OVS+DPDK Datapath 包分类技术
本文主体内容译于[DPDK社区文档],但并没有逐字翻译,在原文的基础上进行了一些调整,增加了对TSS分类器的详细阐述。
1. 概览
本文描述了OVS+DPDK中的包分类器(datapath classifier -- aka dpcls)的设计与实现思路。本文的内容主要牵涉到分类器对封包流的分类及缓存技术,并且对于一些典型场景下的细节给予解释说明。
虚拟交换机与传统硬件交换机的差别较大。硬件交换机通常都使用TCAM以求高效率的包分类与转发。而虚拟交换机由于自身是纯软件实现,不能依靠特殊的硬件设计,为了达到较高的工作效率,在设计和实现上大量使用缓存技术。OVS是一个兼容OpenFlow协议的虚拟交换机软件,发展比较迅速,基本上算是当前的业界网络虚拟化中的标杆与事实标准,OVS为了获得较高的转发性能,采用的基本思想也比较朴素:缓存。
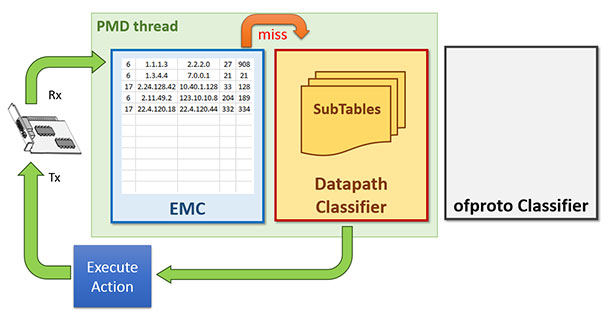
OVS的数据转发面(datapath -- aka dp)有多种实现,其中比较著名的有基于Linux内核协议栈的实现与DPDK的实现。当采用DPDK的实现时,封包的处理流程将完全绕过内核协议栈。OVS+DPDK在封包的查找匹配中,共有三级查找表/缓存的设计。最底一级是为完全精确匹配(Exact Match Cache -- aka EMC),如其名所示,这一级的查找匹配无法实现范围匹配、掩码前缀匹配等功能。中间一级就是本文的主角:dpcls,这一级的包分类器其实就是[这篇论文]描述的TSS分类器,使用论文中描述的TSS算法,这一级的分类器可以实现范围匹配、掩码前缀匹配等功能。如果单纯的作为一个虚拟交换机,仅有最底一级与中间级已经足够,而为了兼容OpenFlow协议,OVS还有最上一级的查找表:OpenFlow分类表(ofproto classifier table),其表项由OpenFlow控制器管理。下图基本展示了这三级查找表/缓存的设计逻辑。
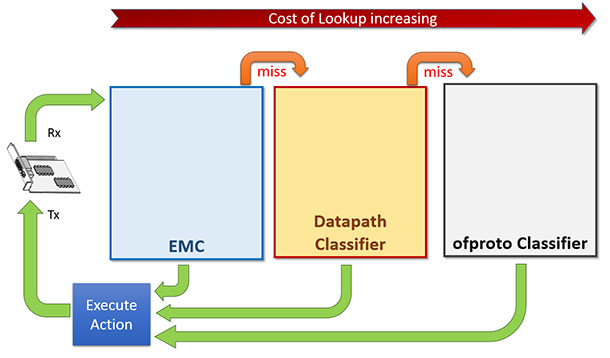
当一个包到达时,优先查找最底一级的EMC表,命中则转发,不命中则继续查找中间一级的包分类器,再不命中的话锅就扔给OpenFlow的分类器了,再不命中就要扔给OpenFlow控制器了,逻辑很清晰。
当封包流很稳定,流的数量EMC表也能hold住的时候,转发的性能取决于EMC表的查找匹配效率。这算是理想状态,现实世界很残酷,EMC表的容量有限,在封包流的数量达到一定规模的时候,决定转发效率的瓶颈就变成了中间一级的dpcls。所以dpcls本身的处理效率对于OVS+DPDK来说是很重要的一个关隘,其设计与实现是比较精巧的。
2. TSS分类算法简述
2.1. rule的定义
这里简单的介绍一下TSS分类器所使用的分类算法,不牵涉任何优化手段,仅介绍原算法本身。
定义rule就是单条的包过滤规则+动作,它可能长这样:
Rule #: ip_src=10.10.2.0/ ip_dst=* protocol=UDP port_src=* port_dst= actions=drop
Rule #: ip_src=10.11.0.0/ ip_dst=* protocol=TCP port_src=* port_dst= actions=output:
为了描述清晰起见,rule中的过滤规则使用了稳定的五个字段,即经典的五元组,但实际上rule可以使用任意多的字段
rule中的过滤规则,或者叫匹配规则,是由多个单字段过滤规则组成的,这些过滤规则符合,或者能转化为以下的形式:
字段值/掩码前缀
比如,对于IP地址来说,经常就是如下的形式
ip_src=192.168.0.0/
ip_dst=33.23.12.0/
对于IP头中的协议字段来讲,由于协议字段仅占八位,多数情况下都是严格匹配,比如上面列出的两个rule,其协议字段都是严格匹配为UDP或TCP,故它们可以写成如下形式
protocol=/(TCP)
protoco=/(UDP)
对于四层头中的端口号,一般情况下在各种防火墙也好,OpenFlow流表也好,匹配规则一般都写成精确匹配或者取值范围的形式,精确匹配可以很简单的写成字段值/前缀掩码的形式,无非就是掩码是16位掩码,而取值范围要转化为字段值/前缀掩码的形式,就需要一定的转化。我们举个例子好了,取值范围[12345, 33123]可以转化为如下形式:
|
* | ~
** | ~
** **** | ~
*** **** | ~
**** **** | ~
* **** **** | ~
** **** **** | ~
*** **** **** | ~
** **** **** **** | ~
**** **** | ~
** **** | ~
* **** | ~
** | ~
|
上面这个例子可能过分了一点,但足以说明一个问题:取值范围在数学上是可以被转化为字段值/前缀掩码这种形式的。
至此,rule中的常见的三种过滤规则都可以转化为字段值/前缀掩码的形式
精确匹配 == 值/全bit掩码
掩码匹配 == 值/掩码
取值范围 == 可以转化为多个 值/掩码 的组合
任意值 == 掩码位为0
将$字段值$记为field,将前缀掩码记为mask,则单个匹配规则的记法如下:
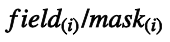
则一个rule的定义与记法就如下:
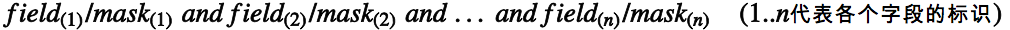
注意组成单条rule的多个匹配规则之间的逻辑关系是与/且,所以当匹配规则中有取值范围时,一个rule要按上面的记法,就得拆分成多个rule
2.2. tuple的定义
按照上方的定义,我们可以写出几个rule,如下所示:
Rule #: ip_src=192.168.0.0/
Rule #: ip_dst=23.23.233.0/ protocol=/(TCP) port_dst=/
Rule #: ip_dst=11.11.233.0/ protocol=/(UDP) port_dst=/
Rule #: ip_src=10.10.0.0/
在上面的例子中,我们省略了不关心的字段。
以上面的4个rule中,我们认为Rule #1与Rule #4属于同一个tuple,而Rule #2与Rule #3属于同一个tuple。
即属于同一个tuple中的所有rule有以下特点
使用相同的匹配字段
每个匹配字段都使用相同的掩码长度
假如我们将匹配字段仅限于传统的五元组,并且把不关心的字段也写出来,如下面这样:
Rule #: ip_src=192.168.0.0/ ip_dst=/ protocol=/ port_src=/ port_dst=/
Rule #: ip_src=/ ip_dst=23.23.233.0/ protocol=/(TCP) port_src=/ port_dst=/
Rule #: ip_src=/ ip_dst=11.11.233.0/ protocol=/(UDP) port_dst=/ port_dst=/
Rule #: ip_src=10.10.0.0/ ip_dst=/ protocol=/ port_src=/ port_dst=/
可以明显看出,其实属于同一个tuple中的所有rule仅有一个特点:
匹配字段的掩码长度相同
即tuple的定义与记法如下:
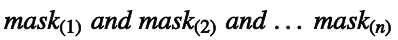
2.3. 分类算法
分类算法要解决的问题,可以描述如下
有一大堆rule
收到一个包
找到与这个包最匹配的rule,如果有多个匹配,按一定策略找出最优的那个
我们将最后一步的这个动作称为match,即是匹配查找
这不是一人困难的问题,至少在算法角度来讲,要解决这个问题并不困难,困难的是怎样快速的解决这个问题。最朴素的做法是:用线性表把所有rule都串起来,每次match都是一次遍历操作,时间复杂度O(N)
显然朴素是不行的
2.4. TSS
TSS首先把所有的rule进行分类,分类的依据是同tuple的所有rule在一起。
其次对于同一个tuple下的所有rule,以哈希表的形式将这些rule存储起来。
依然用例子来说明,还是上方提到的四条rule,如下:
Rule #: ip_src=192.168.0.0/ ip_dst=/ protocol=/ port_src=/ port_dst=/
Rule #: ip_src=/ ip_dst=23.23.233.0/ protocol=/(TCP) port_src=/ port_dst=/
Rule #: ip_src=/ ip_dst=11.11.233.0/ protocol=/(UDP) port_src=/ port_dst=/
Rule #: ip_src=10.10.0.0/ ip_dst=/ protocol=/ port_src=/ port_dst=/
它们将被分别两个tuple,我们分别记为tuple #1与tuple #2,这两个tuple的定义如下
Tuple #: ip_src_mask= ip_dst_mask= protocol_mask= port_src_mask= port_dst_mask=
Tuple #: ip_src_mask= ip_dst_mask= protocol_mask= port_src_mask= port_dst_mask=
每个tuple下都建一个哈希表,我们分别记为ht #1与ht #2。tuple下的rule就存储在相应的哈希表中,如下所示
HT #: Rule # | Rule #
HT #: Rule # | Rule #
上面只讲了哈希表中的value是一个个的rule,但没有说key是什么,下面以Tuple #2中的Rule #2为例说明一下:
首先用tuple的掩码去**与**rule中的各个**字段值**,丢弃tuple不关心的位,得到:
ip_src=_ ip_dst=23.23. protocol= port_src=_ port_dst=
然后把这些位拼接起来,就是哈希表的key,在本例中,转换为二进制如下:
key = () () () () ()
最后,用这个key去做散列,即是哈希表的索引
2.5. 匹配过程
现在所有的rule都被分成了多个tuple,并存储在相应tuple下的哈希表中
当要对一个包进行匹配时,将遍历这多个tuple下的哈希表,一个一个查过去,查出所有匹配成功的结果,然后按一定策略在匹配结果中选出最优的一个。
依然是举例说明,假设我们收到下面这样一个包:
Packet #: ip_src=192.168.1.2 ip_dst=23.23.233.234 protocol=UDP port_src= port_dst=
首先在第一个tuple中进行匹配查找
1) 将包的各个字段与tuple定义的mask进行**与**操作,得到
ip_src=192.168 ip_dst=_ protocol=_ port_src=_ port_dst=_
2) 将有效位拼接起来,得到key
key = () ()
并且这个key去Tuple #1下的哈希表做查找,则会命中Rule #1
3) 匹配成功,结果为Rule #1
然后在第二个tuple中进行匹配查找,显然也会匹配成功,命中Rule #3
最终,假设我们采用最长匹配策略的话,最终的匹配结果应当是Rule #3,因为该rule所属于的tuple掩码位数比Rule #1多。
2.6. TSS vs. 决策树
决策树又称分类树,是一种十分常用的分类、查找、搜索手段。但在网络封包的分类工作中,它并不适合,理由如下:
* 决策树的插入与删除效率不高。虚拟网络环境中的包分类器中的分类规则并不稳定,对于OVS+DPDK来讲,将其视为OpenFlow交换机来使用的话,很多场景下都会导致中间一层的包分类器中的规则发生大量的插入与删除操作。
* TSS的时间与空间复杂度均为O(N)。在最坏情况下,每个tuple中的哈希表仅有一个条目,哈希表的数目将等同于rules的数目,查找效率将趋近于线性查找。这不算糟糕,比起决策树来说,还好上不少。
* TSS中可以使用任意数目的封包字段进行匹配,而决策树一旦成型,要增加或减少一个字段就比较麻烦。在所有的匹配规则都是以传统五元组(ip_dst+ip_src+protocol+port_dst+port_src)进行匹配的情况下,新插入一个使用了第六个字段的匹配规则,这种事情对于TSS分类器来说,没有任何额外的负担,但对于决策树来说,就需要调整整颗树。
在TSS分类器中,查找就意味着一个个的去查各个tuple下的哈希表,直至某个哈希表命中。所有哈希表中的表项都是不重复、不互相覆盖的,这个前置要求解决了TSS算法中的一个蛋疼点:有多个匹配结果时如何最长匹配,在这个前置要求的前提下,一旦查找命中,那么只可能是唯一命中。分类器中的多个哈希表的顺序是随机的,表和表项都是在工作的过程中动态创建的。
2.7. 小结
TSS分类算法的时间复杂度为O(M),其中M是tuple的数量,空间复杂度是O(N),其中N是共计的rule的数量,无论是时间复杂度还是空间复杂度都在一个比较好的范围里。并且相较于其它分类算法,对待rule的插入与删除更友好
TSS分类算法充分利用了网络封包字段值的一些统计学特性,比如以掩码前缀为过滤规则的rule在实际防火墙或者路由器中是十分常见的。
Open vSwitch的数据转发面在包分类上采用了该算法,OVS+kernel datapath中的包分类在细节上与DPDK datapath有比较大的出入,并且随着版本的更迭也在做一些调整,但两者其实都使用的是TSS算法,两者细节处的不同也仅限于如何优化算法的执行效率。关于OVS的总体设计决策,可以参见[这篇论文],论文没有提及任何实现细节,仅在宏观上阐述了OVS的设计决策。
kernel datapath在历代版本中尝试过为tuple/哈希表增加ranking权重、缓存skb_hash与tuple/哈希表等手段,以期望减少遍历多个tuple/哈希表时能尽快命中正确的tuple/哈希表。
DPDK datapath优化的思路则是在TSS分类器下层建立一个小规格的、更快速的完全匹配EMC缓存,以期望在大多数情况下不借助TSS分类器能正确转发大部分流量。
TSS算法,或者叫TSS分类器最初发表于[这篇论文],发表于1999年。
3. 对哈希表进行排序以优化dpcls
在OVS 2.5 LTS分支上,每个PMD线程都会创建一个TSS分类器实例。每次查找都是对分类器中哈希表的遍历,平均开销为N/2,这里的N指的是哈希表的数量。尽管这样理论上看起来很完美,但实际开销中,算散列值也是一部分比较大的开销:每查一个哈希表,都要根据tuple的定义重新掩一次匹配字段,重新算一次散列值。
为了一定程度上缓解这个问题,OVS在2.6版本中,为每个哈希表都增加了一个ranking值,这个ranking值以哈希表命中查找的次数为准,这很好理解,将热度高的哈希表提到前面来,热度低的哈希表放在后面,以尽量减少平均查找哈希表的次数。
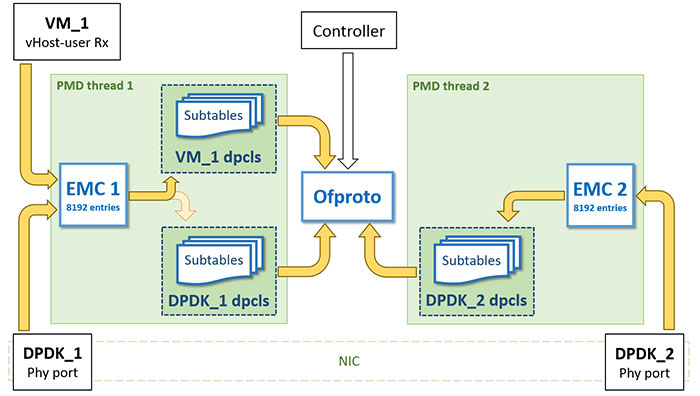
除了上面的改进,在2.6版本中,不再是为每个PMD线程创建一个dpcls实例,而是为每个ovs-port创建一个dpcls实例。这个改进就是工程实践上的经验性改进了,由于同一个port收上来的包有很强的相似性,这样为每个port都创建一个dpcls实例,这样dpcls实例中的哈希表数量,即tuple的数量会变少,变相的也提高了查找效率。
下图展示了多个dpcls的逻辑:下图中有三个ovs-port,其中有两个ovs-port(DPDK_1与DPDK_2)背后是物理网络接口,另外一个ovs-port(VM_1)背后是vHost User型的虚拟port。每个dpcls实例将负责从对应ovs-port收上来的包的分类工作。比如,比VM_1接口收上来的包由线程PMD thread 1处理,该线程先进EMC对包进行匹配,匹配失败后该线程负责对包进行掩码处理,算散列值,然后以该散列值去VM_1 dpcls中去查找。
4. 模糊匹配(wildcard matching)的实现技术
这里阐述的是中间一级的TSS分类器如何使用哈希表实现上层OpenFlow表项指导的模糊匹配功能。
假设OVS OpenFlow流表中增加了一条流表,其匹配规则如下所示:
Rule #: Src IP = "21.2.10.*"
这个规则可以通过如下的ovs命令添加进流表中:
ovs-ofctl add-flow br0 dl_type=0x0800,nw_src=21.2.10.1/,actions=output:
当OVS收到一个源IP字段值为21.2.10.5的包时,并假设EMC与dpcls都查找失败,这个包将送至ofproto classifier中进行匹配,并且会匹配至上面添加的这条规则。匹配成功之后,相应的学习机制会使得dpcls与EMC中都添加一个相应的表项。EMC中添加的表项是一个严格匹配表项,没有模糊匹配功能,而dpcls中添加的表项将带有模糊匹配,我们现在要阐述的就是dpcls如何添加这个表项。
下面的几个小节将一步一步的阐述OVS+DPDK如何建立起tuple哈希表,如何进行查找。我们假设在进行下面几个小节的操作之前,整个OVS+DPDK在中间层和下层,即dpcls与EMC这两层,是不存在任何条目、表项的。
4.1. 单ovs-port场景
上文中说过,在OVS 2.6版本之后,实际实现中是为每一个ovs-port创建一个独立的dpcls实例,下面的阐述中,将先介绍简单的场景,先介绍在单ovs-port场景,仅有一个dpcls实例的情况下,包分类是如何进行的,之后在单ovs-port场景的基础上再介绍实际实现中的多ovs-port场景,多dpcls实例下包分类是如何进行的
4.1.1添加第一个Rule
在向dpcls中的某个哈希表添加Rule #1之前,我们先要创建一个Mask #1。这个Mask如下
Mask #: 0xFF.FF.FF.
Mask创建完成后,下一步就是找到该Rule应属的哈希表,或者创建一个新的哈希表。
再接下来,为了将这个Rule添加进哈希表中,就需要先计算这个Rule的散列值,流程如下图所示:
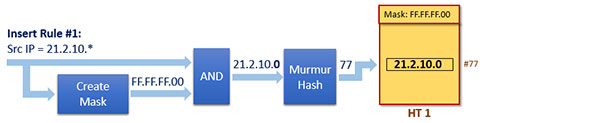
上图将Rule #1添加进了名为HT 1的哈希表中,除了Rule #1外,HT 1这张表中还会存储很多与Rule #1相似的规则,而所谓相似,就是指它们位于同一个tuple中,换名话说,即是这些Rule对应的Mask都相同
即下面这个Rule也会被添加进HT 1中,所有同一个哈希表中的Rule的Mask都是相同的
Rule #1A: Src IP="83.83.83.*"
4.1.2. 查找匹配过程
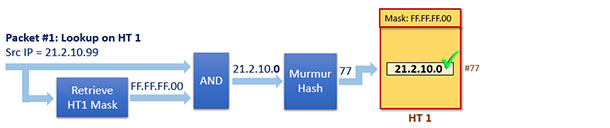
现在有一个包被收上来,其源IP地址为21.2.10.99,我们称这个包为Packet #1,假设现在OVS的dpcls中除了HT 1之外没有其它的哈希表,那么这个包将在该表中进行匹配搜索操作。
首先会将该包与Mask #1进行与操作,将与操作的操作结构进行散列运算,得到散列值,然后就查出结果了。如下图所示
4.1.3. 添加第二个Rule
现在假设我们要添加第二个Rule,有了前面第一个Rule如何添加的阐述,这里就不阐述的那么详细了。这次要添加的Rule依然是源IP地址匹配,但掩码变成了16位:
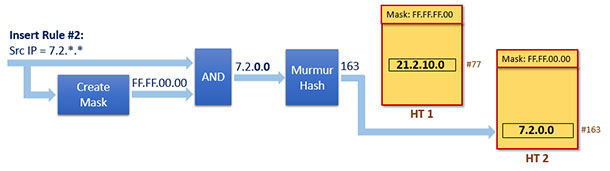
Rule #: Src IP = "7.2.*.*"
该Rule的对应的Mask是一个全新的Mask
Mask #: 0xFF.FF.00.00
这是一个全新的Mask,意味着这个Rule属于一个全新的tuple,一个新的哈希表会被创建,之后该Rule会被插入到新的哈希表中,我们记这个新的哈希表为HT 2。整个插入过程如下图所示:
4.1.4. 第二次查找匹配
现在收上来一个包,其源IP地址为7.2.45.67,我们记该包为Packet #2
现在dpcls中有两个哈希表,匹配查找将试图在这两个表上都执行,直到成功匹配为止。我们假设HT 1是首个被执行搜索的哈希表,则显然会查找失败,其查找匹配过程如下:
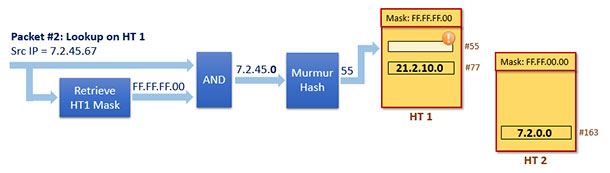
由于查找匹配失败,所以匹配流程将继续在HT 2上执行,流和如下:
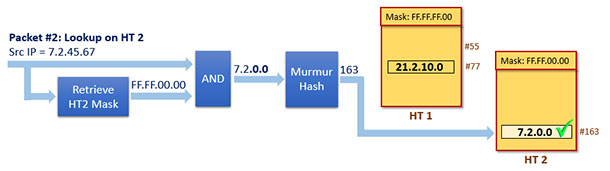
这一次匹配成功!
4.1.5. 小结
通过上面的图例与阐述,重新温习了TSS分类器的分类算法,也认识了OVS+DPDK对于TSS分类器的实现。但故事依然没有结束,在上面的例子中,整个OVS+DPDK的中间层仅有一个dpcls实例,所有OVS收到的包都由这个dpcls进行匹配查找操作,这样做是可行的,但与实际情况并不符合。前文说过,在2.6版本之后,OVS为每个ovs-port都创建了一个dpcls实例,下面我们将继续分析在多port多dpcls实例的情景下,Rule是如何被插入的,包是如何被匹配的。
4.2. 多ovs-port场景
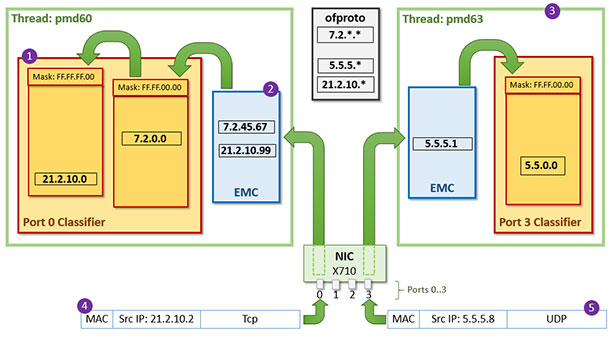
下图展示了两个PMD线程(PMD60与PMD63),两个ovs-port(port0与port3),port0由pmd60负责收包,port3由pmd63负责收包,每个port都有自己的dpcls实例与EMC缓存。这种场景下发生的故事:
1) 假设有两个包到达了port0,其源IP地址分别是21.2.10.99与7.2.45.67,其假设上一章阐述的故事均发生在port0上
2) 即port0的dpcls中会有两个tuple/哈希表,且其EMC中分别存储着源IP地址为21.2.10.99与7.2.45.67这两个包的action
3) 有一个包到达了port3,其源IP地址为5.5.5.1,包收上来之后在port3下的dpcls中生成了一个5.5.0.0/16的rule
4) 现在继续收包,port0上收到一个源IP地址为21.2.10.2的包,EMC中查无记录,于是去dpcls中查找,查找过程如上一章所述,如果运气不好的话需要查找两张哈希表。查找匹配成功后除了包将被转发出去,也会在EMC中下该包的缓存。
5) port3上收到一个源IP地址为5.5.5.8的包,EMC中查无记录,上dpcls查找,一次命中。包被转发,同时下EMC缓存
OVS+DPDK Datapath 包分类技术的更多相关文章
- dpdk数据包捕获技术笔记1
1 高效捕包技术的重要性 高性能系统需要在很短的时间内,成功的收集和处理大量的数据,目标系统的实时数据需要被收集,管里和控制. 2 传统的数据包捕获机制 Inter指出,影响数据包捕获性能主要原因是系 ...
- 基于DPDK的高效数据包捕获技术分析与应用
被NFV的论文折磨了两天,今天上午看了两篇DPDK的综述. 传统的包捕获机制 1. BPF 两个组成部分:转发部分和过滤部分. 转发部分负责从链路层提取数据包并转发给过滤部分. 过滤部分根据过滤规则, ...
- 译文:ovs+dpdk中的“vHost User NUMA感知”特性
本文描述了"vHost User NUMA感知"的概念,该特性的测试表现,以及该特性为ovs+dpdk带来的性能提升.本文的目标受众是那些希望了解ovs+dpdk底层细节的人,如果 ...
- OVS + dpdk 安装与实验环境配置
***DPDK datapath的OVS的安装与实验环境配置 首先肯定是DPDK的安装 0:安装必要的工具 make gcc ...
- DPI (Deep Packet Inspection) 深度包检测技术
详解DPI与网络回溯分析技术 随着网络通讯技术进步与发展,网络通讯已跨入大数据时代,如何监控各类业务系统的通讯数据在大数据流量中传输质量,以及针对海量的网络通讯数据的范畴中存在少量的恶意流量的检测,避 ...
- 谈谈dpdk应用层包处理程序的多进程和多线程模型选择时的若干考虑
看到知乎上有个关于linux多进程.多线程的讨论:http://www.zhihu.com/question/19903801/answer/14842584 自己项目里也对这个问题有过很多探讨和测试 ...
- 深入剖析iLBC的丢包补偿技术(PLC)
转自:http://blog.csdn.net/wanggp_2007/article/details/5136609 丢包补偿技术(Packet Loss Concealment——PLC)是iLB ...
- ovs+dpdk numa感知特性验证
0.介绍 本测试是为了验证这篇文章中提到的DPDK的NUMA感知特性. 简单来说,在ovs+dpdk+qemu的环境中,一个虚拟机牵涉到的内存共有三部分: DPDK为vHost User设备分配的De ...
- USB的包结构及包分类
USB的传输总是低位在前,高位在后. USB的传输方向:从设备到主机的数据为输入:从主机到设备的数据叫做输出. 1. 包结构 以同步域开始,紧跟着一个包标识符PID(Packet Identifier ...
随机推荐
- Android初级教程初谈自定义view自定义属性
有些时候,自己要在布局文件中重复书写大量的代码来定义一个布局.这是最基本的使用,当然要掌握:但是有些场景都去对应的布局里面写对应的属性,就显得很无力.会发现,系统自带的控件无法满足我们的要求,这个时候 ...
- iOS开发之音频播放AVAudioPlayer 类的介绍
主要提供以下了几种播放音频的方法: 1. System Sound Services System Sound Services是最底层也是最简单的声音播放服务,调用 AudioServicesPla ...
- CMake设置FOLDER失败及解决
CMake可以设置FOLDER属性,用来分目录组织VC中的多个工程. FOLDER: Set the folder name. Use to organize targets in an IDE. T ...
- Jeff Atwood:软件工程已死?
原文作者:Jeff Atwood 2009年7月,Tom DeMarco在<IEEE Software>杂志上发表了一篇论文,题为"Software Engineering: A ...
- Cocos2D:塔防游戏制作之旅(四)
让我们看一下项目的结构.在TowerDefense文件夹,你将找到: 含有Cocos2D文件的libs文件夹 含有所有图片和声音的资源文件夹 现在,你已经准备就绪准备开始建造炮台之旅了 ;) 放置炮塔 ...
- 用过的一些Android设备调试特性注意点(挖坑帖)
华为3C Activity切换动画偏快. 显示大图时不容易出现OOM(应用最大内容要比其他手机大一点),所以调试OOM问题时不要用此手机,否则难以发现问题. 小米3 不要调用系统的裁图功能.因为返回的 ...
- Python 编程常见问题
Python 编程常见问题 经常使用Python编程,把经常遇到问题在这里记录一下,省得到网上查找,因此这篇文章会持续更新,需要的可以Mark一下.进入正题: 1.Python常用的文件头声明 #!/ ...
- Dynamics CRM2013 picklist下拉项行数控制
CRM2013和前面几个版本相比有了很大的变化,本文中讲述的picklist亦然.CRM2013的picklist效果图如下所示 目前能看到的是会根据下拉内容项的数量不同而显示不同的下拉行数,但有时客 ...
- int(*p)[]和int(**p)[]
1. int(*p)[10]: 根据运算符的结合律,()的优先级最高,所以p是一个指针,指向的一个维度为10的一维数组. p一个指向数组的某一行 int a[1][4]={1,2,3,4}; int ...
- [C#]ToString("##")格式化用法案例一:自动编码单据流水码
之前的写的自动编码单据流水码是写在存储过程或者函数中的,今天用程序写一个发现TOSTRING可以格式化方便. /// <summary> /// 年月日+两位流水码 /// </su ...