spark集群搭建(三台虚拟机)——hadoop集群搭建(2)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下:
virtualBox5.2、Ubuntu14.04、securecrt7.3.6_x64英文版(连接虚拟机)
jdk1.7.0、hadoop2.6.5、zookeeper3.4.5、Scala2.12.6、kafka_2.9.2-0.8.1、park1.3.1-bin-hadoop2.6
前面搭建了spark集群需要的系统环境,本文在前文基础上搭建hadoop集群
一、配置几个配置文件
hadoop的下载和配置只需在spark1上操作,然后拷贝到另外两台机器上即可,下面的配置均在spark1上进行
$ cd /usr/local/bigdata/hadoop #进入hadoop安装目录
$ cd ./etc/hadoop
1、core-site.xml
$ vim core-site.xml
添加如下,指定namenode的地址:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://spark1:9000</value>
</property>
</configuration>
2、hdfs-site.xml
$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.tmp.dir</name>
<value>/usr/local/hadoop/data/tmp</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
3、mapred-site.xml,指定hadoop运行在yarn之上
$ mv mapred-site.xml.template mapred-site.xml
$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4、yarn-site.xml
$ vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>spark1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5、slaves
$ vim slaves
spark1
spark2
spark3
6、hadoop-env.sh
vim hadoop-env.sh
输入jdk完整路径
export JAVA_HOME=/usr/local/bigdata/jdk
二、另外两台机器
使用拷贝命令将hadoop拷贝过去
$ cd /usr/local/bigdata
$ scp -r hadoop root@spark2:/usr/local/bigdata
$ scp -r hadoop root@spark3:/usr/local/bigdata
三、配置hadoop环境变量,三台机器均需要配置
export HADOOP_HOME=/usr/local/bigdata/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMOM_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
四、启动hadoop集群
格式化namenode
$ hdfs namenode -format
$ start-dfs.sh
此时三台机器启动如下,才算成功
spark1
root@spark1:/usr/local/bigdata/hadoop/etc/hadoop# jps
4275 Jps
3859 NameNode
4120 SecondaryNameNode
3976 DataNode
spark2
root@spark2:/usr/local/bigdata/hadoop/etc/hadoop# jps
6546 DataNode
6612 Jps
spark3
root@spark3:/usr/local/bigdata/hadoop/etc/hadoop# jps
4965 DataNode
5031 Jps
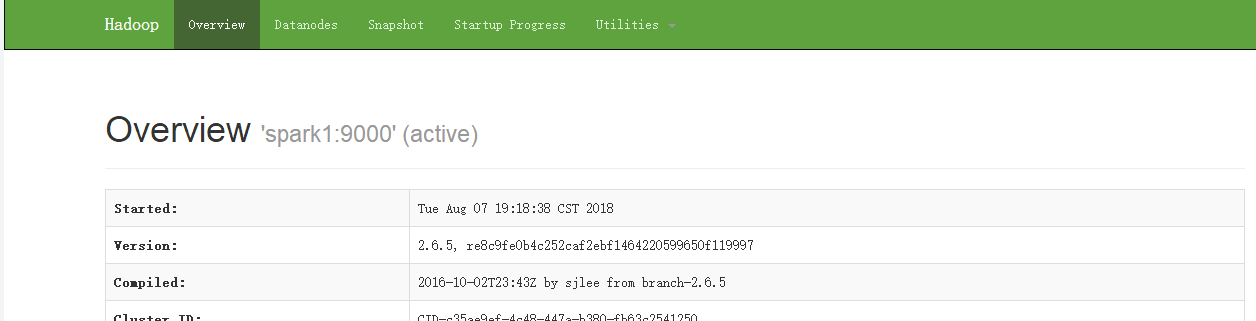
进入浏览器,访问http://spark1:50070
五、启动yarn集群
$ start-yarn.sh
此时spark1
root@spark1:/usr/local/bigdata/hadoop/etc/hadoop# jps
3859 NameNode
4803 Jps
4120 SecondaryNameNode
3976 DataNode
4443 ResourceManager
4365 NodeManager
spark2
root@spark2:/usr/local/bigdata/hadoop/etc/hadoop# jps
6546 DataNode
6947 Jps
6771 NodeManager
spark3
root@spark3:/usr/local/bigdata/hadoop/etc/hadoop# jps
5249 Jps
4965 DataNode
5096 NodeManager
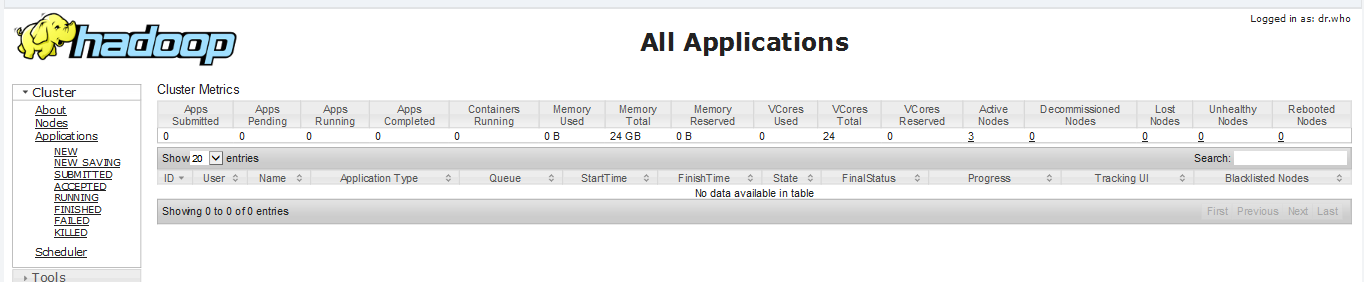
浏览器输入spark1:8088
spark集群搭建(三台虚拟机)——hadoop集群搭建(2)的更多相关文章
- Centos 7下VMware三台虚拟机Hadoop集群初体验
一.下载并安装Centos 7 传送门:https://www.centos.org/download/ 注:下载DVD ISO镜像 这里详解一下VMware安装中的两个过程 网卡配置 是Add ...
- 基于Docker快速搭建多节点Hadoop集群--已验证
Docker最核心的特性之一,就是能够将任何应用包括Hadoop打包到Docker镜像中.这篇教程介绍了利用Docker在单机上快速搭建多节点 Hadoop集群的详细步骤.作者在发现目前的Hadoop ...
- Hadoop4 利用VMware搭建自己的hadoop集群
前言: 前段时间自己学习如何部署伪分布式模式的hadoop环境,之前由于工作比较忙,学习的进度停滞了一段时间,所以今天抽出时间把最近学习的成果和大家分享一下. 本文要介绍的是如 ...
- 搭建简单的hadoop集群(译文)
本文翻译翻译自http://hadoop.apache.org/docs/r2.8.0/hadoop-project-dist/hadoop-common/ClusterSetup.html 具体的实 ...
- 在 Linux 服务器上搭建和配置 Hadoop 集群
实验条件:3台centos服务器,jdk版本1.8.0,Hadoop 版本2.8.0 注:hadoop安装和搭建过程中都是在用户lb的home目录下,master的主机名为host98,slave的主 ...
- Spark应用(app jar)发布到Hadoop集群的过程
记录了Spark,Hadoop集群的开启,关闭,以及Spark应用提交到Hadoop集群的过程,通过web端监控运行状态. 1.绝对路径开启集群 (每次集群重启,默认配置的hadoop集群中tmp文件 ...
- 虚拟机hadoop集群搭建
hadoop tar -xvf hadoop-2.7.3.tar.gz mv hadoop-2.7.3 hadoop 在hadoop根目录创建目录 hadoop/hdfs hadoop/hdfs/tm ...
- 搭建ubuntu版hadoop集群
用到的工具:VMware.hadoop-2.7.2.tar.jdk-8u65-linux-x64.tar.ubuntu-16.04-desktop-amd64.iso 1. 在VMware上安装ub ...
- Hadoop入门第四篇:手动搭建自己的hadoop小集群
前言 好几天没有更新了,本来是应该先写HDFS的相关内容,但是考虑到HDFS是我们后面所有学习的基础,而我只是简单的了解了一下而已,后面准备好好整理HDFS再写这块.所以大家在阅读这篇文章之前,请先了 ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
随机推荐
- Cocos2d-x 学习笔记(16) 触摸事件与分发 EventTouch dispatchTouchEvent EventListenerTouch
1. EventTouch 触摸事件的成员变量:枚举EventCode.存储Touch的容器. 不同的EventCode代表不同时机的触摸事件,能让监听器调用不同的回调函数. enum class E ...
- 安装Go语言及搭建Go语言开发环境
一步一步,从零搭建Go语言开发环境. 安装Go语言及搭建Go语言开发环境 下载 下载地址 Go官网下载地址:https://golang.org/dl/ Go官方镜像站(推荐):https://gol ...
- 第三方应用 flashfxp,filezilla提权
filezilla 提权 filezilla 开源的ftp服务器 默认监听14147端口 默认安装目录下有个敏感文件 filezillaserver.xml(包含用户信息) filezillaserv ...
- python 可变数量参数 ( 多参数返回求 参数个数,最大值,最大值)
一. 自定义一串数字求 参数个数,最大值,最大值()---------方法一: def max(*a): m=a[0] p=a[0] n=0 for x in a: if x>m: m=x n+ ...
- vue-cli3 搭建 vue 项目
vue-cli3 搭建 vue 项目 项目是在mac的环境下配置的 win的同学请移步[https://www.cnblogs.com/zhaomeizi/p/8483597.html] 安装 nod ...
- 微服务架构 ------ Day01 微服务架构优缺点
1. 微服务架构的优点 庞大的单体程序 -> 一套微型程序. 每一个服务有明确的边界(服务之间的消息通讯机制) ,每一个服务都能单独的开发和维护,并且更好理解 每一个服务都能由一个团队来开发,当 ...
- 06 python学习笔记-常用模块(六)
一. 模块.包 1.什么是模块? Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句,是用来组织代码的.模块能定义函数 ...
- Shiro learning - 入门案例(2)
Shiro小案例 在上篇Shiro入门学习中说到了Shiro可以完成认证,授权等流程.在学习认证流程之前,我们应该先入门一个Shiro小案例. 创建一个java maven项目 <?xml ve ...
- fenby C语言 P13
开关语句switch(变量) switch(weekday) ↓ 数字 default:异常处理 case-break #include <stdio.h> int main() { in ...
- 10、pytest -- skip和xfail标记
目录 1. 跳过测试用例的执行 1.1. @pytest.mark.skip装饰器 1.2. pytest.skip方法 1.3. @pytest.mark.skipif装饰器 1.4. pytest ...