用线性单元(LinearUnit)实现工资预测的Python3代码
功能:通过样本进行训练,让线性单元自己找到(这就是所谓机器学习)工资计算的规律,然后用两组数据进行测试机器是否真的get到了其中的规律。
原文链接在文尾,文章中的代码为了演示起见,仅根据工作年限来预测工资,参数是一维的,最后绘制的图也是平面图。本着学习的态度,我将代码改为能根据两个参数来预测工资,两个参数分别是工作年限和级别,并且用3D图绘制出拟合的效果。原作者的代码是适用于Python2.7的,我的代码适用于Python3,谨供参考。
注意:绘图代码需要安装matplotlib。
代码:
#!/usr/bin/env python
# -*- coding: UTF-8 -*- from Perceptron import Perceptron #定义激活函数f
f = lambda x: x class LinearUnit(Perceptron):
def __init__(self, input_num):
'''初始化线性单元,设置输入参数的个数'''
Perceptron.__init__(self, input_num, f) def get_training_dataset():
'''
捏造5个人的收入数据
'''
# 构建训练数据
# 输入向量列表,每一项的第一个是工作年限,第二个是级别
# 构造这些数据所用的公式是:工资=1000*年限 + 500*级别,看机器是否能猜出来
input_vecs = [[5,1], [3, 7], [8,2], [1.5,5], [10,6]]
# 期望的输出列表,月薪,注意要与输入一一对应。【注意! 我故意让结果不太准确,这也会导致预测的结果有偏差】
labels = [5200, 6700, 9300, 3500, 15500]
return input_vecs, labels def train_linear_unit():
'''
使用数据训练线性单元
'''
# 创建感知器,输入参数的特征数为2(工作年限,级别)
lu = LinearUnit(2)
# 训练,迭代10轮, 学习速率为0.005
input_vecs, labels = get_training_dataset()
lu.train(input_vecs, labels, 10, 0.005)
#返回训练好的线性单元
return lu def plot(linear_unit):
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
input_vecs, labels = get_training_dataset()
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(list(map(lambda x: x[0], input_vecs)),
list(map(lambda x: x[1], input_vecs)),
labels) weights = linear_unit.weights
bias = linear_unit.bias
x = range(0,12,1) # work age
y = range(0,12,1) # level
x, y = np.meshgrid(x, y)
z = weights[0] * x + weights[1] * y + bias
ax.plot_surface(x, y, z, cmap=plt.cm.winter) plt.show() if __name__ == '__main__':
'''训练线性单元'''
linear_unit = train_linear_unit()
# 打印训练获得的权重
#print (linear_unit)
# 测试
print ('预测:')
print ('Work 3.4 years, level 2, monthly salary = %.2f' % linear_unit.predict([3.4,2]))
print ('Work 15 years, level 6, monthly salary = %.2f' % linear_unit.predict([15,6]))
plot(linear_unit)
为了代码的正常运行,你可能还需要下面这个感知机的类文件,另存为Perceptron.py(注意大小写),和上面的代码放在同一个目录下即可。
#coding=utf-8 from functools import reduce # for py3 class Perceptron(object):
def __init__(self, input_num, activator):
'''
初始化感知器,设置输入参数的个数,以及激活函数。
激活函数的类型为double -> double
'''
self.activator = activator
# 权重向量初始化为0
self.weights = [0.0 for _ in range(input_num)]
# 偏置项初始化为0
self.bias = 0.0
def __str__(self):
'''
打印学习到的权重、偏置项
'''
return 'weights\t:%s\nbias\t:%f\n' % (self.weights, self.bias) def predict(self, input_vec):
'''
输入向量,输出感知器的计算结果
'''
# 把input_vec[x1,x2,x3...]和weights[w1,w2,w3,...]打包在一起
# 变成[(x1,w1),(x2,w2),(x3,w3),...]
# 然后利用map函数计算[x1*w1, x2*w2, x3*w3]
# 最后利用reduce求和 #list1 = list(self.weights)
#print ("predict self.weights:", list1) return self.activator(
reduce(lambda a, b: a + b,
list(map(lambda tp: tp[0] * tp[1],
zip(input_vec, self.weights)))
, 0.0) + self.bias)
def train(self, input_vecs, labels, iteration, rate):
'''
输入训练数据:一组向量、与每个向量对应的label;以及训练轮数、学习率
'''
for i in range(iteration):
self._one_iteration(input_vecs, labels, rate) def _one_iteration(self, input_vecs, labels, rate):
'''
一次迭代,把所有的训练数据过一遍
'''
# 把输入和输出打包在一起,成为样本的列表[(input_vec, label), ...]
# 而每个训练样本是(input_vec, label)
samples = zip(input_vecs, labels)
# 对每个样本,按照感知器规则更新权重
for (input_vec, label) in samples:
# 计算感知器在当前权重下的输出
output = self.predict(input_vec)
# 更新权重
self._update_weights(input_vec, output, label, rate) def _update_weights(self, input_vec, output, label, rate):
'''
按照感知器规则更新权重
'''
# 把input_vec[x1,x2,x3,...]和weights[w1,w2,w3,...]打包在一起
# 变成[(x1,w1),(x2,w2),(x3,w3),...]
# 然后利用感知器规则更新权重
delta = label - output
self.weights = list(map( lambda tp: tp[1] + rate * delta * tp[0], zip(input_vec, self.weights)) ) # 更新bias
self.bias += rate * delta print("_update_weights() -------------")
print("label - output = delta:" ,label, output, delta)
print("weights ", self.weights)
print("bias", self.bias) def f(x):
'''
定义激活函数f
'''
return 1 if x > 0 else 0 def get_training_dataset():
'''
基于and真值表构建训练数据
'''
# 构建训练数据
# 输入向量列表
input_vecs = [[1,1], [0,0], [1,0], [0,1]]
# 期望的输出列表,注意要与输入一一对应
# [1,1] -> 1, [0,0] -> 0, [1,0] -> 0, [0,1] -> 0
labels = [1, 0, 0, 0]
return input_vecs, labels def train_and_perceptron():
'''
使用and真值表训练感知器
'''
# 创建感知器,输入参数个数为2(因为and是二元函数),激活函数为f
p = Perceptron(2, f)
# 训练,迭代10轮, 学习速率为0.1
input_vecs, labels = get_training_dataset()
p.train(input_vecs, labels, 10, 0.1)
#返回训练好的感知器
return p if __name__ == '__main__':
# 训练and感知器
and_perception = train_and_perceptron()
# 打印训练获得的权重 # 测试
print (and_perception)
print ('1 and 1 = %d' % and_perception.predict([1, 1]))
print ('0 and 0 = %d' % and_perception.predict([0, 0]))
print ('1 and 0 = %d' % and_perception.predict([1, 0]))
print ('0 and 1 = %d' % and_perception.predict([0, 1]))
正常运行的话,输出的预测结果是这样的:
预测:
Work 3.4 years, level 2, monthly salary = 5125.02
Work 15 years, level 6, monthly salary = 20815.01
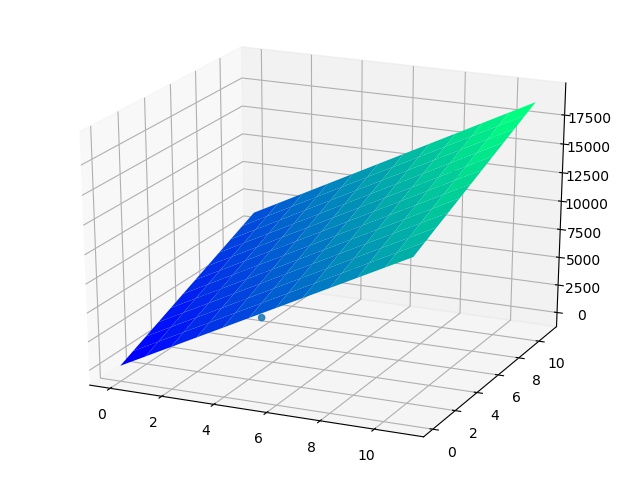
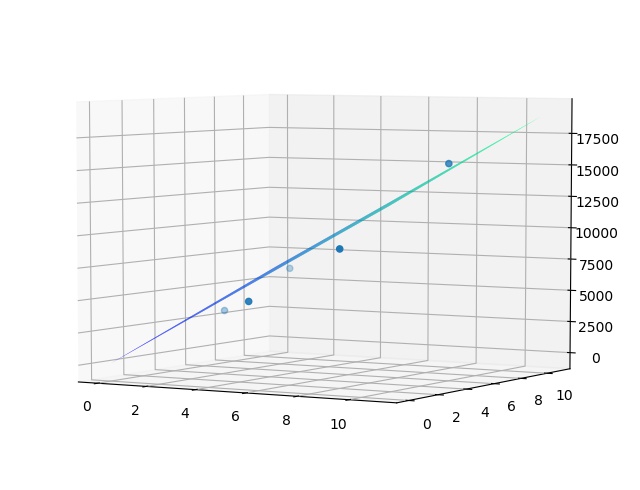
由上可见,本例中两个输入一个输出的线性单元拟合出来的是一个平面(因为预设的工资公式是线性的)。在旋转一个角度后看的更清楚:
原文链接:
https://www.zybuluo.com/hanbingtao/note/448086
文章写的很好,代码也漂亮,墙裂推荐大家看看原文。
用线性单元(LinearUnit)实现工资预测的Python3代码的更多相关文章
- (2)Deep Learning之线性单元和梯度下降
往期回顾 在上一篇文章中,我们已经学会了编写一个简单的感知器,并用它来实现一个线性分类器.你应该还记得用来训练感知器的『感知器规则』.然而,我们并没有关心这个规则是怎么得到的.本文通过介绍另外一种『感 ...
- 感知机和线性单元的C#版本
本文的原版Python代码参考了以下文章: 零基础入门深度学习(1) - 感知器 零基础入门深度学习(2) - 线性单元和梯度下降 在机器学习如火如荼的时代,Python大行其道,几乎所有的机器学习的 ...
- ReLu(修正线性单元)、sigmoid和tahh的比较
不多说,直接上干货! 最近,在看论文,提及到这个修正线性单元(Rectified linear unit,ReLU). Deep Sparse Rectifier Neural Networks Re ...
- 修正线性单元(Rectified linear unit,ReLU)
修正线性单元(Rectified linear unit,ReLU) Rectified linear unit 在神经网络中,常用到的激活函数有sigmoid函数f(x)=11+exp(−x).双曲 ...
- 量化投资_MATLAB在时间序列建模预测及程序代码
1 ARMA时间序列机器特性 下面介绍一种重要的平稳时间序列——ARMA时间序列. ARMA时间序列分为三种: AR模型,auto regressiv model MA模型,moving averag ...
- 修正剑桥模型预测-用python3.4
下面是预测结果: #!/usr/bin/env python # -*- coding:utf-8 -*- # __author__ = "blzhu" ""& ...
- 基于深度学习方法的dota2游戏数据分析与胜率预测(python3.6+keras框架实现)
很久以前就有想过使用深度学习模型来对dota2的对局数据进行建模分析,以便在英雄选择,出装方面有所指导,帮助自己提升天梯等级,但苦于找不到数据源,该计划搁置了很长时间.直到前些日子,看到社区有老哥提到 ...
- kaggle预测房价的代码步骤
# -*- coding: utf-8 -*- """ Created on Sat Oct 20 14:03:05 2018 @author: 12958 " ...
- 用python实现MRO算法
引子: 如图反映了python3中,几个类的继承关系和查找顺序.对于类A,其查找顺序为:A,B,E,C,F,D,G,(Object),这并不是一个简单的深度优先或广度优先的规律.那么这个顺序到底是如何 ...
随机推荐
- 无废话XML--XML解析(DOM和SAX)
XML处理模式 处理XML有2种方式,DOM和SAX.一般的实际开发中,这2种使用的不多,直接用dom4j来解析XML就好了,包括CRUD等操作都很方便的.这里介绍的DOM和SAX是比较底层的,具体的 ...
- jsp的语法
JSP指令和脚本元素指令 <%@ 指令%>声明 <%! 声明%>表达式 <%= 表达式%>代码段/脚本段 <% 代码段%>注释 <%-- 注释-- ...
- LAMP_yum安装
前言,人总是会越来越懒,说真的,我是摸着良心说话的 开始总是喜欢源码安装,因为可以定制,而且能显得有格调(逼格),但是一安装就要半天,还有各种依赖包的安装,各种报错,不忍直视 下面是我摘自晚上的一篇l ...
- Apache Traffic Server服务搭建
一.简介 Apache Traffic Server(ATS或TS)是一个高性能的.模块化的HTTP代理和缓存服务器,与 Nginx 和 Squid 类似.它通过将频繁访问的信息缓存在网络的边缘来改善 ...
- 面试中的Java链表
链表作为常考的面试题,并且本身比较灵活,对指针的应用较多.本文对常见的链表面试题Java实现做了整理. 链表节点定义如下: static class Node { int num; Node next ...
- LOJ #116 有源汇点有上下界的最大流
先连一条从汇点到源点的容量为INF的边,将其转化成无源汇点有上下界的可行流,判断是否可行 若可行的话删掉超级源点和超级汇点,再跑一遍最大流即可 #include <iostream> #i ...
- BZOJ 2754: [SCOI2012]喵星球上的点名 [后缀数组+暴力]
2754: [SCOI2012]喵星球上的点名 Time Limit: 20 Sec Memory Limit: 128 MBSubmit: 1906 Solved: 839[Submit][St ...
- POJ1556 The Doors [线段相交 DP]
The Doors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 8334 Accepted: 3218 Descrip ...
- 输入url到渲染出页面的过程
输入地址 浏览器查找域名的 IP 地址 这一步包括 DNS 具体的查找过程,包括:浏览器缓存->系统缓存->路由器缓存... 浏览器向 web 服务器发送一个 HTTP 请求 服务器的永久 ...
- Java数据结构和算法(十五)——无权无向图
前面我们介绍了树这种数据结构,树是由n(n>0)个有限节点通过连接它们的边组成一个具有层次关系的集合,把它叫做“树”是因为它看起来像一棵倒挂的树,包括二叉树.红黑树.2-3-4树.堆等各种不同的 ...