数据挖掘-K-近邻算法
数据挖掘-K-近邻算法
1. K-近邻算法概述
1.1 K-近邻算法介绍
1.1.1 KNN算法作用
- KNN(K-Nearest Neighbor)最邻近分类算法是数据挖掘分类(classification)技术中最简单的算法之一,其指导思想是”近朱者赤,近墨者黑“,即由你的邻居来推断出你的类别
1.1.2 KNN 算法思想
(1)思想
- 为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则(majority-voting),将未知样本与K个最邻近样本中所属类别占比较多的归为一类
- KNN在做回归和分类的主要区别,在于最后做预测时候的决策不同
- 在分类预测时,一般采用多数表决法,即选取的k个邻居中占多数的类
- 在做回归预测时,一般使用平均值法,即选取的k个邻居中的数值平均值
(2)例:
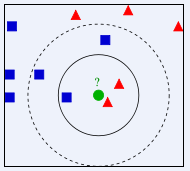
如下图所示,如何判断绿色圆应该属于哪一类,是属于红色三角形还是属于蓝色四方形?
- 如果K=3,由于红色三角形所占比例为2/3,绿色圆将被判定为属于红色三角形那个类
- 如果K=5,由于蓝色四方形比例为3/5,因此绿色圆将被判定为属于蓝色四方形类
1.1.3 KNN算法特点
由于KNN最邻近分类算法在分类决策时只依据最邻近的一个或者几个样本的类别来决定待分类样本所属的类别,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合
KNN算法即可以应用于分类算法中,也可以应用于回归算法中。
KNN算法的准确性很大程度上依赖于K值的选择
1.2 KNN算法涉及的问题
1.2.1 K值的选择
(1)为什么选择K值
- KNN算法的准确性很大程度上依赖于K值的选择,要选取合适的K值使得算法最终的结果准确性最高
(2)K值的选择过程
- 选一个较小的值,然后通过交叉验证选择一个合适的最终值。
- k越小,即使用较小的领域中的样本进行预测,训练误差会减小,但模型会很复杂,以至于过拟合。
- k越大,即使用交大的领域中的样本进行预测,训练误差会增大,模型会变得简单,容易导致欠拟合。
1.2.2 距离的度量

(1)欧几里得距离
使用欧几里得距离:欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)
- 在二维和三维空间中的欧氏距离就是两点之间的实际距离
- 对于n维空间l两点,\(X(x_1,x_2,...x_n),Y(y_1,y_2,...,y_n)\),两者欧几里得距离:
\(d(X,Y)=\sqrt{(x_1-y_1)^2+(x_2-y_2)^2+...+(x_n-y_n)^2}=\sqrt{\sum_{i=1}^n{(x_i-y_i)^2}}\)
(2)曼哈顿距离
定义曼哈顿距离的正式意义为L1-距离或城市区块距离,也就是在欧几里德空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。
例如在平面上,坐标X(x1,x2)的与坐标Y(y1,y2)的曼哈顿距离为:
\(d(X,Y)=|x_1-y_1|+|x_2-y_2|\)
1.2.3 加权KNN算法
(1)KNN算法的不足
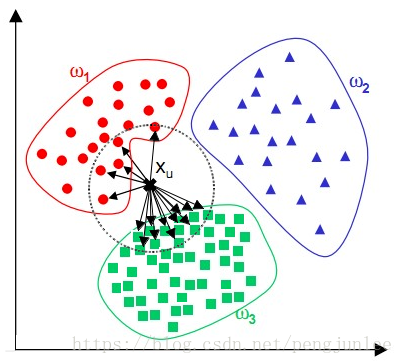
- KNN算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时:
- 该样本的K个邻居中大容量类的样本占多数,如下图所示。该算法只计算最近的邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进
(2)加权方式
- 反函数:
- 该方法最简单的形式是返回距离的倒数,比如距离d,权重1/d。有时候,完全一样或非常接近的商品权重会很大甚至无穷大。基于这样的原因,在距离求倒数时,在距离上加一个常量:\(weight = \frac{1}{distance + const}\)
- 这种方法的潜在问题是,它为近邻分配很大的权重,稍远一点的会衰减的很快。虽然这种情况是我们希望的,但有时候也会使算法对噪声数据变得更加敏感
- 高斯函数:
- \(f(x)=ae^N\),\(N=-\frac{(x-b)^2}{2c^2},a,b,c∈R\)
- 高斯函数在距离为0的时候权重为1,随着距离增大,权重减少,但不会变为0
(3)具体算法
- 在处理离散型数据时,将这k个数据用权重区别对待,预测结果与第n个数据的label相同的概率:
- \(P_n=\frac{W_n}{\sum_{i=1}^kW_i}\)
- 例:设有共选取5个最近点,A(1),B(2),C(2),D(2),E(3)(后面为距离,AB属于类1,CDE属于类2),为求简单,设权重为距离的倒数,\(\sum_{i=1}^kW_i=\frac{17}{6}\),得各权重WA(\(\frac{17}{6}\)),WB(\(\frac{17}{12}\)),WC(\(\frac{17}{12}\)),WD(\(\frac{17}{12}\)),WE(\(\frac{17}{18}\)),则1类的总权重为\(W_1 = \frac{17}{4}=4.25\),\(W_2=\frac{73}{18}=4.0555\),得该点属于1类
- 在处理数值型数据时,并不是对这k个数据简单的求平均,而是加权平均:通过将每一项的距离值\(D_i\)乘以对应权重\(W_i\),然后将结果累加。求出总和后,在对其除以所有权重之和,
- 对于k个点 i类 点的预测结果:
- \(f(x) = \frac{\sum_{i=1}^kD_iW_i}{\sum_{i=1}^kW_i}\)
- 每预测一个新样本的所属类别时,都会对整体样本进行遍历,可以看出kNN的效率实际上是十分低下的
1.3 KNN算法实现
1.3.1 算法步骤
计算测试数据与各个训练数据之间的距离
按照距离的递增关系进行排序
选取距离最小的K个点
确定前K个点所在类别的出现频率
返回前K个点中出现频率最高的类别作为测试数据的预测分类
1.4 Python 实现KNN算法
1.4.1 sklearn包使用
- 调用sklearn包实例:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
#读取鸢尾花数据集
iris = load_iris()
x = iris.data
y = iris.target
k_range = range(1, 31)
k_error = []
#循环,取k=1到k=31,查看误差效果
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
#cv参数决定数据集划分比例,这里是按照5:1划分训练集和测试集
scores = cross_val_score(knn, x, y, cv=6, scoring='accuracy')
k_error.append(1 - scores.mean())
#画图,x轴为k值,y值为误差值
plt.plot(k_range, k_error)
plt.xlabel('Value of K for KNN')
plt.ylabel('Error')
plt.show()
数据挖掘-K-近邻算法的更多相关文章
- 数据挖掘算法(一)--K近邻算法 (KNN)
数据挖掘算法学习笔记汇总 数据挖掘算法(一)–K近邻算法 (KNN) 数据挖掘算法(二)–决策树 数据挖掘算法(三)–logistic回归 算法简介 KNN算法的训练样本是多维特征空间向量,其中每个训 ...
- 数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例)
数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例) 简介 scikit-learn 估计器 加载数据集 进行fit训练 设置参数 预处理 流水线 结尾 数据挖掘入门系 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- 用Python从零开始实现K近邻算法
KNN算法的定义: KNN通过测量不同样本的特征值之间的距离进行分类.它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别.K通 ...
- Python3入门机器学习 - k近邻算法
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- k近邻算法的Java实现
k近邻算法是机器学习算法中最简单的算法之一,工作原理是:存在一个样本数据集合,即训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据和所属分类的对应关系.输入没有标签的新数据之后, ...
随机推荐
- video标签加载视频有声音却黑屏
问题 昨天用户上传了一个视频文件,然而发现虽然有声音但是黑屏. 解释 因为原视频的编码是用 mp4v 格式的,它需要专用的解码器.而 chrome 并不支持,所以无法播放. 然后如果用转码功能转成用 ...
- MATLAB神经网络(5) 基于BP_Adaboost的强分类器设计——公司财务预警建模
5.1 案例背景 5.1.1 BP_Adaboost模型 Adaboost算法的思想是合并多个“弱”分类器的输出以产生有效分类.其主要步骤为:首先给出弱学习算法和样本空间($X$,$Y$),从样本空间 ...
- AspNetCore3.1源码解析_2_Hsts中间件
title: "AspNetCore3.1源码解析_2_Hsts中间件" date: 2020-03-16T12:40:46+08:00 draft: false --- 概述 在 ...
- JAVA设计模式之-模板方法+(钩子函数)
1.定义 允许子类对父类的一个或多个步骤进行重写.例如聚合支付场景中有很多共同的步骤,比如验签.四要素验证.风控等等,但是在支付的时候走不同的渠道可能在调用和参数上有很大的不同,比如有的是xml,有的 ...
- Java Grammar(三):修饰符
简介 修饰符是用于限定类型以及类型成员申明的一种符号,从修饰对象上可以分为类修饰符,方法修饰符,变量修饰符:从功能上可以划分为访问控制修饰符和非访问修饰符.访问修饰符控制访问权限,不同的访问修饰符有不 ...
- go源码分析(一) 通过调试看go程序初始化过程
参考资料:Go 1.5 源码剖析 (书签版).pdf 编写go语言test.go package main import ( "fmt" ) func main(){ fmt.Pr ...
- dos下 批处理 用 pause 可以在最后暂停 查看结果信息 build.bat
dos下 批处理 用 pause 可以在最后暂停 查看结果信息
- Salesforce LWC学习(十三) 简单知识总结篇一
本篇参考:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript 随着项目的学习以及trailhead的学习,会遇见自己曾经模糊的定义或者比较浪 ...
- CMDB_Agent版本
目录 CMDB_Agent版本 CMDB概念 CMDB_Agent介绍 agent方案 ssh类方案 相比较 架构目录 bin-start.py 启动文件 conf-config.py 自定义配置文件 ...
- Servlet(五)----ServletContext对象
## ServletContext对象 1.概念:代表整个web应用,可以和程序的容器(服务器)来通信 2.获取: 1.通过request对象获取 request.getServletContext ...