关于checkpoint
Ⅰ、Checkpoint
1.1 checkpoint的作用
- 缩短数据库的恢复时间
- 缓冲池不够用时,将脏页刷到磁盘
- 重做日志不可用时,刷新脏页
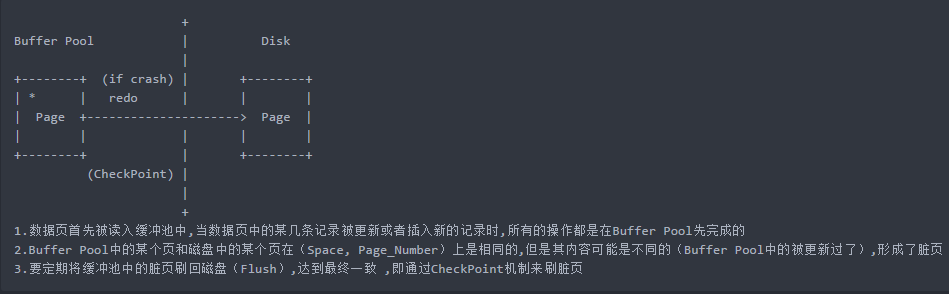
1.2 展开分析
page被缓存在bp中,page在bp中和disk中不是时刻保持一致的(page修改一下就刷一次盘是不现实的,是通过checkpoint来玩的)
万一宕机,重启的时候disk上那个page需要恢复到原来bp中page的那个版本
那问题是,两个page版本不一致咋整?没事,我们做到最终一致就行
那我们就说一下这个最终一致是个怎样的过程,通过一个例子来说明:
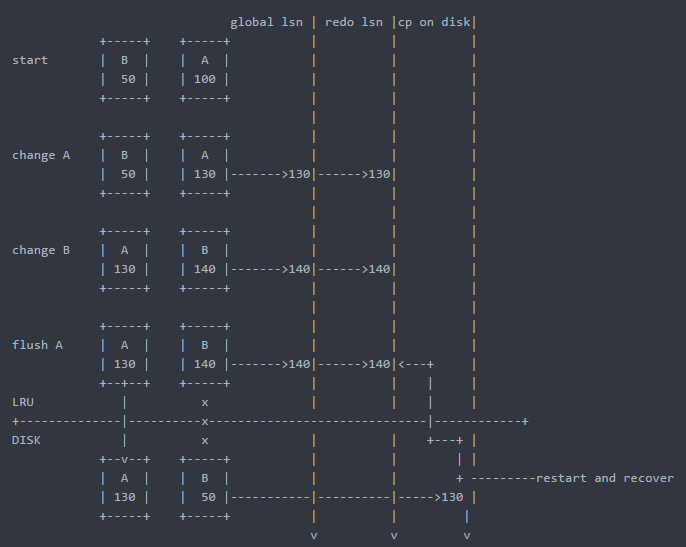
Step1:
一个page读到bp中时,它的lsn(这个鬼东西待会儿仔细说,先理解为一个flag)是100,然后这个page被modify了,它的lsn变成了130,当对应的事务提交后,修改日志会被记录到redo里面,此时redo和全局的lsn就相应的变成了130
Step2:
另外一个page之前进bp的时候lsn是50,前面那个page被modify之后,它也被修改,它的lsn变成了140,它这个140的lsn也写到了redo里,全局lsn变成140
Step3:
关键的一步,假设此时lsn为130的page被刷到disk上了(什么时候刷也是个学问,这里不说),而lsn为140的那个page还没被刷,磁盘上保存的还是老版本,突然宕机了。
Step4:
这时候restart数据库,就会从磁盘上cp的位置(130)开始读redo log,一直回放到140,这样没被刷到磁盘的那个page就恢复到宕机之前的状态了。
划重点:
①这个130,140其实就是字节数,也就是说你对这个页修改产生了10个字节的日志,那么lsn就加10
②page原来读进bp的lsn甭管,只管它改变了多少字节就行,所以这个lsn的变化肯定是一个单调递增的过程,其实lsn就是日志写了多少字节(之前没理解好,以为各个page的lsn是自己玩自己的)
Ⅱ、LSN(log sequence number)——日志序列号
lsn是用来保存checkpoint的,保存现在刷新到磁盘的位置在哪里
这个130,140其实就是字节数,也就是说你对这个页修改产生了10个字节的日志,那么lsn就加10,lsn没有上限,8字节
2.1 lsn存在什么地方?
- 每个page有一个LSN,page更新一下LSN就会更新一下,记录在page header中
- 整个MySQL实例也有一个LSN(这就是checkpoint),记录在第一个重做日志的前2k的块里(就给它用,不会被覆盖)
- redo log里有一个LSN
全局lsn位置之前的内容已经刷磁盘上,只要恢复它后面的日志,数据就恢复了
2.2 查看lsn和整个checkpoint流程梳理
看page中的lsn,page中其实是保存两个lsn的,如下:
(root@172.16.0.10) [(none)]> desc information_schema.INNODB_BUFFER_PAGE_LRU;
+---------------------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------------------+---------------------+------+-----+---------+-------+
| POOL_ID | bigint(21) unsigned | NO | | 0 | |
| LRU_POSITION | bigint(21) unsigned | NO | | 0 | |
| SPACE | bigint(21) unsigned | NO | | 0 | |
| PAGE_NUMBER | bigint(21) unsigned | NO | | 0 | |
| PAGE_TYPE | varchar(64) | YES | | NULL | |
| FLUSH_TYPE | bigint(21) unsigned | NO | | 0 | |
| FIX_COUNT | bigint(21) unsigned | NO | | 0 | |
| IS_HASHED | varchar(3) | YES | | NULL | |
| NEWEST_MODIFICATION | bigint(21) unsigned | NO | | 0 | |
| OLDEST_MODIFICATION | bigint(21) unsigned | NO | | 0 | |
| ACCESS_TIME | bigint(21) unsigned | NO | | 0 | |
| TABLE_NAME | varchar(1024) | YES | | NULL | |
| INDEX_NAME | varchar(1024) | YES | | NULL | |
| NUMBER_RECORDS | bigint(21) unsigned | NO | | 0 | |
| DATA_SIZE | bigint(21) unsigned | NO | | 0 | |
| COMPRESSED_SIZE | bigint(21) unsigned | NO | | 0 | |
| COMPRESSED | varchar(3) | YES | | NULL | |
| IO_FIX | varchar(64) | YES | | NULL | |
| IS_OLD | varchar(3) | YES | | NULL | |
| FREE_PAGE_CLOCK | bigint(21) unsigned | NO | | 0 | |
+---------------------+---------------------+------+-----+---------+-------+
20 rows in set (0.00 sec)
newest_modification 页最新更新完后的lsn
oldest_modification 页第一次更新完后的lsn
page刷到磁盘的时候,全局的check_point保存的是oldest(只保存第一次修改时的lsn),而page中的lsn保存的是newest
(root@172.16.0.10) [(none)]> show engine innodb status\G
...
---
LOG
---
Log sequence number 15151135824 当前内存中最新的LSN
Log flushed up to 15151135824 redo刷到磁盘的LSN
Pages flushed up to 15151135824 最后一个刷到磁盘上的页的最新的LSN(NEWEST_MODIFICATION)
Last checkpoint at 15151135815 最后一个刷到磁盘上的页的第一次被修改时的LSN(OLDEST_MODIFICATION)
...
Log sequence number和Log flushed up这两个LSN可能会不同,运行过程中后者可能会小于 前者,因为redo日志也是先在内存中更新,再刷到磁盘的
最后一个小于前面三个,为什么?
脏页会被指向flush list这个就不多赘述了
flush list是根据lsn进行组织的,而且还是用一个page第一次放进来的lsn进行组织的,也就是说这个page再次发生更新,它的位置是不会移动的
分析一波:
bp的LRU列表中,一个page,假设LSN进来的时候是100,当前全局LSN也是100,如果这个page变化了,产生了20字节的日志,这时候page的lsn变成120,并且通过指针指向flush list中去了,但是这个page立马又被更新产生20字节日志,此时page的lsn为140,而此时在flush list中的lsn还是120(这里意思就是page里面保存了两种lsn,一个是第一次修改页的,一个是最后一次修改页的)
当这个lsn为120的page被刷到disk上,那么disk上的cp就是120了,但是上面的三个值都是140,是不是很好理解呢,那就是说,每个page只更新一次,那这四个值就相等了呗,23333!
为什么这么设计?
为了恢复的时候,保证redo回放的过程的连续性,不会出错
page A第一次修改后lsn是120,记录到全局lsn,后面还有个page B被更新,lsn变为140,此时,page A再更新,lsn变为160了。这时候发生宕机,page A被刷到磁盘,page B没刷过去,如果flush list里面记录160的话,发生故障重启时lsn为140的page B怎么恢复?是不是被跳过去了
那从120开始恢复,那个页已经是160了,为什么还要恢复?
数据库会检测,如果page的lsn大于实例的lsn,就不会恢复这个page,跨过去,只将page B从120恢复到140
tips:
①checkpoint不需要实时刷新到磁盘,不是一个页更新了就要更新磁盘上的cp,磁盘上的cp前置一点是没有关系的,大不了多scan一点redo log,读到不回放就是了,而是由master_thread控制,差不多每秒钟更新一次
②回滚问题
回滚不是通过redo来回滚的,所有的page前滚到一个位置(恢复完),这些page对应的事务还是活跃的,还没提交,之后这些事务都会通过undo log来undo回滚,但undo是通过redo来恢复的
比如一个页120-160已经恢复过去了,但是这个事务需要回滚,却又已经刷到磁盘了,没关系,通过undo log往回滚一下就好了
事务活跃列表存放在undo段中,只要事务没提交就在里面,提交后移动到undo的history中,这个历史列表是用来做purge的,这里面的undo会被慢慢回收
Ⅲ、checkpoint 分类
- Sharp Checkpoint
将所有的赃页都刷新回磁盘,刷新时系统hang住,InnoDB关闭时使用
相关参数:innodb_fast_shutdown={1|0} - Fuzzy Checkpoint
将部分脏页刷新回磁盘,对系统影响较小
innodb_io_capacity来控制,最小限制为100,表示一次最多刷新脏页的能力,与IOPS相关
SSD可以设置在4000-8000,SAS最多设置在800多(IOPS在1000左右)
Ⅳ、什么时候刷dirty page
以前在master thread线程中(从flush_list中进行刷新)
现在都在page_cleaner_thread线程中(每一秒,每十秒)
FLUSH_LRU_LIST 刷新
5.5以前需要保证在LRU_LIST尾部要有100个空闲页(可替换的页),即刷新一部分数据 ,保证有100个空闲页。
由innodb_lru_scan_depth参数来控制,并不只是刷最后一个页,默认探测尾部1024个页(默认),1024个页中所有脏页会一起刷掉,该参数是应用到每个Buffer Pool,总数即为该值乘以Buffer Pool的个数,总量超过innodb_io_capacity是不合理的,即此参数不得超过innodb_io_capacity/innodb_buffer_pool_instances,ssd的话,可以适当把这个扫描深度调深一点
Async/Sync Flush Checkpoint
重做日志重用Dirty Page too much
赃页比例超过bp总量的一定比例,本来是通过page_cleaner_thread来刷,但是脏页太多了,就会强行刷,由innodb_max_dirty_pages_pct参数控制
tips:
①页只会从flush_list中刷新这个观点是不对的,只有page_cleaner_thread定期问flush_list要脏页,一个一个刷,刷到innodb_io_capacity的比例值
②LRU list中既存在干净的页也存在脏页,假设最后一个页,是脏的,另一个线程需要一个页,free list已经空了,lru会把这个页淘汰给这个线程去使用,这时候也需要刷新这个脏页,默认一下探测1024个page,把脏页刷掉
关于checkpoint的更多相关文章
- SQL Server CheckPoint的几个误区
有关CheckPoint的概念对大多数SQL Server开发或DBA人员都不陌生.但是包括我自己在内,大家对于CheckPoint都或多或少存在某些误区,最近和高文佳同学(感谢高同学的探讨) ...
- 关于Oracle GoldenGate中Extract的checkpoint的理解 转载
什么是checkpoint? 在Oracle 数据库中checkpoint的意思是将内存中的脏数据强制写入到磁盘的事件,其作用是保持内存中的数据与磁盘上的数据一致.SCN是用来描述该事件发生的准确的时 ...
- 利用SSIS的ForcedExecutionResult 属性 和CheckPoint调试Package
1,ForcedExecutionResult 强制一个package或task执行的结果,共有四种值 None,Success,Failure,Completion,默认值是None,表示不强制返回 ...
- SSIS的CheckPoint用法
在SSIS的Package Property中有CheckPoints的属性目录,CheckPoint是SSIS的Failover Feature.通过简单的配置CheckPoint,能够在Packa ...
- 检查点(Checkpoint)过程如何处理未提交的事务
每次我讲解SQL Server之前,我都会先简单谈下当我们执行查询时,在SQL Server内部发生了什么.执行一个SELECT语句非常简单,但是执行DML语句更加复杂,因为SQL Server要修改 ...
- [20140117]疑似checkpoint堵塞数据库连接
注:这个说法是不成立的,问题已经解决,但是无法正确的定位到具体什么原因:[20140702]奇怪的应用程序超时 背景: 开发通过应用程序的日志发现间歇性的出现,数据库连接超时 原因: 只能大概猜测,没 ...
- 浅谈checkpoint与内存缓存
事务日志存在检查点checkpoint,把内存中脏数据库写入磁盘,以减少故障恢复的时间,在此之前有必要提下SQL Server内存到底存放了哪些数据? SQL Server内存使用 对SQL Serv ...
- oracle检查点队列(checkpoint queue)
buffer cache CBC链 按地址链 LRU 干净buffer LRUW 脏buffer 按照冷热 checkpoint queue:链buffer,①链脏块②按buffer第一次脏的时 ...
- Flink - Checkpoint
Flink在流上最大的特点,就是引入全局snapshot, CheckpointCoordinator 做snapshot的核心组件为, CheckpointCoordinator /** * T ...
- HDFS中的checkpoint( 检查点 )的问题
1.问题的描述 由于某种原因,需要在原来已经部署了Cloudera CDH集群上重新部署,重新部署之后,启动集群,由于Cloudera Manager 会默认设置dfs.namenode.checkp ...
随机推荐
- 在app内打开自己app的专用设置界面
在我们的APP中,可能会使用多种服务,例如定位.推送.相册.拍照.通讯录等.选择是否允许一般只出现在安装app后第一次打开时,可是我们依然需要在使用到某种服务的时候判断是否用户是否允许了该服务,因为用 ...
- obj-c编程01:第一个类和对象的范例
这是obj-c学习过程中的第一篇博文,接下来还会有未知的N篇内容(关键是不知道obj-c有多难搞啊!),而且在以后不断的学习中,还会不断的在以前写的博文中修改和添加新的内容.在遇到暂时无法解决的问题时 ...
- 使用Interlocked在多线程下进行原子操作,无锁无阻塞的实现线程运行状态判断
巧妙地使用Interlocked的各个方法,再无锁无阻塞的情况下判断出所有线程的运行完成状态. 昨晚耐着性子看完了clr via c#的第29章<<基元线程同步构造>>,尽管这 ...
- className.class.getResourceAsStream与ClassLoader.getSystemResourceAsStream区别
className.class.getResourceAsStream : 一: 要加载的文件和.class文件在同一目录下,例如:com.x.y 下有类Test.class ,同时有资源文件conf ...
- vs工具
首页 精选版块 论坛帮助 论坛牛人 论坛地图 专家问答 CSDN > CSDN论坛 > .NET技术 > 非技术区 返回列表 管理菜单 结帖 发帖 回复 关注 [推荐] Visual ...
- Web开发问题记录
1.先说一个CSS的:CSS中带有中文(比如字体定义)的属性定义最好放在该选择器定义诸项的最后一条,为什么----编码格式问题. 2.其实自己也可以用自己写的DispatcherServlet+jsp ...
- Django Web项目代码规范参考
Python:PEP8+GoogleStyle+DjangoSytlePEP8中文版:http://www.cnblogs.com/huazi/archive/2012/11/28/2792929.h ...
- AngularJS + RequireJS
http://www.startersquad.com/blog/AngularJS-requirejs/ While delivering software projects for startup ...
- .net core使用orm操作mysql数据库
Mysql数据库由于其体积小.速度快.总体拥有成本低,尤其是开放源码这一特点,许多中小型网站为了降低网站总体拥有成本而选择了MySQL作为网站数据库.MySQL是一个多用户.多线程的关系型数据库管理系 ...
- 搭建centos7的开发环境2-单机版Hadoop2.7.3配置
最近公司准备升级spark环境,主要原因是生产环境的spark和hadoop版本都比较低,但是具体升级到何种版本还不确定,需要做进一步的测试分析.这个任务对于大数据开发环境配置有要求,这里记录一下配置 ...