kaggle入门项目:Titanic存亡预测(二)数据处理
原kaggle比赛地址:https://www.kaggle.com/c/titanic
原kernel地址:A Data Science Framework: To Achieve 99% Accuracy
问题处理之前要知道的事:
数据科学框架(A Data Science Framework)
1.定义问题(Define the Problem):
问题→需求→方法→设计→技术,这是刚开始拿到问题的解决流程,所以在我们用一些fancy的技巧和算法解决问题之前,必须要明确我们需要解决的问题到底是什么
2.获取数据:
从dirty data转换到clean data 的方法。
3.数据处理准备(Prepare Data for Consumption):
不太清楚如何准确的翻译Prepare Data for Consumption,但是根据此kernel的解释。就是数据整理,简单的说就是把“野生”数据转换成“被驯服”的数据,将数据整理成适合存储和处理的数据架构,输的提取、数据清理、处理异常、缺失、离群的数据点。
4:探索性数据分析(Perform Exploratory Analysi):
GIGO,减少无意义的输入才能提升输出的质量,所以使用图表、数据显示等可视化方法才能发现潜在的问题与feature、feature 之前的关联度。同样,数据分类也利于理解选择合适的数据模型。
5:数据建模(Model Data):
知道如何针对该问题选取合适的工具(tool),差的模型导致差的结论,毋庸置疑。
6:验证与实现数据模型(Validate and Implement Data Model):
这一步确保没有过拟合(overfit)——训练集上性能出众,测试集上抓瞎。
7:优化与策略(Optimize and Strategize):
通过迭代提升性能。
接下来就通过这七步来逐一分析Titanic号问题。
Step 1:Define the Problem
Titanic号的悲剧发生于1912年4月15日,2224名乘客中死亡1502人,举世震惊。我们的这次的问题就是通过Titanic的乘客信息来预测该乘客的生还可能。
知识点:二元分类问题,Pyhton或R语言(该kernel使用Pyhton)
Step 2:Gather the Data
https://www.kaggle.com/c/titanic/data (Titanic数据集下载)
Step 3:Prepare Data for Consumption
3.11 Load Data Modelling Libraies
数据清理,所需Python包已包含在kernel中
需要注意的是作者使用的是python3,在之前的学习中我使用的Pyhton2.7,因此我卸载了所有的python环境与老版本的各种包,直接下载了anaconda3.6版本一步到位。在这里还是推荐大家使用python3进行数据分析,他比python2更规范,更先进。
3.2 Meet and Great Data
通过数据集feature的名字与解释来了解具体属性,通过info()和sample()函数获取feature信息,需要注意的有以下几点:
1.Survived列是需要输出的,二元变量,1代表存活,0代表死亡。其他features是为了学习与预测提供的。注意:features多并不一定是好事,选择合适的features才重要。
2.PassengerID与Ticket列是随机的唯一标识符,对预测没有贡献,直接除去。
3.Pclass是仓位等级,贡献较大我们将其以1,2,3代替。
4.Name列看上去没什么用处,其实我们可以通过名字的title确定性别、家庭规模、及其社会地位。
5.Sex和Embarked可以转换为dummy variables——虚拟变量,便于模型构造
6.Age和Fare,连续变量。
7.SibSp代指兄弟姐妹同船人数,Parch代指父母同船人数,这两个属性可以巧妙的合成家庭大小,对预测很有帮助。
8.Cabin列的缺失实在是太多了,这种情况我们直接删除之。
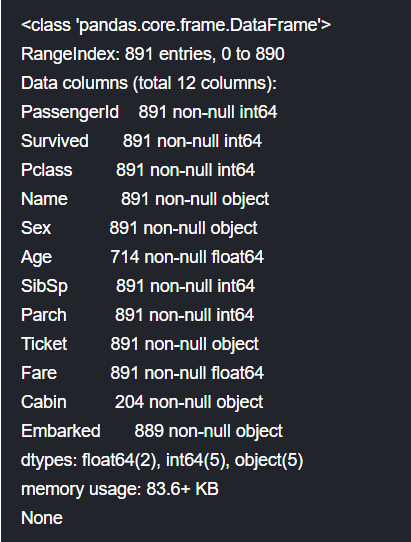
我们发现数据的缺失并不算多,但是为了模型训练,我们必须进行缺失数据处理,随后讨论。
3.21 The 4 C's of Data Cleaning: Correcting, Completing, Creating, and Converting
数据清理的4C要义:
1.Correcting 准确性:简单的例子,如果Age里本应该是80却错标成800,这就出现了incorrect。
2.Completing完整性:有些算法没法处理丢失信息,所以当然要进行丢失数据处理啦。
两种常用方法:要么删除要么填充,不建议删除,因为很多feature含有大量信息,简单删除后肯定会产生bias。填充的话一边使用均值、中位数或者均值+随机化标准偏差。
3.Creating创造性:用现有数据产生新数据集,用我一个师兄的话就是靠脑洞!当然这是比较调侃的说法,有很多creat feature的方法可以参考,作为初学者我也并未深入学习,待到以后有所心得了再来分享。
4.Converting数据转换:用此kernel 的话说是数据格式化,因为分类的数据并不适合算法计算,因此我们引入dummy variables,于此相关的还有One-hot编码。
3.22 Clean Data
作者使用了pandas 的fillna()方法对数据集中的空值进行填充:
对于连续变量,例如Age、Fare使用中位数进行填充median(),至于为什么不使用平均数进行填充是因为有很多离群点会对数据造成干扰,中位数更能代表大多数数据的中指,这会在后来的数据可视化分析上体现。
对于分类型变量例如Embarked,使用众数进行填充mode()[0],毕竟当我们不知道某一row属于何种类别的时候将其归类为概率较高的类别是合理的。
接着使用
dataset['FamilySize'] = dataset ['SibSp'] + dataset['Parch'] + 1
构造了家庭大小数属性。
添加IsAlone属性标识是否一人登船。
从Name属性中提取Title,因为我们发现所有的名字几乎都含有title,就是Mr、Miss等称呼
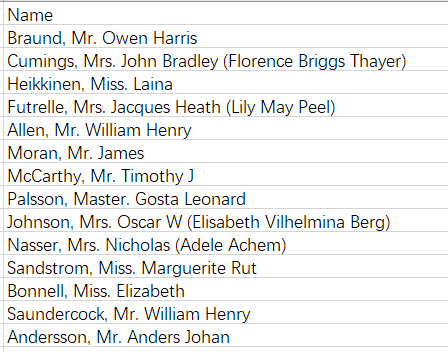
因此我们提取(,)与(.)之间的元素,构成Title属性,该属性隐藏着性别与社会地位等信息。
我们构建FareBin和AgeBin将船票价格和年龄分成几个不同的等级,使得连续数据集更好的适应算法。这里用到了pandas的qcut()和cut()函数。
3.23 Convert Formats
将分类的变量转换为dummy variables,所谓dummy变量就是用0或1来表示该属性是否出现,我们可以发现处理后的data1_dummy出现了Embarked_C、Embarked_Q、Embarked_S等等dummy变量,应该很好理解了。
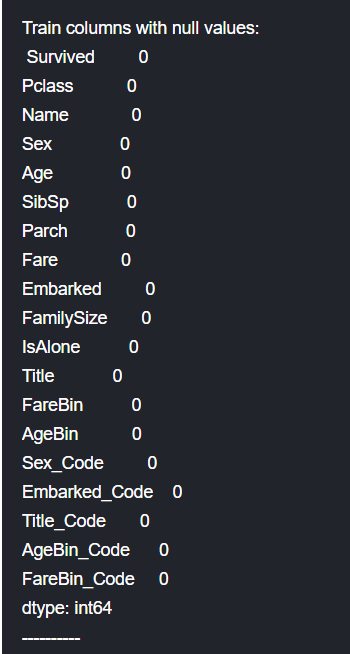
3.24 Da-Double Check Cleaned Data
再次确认数据处理结果,cleaning Done!
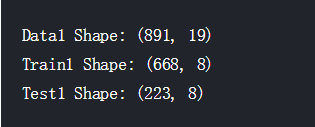
3.25 Split Training and Testing Data
接下来分割数据集,我们将训练数据集以75/25的比例分割为新的训练集和验证集,验证集的存在是为了保证我们不过拟合。使用的函数是sklearn中的model_selection.train_test_split(),在没有制定该函数的分割比例的情况下默认进行75/25的分割。
未完待续~
kaggle入门项目:Titanic存亡预测(二)数据处理的更多相关文章
- kaggle入门项目:Titanic存亡预测 (一)比赛简介
自从入了数据挖掘的坑,就在不停的看视频刷书,但是总觉得实在太过抽象,在结束了coursera上Andrew Ng 教授的机器学习课程还有刷完一整本集体智慧编程后更加迷茫了,所以需要一个实践项目来扎实之 ...
- kaggle入门项目:Titanic存亡预测(四)模型拟合
原kaggle比赛地址:https://www.kaggle.com/c/titanic 原kernel地址:A Data Science Framework: To Achieve 99% Accu ...
- kaggle入门项目:Titanic存亡预测(三)数据可视化与统计分析
---恢复内容开始--- 原kaggle比赛地址:https://www.kaggle.com/c/titanic 原kernel地址:A Data Science Framework: To Ach ...
- kaggle入门题Titanic
集成开发环境:Pycharm python版本:2.7(anaconda库) 用到的库:科学计算库numpy,数据分析包pandas,画图包matplotlib,机器学习库sklearn 大体步骤分为 ...
- Kaggle入门——使用scikit-learn解决DigitRecognition问题
Kaggle入门--使用scikit-learn解决DigitRecognition问题 @author: wepon @blog: http://blog.csdn.net/u012162613 1 ...
- Kaggle入门——泰坦尼克号生还者预测
前言 这个是Kaggle比赛中泰坦尼克号生存率的分析.强烈建议在做这个比赛的时候,再看一遍电源<泰坦尼克号>,可能会给你一些启发,比如妇女儿童先上船等.所以是否获救其实并非随机,而是基于一 ...
- SpringCloud学习之手把手教你用IDEA搭建入门项目(二)
本篇博客是承接上一篇<手把手教你用IDEA搭建SpringCloud入门项目(一)>,不清楚的请到我的博客空间查看后再看本篇博客 1)先创建一个Eureka服务注册中心模块,用来作为服务的 ...
- Kaggle入门
Kaggle入门 1:竞赛 我们将学习如何为Kaggle竞赛生成一个提交答案(submisson).Kaggle是一个你通过完成算法和全世界机器学习从业者进行竞赛的网站.如果你的算法精度是给出数据集中 ...
- TensorFlow 入门之手写识别(MNIST) 数据处理 一
TensorFlow 入门之手写识别(MNIST) 数据处理 一 MNIST Fly softmax回归 准备数据 解压 与 重构 手写识别入门 MNIST手写数据集 图片以及标签的数据格式处理 准备 ...
随机推荐
- Chipmunk碰撞回调短时间内重入的解决办法
Chipmunk引擎中碰撞行为可能在细微处与一般认识略有不同. 比如碰撞回调方法可能会重入.不知道方法(函数)重入概念的童鞋可以自行谷哥或度娘. 第一次碰撞方法还未返回,第二次碰撞回调又被调用了.至于 ...
- Python学习笔记 - 字符串和编码
#!/usr/bin/env python3 # -*- coding: utf-8 -*- #第一行注释是为了告诉Linux/OS X系统, #这是一个Python可执行程序,Windows系统会忽 ...
- 无法与域Active Directory域控制器(AD DC)连接(虚机加域出错问题)
今天建了两台虚机用的VMWARE,一台做域控,一台做应用服务器,但是部署好域控要把应用服务器加入域时候报错 虚机网卡设置桥接并设置好IP使两台虚机在同一个局域网内,通过ip地址互ping能ping通, ...
- 关于jQuery中的trigger和triggerHandler方法的使用
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Java图形界面编程生成exe文件
1. 先将代码打成jar,然后使用exe4j转成exe ext4j下载 链接:http://pan.baidu.com/s/1kTCIZtX 密码:pvj1 打开EXE4J Advanced Opti ...
- 程序员的视角:java 线程
在我们开始谈线程之前,不得不提下进程. 无论进程还是线程都是很抽象的概念,有一个关于进程和线程很形象的比喻能帮我们更好的理解. 进程就像个房子,房子是一个包含了特定属性的容器,例如空间大小.卧室数量等 ...
- iOS中关于UIApplication的详细介绍
UIApplication 什么是UIApplication? UIApplication对象是应用程序的象征.每一个应用都有自己的UIApplication对象,这个对象是系统自动帮我们创建的, 它 ...
- "《算法导论》之‘图’":单点最短路径(有向图)
也许最直观的图处理问题就是你常常需要使用某种地图软件或者导航系统来获取从一个地方到另一个地方的路径.我们立即可以得到与之对应的图模型:顶点对应交叉路口,边对应公路,边的权重对应该路段的成本(时间或距离 ...
- C# DataTable,DataSet,IList,IEnumerable 互转扩展属性
using System; using System.Collections.Generic; using System.Data; using System.Linq; using System.R ...
- LeetCode(41)-Rectangle Area
题目: Find the total area covered by two rectilinear rectangles in a 2D plane. Each rectangle is defin ...