.35-浅析webpack源码之babel-loader入口文件路径读取
哈哈,上首页真难,每次都被秒下,心疼自己1秒~
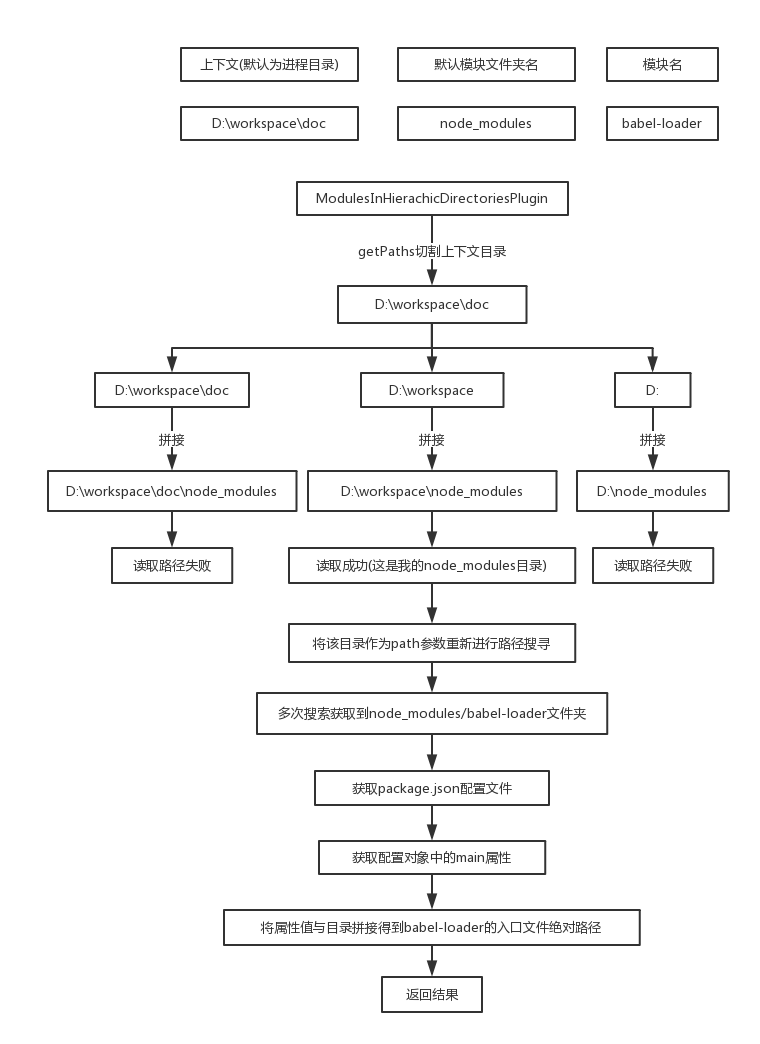
这里补充一个简要图,方便理解流程:
在处理./input.js入口文件时,在类型判断被分为普通文件,所以走的文件事件流,最后拼接得到文件的绝对路径。
但是对应"babel-loader"这个字符串,在如下正则中被判定为模块类型:
// Resolver.js
var notModuleRegExp = /^\.$|^\.[\\\/]|^\.\.$|^\.\.[\/\\]|^\/|^[A-Z]:[\\\/]/i;
Resolver.prototype.isModule = function isModule(path) {
return !notModuleRegExp.test(path);
};
因此,参考第33节的流程图,在ModuleKindPlugin插件中,会走新的事件流,如下:
ModuleKindPlugin.prototype.apply = function(resolver) {
var target = this.target;
resolver.plugin(this.source, function(request, callback) {
// 这里request.module为true 继续走下面的代码
if (!request.module) return callback();
var obj = Object.assign({}, request);
delete obj.module;
// target => raw-module
resolver.doResolve(target, obj, "resolve as module", createInnerCallback(function(err, result) {
if (arguments.length > 0) return callback(err, result);
// Don't allow other alternatives
callback(null, null);
}, callback));
});
};
进入raw-module事件流!
raw-module事件流
事件流定义如下:
// raw-module
// 默认为空数组
moduleExtensions.forEach(function(item) {
plugins.push(new ModuleAppendPlugin("raw-module", item, "module"));
});
// 垃圾插件
if (!enforceModuleExtension)
plugins.push(new TryNextPlugin("raw-module", null, "module"));
这里没有任何操作,直接进入module事件流。
module事件流 => ModulesInHierachicDirectoriesPlugin
定义地点如下:
// module
// modules => [ [ 'node_modules' ] ]
modules.forEach(function(item) {
// 进这个分支
if (Array.isArray(item))
plugins.push(new ModulesInHierachicDirectoriesPlugin("module", item, "resolve"));
else
plugins.push(new ModulesInRootPlugin("module", item, "resolve"));
});
这个modules是默认的一个数组,内容为node_modules,后来二次包装变成个二维数组了。
总之不管那么多,直接看插件内容:
ModulesInHierachicDirectoriesPlugin.prototype.apply = function(resolver) {
var directories = this.directories;
var target = this.target;
resolver.plugin(this.source, function(request, callback) {
var fs = this.fileSystem;
// 早该这样了 一堆callback谁分的清啊
var topLevelCallback = callback;
// getPaths获取进程路径各级目录
// D:\workspace\doc => ['d:\\workspace\\doc','d:\\workspace','d:']
// 这个map+reduce总的来说就是拼接路径
/*
最后会生成
[
'D:\\workspace\\doc\\node_modules',
'D:\\workspace\\node_modules',
'D:\\node_modules'
]
*/
var addrs = getPaths(request.path).paths.map(function(p) {
return directories.map(function(d) {
return this.join(p, d);
}, this);
}, this).reduce(function(array, p) {
array.push.apply(array, p);
return array;
}, []);
// 开始读取每一个拼接成的数组
forEachBail(addrs, function(addr, callback) {
fs.stat(addr, function(err, stat) {
// 当读取到一个有效路径时就进入下一个事件流
if (!err && stat && stat.isDirectory()) {
var obj = Object.assign({}, request, {
path: addr,
request: "./" + request.request
});
var message = "looking for modules in " + addr;
return resolver.doResolve(target, obj, message, createInnerCallback(callback, topLevelCallback));
}
if (topLevelCallback.log) topLevelCallback.log(addr + " doesn't exist or is not a directory");
if (topLevelCallback.missing) topLevelCallback.missing.push(addr);
return callback();
});
}, callback);
});
};
这里的方法很简单很暴力,直接拆分当前的目录,然后跟node_modules进行拼接,然后尝试读取每一个路径。
当读取成功而且该目录是一个文件夹时,就会把信息加入对象并进入下一个事件流。
这个事件流的名字是resolve……是的,又要进入新的一轮循环,这次会以普通文件的形式读取,所以之前在获取模块类型的第一时间需要删除module属性。
再次进入doResolve中,这里只用文字描述流程,request变成了./babel-loader,path为node_modules文件夹的路径。
1、ParsePlugin类型判断
由于在上面的代码中,request被手动添加了./的前缀,所以在模块判断正则中被判定为非模块。
2、DescriptionFilePlugin
由于path修改,所以在读取package.json时会直接读取node_modules/babel-loader/package.json文件。
但是在第一次读取会失败,因为并不存在node_modules/package.json文件,修正过程看下面。
3、JoinRequestPlugin
在这个插件,配置文件读取路径会被修正,代码如下:
JoinRequestPlugin.prototype.apply = function(resolver) {
var target = this.target;
resolver.plugin(this.source, function(request, callback) {
/*
path => D:\workspace\node_modules
request => ./babel-loader
拼接后得到 D:\\workspace\\node_modules\\babel-loader
*/
var obj = Object.assign({}, request, {
path: resolver.join(request.path, request.request),
relativePath: request.relativePath && resolver.join(request.relativePath, request.request),
request: undefined
});
resolver.doResolve(target, obj, null, callback);
});
};
4、FileExistsPlugin
由于上面的修正,这个插件的读取会有一些问题:
FileExistsPlugin.prototype.apply = function(resolver) {
var target = this.target;
resolver.plugin(this.source, function(request, callback) {
var fs = this.fileSystem;
var file = request.path;
// file => D:\\workspace\\node_modules\\babel-loader
fs.stat(file, function(err, stat) {
if (err || !stat) {
if (callback.missing) callback.missing.push(file);
if (callback.log) callback.log(file + " doesn't exist");
return callback();
}
// 由于这是一个文件夹 所以会进入这个分支
if (!stat.isFile()) {
if (callback.missing) callback.missing.push(file);
if (callback.log) callback.log(file + " is not a file");
return callback();
}
this.doResolve(target, request, "existing file: " + file, callback, true);
}.bind(this));
});
};
由于读取到这是一个文件夹,所以不会进入最后的事件流,而是直接调用无参回调函数,再次重新尝试读取。
文件夹读取 => existing-drectory
由于这里会读取文件夹类型,所以顺便把文件夹的事件流分支过一下。
相关的核心事件流只有existing-directory,如下:
// existing-directory
// 这个忽略
plugins.push(new ConcordMainPlugin("existing-directory", {}, "resolve"));
// 默认 mainFields => ["browser", "module", "main"]
mainFields.forEach(function(item) {
plugins.push(new MainFieldPlugin("existing-directory", item, "resolve"));
});
// 默认 mainFiles => ["index"]
mainFiles.forEach(function(item) {
plugins.push(new UseFilePlugin("existing-directory", item, "undescribed-raw-file"));
});
除去第一个垃圾插件,后面两个可以过一下。
MainFieldPlugin
这个插件主要获取loader的入口文件相对路径。
// existing-directory
// 这个忽略
plugins.push(new ConcordMainPlugin("existing-directory", {}, "resolve"));
/*
默认mainFields =>
{ name: 'loader', forceRelative: true }
{ name: 'main', forceRelative: true }
*/
mainFields.forEach(function(item) {
plugins.push(new MainFieldPlugin("existing-directory", item, "resolve"));
});
MainFieldPlugin.prototype.apply = function(resolver) {
var target = this.target;
// options => ["browser", "module", "main"]
var options = this.options;
resolver.plugin(this.source, function mainField(request, callback) {
if (request.path !== request.descriptionFileRoot) return callback();
var content = request.descriptionFileData;
// path.basename => 获取path的最后一部分
// D:\workspace\node_modules\babel-loader\package.json => package.json
var filename = path.basename(request.descriptionFilePath);
var mainModule;
// loader、main
var field = options.name;
if (Array.isArray(field)) {
var current = content;
for (var j = 0; j < field.length; j++) {
if (current === null || typeof current !== "object") {
current = null;
break;
}
current = current[field[j]];
}
if (typeof current === "string") {
mainModule = current;
}
} else {
// 获取配置文件中对应键的值
if (typeof content[field] === "string") {
mainModule = content[field];
}
}
if (!mainModule) return callback();
if (options.forceRelative && !/^\.\.?\//.test(mainModule))
mainModule = "./" + mainModule;
// 定义request的值
var obj = Object.assign({}, request, {
request: mainModule
});
return resolver.doResolve(target, obj, "use " + mainModule + " from " + options.name + " in " + filename, callback);
});
}
而在babel-loader中,有一个名为main的键,值为'lib/index.js',与目录拼接后,刚好是babel-loader这个模块的入口文件的绝对路径。
一旦在package.json中找到了对应的值,就会跳过下一个插件,直接进入最终的事件流。
但是为了完整,还是看一眼,当package.json中没有对入口文件的路径进行定义时,会进入MainFieldPlugin插件,源码如下:
UseFilePlugin.prototype.apply = function(resolver) {
var filename = this.filename;
var target = this.target;
resolver.plugin(this.source, function(request, callback) {
// 默认filename => "index"
// 直接对目录与默认入口文件名进行拼接
var filePath = resolver.join(request.path, filename);
// 重定义键
var obj = Object.assign({}, request, {
path: filePath,
relativePath: request.relativePath && resolver.join(request.relativePath, filename)
});
resolver.doResolve(target, obj, "using path: " + filePath, callback);
});
};
很简单,直接拼接默认入口文件名与目录,接下来流程如下:
mainFiles.forEach(function(item) {
plugins.push(new UseFilePlugin("existing-directory", item, "undescribed-raw-file"));
});
// undescribed-raw-file
// 重新走一边文件类型的流程
plugins.push(new DescriptionFilePlugin("undescribed-raw-file", descriptionFiles, "raw-file"));
plugins.push(new NextPlugin("after-undescribed-raw-file", "raw-file"));
可以看到,拼接完后,将以文件类型的形式尝试重新读取新路径。
至此,模块的入口文件路径读取过程解析完毕,基本上其他loader、框架、库等都是按照这个模式读取到入口文件的。
.35-浅析webpack源码之babel-loader入口文件路径读取的更多相关文章
- .17-浅析webpack源码之compile流程-入口函数run
本节流程如图: 现在正式进入打包流程,起步方法为run: Compiler.prototype.run = (callback) => { const startTime = Date.now( ...
- php 读取网页源码 , 导出成txt文件, 读取xls,读取文件夹下的所有文件的文件名
<?php // 读取网页源码$curl = curl_init();curl_setopt($curl, CURLOPT_URL, $url);curl_setopt($curl, CURLO ...
- CI 框架源码解析一之入口文件 index.php
Index.php作为CI框架的入口文件,源码分析,自然而然由此开始.在源码分析的过程中,我们并不会逐行进行解释,而只解释核心的功能和实现,如果英文水平很好的话,读过index.php文件的英文注释之 ...
- .38-浅析webpack源码之读取babel-loader并转换js文件
经过非常非常长无聊的流程,只是将获取到的module信息做了一些缓存,然后生成了loaderContext对象. 这里上个图整理一下这节的流程: 这一节来看webpack是如何将babel-loade ...
- .34-浅析webpack源码之事件流make(3)
新年好呀~过个年光打游戏,function都写不顺溜了. 上一节的代码到这里了: // NormalModuleFactory的resolver事件流 this.plugin("resolv ...
- .3-浅析webpack源码之预编译总览
写在前面: 本来一开始想沿用之前vue源码的标题:webpack源码之***,但是这个工具比较巨大,所以为防止有人觉得我装逼跑来喷我(或者随时鸽),加上浅析二字,以示怂. 既然是浅析,那么案例就不必太 ...
- 从Webpack源码探究打包流程,萌新也能看懂~
简介 上一篇讲述了如何理解tapable这个钩子机制,因为这个是webpack程序的灵魂.虽然钩子机制很灵活,而然却变成了我们读懂webpack道路上的阻碍.每当webpack运行起来的时候,我的心态 ...
- .30-浅析webpack源码之doResolve事件流(1)
这里所有的插件都对应着一个小功能,画个图整理下目前流程: 上节是从ParsePlugin中出来,对'./input.js'入口文件的路径做了处理,返回如下: ParsePlugin.prototype ...
- .27-浅析webpack源码之事件流make(2)
上一节跑到了NormalModuleFactory模块,调用了原型方法create后,依次触发了before-rsolve.factory.resolver事件流,这节从resolver事件流开始讲. ...
随机推荐
- Core Graphics 和Quartz 2D的区别
quartz是一个通用的术语,用于描述在IOS和MAC OS X中整个媒体层用到的多种技术 包括图形.动画.音频.适配. Quart 2D 是一组二位绘图和渲染API,Core Graphic会使用 ...
- HTML怎么设置字与字之间的间距代替空格
空格:   CSS: letter-spacing字与字 word-spacing词与词 行距:line-height:1.5; 段落:<p style="margin ...
- Jpa 本地方式实现数据的持久化【千锋】
Jpa本身支持多种方式的对象持久化,比如数据库方式,还有一种方式就是本地文件的方式,本文来讲解以本地方式实现的数据持久化,具体的资源大家可以参阅一下网站:http://www.objectdb.com ...
- linu_nginx_location语法
location的作用是什么? 每个server中都需要配置location,通过location匹配域名后内容,再通过location响应同一个域名下不同请求 location语法 location ...
- python_如何定义带参数的装饰器?
案例: 实现一个装饰器,用它来检查被装饰函数的参数类型. 需求: 装饰器可以通过函数,指明函数参数类型,进行函数调用的时候,传入参数,检测到不匹配时,抛出异常 如何解决这个问题? 先要获取函数的签名, ...
- vs2005配置OpenCv2.3.1
编译OpenCv 1 用CMake导出VC++项目文件 运行cmake-gui,设置where is the source code路径为OpenCV安装路径(本文档假定安装位置为:c:\OpenCV ...
- secureCRT sftp使用
sftp-- help 可用命令: cd 路径 更改远程目录到"路径" lcd 路径 更改本地目录到"路径" chgrp group path 将文件" ...
- Spring 4.x (三)
1 Spring中加入DataSource并引入jdbc.properties 步骤: ①加入c3p0的jar包和mysql的驱动包 ②在src下新建jdbc.propertes文件 jdbc.dri ...
- sed,n,N,d,D,p,P,h,H,g,G,x,解析
原文地址 这篇文章主要是我参考命令的,直接复制粘贴,有问题请拍砖 A. sed执行模板=sed '模式{命令1;命令2}' 即逐行读入模式空间,执行命令,最后输出打印出来 B. p打印当前模式空间所有 ...
- redis数据类型-散列类型
Redis数据类型 散列类型 Redis是采用字典结构以键值对的形式存储数据的,而散列类型(hash)的键值也是一种字典结构,其存储了字段(field)和字段值的映射,但字段值只能是字符串,不支持其他 ...