机器学习中 K近邻法(knn)与k-means的区别
简介
K近邻法(knn)是一种基本的分类与回归方法。k-means是一种简单而有效的聚类方法。虽然两者用途不同、解决的问题不同,但是在算法上有很多相似性,于是将二者放在一起,这样能够更好地对比二者的异同。
算法描述
knn
算法思路:
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
k近邻模型的三个基本要素:
- k值的选择:k值的选择会对结果产生重大影响。较小的k值可以减少近似误差,但是会增加估计误差;较大的k值可以减小估计误差,但是会增加近似误差。一般而言,通常采用交叉验证法来选取最优的k值。
- 距离度量:距离反映了特征空间中两个实例的相似程度。可以采用欧氏距离、曼哈顿距离等。
- 分类决策规则:往往采用多数表决。
k-means
算法步骤:
1. 从n个数据中随机选择 k 个对象作为初始聚类中心;
2. 根据每个聚类对象的均值(中心对象),计算每个数据点与这些中心对象的距离;并根据最小距离准则,重新对数据进行划分;
3. 重新计算每个有变化的聚类簇的均值,选择与均值距离最小的数据作为中心对象;
4. 循环步骤2和3,直到每个聚类簇不再发生变化为止。
k-means方法的基本要素:
- k值的选择:也就是类别的确定,与K近邻中k值的确定方法类似。
- 距离度量:可以采用欧氏距离、曼哈顿距离等。
应用实例
问题描述
已知若干人的性别、身高和体重,给定身高和体重判断性别。考虑使用k近邻算法实现性别的分类,使用k-means实现性别的聚类。
数据
数据集合:https://github.com/shuaijiang/FemaleMaleDatabase
该数据集包含了训练数据集和测试数据集,考虑在该数据集上利用k近邻算法和k-means方法分别实现性别的分类和聚类。
将训练数据展示到图中,可以更加直观地观察到数据样本之间的联系和差异,以及不同性别之间的差异。
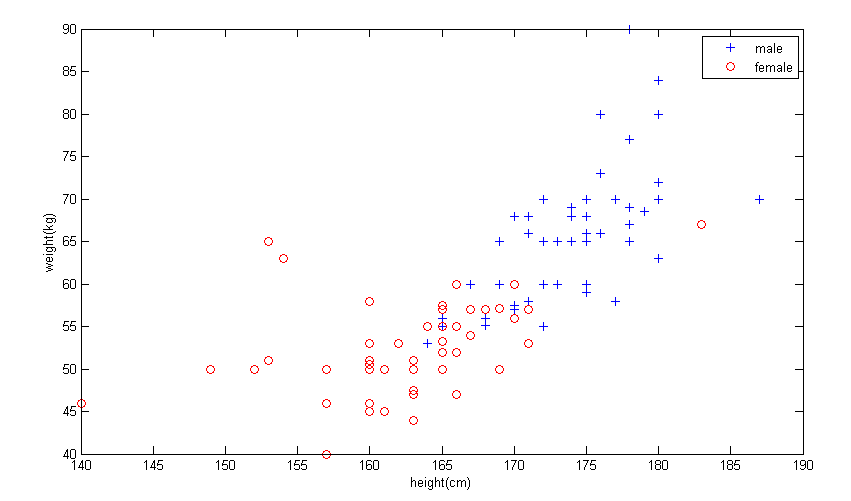 数据展示
数据展示
KNN的分类结果
KNN算法中的基本设置
- k=5
- 距离度量:欧氏距离
- 分类决策规则:多数投票
- 测试集:https://github.com/shuaijiang/FemaleMaleDatabase/blob/master/test0.txt
利用KNN算法,在测试集上的结果如下混淆矩阵表所示。从表中可以看出,测试集中的男性全部分类正确,测试集中的女性有一个被错误分类,其他都分类正确。
混淆矩阵 Test:male Test:female Result:male 20 1 Result:female 0 14
(表注:Test:male、Test:female分别表示测试集中的男性和女性,Result:male和Result:female分别表示结果中的男性和女性。表格中第一个元素:即Test:male列、Result:male行,表示测试集中为男性、并且结果中也为男性的数目。表格中其他元素所代表的含义以此类推)
由上表可以计算分类的正确率:(20+14)/(20+14+1) = 97.14%
K-means的聚类结果
K-means算法的基本设置
- k=2
- 距离度量:欧氏距离
- 最大聚类次数:200
- 类别决策规则:根据每个聚类簇中的多数决定类别
- 测试集:https://github.com/shuaijiang/FemaleMaleDatabase/blob/master/test0.txt
混淆矩阵 Test:male Test:female Result:male 20 1 Result:female 0 14
(表注:该表与上表内容一致)
由于选择初始中心点是随机的,所以每次的聚类结果都不相同,最好的情况下能够完全聚类正确,最差的情况下两个聚类簇没有分开,根据多数投票决定类别时,被标记为同一个类别。
KNN VS K-means
二者的相同点:
- k的选择类似
- 思路类似:根据最近的样本来判断某个样本的属性
二者的不同点:
- 应用场景不同:前者是分类或者回归问题,后者是聚类问题;
- 算法复杂度: 前者O(n^2),后者O(kmn);(k是聚类类别数,m是聚类次数)
- 稳定性:前者稳定,后者不稳定。
总结
本文概括地描述了K近邻算法和K-means算法,具体比较了二者的算法步骤。在此基础上,通过将两种方法应用到实际问题中,更深入地比较二者的异同,以及各自的优劣。本文作者还分别实现了K近邻算法和K-means算法,并且应用到了具体问题上,最后得到了结果。
以上内容难免有所纰漏和错误,欢迎指正。
机器学习中 K近邻法(knn)与k-means的区别的更多相关文章
- K近邻法(KNN)原理小结
K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用.比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出 ...
- k近邻法(KNN)和KMeans算法
k近邻算法(KNN): 三要素:k值的选择,距离的度量和分类决策规则 KMeans算法,是一种无监督学习聚类方法: 通过上述过程可以看出,和EM算法非常类似.一个简单例子, k=2: 畸变函数(dis ...
- scikit-learn K近邻法类库使用小结
在K近邻法(KNN)原理小结这篇文章,我们讨论了KNN的原理和优缺点,这里我们就从实践出发,对scikit-learn 中KNN相关的类库使用做一个小结.主要关注于类库调参时的一个经验总结. 1. s ...
- 机器学习--K近邻 (KNN)算法的原理及优缺点
一.KNN算法原理 K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法. 它的基本思想是: 在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对 ...
- 机器学习PR:k近邻法分类
k近邻法是一种基本分类与回归方法.本章只讨论k近邻分类,回归方法将在随后专题中进行. 它可以进行多类分类,分类时根据在样本集合中其k个最近邻点的类别,通过多数表决等方式进行预测,因此不具有显式的学习过 ...
- k近邻法(kNN)
<统计学习方法>(第二版)第3章 3 分类问题中的k近邻法 k近邻法不具有显式的学习过程. 3.1 算法(k近邻法) 根据给定的距离度量,在训练集\(T\)中找出与\(x\)最邻近的\(k ...
- k近邻法
k近邻法(k nearest neighbor algorithm,k-NN)是机器学习中最基本的分类算法,在训练数据集中找到k个最近邻的实例,类别由这k个近邻中占最多的实例的类别来决定,当k=1时, ...
- 学习笔记——k近邻法
对新的输入实例,在训练数据集中找到与该实例最邻近的\(k\)个实例,这\(k\)个实例的多数属于某个类,就把该输入实例分给这个类. \(k\) 近邻法(\(k\)-nearest neighbor, ...
- 机器学习笔记(十)---- KNN(K Nearst Neighbor)
KNN是一种常见的监督学习算法,工作机制很好理解:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个"邻居"的信息来进行预测.总结一句话就是&quo ...
随机推荐
- 2D变形transform的translate和rotate
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- PORTE_ISFR & (1<<n)
位运算关键:空出补零,溢出舍弃
- QT 创建一个具有复选功能的下拉列表控件
最近研究了好多东西,前两天突然想做一个具有复选功能的下拉列表框.然后在网上"学习"了很久之后,终于发现了一个可以用的,特地发出来记录一下. 一.第一步肯定是先创建一个PROJECT ...
- linux中的颜色控制
\033[031m xxx \033[0m ---------------------->中间的xxx部分显示为红色,不接后面的\033[0m,则以后显示的都是红色,\033表示开始和结束 ...
- python爬微信公众号前10篇历史文章(6)-话说http cookies
早期Web开发面临的最大问题之一是如何管理状态.简言之,服务器端没有办法知道两个请求是否来自于同一个浏览器.这是cookies的起源. 什么是cookie? A cookie is a small s ...
- C++环境搭建与atom编译器编译C++
Windows下安装 方法一--VS: 使用windows开发神器visio studio.这种方法比较简单,直接下载一个最新的vs安装就行.不单单是C++,C.C#.VB等都可以开发. 方法二--只 ...
- Object.defineProperty实现数据绑定
1.Object.defineProperty方法 Object.defineProperty(obj, prop, descriptor); (1)参数: obj:目标对象 prop:需要定义的属 ...
- 基于hi-nginx的web开发(python篇)——路由装饰器
现在,有了起步的基本认识,现在需要一个可以媲美flask或者bottle的简洁易用的路由功能,可以用装饰器写法任意映射 URLs 到代码. 这个,并不难.首先,来一个叫做hi的模块:hi.py: im ...
- 排序算法Java实现(归并排序)
算法描述:对于给定的一组记录,首先将每两个相邻的长度为1的子序列进行归并,得到 n/2(向上取整)个长度为2或1的有序子序列,再将其两两归并,反复执行此过程,直到得到一个有序序列. package s ...
- 从 MVC 到前后端分离
从 MVC 到前后端分离 1 理解 MVC MVC 是一种经典的设计模式,全名为 Model-View-Controller,即 模型-视图-控制器. 其中,模型 是用于封装数据的载体,例如,在 Ja ...