分布式缓存管理平台XXL-CACHE
《分布式缓存管理平台XXL-CACHE》
一、简介
1.1 概述
XXL-CACHE是一个分布式缓存管理平台,其核心设计目标是“让分布式缓存的接入和管理的更加的简洁和高效”。现已开放源代码,开箱即用。
XXL-CACHE核心思想:将分布式缓存抽象成公共RPC服务,对外提供公共API进行缓存操作; 提供缓存公共的管理和监控平台:方便的查询、管理和监控线上缓存数据;
1.2 特性
- 1、多种缓存支持:支持Redis、Memcached两种缓存在线的查询和管理;
- 2、分布式缓存管理:支持分布式环境下,集群缓存服务的查询和管理,自动命中缓存服务节点;
- 3、方便:支持通过Web界管理缓存模板,查询和管理缓存数据;
- 4、透明:集群节点变动时,缓存命中的分片逻辑保持线上一致,自动命中缓存数据;
- 5、查看序列化缓存数据:通常缓存中保存的是序列化的Java数据,因此当需要查看缓存键值数据非常麻烦,本系统支持方便的查看缓存数据内容,反序列化数据;
- 6、查看缓存数据长度:直观显示缓存数据的长度;
- 7、查看缓存JSON格式内容:支持将缓存数据转换成JSON格式,直观查看缓存数据内容;
1.3 下载
文档地址
源码仓库地址
| 源码仓库地址 | Release Download |
|---|---|
| https://github.com/xuxueli/xxl-cache | Download |
| http://gitee.com/xuxueli0323/xxl-cache | Download |
技术交流
1.4 环境
- Maven3+
- Jdk1.7+
- Tomcat7+
- Mysql5.5+
二、快速入门
2.1 初始化“数据库”
请下载项目源码并解压,获取 "调度数据库初始化SQL脚本"(脚本文件为: 源码解压根目录/xxl-cache/doc/db/xxl-cache-mysql.sql) 并执行即可。
2.2 编译源码
解压源码,按照maven格式将源码导入IDE, 使用maven进行编译即可,源码结构如下图所示:

- xxl-cache-admin:缓存管理平台
- xxl-cache-core:公共依赖,为缓存服务抽象成公共RPC服务做准备
2.3 配置部署“缓存管理平台”
项目:xxl-cache-admin
作用:查询和管理线上分布式缓存数据
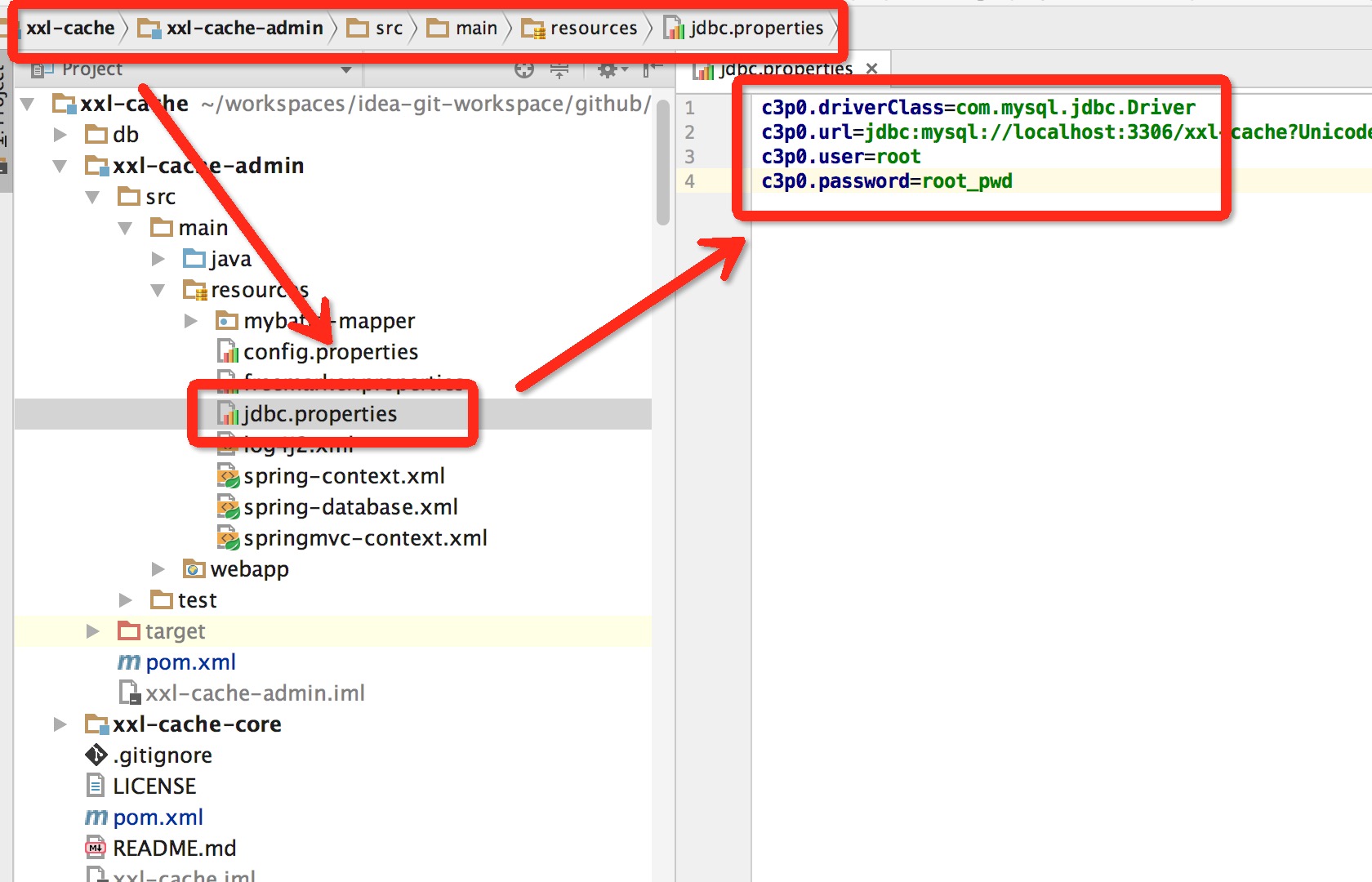
- A:配置“JDBC链接”:请在下图所示位置配置jdbc链接地址,链接地址请保持和 2.1章节 所创建的调度数据库的地址一致。
- B:配置“分布式缓存配置”:请在下图所示位置配置分布树缓存信息,和线上项目中缓存配置务必保持一致。
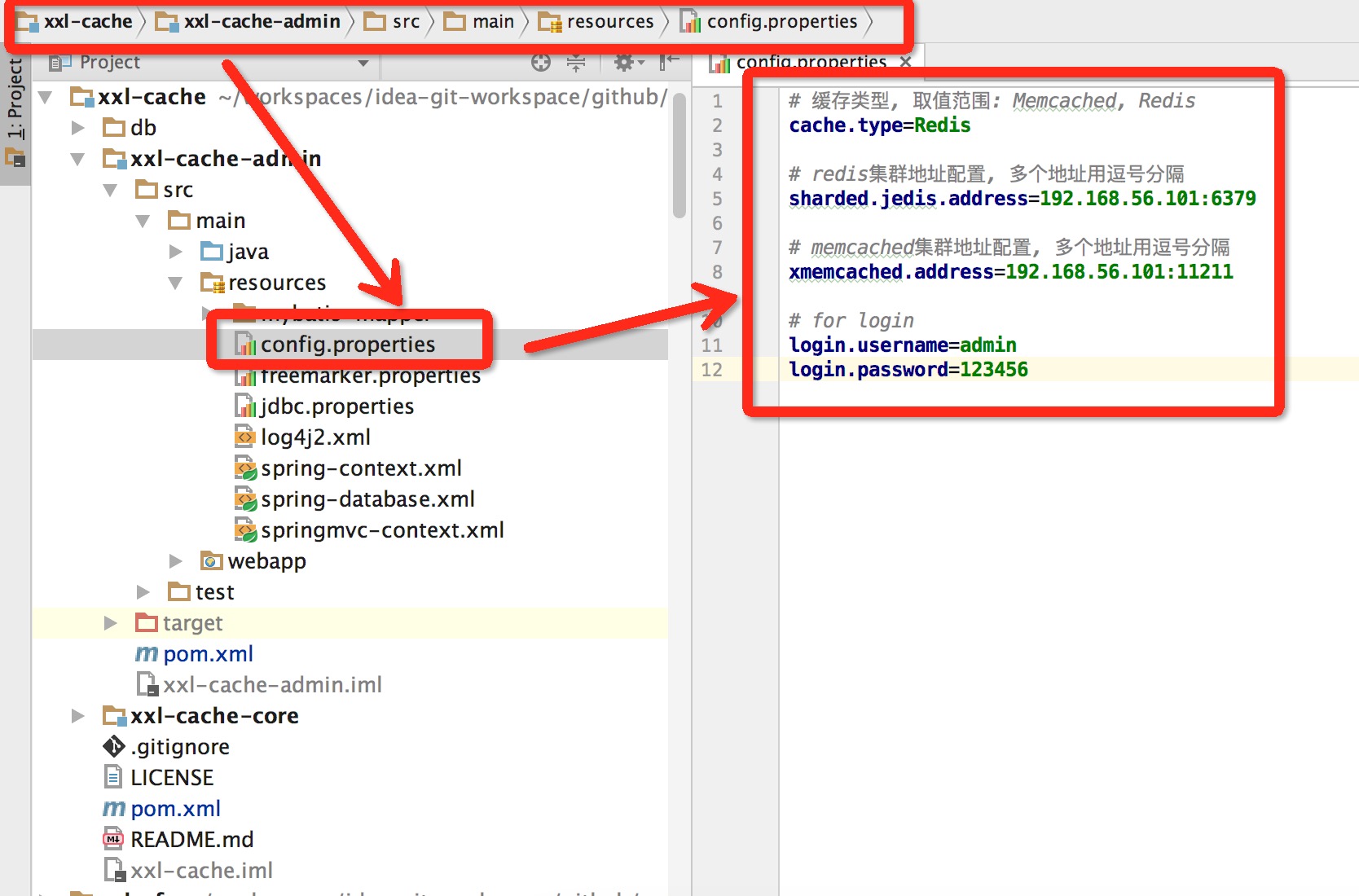
配置详解:
# 缓存类型, 取值范围: Memcached, Redis;(如配置Redis,则Redis地址生效,Memcached配置则被忽略,可删除)
cache.type=Redis
# redis集群地址配置, 多个地址用逗号分隔(当cache.type为Redis时生效)
sharded.jedis.address=192.168.56.101:6379
# memcached集群地址配置, 多个地址用逗号分隔(当cache.type为Memcached时生效)
xmemcached.address=192.168.56.101:11211
# for login (登录账号)
login.username=admin
login.password=123456
2.4 查询线上缓存
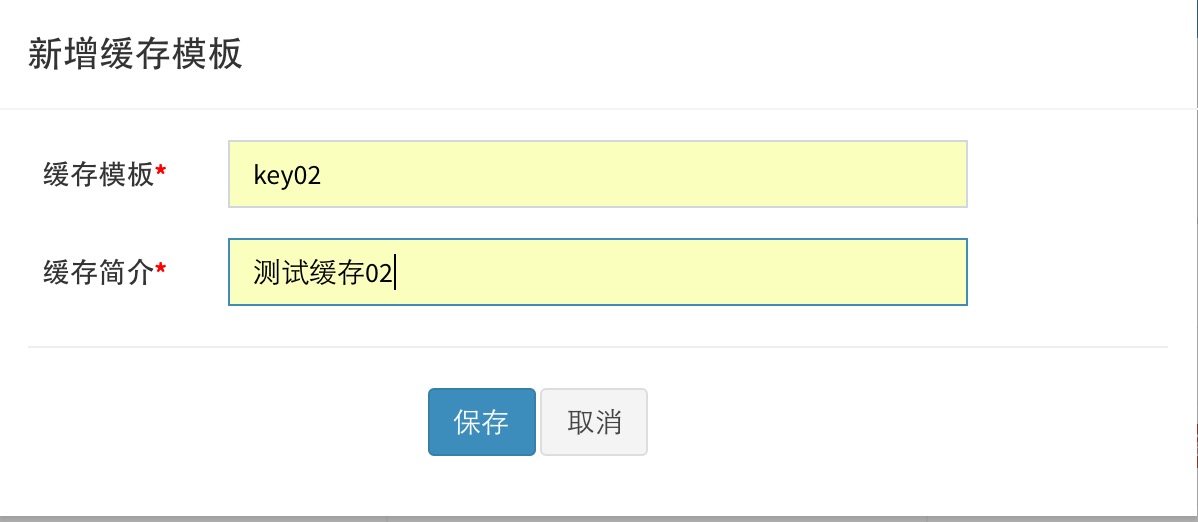
进入“缓存管理”界面,点击“新增缓存模板界面”,配置模板信息
然后,点击缓存模板右侧的“缓存操作”按钮
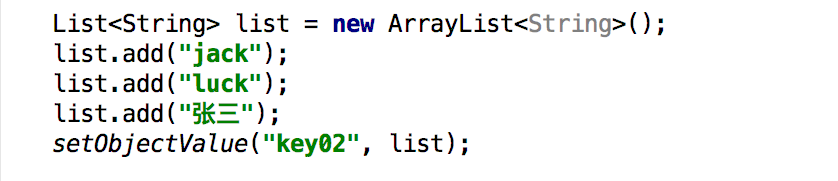
Set缓存数据,代码如下
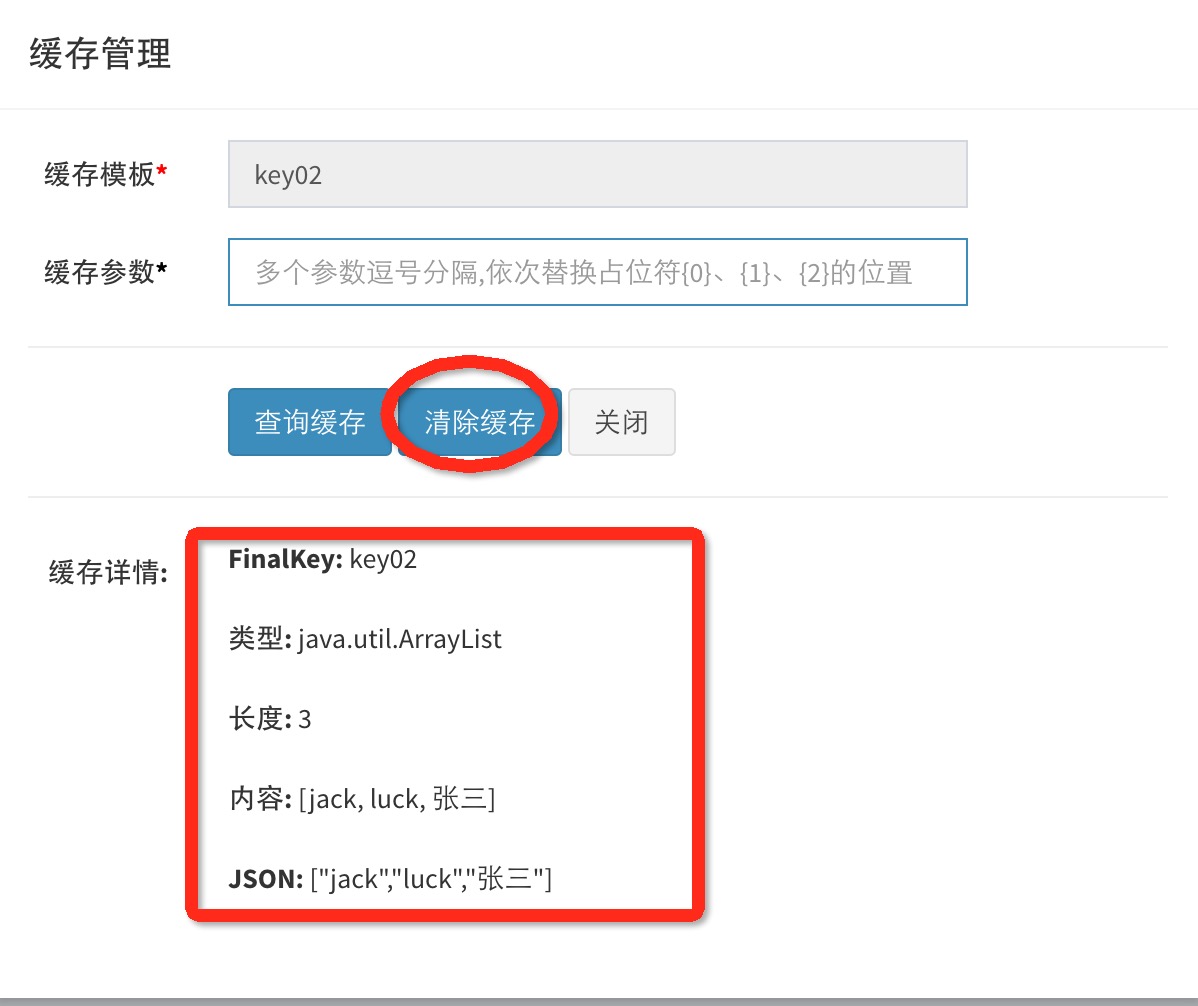
点击“查询缓存”,即可直观查看缓存信息
二、缓存模板详解
3.1 XXl-CACHE系统中常用名词(缓存属性)解释
缓存模板:生成缓存Key的模板,占位符用{0}、{1}、{2}依次替代;
缓存描述:缓存的描述说明;
缓存参数:“缓存模板”中占位符对应的参数,多个参数逗号分隔,依次替换占位符{0}、{1}、{2}的位置;
FinalKey:保存在分布式缓存服务中最终的Key的值,根据“缓存模板”和“缓存参数”生成;
四、缓存管理
略
五、总体设计
5.1 源码目录介绍
- /db :“数据库”建表脚本
- /xxl-cache-admin :缓存管理平台,项目源码;
- /xxl-cache-core : 公共依赖;(规划中)
5.2 核心思想
XXL-CACHE核心思想:
1、将分布式缓存抽象成公共RPC服务,对外提供公共API进行缓存操作:
- 1、项目接入缓存服务更加方便:接入方只需要依赖一个RPC服务的API即可;
- 2、统一监控和维护缓存服务;
- 3、方便控制client连接数量;
- 4、缓存节点变更更加方便;
- 5、在节点变更时, 缓存分片很大可能会受影响, 这将导致不同服务的分片逻辑出现不一致的情况, 统一缓存服务可以避免之;
- 6、可以屏蔽底层API操作,提供公共API,避免API误操作;
2、提供缓存管理和监控平台:方便的查询、管理和监控线上缓存数据;
规划中
- 1、支持遍历线上缓存, 比如Redis模式, 通过 keys * 获取线上所有缓存Key的列表;
六、历史版本
版本1.0.0
时间:2016年7月下旬;
特性:
- 1、多种缓存支持:支持Redis、Memcached两种缓存在线的查询和管理;
- 2、分布式缓存管理:支持分布式环境下,集群缓存服务的查询和管理,自动命中缓存服务节点;
- 3、方便:支持通过Web界管理缓存模板,查询和管理缓存数据;
- 4、透明:集群节点变动时,缓存命中的分片逻辑保持线上一致,自动命中缓存数据;
- 5、查看序列化缓存数据:通常缓存中保存的是序列化的Java数据,因此当需要查看缓存键值数据非常麻烦,本系统支持方便的查看缓存数据内容,反序列化数据;
- 6、查看缓存数据长度:直观显示缓存数据的长度;
- 7、查看缓存JSON格式内容:支持将缓存数据转换成JSON格式,直观查看缓存数据内容;
七、其他
7.1 报告问题
XXL-CACHE托管在Github上,如有问题可在 ISSUES 上提问,也可以加入上文技术交流群;
7.2 接入登记
更多接入公司,欢迎在github 登记
分布式缓存管理平台XXL-CACHE的更多相关文章
- 分布式逻辑管理平台XXL-GLUE
<分布式逻辑管理平台XXL-GLUE> 一.简介 1.1 概述 XXL-GLUE 是一个分布式环境下的 "可执行逻辑单元" 管理平台, 学习简单,扩展JVM的动态 ...
- HDFS集中式缓存管理(Centralized Cache Management)
Hadoop从2.3.0版本号開始支持HDFS缓存机制,HDFS同意用户将一部分文件夹或文件缓存在HDFS其中.NameNode会通知拥有相应块的DataNodes将其缓存在DataNode的内存其中 ...
- 分布式爬虫管理平台Crawlab安装与使用
Why,为什么需要爬虫管理平台? 以下摘自官方文档: Crawlab主要解决的是大量爬虫管理困难的问题,例如需要监控上百个网站的参杂scrapy和selenium的项目不容易做到同时管理,而且命令行管 ...
- .net 分布式架构之分布式缓存中间件
开源git地址: http://git.oschina.net/chejiangyi/XXF.BaseService.DistributedCache 分布式缓存中间件 方便实现缓存的分布式,集群, ...
- HDFS集中式的缓存管理原理与代码剖析--转载
原文地址:http://yanbohappy.sinaapp.com/?p=468 Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache ...
- HDFS集中式的缓存管理原理与代码剖析
转载自:http://www.infoq.com/cn/articles/hdfs-centralized-cache/ HDFS集中式的缓存管理原理与代码剖析 Hadoop 2.3.0已经发布了,其 ...
- Crawlab Lite 正式发布,更轻量的爬虫管理平台
Crawlab 是一款基于 Golang 的分布式爬虫管理平台,产品发布已经一年有余,经过开发团队的不断打磨,即将迭代到 v0.5 版本.在这期间我们为 Crawlab 加入了大量社区用户共同期望的功 ...
- 爬虫管理平台以及wordpress本地搭建
爬虫管理平台以及wordpress本地搭建 学习目标: 各爬虫管理平台了解 scrapydweb gerapy crawlab 各爬虫管理平台的本地搭建 Windows下的wordpress搭建 爬虫 ...
- NCache:最新发布的.NET平台分布式缓存系统
NCache:最新发布的.NET平台分布式缓存系统在等待Microsoft完成Velocity这个.NET平台下的分布式内存缓存系统的过程中,现在让我们将目光暂时投向其他已经有所建树的软件开发商.Al ...
随机推荐
- MinerThreadPool.java 线程池
MinerThreadPool.java 线程池 package com.iteye.injavawetrust.miner; import java.util.concurrent.Blocking ...
- Java集合之Collection
Java集合是java提供的工具包,包含了常用的数据结构:集合.链表.队列.栈.数组.映射等.Java集合工具包位置是java.util.* Java集合主要可以划分为4个部分:List列表.Set集 ...
- 用CSS指定外部链接的样式
大部分的信息类网站,比如维基百科,都会对外部链接(<a>标签)指定特定的样式.作为用户,一眼就知道该链接是指向另一个站点的资源是很好的体验.许多网站在服务器端做外部链接检查,添加一个`re ...
- Android 上滑上拉菜单SlidingDrawer 不全屏显示的方法
这里来说一个已经被废弃的SlidingDrawer.. 他可以实现上拉,下拉的菜单. 但是有个问题就是上拉以后,是全屏显示的. 首先 写一个布局: <RelativeLayout xmlns:a ...
- 在多台PC上进行ROS通讯-学习笔记
首先,致谢易科(ExBot)和ROSWiki中文社区. 重要参考文献: Running ROS across multiple machines http://wiki.ros.org/ROS/Tut ...
- linux下播放组播流出现setsockopt:No such device错误
在linux下播放组播流出现setsockopt:No such device错误是因为多播IP没有add路由表里面 可以采用如下命令完成: root@android:/ # busybox rout ...
- 什么是网络套接字(Socket)?
什么是网络套接字(Socket)?一时还真不好回答,而且网络上也有各种解释,莫衷一是.下文将以本人所查阅到的资料来说明一下什么是Socket. Socket定义 Socket在维基百科的定义: A n ...
- FPGrowth 实现
在关联规则挖掘领域最经典的算法法是Apriori,其致命的缺点是需要多次扫描事务数据库.于是人们提出了各种裁剪(prune)数据集的方法以减少I/O开支,韩嘉炜老师的FP-Tree算法就是其中非常高效 ...
- Leetcode_260_Single Number III
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/50276549 Given an array of numb ...
- how tomcat works 读书笔记 十一 StandWrapper 上
方法调用序列 下图展示了方法调用的协作图: 这个是前面第五章里,我画的图: 我们再回顾一下自从连接器里 connector.getContainer().invoke(request, resp ...