python 堆排序
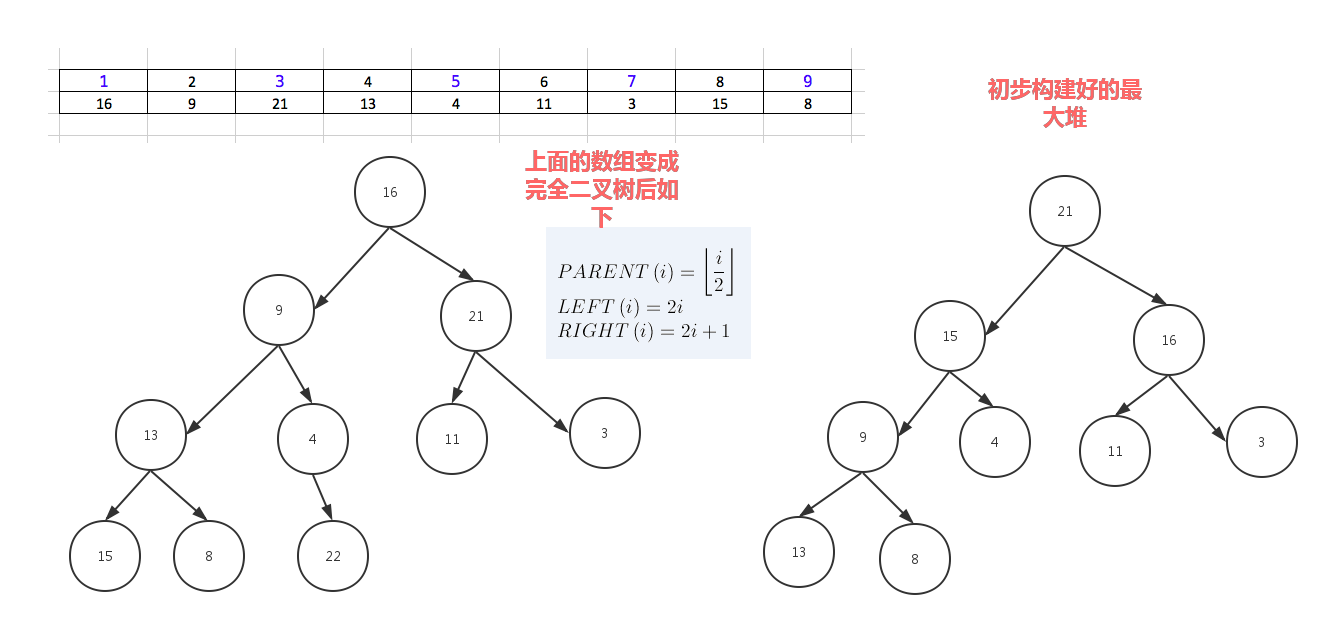
堆排序就是把堆顶的最大数取出,
将剩余的堆继续调整为最大堆,具体过程在第二块有介绍,以递归实现
剩余部分调整为最大堆后,再次将堆顶的最大数取出,再将剩余部分调整为最大堆,这个过程持续到剩余数只有一个时结束
dataset = [16,9,21,3,13,14,23,6,4,11,3,15,99,8,22] for i in range(len(dataset)-1,0,-1):
print("-------",dataset[0:i+1],len(dataset),i)
#for index in range(int(len(dataset)/2),0,-1):
for index in range(int((i+1)/2),0,-1):
print(index)
p_index = index l_child_index = p_index *2 - 1
r_child_index = p_index *2
print("l index",l_child_index,'r index',r_child_index)
p_node = dataset[p_index-1]
left_child = dataset[l_child_index] if p_node < left_child: # switch p_node with left child
dataset[p_index - 1], dataset[l_child_index] = left_child, p_node
# redefine p_node after the switch ,need call this val below
p_node = dataset[p_index - 1] if r_child_index < len(dataset[0:i+1]): #avoid right out of list index range
right_child = dataset[r_child_index]
print(p_index,p_node,left_child,right_child)
if p_node < right_child: #swith p_node with right child
dataset[p_index - 1] , dataset[r_child_index] = right_child,p_node
# redefine p_node after the switch ,need call this val below
p_node = dataset[p_index - 1] else:
print("p node [%s] has no right child" % p_node) #最后这个列表的第一值就是最大堆的值,把这个最大值放到列表最后一个, 把神剩余的列表再调整为最大堆 print("switch i index", i, dataset[0], dataset[i] )
print("before switch",dataset[0:i+1])
dataset[0],dataset[i] = dataset[i],dataset[0]
print(dataset)
堆排序详解:http://www.cnblogs.com/0zcl/p/6737944.html
python 堆排序的更多相关文章
- python堆排序
堆是完全二叉树 子树是不相交的 度 节点拥有子树的个数 满二叉树: 每个节点上都有子节点(除了叶子节点) 完全二叉树: 叶子结点在倒数第一层和第二层,最下层的叶子结点集中在树的左部 ,在右边的话,左子 ...
- python堆排序实现TOPK问题
# 构建小顶堆跳转def sift(li, low, higt): tmp = li[low] i = low j = 2 * i + 1 while j <= higt: # 情况2:i已经是 ...
- python3数据结构与算法
python内置的数据结构包括:列表(list).集合(set).字典(dictionary),一般情况下我们可以直接使用这些数据结构,但通常我们还需要考虑比如搜索.排序.排列以及赛选等一些常见的问题 ...
- 排序NB三人组
排序NB三人组 快速排序,堆排序,归并排序 1.快速排序 方法其实很简单:分别从初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”.先从右往左找一个小于6的数,再从左往 ...
- Python3 实例
一直以来,总想写些什么,但不知从何处落笔. 今儿个仓促,也不知道怎么写,就把手里练习过的例子,整理了一下. 希望对初学者有用,都是非常基础的例子,很适合初练. 好了,Follow me. 一.Pyth ...
- 数据结构:堆排序 (python版) 小顶堆实现从大到小排序 | 大顶堆实现从小到大排序
#!/usr/bin/env python # -*- coding:utf-8 -*- ''' Author: Minion-Xu 小堆序实现从大到小排序,大堆序实现从小到大排序 重点的地方:小堆序 ...
- 你需要知道的九大排序算法【Python实现】之堆排序
六.堆排序 堆排序是一种树形选择排序,是对直接选择排序的有效改进. 堆的定义下:具有n个元素的序列 (h1,h2,...,hn),当且仅当满足(hi>=h2i,hi>=2i+1)或(h ...
- python下实现二叉堆以及堆排序
python下实现二叉堆以及堆排序 堆是一种特殊的树形结构, 堆中的数据存储满足一定的堆序.堆排序是一种选择排序, 其算法复杂度, 时间复杂度相对于其他的排序算法都有很大的优势. 堆分为大头堆和小头堆 ...
- 高速排序,归并排序,堆排序python实现
高速排序的时间复杂度最好情况下为O(n*logn),最坏情况下为O(n^2),平均情况下为O(n*logn),是不稳定的排序 归并排序的时间复杂度最好情况下为O(n*logn),最坏情况下为O(n*l ...
随机推荐
- jquery四种监听事件的区别
最近找工作被问到了jquery有哪些事件监听,都有什么区别,忽然有点想不起来了... 然后上网上查看了相关的资料,总结一下,方便大家查看,也方便自己复习! 1.bind()方法: bind(type, ...
- java的几种引用之二
import java.lang.ref.PhantomReference;import java.lang.ref.ReferenceQueue;import java.lang.ref.SoftR ...
- Spring 之BeanFactory(转)
BeanFactory是Spring的“心脏”.它就是Spring IoC容器的真面目. Spring使用BeanFactory来实例化.配置和管理Bean.但是,在大多数情况我们并不直接使用Bean ...
- npm包管理器小节一下
淘宝npm镜像cnpm设置 npm install -g cnpm --registry=https://registry.npm.taobao.org 更新npm的版本 npm install np ...
- [HDU5663]Hillan and the girl
题面戳我(题面很鬼畜建议阅读一下) 题意:给出n,m,求 \[\sum_{i=1}^{n}\sum_{j=1}^{m}[gcd(i,j)\mbox{不是完全平方数}]\] 多组数据,\(n,m\le1 ...
- hibernate 反向生成 实体类
1,配置数据库连接 步骤. 点击 windows -> open perspective - > myeclipse datebase Exprorer 打开了dateb ...
- 2018java平均工资,想转行学java的快点上车
很多人选择工作的原因很简单:要么有钱,要么自己开心,当然绝大多数人是既没有钱也不开心...(现实就是这么残酷).哪有钱多事少的活,请告诉我,我第一个去!!我想大部分人对java充满好奇的一个原因就是钱 ...
- Selenium元素定位之Xpath
Xpath非常强大,使用Xpath可以代替前六种基本的定位方式,这种定位方式几乎可以定位到页面上的任何元素. Xpath简介 Xpath就是xml path,是一种在xml中查找信息的语言,因为htm ...
- Devstack 安装OpenStack Pike版本(单机环境)
问题背景 最近在研究OpenStack的时候,需要对其源代码进行调试,公司服务器上部署的OpenStack环境又不能随意的进行折腾,为了研究的持续性和方便性,就决定再自己的虚拟机上面使用Devstac ...
- UWP 创建动画的极简方式 — LottieUWP
提到 UWP 中创建动画,第一个想到的大多都是 StoryBoard.因为 UWP 和 WPF 的界面都是基于 XAML 语言的,所以实现 StoryBoard 会非常方便. 来看一个简单的 Stor ...