->C/C++-->所有选项-->Openmp支持改为 是(可以使用下拉菜单)
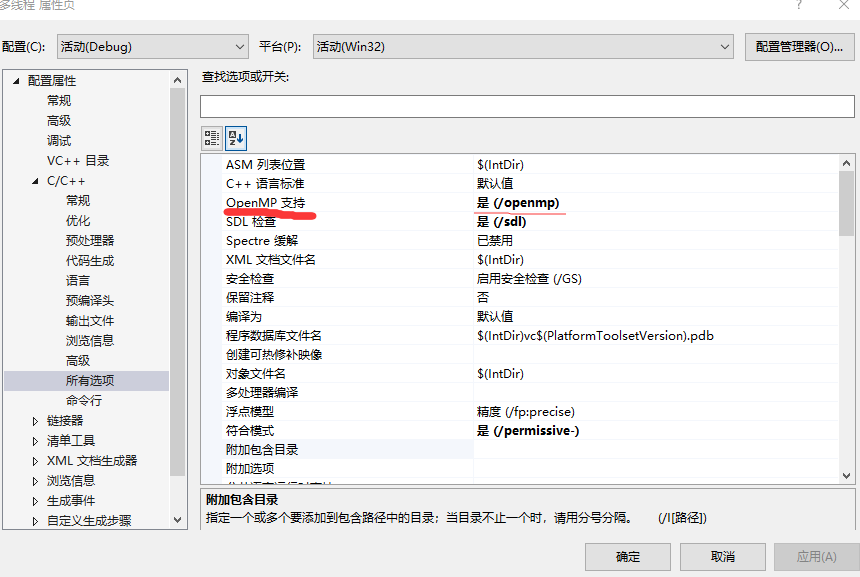
严重性 代码 说明 项目 文件 行 禁止显示状态 禁止显示状态
错误 C2338 C++/CLI、C++/CX 或 OpenMP 不支持两阶段名称查找;请使用 /Zc:twoPhase- 多线程 C:\Users\tonyson_in_the_rain\source\repos\多线程\多线程\c1xx 1
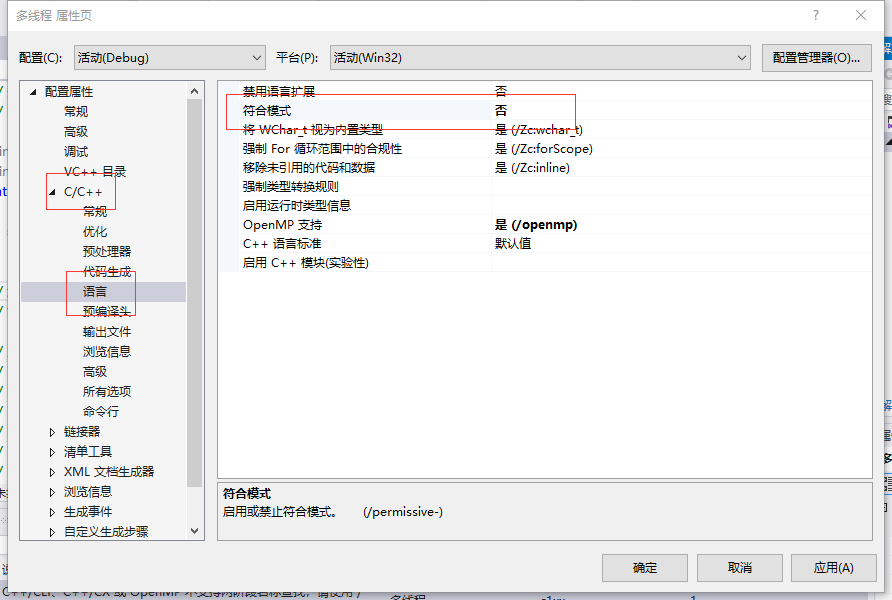
如果报错,再在属性菜单中找到C/C++ --> 语言 -->符合模式下拉菜单中选择"否"
第一个程序
- omp_get_thread_num()返回线程的编号
pragma omp parallel 用作注释的形式,即使没有openmp功能的编译环境也能够串行地正常执行程序.
#include "stdio.h"
#include "omp.h"
#include "windows.h"
int main()
{
printf("Hello from serial.\n");
printf("Thread number = %d\n", omp_get_thread_num()); //串行执行
Sleep(1000);
#pragma omp parallel //开始并行执行
{
printf("Hello from parallel. Thread number=%d\n", omp_get_thread_num());
Sleep(1000);
}
printf("Hello from serial again.\n");
return 0;
}
运行结果如下:

开始是串行,主线程的号为0,之后的1 2 3为子线程
循环
要求是for循环,而且必须能知道具体的循环次数.不能够使用break和return语句.
for循环的第一步是任务划分,如果有4个线程,100次循环,那么线程0就分配到了1-25次循环,然后线程1分配到26-50次,以此类推.
数据的相关性
int x[100], y[100], k, m;
x[0] = 0;
y[0] = 1;
#pragma omp parallel for private(k)
for (k = 1; k < 100; k++) {
x[k] = y[k - 1] + 1; //S1
y[k] = x[k - 1] + 2; //S2
printf("x[%d]=%d thread=%d\n", k, x[k], omp_get_thread_num());
printf("y[%d]=%d thread=%d\n", k, y[k], omp_get_thread_num());
}
printf("y=%d\n", y[99]);
printf("x=%d\n", x[99]);
这样的话,如果分配好后4个线程并行,那么1号线程计算时,变量用的是前一次的结果,但是前一次操作还没有进行,变量还没有初始化直接就运行,程序会出错.

提供一个改写方法,这个方法不受线程数量的影响,最终只能划分为两份,因为划分以迭代次数为最小单位,而for循环最外层只循环两次,所以最多只能划分成两份.
#pragma omp parallel for private(m, k)
for (m = 0; m < 2; m++)
{
for (k = m * 50 + 1; k < m * 50 + 50; k++)
{
x[k] = y[k - 1] + 1; //S1
y[k] = x[k - 1] + 2; //S2
printf("x[%d]=%d thread=%d\n", k, x[k], omp_get_thread_num());
printf("y[%d]=%d thread=%d\n", k, y[k], omp_get_thread_num());
}
}
多重循环
并不是所有的for循环都会并行化,只有紧挨着编译指导语句pragma omp parallel for的for循环会并行化
int i;int j;
#pragma omp parallel for private(j) //可以尝试去掉private语句,查看程序执行结果
for(i=0; i<2; i++)
for(j=6; j<10; j++)
printf( "i=%d j=%d\n", i , j);
printf("######################\n");
for(i=0; i<2; i++)
#pragma omp parallel for
for(j=6; j<10; j++)
printf( "i=%d j=%d\n", i , j );
上面部分运行结果:

其中一个线程获得了i=0时的任务,而另一个获得了i=1的迭代任务,j是串行的
如果去掉private:

如果不不用private,那么j就变成了共享的变量,两个线程并行就会出现错误,而编译指导语句后面的for循环中的i变量默认是私有变量,所以可以正常执行.
下面部分的运行结果:

下面
规约操作
会反复地把一个二元运算符应用在一个变量和另外一个值上,比如数组求和
int main()
{
int arx[100], ary[100], n = 100, a = 0, b = 0;
for (int i = 0; i < 100; i++)
{
arx[i] = 1; ary[i] = 1;
}
# pragma omp parallel for reduction(+:a,b)//可以去掉reduction子句,对比线程处理过程中的不同
for (int i = 0; i < n; i++)
{
a = a + arx[i];
b = b + ary[i];
printf("a=%d i= %d thread=%d\n", a, i, omp_get_thread_num());
printf("b=%d i= %d thread=%d\n", b, i, omp_get_thread_num());
}
printf("a=%d b= %d thread=%d\n", a, b, omp_get_thread_num());
}
| 运算符 | 数据类型 | 默认初始值 |
|---|---|---|
| + | 整数,浮点 | 0 |
| ***** | 整数,浮点 | 1 |
| - | 整数,浮点 | 0 |
| & | 整数 | 所有位都开启,****~0 |
| | | 整数 | 0 |
| ^ | 整数 | 0 |
| && | 整数 | 1 |
| || | 整数 | 0 |
可以使用的规约操作

私有变量的初始化和终结
- firstprivate把变量初始的值的带进来,取自原来同名变量的值
- lastprivate把变量的值带回去(将最后一次循环的相应变量赋给val
#include "stdio.h"
#include "omp.h"
#include "windows.h"
int main()
{
int val = 8;
#pragma omp parallel for firstprivate(val) lastprivate(val) //此处可充分改变private语句,观察程序执行结果
for (int i = 0; i < 4; i++) //可以改变循环次数,得到不同的最终值,如:i<7
{
printf("i=%d val=%d thread=%d\n", i, val, omp_get_thread_num());
if (i == 2)
val = 10000;
if (i == 3)
val = 11111;
printf("i=%d val=%d thread=%d\n", i, val, omp_get_thread_num());
}
printf("val=%d\n", val);
}

最后迭代时i=3,val=11111,所以最后带回去11111即可.
数据相关性与并行化操作
int main()
{
#pragma omp parallel
for (int i = 0; i < 5; i++)
printf("hello world i=%d\n", i);
printf("###########################\n");
#pragma omp parallel for
for (int i = 0; i < 5; i++)
printf("hello world i=%d\n", i);
}
上面是普通的并行操作,下面是for循环的并行化,输出如下:
hello world i=0
hello world i=1
hello world i=2
hello world i=3
hello world i=4
hello world i=0
hello world i=1
hello world i=0
hello world i=1
hello world i=0
hello world i=1
hello world i=2
hello world i=3
hello world i=4
hello world i=2
hello world i=3
hello world i=4
hello world i=2
hello world i=3
hello world i=4
###########################
hello world i=0
hello world i=1
hello world i=4
hello world i=3
hello world i=2
上边的实际上就是重复了这个任务,4个线程重复执行相同的任务,而下面就是for循环的并行.
私有全局变量
- threadprivate 每个线程有一个私有的副本,相互不要干扰
#include "stdio.h"
#include "omp.h"
#include "windows.h"
int counter = 50; //using threadprivate
#pragma omp threadprivate(counter)
void inc_counter() {
counter++;
}
int main()
{
#pragma omp parallel //注释上面的threadprivate子句,查看求和结果
{
for (int i = 0; i < 10000; i++)
inc_counter();
printf("counter=%d\n", counter);
}
}
正确的执行结果
counter=10050
counter=10050
counter=10050
counter=10050
如果注释掉#pragma omp threadprivate(counter)

并行区域编程
说的就是一个普通的并行区域的编译指导语句
pragma omp parallel
子句 private shared default reduction if copyin
并行区域编译指导语句的使用限制
程序块必须是只有单一入口和单一出口的程序块
不能从外面转入到程序块的内部,也不允许从程序块内部有多个出口转到程序块之外
程序块内部的跳转是允许的
程序块内部直接调用exit函数来退出整个程序的执行也是允许的
// OpenMP2.cpp : 定义控制台应用程序的入口点。
//
#include "stdio.h"
#include "omp.h"
#include <windows.h> //使用Sleep()函数需要包含此头文件
int counter = 0;
#pragma omp threadprivate(counter)
void inc_counter() {
counter++;
}
int main()
{
#pragma omp parallel //注释上面的threadprivate子句,查看求和结果
{
for (int i = 0; i < 10000; i++)
inc_counter();
printf("counter=%d\n", counter);
}
return 0;
}
/*
counter=10000
counter=30162
counter=20000
counter=39535
*/
/*
counter=10000
counter=10000
counter=10000
counter=10000
*/
copyin 可以把变量的值初始化到每个子线程的副本里面
// OpenMP2.cpp : 定义控制台应用程序的入口点。
//
#include "stdio.h"
#include "omp.h"
#include <windows.h> //使用Sleep()函数需要包含此头文件
int global;
#pragma omp threadprivate(global) ///?????????
int main()
{
global = 1000;
#pragma omp parallel copyin(global)
{
printf("global=%d, thread=%d\n", global, omp_get_thread_num());
global = omp_get_thread_num();
printf("global=%d, thread=%d\n", global, omp_get_thread_num());
}
printf("global=%d\n", global);
printf("parallel again\n");
#pragma omp parallel
printf("global=%d\n", global);
return 0;
}

为什么是0呢?因为global是问的主线程的global,已经由主线程改成了0,而其他的线程中的global还保存着原来的值.
工作共享
工作队列 不断从队列中取出标识号来完成
根据线程号分配任务
//程序段12(OMP_NUM_THREADS=4)
/* global=1000;
#pragma omp parallel copyin(global)
{
printf("global=%d, thread=%d\n",global,omp_get_thread_num());
global=omp_get_thread_num();
printf("global=%d, thread=%d\n",global,omp_get_thread_num());
}
printf("global=%d\n",global);
printf("parallel again\n");
#pragma omp parallel
printf("global=%d\n",global);*/
//使用copyin()子句的变量必须通过threadprivate()声明,
//parallel后可以使用private()子句、firstprivate()子句,不能使用lastprivate()子句
/*int g=100;
#pragma omp parallel firstprivate(g)
{
printf("g=%d, thread=%d\n",g,omp_get_thread_num());
g=omp_get_thread_num();
printf("g=%d, thread=%d\n",g,omp_get_thread_num());
}
printf("g=%d\n",g);
printf("parallel again\n");
#pragma omp parallel
printf("g=%d\n",g);*/
//程序段15
/*#pragma omp parallel
{
printf("outside loop thread=%d\n", omp_get_thread_num());
#pragma omp for
for(int i=0;i<4;i++)
printf("inside loop i=%d thread=%d\n", i, omp_get_thread_num());
} */

//程序段16
#pragma omp parallel sections
{
#pragma omp section
printf("section 1 thread=%d\n",omp_get_thread_num());
#pragma omp section
printf("section 2 thread=%d\n",omp_get_thread_num());
#pragma omp section
printf("sectino 3 thread=%d\n",omp_get_thread_num());
}
```
```
// OpenMP2.cpp : 定义控制台应用程序的入口点。
//
#include "stdio.h"
#include "omp.h"
#include <windows.h> //使用Sleep()函数需要包含此头文件
int main()
{
#pragma omp parallel num_threads(4)
{
printf("parallel region before single. thread %d\n", omp_get_thread_num());
#pragma omp single //执行期间其他线程等待
{
Sleep(1000);
printf("single region by thread %d.\n", omp_get_thread_num());
}
printf("parallel region after single. thread %d.\n", omp_get_thread_num());
}
}
```

把single改成master,执行的结果还是0,因为主线程就是0号线程,master只能由主线程执行
## 并行区域的共享
/ 2.根据线程号分配任务.由于每个线程在执行的过程中的线程标识号
// 是不同的,可以根据这个线程标识号来分配不同的任务
//#pragma omp parallel private(myid)
// {
// int nthreads = omp_get_num_threads();
// int myid = omp_get_thread_num();
// work_done(myid, nthreads); // 分配任务函数
// }
### 使用for语句分配任务
```
int main()
{
#pragma omp parallel num_threads(2)
{
printf("outside loop thread=%d\n", omp_get_thread_num());
#pragma omp for
for (int i = 0; i < 4; i++)
printf("inside loop i=%d thread=%d\n", i, omp_get_thread_num());
}
}
outside loop thread=0
outside loop thread=1
inside loop i=2 thread=1
inside loop i=3 thread=1
inside loop i=0 thread=0
inside loop i=1 thread=0
int main()
{
#pragma omp parallel num_threads(4)
{
printf("outside loop thread=%d\n", omp_get_thread_num());
#pragma omp for
for (int i = 0; i < 4; i++)
printf("inside loop i=%d thread=%d\n", i, omp_get_thread_num());
}
}
outside loop thread=0
inside loop i=0 thread=0
outside loop thread=2
inside loop i=2 thread=2
outside loop thread=1
inside loop i=1 thread=1
outside loop thread=3
inside loop i=3 thread=3
```
### 使用工作分区
```
// OpenMP2.cpp : 定义控制台应用程序的入口点。
//
#include "stdio.h"
#include "omp.h"
#include <windows.h> //使用Sleep()函数需要包含此头文件
int global = 88;
#pragma omp threadprivate(global)
int counter = 50; //using threadprivate
#pragma omp threadprivate(counter)
void inc_counter() {
counter++;
}
int main()
{
#pragma omp parallel sections
{
#pragma omp section
printf("section 1 thread=%d\n", omp_get_thread_num());
#pragma omp section
printf("section 2 thread=%d\n", omp_get_thread_num());
#pragma omp section
printf("sectino 3 thread=%d\n", omp_get_thread_num());
}
}
```

## openmp线程同步
提供了三种不同的互斥锁机制,分别是临界区,原子操作和库函数
原子操作只能作用在语言内建的基本数据结构
也可以加锁,比较安全
```
omp_lock_t lock;
omp_init_lock(&lock);
omp_destroy_lock(&lock);
omp_set_lock(&lock);
omp_unset_lock(&lock);
```
## 隐含的同步屏障
默认是把1-9分给了4个线程,执行完i的循环之后才可以输出finished,使用nowait后可以直接输出finished
```
int main()
{
#pragma omp parallel
{
#pragma omp for nowait
for (int i = 0; i < 9; i++)
printf("i=%d thread=%d\n", i, omp_get_thread_num());
printf("finished\n");
}
}
```
```
i=0 thread=0
i=1 thread=0
i=2 thread=0
finished
i=5 thread=2
i=6 thread=2
finished
i=7 thread=3
i=3 thread=1
i=8 thread=3
i=4 thread=1
finished
finished
```
如果去掉nowait
```
i=0 thread=0
i=1 thread=0
i=2 thread=0
i=3 thread=1
i=7 thread=3
i=8 thread=3
i=5 thread=2
i=6 thread=2
i=4 thread=1
finished
finished
finished
finished
```
可以控制每个子任务之间的并行部分和串行部分,可以先执行并行最后串行.
```
// OpenMP2.cpp : 定义控制台应用程序的入口点。
//
#include "stdio.h"
#include "omp.h"
#include <windows.h> //使用Sleep()函数需要包含此头文件
void work(int k)
{
printf("并行--thread id =%d k=%d\n", omp_get_thread_num(), k);
#pragma omp ordered
printf("order-id=%d k=%d\n", omp_get_thread_num(), k);
}
void ordered_func(int lb, int ub, int stride)
{
int i;
#pragma omp parallel for ordered schedule(dynamic) num_threads(5)
for (i = lb; i < ub; i += stride)
work(i);
}
int main()
{
ordered_func(0, 50, 5);
}
```

并行执行的时候顺序
后面的需要等待,所以就排在后面去了
## if子句的应用
如果if成立,那么就并行执行,否则就串行执行
[TOC]
## 火车卖票
```c++
// OpenMP2.cpp : 定义控制台应用程序的入口点。
//
#include "stdio.h"
#include "omp.h"
#include <windows.h> //使用Sleep()函数需要包含此头文件
int num;
omp_lock_t lock;
int getnum()
{
int temp = num;
//omp_set_nest_lock(&lock);
#pragma omp atomic
num--;
//omp_unset_nest_lock(&lock);
return num+1;
}
void chushou(int i)
{
int s = getnum();
while (s >= 0)
{
omp_set_lock(&lock);
printf("站点%d卖掉了第%d张票\n", i, s);
s = getnum();
omp_unset_lock(&lock);
Sleep(500);
}
}
int main()
{
num = 100;
int myid;
omp_init_lock(&lock);
#pragma omp parallel private(myid) num_threads(4)
{
myid = omp_get_thread_num();
//printf("my id is:%d\n", myid);
chushou(myid);
}
omp_destroy_lock(&lock);
return 0;
}
```
## 生产消费循环队列
```c++
#include "stdio.h"
#include "omp.h"
#include <windows.h> //使用Sleep()函数需要包含此头文件
int buf[5];//缓冲区的大小
int poi;
int poi2;
int num;
omp_lock_t lock;
void shengchan()
{
puts("shengchan");
while (true)
{
omp_set_lock(&lock);
if (num < 5)
{
while (buf[poi] == 1)poi = (poi + 1) % 5;
printf("生产者在%d位置上放置了一个\n", poi);
buf[poi] = 1;
num++;
poi = (poi + 1) % 5;
}
omp_unset_lock(&lock);
Sleep(500);
}
}
void xiaofei()
{
puts("xiaofei");
while (true)
{
omp_set_lock(&lock);
//printf("%d\n", num);
if (num>=1)
{
while (buf[poi2] == 0)poi2 = (poi2 + 1) % 5;
printf("消费者在%d位置上消费了一个\n", poi2);
buf[poi2] = 0;
num--;
}
omp_unset_lock(&lock);
Sleep(500);
}
}
int main()
{
omp_init_lock(&lock);
#pragma omp parallel sections num_threads(2)
{
#pragma omp section
shengchan();
#pragma omp section
xiaofei();
}
omp_destroy_lock(&lock);
return 0;
}
```
## 蒙特卡洛圆周率
```c++
#include "stdio.h"
#include "omp.h"
#include <windows.h> //使用Sleep()函数需要包含此头文件
#include<time.h>
#include<iostream>
using namespace std;
double distance(double x, double y)
{
return sqrt((x - 0.5) * (x - 0.5) + (y - 0.5) * (y - 0.5));
}
bool judge(double x,double y)
{
return distance(x, y) <= 0.5;
}
int in_num;
int main()
{
/*
for (int i = 1; i <= 5; i++)
{
cout << rand() / (double)RAND_MAX << endl;
}*/
bool flag = false;
double x;
double y;
#pragma omp for private(flag,x,y)
for (int i = 1; i <= 10000; i++)
{
x = rand() / (double)RAND_MAX;
y = rand() / (double)RAND_MAX;
flag = judge(x,y);
if (flag)
{
#pragma omp atomic
in_num++;
}
}
double ans = (double)in_num / 10000;
cout << ans*4 << endl;
}
```
## 多线程二维数组和解法1 firstprivate+atomic
```c++
#include "stdio.h"
#include "omp.h"
#include <windows.h> //使用Sleep()函数需要包含此头文件
#include<time.h>
#include<iostream>
using namespace std;
int a[5][5] = { {1,1,1,1,1},{2,2,2,2,2},{3,3,3,3,3},{4,4,4,4,4},{5,5,5,5,5} };
int final_ans = 0;
void increase(int temp_sum)
{
#pragma omp atomic
final_ans += temp_sum;
}
int main()
{
int temp_sum=0;
int i,j;
#pragma omp parallel for private(i,j) firstprivate(temp_sum) num_threads(5)//每个线程必须一致,或者采用ppt上的例子进行划分
// firstprivate(temp_sum) reduction(+:temp_sum) 这两个不能同时出现
for (i = 0; i <= 4; i++)
{
//temp_sum += 1;
//printf("%d 当前的temp_sum值为%d\n",i, temp_sum);
for (j = 0; j <= 4; j++)
{
temp_sum += a[i][j];
}
printf("temp_sum is %d\n", temp_sum);
increase(temp_sum);
}
printf("%d\n", final_ans);
return 0;
}
```
## 多线程二维数组解法2 线程可以不用对应数量
```
#include "stdio.h"
#include "omp.h"
#include <windows.h> //使用Sleep()函数需要包含此头文件
#include<time.h>
#include<iostream>
using namespace std;
int a[5][5] = { {1,1,1,1,1},{2,2,2,2,2},{3,3,3,3,3},{4,4,4,4,4},{5,5,5,5,5} };
int ans_buf[5];
int main()
{
int i, j;
#pragma omp parallel for num_threads(3) private(j)
for (int i = 0; i <= 4; i++)
{
for (int j = 0; j <= 4; j++)
{
ans_buf[i] += a[i][j];
}
}
int sum = 0;
for (int i = 0; i <= 4; i++)
sum += ans_buf[i];
printf("%d\n", sum);
}
```
1.模拟龟兔赛跑,先到达终点者输出
2.多线程二维矩阵前缀和(难) 需要先了解二维前缀和
3.模拟多个人通过一个山洞的模拟,这个山洞每次只能通过一个人,每个人通过山洞的时间为5秒,随机生成10个人,同时准备过此山洞,显示以下每次通过山洞的人的姓名。
4.多线程斐波那契数列(有点难)
5.openmp 快排 归并排序
6.3节点有5个人要去0 0节点有5个人要去3 防死锁

7.多线程 大数求和
lastprivate求和
并行串行判断Openmp多线程编程练习的更多相关文章
- openMP多线程编程
OpenMP(Open Muti-Processing) OpenMP缺点: 1:作为高层抽象,OpenMp并不适合需要复杂的线程间同步和互斥的场合: 2:另一个缺点是不能在非共享内存系统(如计算机集 ...
- 在C++中使用openmp进行多线程编程
在C++中使用openmp进行多线程编程 一.前言 多线程在实际的编程中的重要性不言而喻.对于C++而言,当我们需要使用多线程时,可以使用boost::thread库或者自从C++ 11开始支持的st ...
- OpenMP 并行编程
OpenMP 并行编程 最近开始学习并行编程,目的是为了提高图像处理的运行速度,用的是VS2012自带的OpenMP. 如何让自己的编译器支持OpenMP: 1) 点击 项目属性页 2)点击 配置 3 ...
- Web Worker javascript多线程编程(一)
什么是Web Worker? web worker 是运行在后台的 JavaScript,不占用浏览器自身线程,独立于其他脚本,可以提高应用的总体性能,并且提升用户体验. 一般来说Javascript ...
- Web Worker javascript多线程编程(二)
Web Worker javascript多线程编程(一)中提到有两种Web Worker:专用线程dedicated web worker,以及共享线程shared web worker.不过主要讲 ...
- windows多线程编程实现 简单(1)
内容:实现win32下的最基本多线程编程 使用函数: #CreateThread# 创建线程 HANDLE WINAPI CreateThread( LPSECURITY_ATTRIBUTES lpT ...
- Rust语言的多线程编程
我写这篇短文的时候,正值Rust1.0发布不久,严格来说这是一门兼具C语言的执行效率和Java的开发效率的强大语言,它的所有权机制竟然让你无法写出线程不安全的代码,它是一门可以用来写操作系统的系统级语 ...
- windows多线程编程星球(一)
以前在学校的时候,多线程这一部分是属于那种充满好奇但是又感觉很难掌握的部分.原因嘛我觉得是这玩意儿和编程语言无关,主要和操作系统的有关,所以这部分内容主要出现在讲原理的操作系统书的某一章,看完原理是懂 ...
- Java多线程编程核心技术---学习分享
继承Thread类实现多线程 public class MyThread extends Thread { @Override public void run() { super.run(); Sys ...
随机推荐
- Idea插件之IdeTalk
前言 随着越来越多的公司与Java工程师,逐步从Eclipse过度到Idea,安装相应的插件可能会成倍的增加工作效率. IDETalk是由JetBrains的工程师开发的一款代码级的协同工具,主要是为 ...
- Windows Terminal 安装及美化
windows terminal 是今年微软Build大会上推出的一款的全新终端,用来代替cmder之类的第三方终端.具有亚克力透明.多标签.Unicode支持(中文,Emoji).自带等宽字体等这些 ...
- mysql root用户登录后无法查看数据库全部表
可能是把root@localhost用户删掉了. 首先停掉mysql服务,在/etc/my.cnf中添加 skip-grant-tables,同时可以添加skip-networking选项来禁用网络功 ...
- python的__name__ == \'__main__\' 意义
转自http://www.jb51.net/article/51892.htm 很多新手刚开始学习python的时候经常会看到python 中__name__ = \'__main__\' 这样的代码 ...
- Flume 知识点(六)Flume 的监控
简述 使用 Flume 实时收集日志的过程中,尽管有事务机制保证数据不丢失,但仍然需要时刻关注 Source.Channel.Sink 之间的消息传输是否正常. 比如,SouceChannel 传输了 ...
- Java 学习笔记之 线程isInterrupted方法
线程isInterrupted方法: isInterrupted()是Thread对象的方法,测试线程是否已经中断. public class ThreadRunMain { public stati ...
- DrawerLayout(抽屉效果)
DrawerLayout是V4包下提供的一种左滑右滑抽屉布局效果. 实现效果如下: 因为是官方提供的,所以使用起来也相对的比较简单. DrawerLayout 提供 1.当界面弹出的时候,主要内容区会 ...
- HTML基础知识(块级标签,行内标签,行内块标签)
块级元素:独占一行,对宽高的属性值生效:如果不给宽度,块级元素就默认为浏览器的宽度,即就是100%宽: 行内元素:可以多个标签存在一行,对宽高属性值不生效,完全靠内容撑开宽高! 其中还有一种结合两种模 ...
- Spring入门(十五):使用Spring JDBC操作数据库
在本系列的之前博客中,我们从没有讲解过操作数据库的方法,但是在实际的工作中,几乎所有的系统都离不开数据的持久化,所以掌握操作数据库的使用方法就非常重要. 在Spring中,操作数据库有很多种方法,我们 ...
- Redis面试篇 -- Redis主从复制原理
Redis一般是用来支撑读高并发的,为了分担读压力,Redis支持主从复制.架构是主从架构,一主多从, 主负责写,并且将数据复制到其它的 slave 节点,从节点负责读. 所有的读请求全部走从 ...