python爬虫(5)——正则表达式(二)
前一篇文章,我们使用re模块来匹配了一个长的字符串其中的部分内容。下面我们接着来作匹配“1305101765@qq.com advantage 314159265358 1892673 3.14 little Girl try_your_best 56 123456789@163.com python3”
我们的目标是匹配‘56’,其中\d表示匹配数字,{2}表示匹配次数为两次,{M,N},M,N均为非负整数,M<=N,表示匹配M-N次。在匹配规则前面加个r的意思是表示原生字符串。
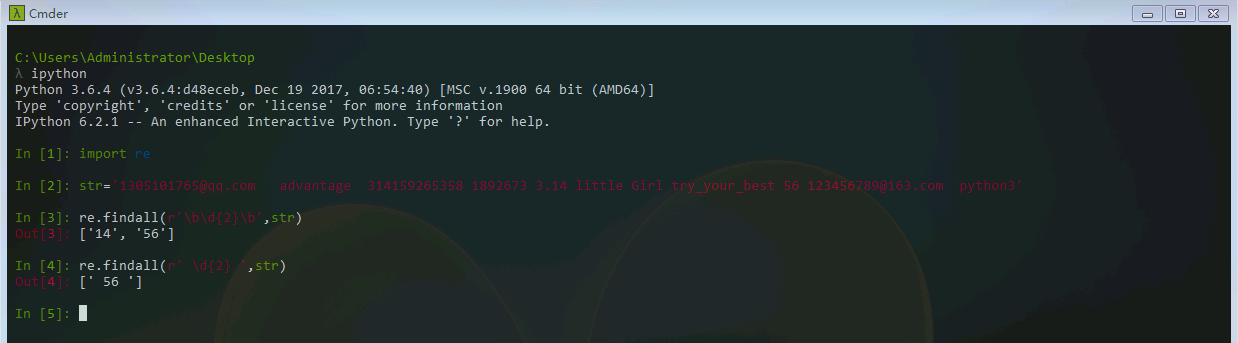
实际上我们在使用正则表达式的时候,通常先将其编译成pattern对象,使用re.compile()方法来进行编译。下面我们来匹配IP地址如:192.168.1.1。
import re
str='192.168.1.1'
re.search(r'(([01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])\.){3}([01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])',str)
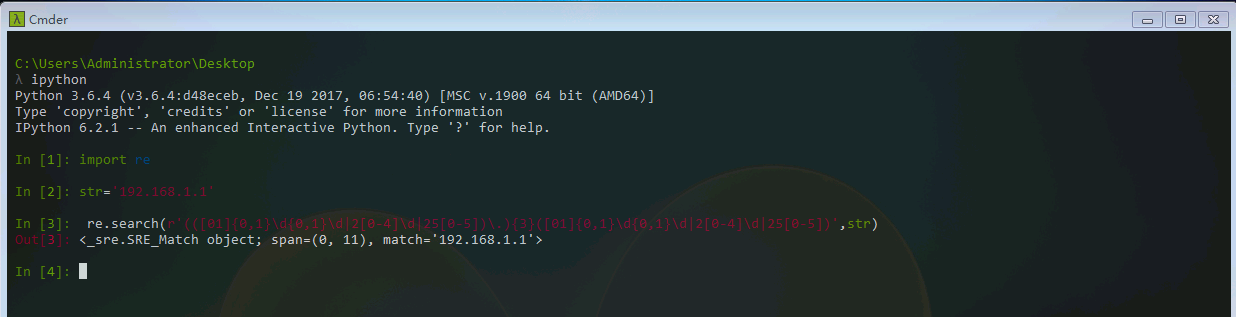
可以看出来,正则使用起来并不简单。在上面的规则中,我们是用了三个子组,如果我们在网页上用findall匹配所有IP,它会把结果给分类了,变成(‘192’,‘168’,‘1’,‘1’)。显然这不是我们想要的。这时候,我们需要用(?:...)来表示非捕获组,即该子组匹配的字符串无法从后面获取。
有了之前的基础,我尝试着写下了如下的代码,从西刺代理网站上爬取IP地址,并用代理访问网站验证其是否可用。当中用到了python的异常处理机制。虽然代码不成熟,但还是分享出来,慢慢改进。
import urllib.request
import re url="http://www.xicidaili.com/"
useful_ip=[]
def loadPage(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"}
response=urllib.request.Request(url,headers=headers)
html=urllib.request.urlopen(response).read().decode("utf-8")
return html def getProxy():
html=loadPage(url)
pattern=re.compile(r'(<td>\d+</td>)')
duankou=pattern.findall(html)
pattern=re.compile(r'(?:(?:[01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])\.){3}(?:[01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])')
content_list=pattern.findall(html)
list_num=[]
for num in duankou:
list_num.append(num[4:-5])
for i in range(len(list_num)):
ip=content_list[i]+ ":"+list_num[i]
while True:
proxy_support=urllib.request.ProxyHandler({'http':ip})
opener=urllib.request.build_opener(proxy_support)
opener.add_handler=[("User-Agent","Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36")]
urllib.request.install_opener(opener)
try:
print("正在尝试使用 %s 访问..." % ip)
ip_filter="http://www.whatsmyip.org/"
ip_response=urllib.request.urlopen(ip_filter)
except urllib.error.URLError:
print("访问出错,这个IP不能用啦")
break
else:
print("访问成功!")
print("可用IP为: %s " % ip)
useful_ip.append(ip)
if input("继续爬取?")=="N":
print("有效IP如下:")
for key in useful_ip:
print(key)
exit()
else:
break if __name__=="__main__":
getProxy()
在处理IP地址对应的端口号时,我用的一个非常笨的方法。实际上有更好的办法解决,大家也可以想一想。在上面这段代码中,使用urllib访问网站、Handler处理器自定义opener、python异常处理、正则匹配ip等一系列的知识点。任何知识,用多了才会熟练。
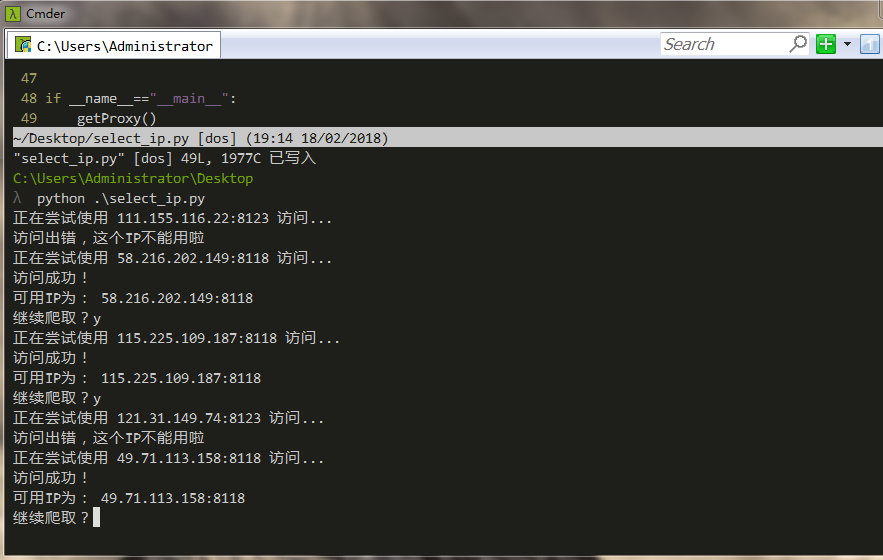
可以看到它运行成功,并且找到一个可用IP后会问你是否继续爬取。当然,我们可以手动构建一个IPPOOL即IP池,自定义一个函数,把可以用的IP写入一个文件保存起来,这里就不作赘述了。在github上有成熟的ip池代码,大家可以下载下来阅读,这里只是把前面讲的一些用法做一个简单的试验,因此并没有把这段代码完善。
python爬虫(5)——正则表达式(二)的更多相关文章
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- Python爬虫初学(二)—— 爬百度贴吧
Python爬虫初学(二)-- 爬百度贴吧 昨天初步接触了爬虫,实现了爬取网络段子并逐条阅读等功能,详见Python爬虫初学(一). 今天准备对百度贴吧下手了,嘿嘿.依然是跟着这个博客学习的,这次仿照 ...
- 玩转python爬虫之正则表达式
玩转python爬虫之正则表达式 这篇文章主要介绍了python爬虫的正则表达式,正则表达式在Python爬虫是必不可少的神兵利器,本文整理了Python中的正则表达式的相关内容,感兴趣的小伙伴们可以 ...
- Python爬虫入门(二)之Requests库
Python爬虫入门(二)之Requests库 我是照着小白教程做的,所以该篇是更小白教程hhhhhhhh 一.Requests库的简介 Requests 唯一的一个非转基因的 Python HTTP ...
- 【Python爬虫】正则表达式与re模块
正则表达式与re模块 阅读目录 在线正则表达式测试 常见匹配模式 re.match re.search re.findall re.compile 实战练习 在线正则表达式测试 http://tool ...
- Python 爬虫实战(二):使用 requests-html
Python 爬虫实战(一):使用 requests 和 BeautifulSoup,我们使用了 requests 做网络请求,拿到网页数据再用 BeautifulSoup 解析,就在前不久,requ ...
- python 爬虫之-- 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. 正则表达式非python独有,python 提供了正则表达式的接口,re模块 一.正则匹配字符简介 模式 描述 \d ...
- Python 爬虫入门(二)—— IP代理使用
上一节,大概讲述了Python 爬虫的编写流程, 从这节开始主要解决如何突破在爬取的过程中限制.比如,IP.JS.验证码等.这节主要讲利用IP代理突破. 1.关于代理 简单的说,代理就是换个身份.网络 ...
- Python爬虫小白---(二)爬虫基础--Selenium PhantomJS
一.前言 前段时间尝试爬取了网易云音乐的歌曲,这次打算爬取QQ音乐的歌曲信息.网易云音乐歌曲列表是通过iframe展示的,可以借助Selenium获取到iframe的页面元素, 而QQ音乐采用的是 ...
- python爬虫入门(二)Opener和Requests
Handler和Opener Handler处理器和自定义Opener opener是urllib2.OpenerDirector的实例,我们之前一直在使用urlopen,它是一个特殊的opener( ...
随机推荐
- Git分支管理及常见操作
众所周知,使用Git分支,我们可以从开发主线上分离开来,然后在不影响主线的同时继续工作. 既然要使用Git分支,这里就涉及到Git分支的管理及常见操作,如列出分支,分支的创建,分支的删除,分支的合并等 ...
- webpack的安装与使用
在安装 Webpack 前,你本地环境必须已安装nodejs. 可以使用npm安装,当然由于 npm 安装速度慢,也可以使用淘宝的镜像及其命令 cnpm,安装使用介绍参照:使用淘宝 NPM 镜像. 使 ...
- tp5 $_ENV获取不到数据
$_ENV变量是取决于服务器的环境变量的,从不同的服务器上获取的$_ENV变量打印出的结果可能是不同的. php的配置文件php.ini的配置项为:variables_order = "GP ...
- [数据分析工具] Pandas 功能介绍(二)
条件过滤 我们需要看第一季度的数据是怎样的,就需要使用条件过滤 体感的舒适适湿度是40-70,我们试着过滤出体感舒适湿度的数据 最后整合上面两种条件,在一季度体感湿度比较舒适的数据 列排序 数据按照某 ...
- sass和compass实战 读书笔记(一)
sass优势: 不做重复的工作 一 消除样式表冗余(通过变量赋值的方式) 1. 通过变量来复用属性值 2. 使用嵌套来快速写出多层级的选择器 3. 通过混合器来复用一段样式 4. 使用选择器继承来避 ...
- 云计算之路-阿里云上:部分服务器未及时续费造成docker swarm集群故障
非常非常抱歉,由于我们的疏忽 —— docker swarm 集群中的 2 台服务器没有及时续费,造成在夜里0点被自动关机,从而引发整个 docker swarm 集群故障,造成今天凌晨 0:30 ~ ...
- C#动态设置匿名类型对象的属性
用C#写WPF程序, 实现功能的过程中碰到一个需求: 动态设置对象的属性,属性名称是未知的,在运行时才能确定. 本来这种需求可以用 Dictionary<string, object> 实 ...
- linux_运维职责
运维准则: 不要删文件,移动文件,可以复原,一个月后什么事没有,删除 运维人员主要关注哪些方面? CPU:对计算机工作速度和效率起决定性作用(intel amd) 内存: 临时存放数据:容量和处理速度 ...
- Linkin大话eclipse快捷键
刚来这家公司的时候,作为菜鸟的我在帮别人调试代码的时候,有人说我快捷键使用的很熟悉. 呵呵,工欲善其事必先利其器,以下这些快捷键是最常用的也是要必须记住的. [Ctrl开头] Ctrl+1:快速修复 ...
- 一个Android上的以滑动揭示的方式显示并切换图片的View
SlideView是一个Android上的以滑动揭示的方式显示并切换图片的View,以视觉对比的方式把一套相似的图片展示出来. 示例 翻页图片揭示效果: 特性 设置一组(List<ImageIn ...