Python爬虫实践 -- 记录我的第二只爬虫
1、爬虫基本原理
我们爬取中国电影最受欢迎的影片《红海行动》的相关信息。其实,爬虫获取网页信息和人工获取信息,原理基本是一致的。

人工操作步骤:
1. 获取电影信息的页面
2. 定位(找到)到评分信息的位置
3. 复制、保存我们想要的评分数据
爬虫操作步骤:
1. 请求并下载电影页面信息
2. 解析并定位评分信息
3. 保存评分数据
综合言之,原理图如下:
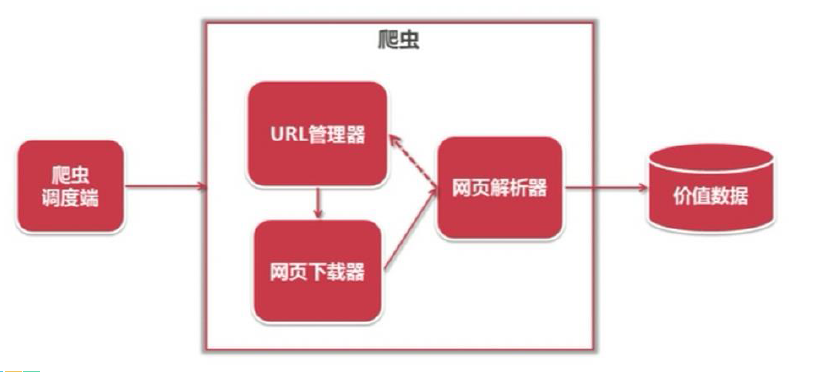
2、爬虫的基本流程
简单来说,我们向服务器发送请求后,会得到返回的页面;通过解析页面之后,我们可以抽取我们想要的那部分信息,并存储在指定的文档或数据库中。这样,我们想要的信息就被我们“爬”下来啦~

3、安装python依赖包 Requests+Xpath
Python 中爬虫相关的包很多:Urllib、requsts、bs4……我们从简单 requests+xpath 上手!更高级的 BeautifulSoup 还是有点难的。
然后我们安装 requests+xpath 的应用包以爬取豆瓣电影:
在Windows 终端分别输入以下两行代码:
pip install requestspip install lxml
4、代码整理--获取豆瓣电影目标网页并解析
我们要爬取豆瓣电影《红海行动》相关信息,目标地址是:https://movie.douban.com/subject/26861685/
给定 url 并用 requests.get() 方法来获取页面的text,用 etree.HTML() 来解析下载的页面数据“data”。
url = 'https://movie.douban.com/subject/26861685/' data = requests.get(url).text s=etree.HTML(data)
5、获取电影名称
获取元素的Xpath信息并获得文本:
file=s.xpath('元素的Xpath信息/text()')
这里的“元素的Xpath信息”是需要我们手动获取的,获取方式为:定位目标元素,在网站上依次点击:右键 > 检查
快捷键“shift+ctrl+c”,移动鼠标到对应的元素时即可看到对应网页代码:
在电影标题对应的代码上依次点击 右键 > Copy > Copy XPath,获取电影名称的Xpath:
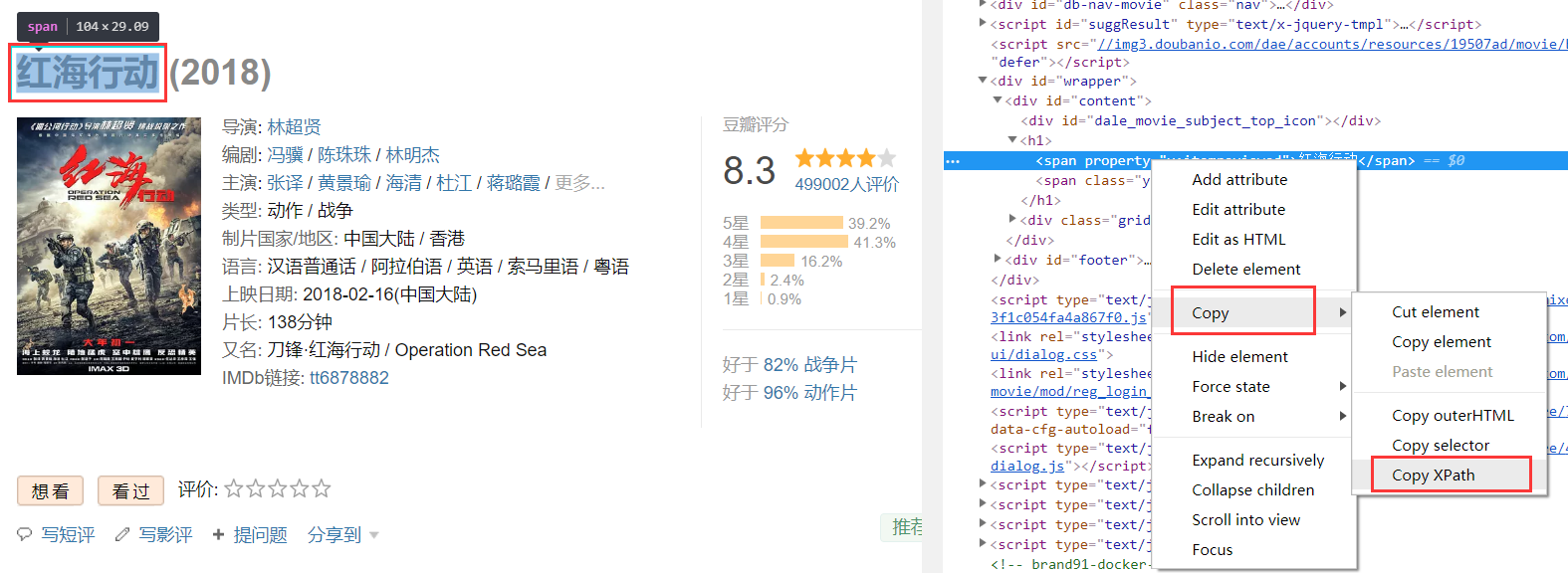
这样我们就把元素中的Xpath信息复制下来了:
//*[@id="content"]/h1/span[1]
放到代码中并打印信息:
film=s.xpath('//*[@id="content"]/h1/span[1]/text()')
print(film)
6、 代码以及运行结果
以上完整代码如下:
import requests from lxml
import etree url = 'https://movie.douban.com/subject/26861685/'
data = requests.get(url).text
s=etree.HTML(data)
film=s.xpath('//*[@id="content"]/h1/span[1]/text()') print (film)
在 Pycharm 中运行完整代码及结果如下:

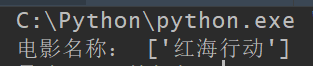
至此,我们完成了爬取豆瓣电影《红海行动》中“电影名称”信息的代码编写,可以在 Pycharm 中运行。
7、 获取其它元素信息
除了电影的名字,我们还可以获取导演、主演、电影片长等信息,获取的方式是类似的。代码如下:
director=s.xpath('//*[@id="info"]/span[1]/span[2]/a/text()') #导演
actor1=s.xpath('//*[@id="info"]/span[3]/span[2]/span[1]/a/text()') #主演1
actor2=s.xpath('//*[@id="info"]/span[3]/span[2]/span[2]/a/text()') #主演2
actor3=s.xpath('//*[@id="info"]/span[3]/span[2]/span[3]/a/text()') #主演3
time=s.xpath(‘//*[@id="info"]/span[12]/text()') #电影片长
观察上面的代码,发现获取不同“主演”信息时,区别只在于“span[x]”中“x”的数字大小不同。实际上,要一次性获取所有“主演”的信息时,用不加数字的“a”表示即可。代码如下:
actor=s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()') #主演完整代码如下:
import requests
from lxml import etree
url = 'https://movie.douban.com/subject/26861685/'
data = requests.get(url).text
s=etree.HTML(data)
film=s.xpath('//*[@id="content"]/h1/span[1]/text()') #导演
director=s.xpath('//*[@id="info"]/span[1]/span[2]/a/text()') #导演
actor=s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()') #主演
time=s.xpath('//*[@id="info"]/span[12]/text()') #电影片长
print('电影名称:',film)
print('导演:',director)
print('主演:',actor)
print('片长:',time)
在 Pycharm 中运行完整代码结果如下:

8、 关于解析神器 Xpath
Xpath 即为 XML 路径语言(XML Path Language),它是一种用来确定 XML 文档中某部分位置的语言。
Xpath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。起初 Xpath 的提出的初衷是将其作为一个通用的、介于 Xpointer 与 XSL 间的语法模型。但是Xpath 很快的被开发者采用来当作小型查询语言。
Xpath解析网页的流程:
1. 首先通过Requests库获取网页数据
2. 通过网页解析,得到想要的数据或者新的链接
3. 网页解析可以通过 Xpath 或者其它解析工具进行,Xpath 在是一个非常好用的网页解析工具

常见的网页解析方法比较

- 正则表达式使用比较困难,学习成本较高
- BeautifulSoup 性能较慢,相对于 Xpath 较难,在某些特定场景下有用
- Xpath 使用简单,速度快(Xpath是lxml里面的一种),是入门最好的选择
Python爬虫实践 -- 记录我的第二只爬虫的更多相关文章
- Python爬虫实践 -- 记录我的第一只爬虫
一.环境配置 1. 下载安装 python3 .(或者安装 Anaconda) 2. 安装requests和lxml 进入到 pip 目录,CMD --> C:\Python\Scripts,输 ...
- Python爬虫个人记录(三)爬取妹子图
这此教程可能会比较简洁,具体细节可参考我的第一篇教程: Python爬虫个人记录(一)豆瓣250 Python爬虫个人记录(二)fishc爬虫 一.目的分析 获取煎蛋妹子图并下载 http://jan ...
- Python爬虫学习记录【内附代码、详细步骤】
引言: 昨天在网易云课堂自学了<Python网络爬虫实战>,视频链接 老师讲的很清晰,跟着实践一遍就能掌握爬虫基础了,强烈推荐! 另外,在网上看到一位学友整理的课程记录,非常详细,可以优先 ...
- Python爬虫个人记录(二) 获取fishc 课件下载链接
参考: Python爬虫个人记录(一)豆瓣250 (2017.9.6更新,通过cookie模拟登陆方法,已成功实现下载文件功能!!) 一.目的分析 获取http://bbs.fishc.com/for ...
- python爬虫实践
模拟登陆与文件下载 爬取http://moodle.tipdm.com上面的视频并下载 模拟登陆 由于泰迪杯网站问题,测试之后发现无法用正常的账号密码登陆,这里会使用访客账号登陆. 我们先打开泰迪杯的 ...
- # Python 3 & 爬虫一些记录
目录 Python 3 & 爬虫一些记录 交互模式和命令行模式 函数积累 语法积累 列表和元组 输入 交互模式下输入多行 爬虫 HTTP报文请求头User-Agent信息 解析库pyquery ...
- 路飞学城—Python爬虫实战密训班 第二章
路飞学城—Python爬虫实战密训班 第二章 一.Selenium基础 Selenium是一个第三方模块,可以完全模拟用户在浏览器上操作(相当于在浏览器上点点点). 1.安装 - pip instal ...
- python编写知乎爬虫实践
爬虫的基本流程 网络爬虫的基本工作流程如下: 首先选取一部分精心挑选的种子URL 将种子URL加入任务队列 从待抓取URL队列中取出待抓取的URL,解析DNS,并且得到主机的ip,并将URL对应的网页 ...
- powershell中的两只爬虫
--------------------序-------------------- (PowerShell中的)两只爬虫,两只爬虫,跑地快,爬网页不赖~~~ 一只基于com版的ie,一只基于.net中 ...
随机推荐
- Artwork
A template for an artwork is a white grid of n × m squares. The artwork will be created by painting ...
- 基于Python的数据分析(1):配置安装环境
数据分析是一个历史久远的东西,但是直到近代微型计算机的普及,数据分析的价值才得到大家的重视.到了今天,数据分析已经成为企业生产运维的一个核心组成部分. 据我自己做数据分析的经验来看,目前数据分析按照使 ...
- ccf 目录格式转换
任务背景: 在网络上获取的ccf目录的格式是PDF,但是要进行数据分析时,PDF格式的数据是不符合要求的,因此需要将pdf格式转化为excel格式 任务目的: 将pdf格式的CCF目录转化为excel ...
- SDE与shapefile之间的数据导入与导出
一.SDE要素导出到shapefile中. 1.创建一个新的shapefile文件. private bool CreateShapefile(string filepath, string name ...
- Binary Search 的递归与迭代实现及STL中的搜索相关内容
与排序算法不同,搜索算法是比较统一的,常用的搜索除hash外仅有两种,包括不需要排序的线性搜索和需要排序的binary search. 首先介绍一下binary search,其原理很直接,不断地选取 ...
- 基于ubuntu16.04部署IBM开源区块链项目-弹珠资产管理(Marbles)
前言 本教程基本上是对Marbles项目的翻译过程. 如果英文比较好的话,建议根据官方操作说明,一步步进行环境部署.当然你也可以参考本教程在自己的主机上部署该项目. Marbles 介绍 关于 Mar ...
- Java开源生鲜电商平台-财务系统模块的设计与架构(源码可下载)
Java开源生鲜电商平台-财务系统模块的设计与架构(源码可下载) 前言:任何一个平台也好,系统也好,挣钱养活团队这个是无可厚非的,那么对于一个生鲜B2B平台盈利模式( 查看:http://www.cn ...
- selenium+python自动化测试
F12: 右键 选择复制 path 在selenium+python自动化测试(一)–环境搭建中,运行了一个测试脚本,脚本内容如下: from selenium import webdriver ...
- MyBatis系列目录--5. MyBatis一级缓存和二级缓存(redis实现)
转载请注明出处哈:http://carlosfu.iteye.com/blog/2238662 0. 相关知识: 查询缓存:绝大数系统主要是读多写少. 缓存作用:减轻数据库压力,提供访问速度. 1. ...
- Ajax跨域之ContentType为application/json请求失败的问题
项目里的接口都是用springmvc写的,其中在@requestmapping接口中定义了consumes="application/json",也就是该接口只接受ContentT ...