HashMap1.7和1.8,红黑树原理!
jdk 1.7
概述
HashMap基于Map接口实现,元素以键值对的方式存储,并允许使用null键和null值,但只能有一个键作为null,因为key不允许重复,另外HashMap不能保证放入元素的数据,它是无序的,和放入的顺序并不能相同,HashMap是线程不安全的。
继承关系
public class HashMap<K,V>extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
基本属性
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //默认初始化大小 16
static final float DEFAULT_LOAD_FACTOR = 0.75f; //负载因子0.75
static final Entry<?,?>[] EMPTY_TABLE = {}; //初始化的默认数组
transient int size; //HashMap中元素的数量
int threshold; //判断是否需要调整HashMap的容量
HashMap的数据存储结构
HashMap有数组和链表来实现对数据的存储,HashMap采用Entry数组来存储key-value对,每一个键值对组成了一个Entry实体,Entry类实际上是一个单向的链表结构,它具有Next指针,可以链接下一个Entry实体,以次来解决Hash冲突的问题。
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;
链表存储区间离散,占用内存比较宽松,故空间复杂度小,但时间复杂度很大,达 O(N) 。链表的特点是:寻址困难,插入和删除容易。
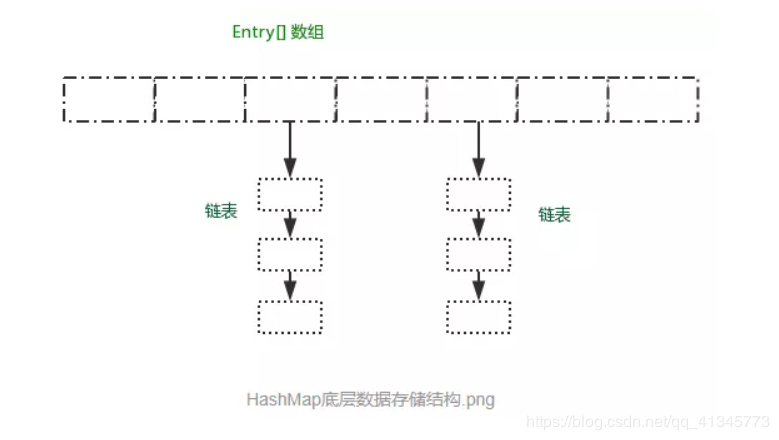
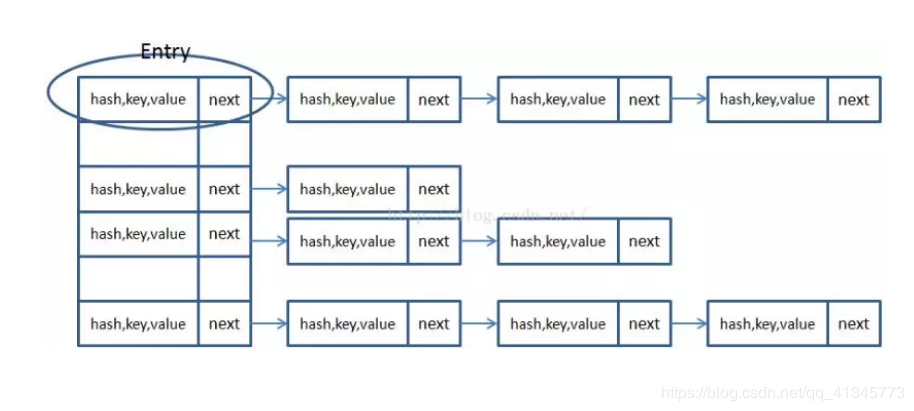
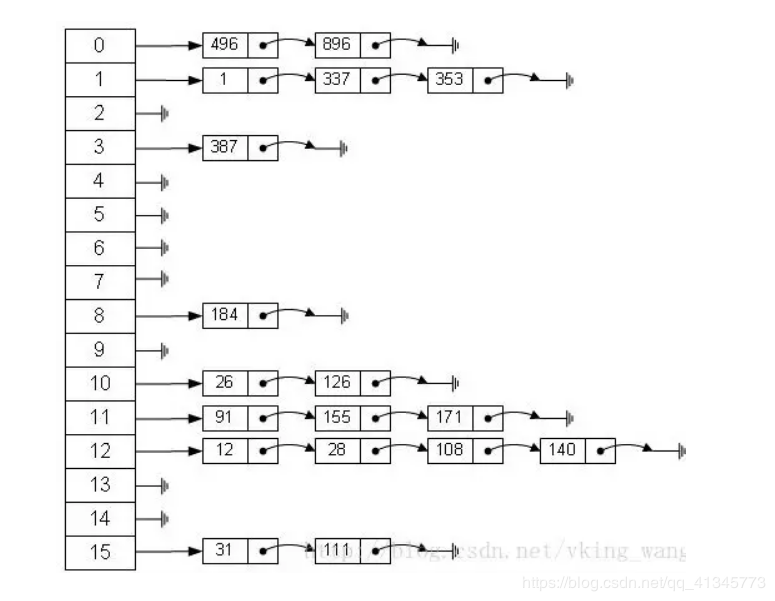
从上图可以发现数组结构是由数组+链表组成,一个长度为16的数组中,每个元素存储的是一个链表的头节点。那么这些元素是按照什么样的规矩存储到数组中?
通过hash(key.hashCode())%length 获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
取模运算的方式固然简单,但是效率很低。为了实现高效的HashMao算法,HashMap的发明者采用了位运算的方式。
公式: index = HashCode(Key) & (Length - 1)
以值为“book”的key来演示整个过程:
1.计算book的hashcode,结果为十进制的3029737,二进制的101110001110101110 1001。
2.假定HashMap长度是默认的16,计算Length-1的结果为十进制的15,二进制的1111。
3.把以上两个结果做与运算,101110001110101110 1001 & 1111 = 1001,十进制是9,所以 index=9。
可以说,Hash算法最终得到的index结果,完全取决于Key的Hashcode值的最后几位。
这样做不但效果上等同于取模,而且还大大提升了性能。
HashMap里面实现一个静态内部类Entry,其重要的属性有 hash,key,value,next。
HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。
Put方法的原理
比如调用 hashMap.put("apple", 0) ,插入一个Key为“apple"的元素。这时候我们需要利用一个哈希函数来确定Entry的插入位置(index):
假定最后计算出的index是2,那么结果如下:

但是,因为HashMap的长度是有限的,当插入的Entry越来越多时,再完美的Hash函数也难免会出现index冲突的情况。比如下面这样:
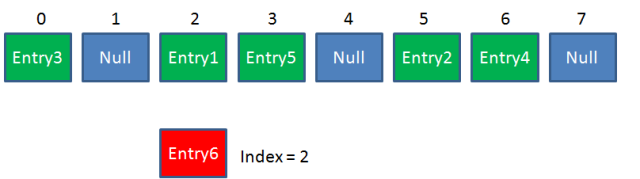
可以利用链表来解决。
HashMap数组的每一个元素不止是一个Entry对象,也是一个链表的头节点。每一个Entry对象通过Next指针指向它的下一个Entry节点。当新来的Entry映射到冲突的数组位置时,只需要插入到对应的链表即可:
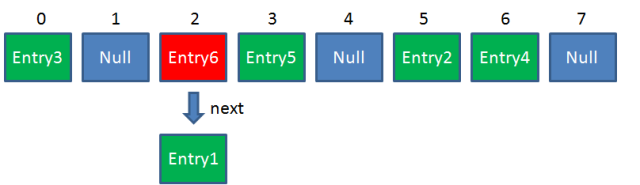
需要注意的是,新来的Entry节点插入链表时,使用的是“头插法”。
Get方法的原理
首先会把输入的Key做一次Hash映射,得到对应的index:
由于刚才所说的Hash冲突,同一个位置有可能匹配到多个Entry,这时候就需要顺着对应链表的头节点,一个一个向下来查找。假设我要查找的Key是“apple”:
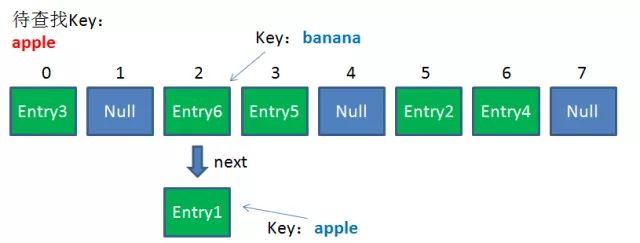
第一步,查看的是头节点Entry6,Entry6的Key是banana,显然不是我要找的结果。
第二步,查看的是Next节点Entry1,Entry1的Key是apple,正是我要找的结果。
之所以把Entry6放在头节点,是因为HashMap的发明者认为,后插入的Entry被查找的可能性更大。
高并发下的HashMap
HashMap的容量是有限的。当经过多次元素插入,使得HashMap达到一定饱和度时,Key映射位置发生冲突的几率会逐渐提高。
这时候,HashMap需要扩展它的长度,也就是进行Resize。
影响发生Resize的因素有两个:
1.Capacity
HashMap的当前长度。HashMap的长度是2的幂。
2.LoadFactor
HashMap负载因子,默认值为0.75f。
衡量HashMap是否进行Resize的条件如下:
*HashMap.Size >= Capacity LoadFactor
HashMap的Rezie不是简单的吧长度扩大,而是经过两个步骤
1.扩容
创建一个新的Entry空数组,长度是原数组的2倍。
2.ReHash
遍历原Entry数组,把所有的Entry重新Hash到新数组。为什么要重新Hash呢?因为长度扩大以后,Hash的规则也随之改变。
回顾一下Hash公式:
index = HashCode(Key) & (Length - 1)
当原数组长度为8时,Hash运算是和111B做与运算;新数组长度为16,Hash运算是和1111B做与运算。Hash结果显然不同。
Resize前的HashMap:
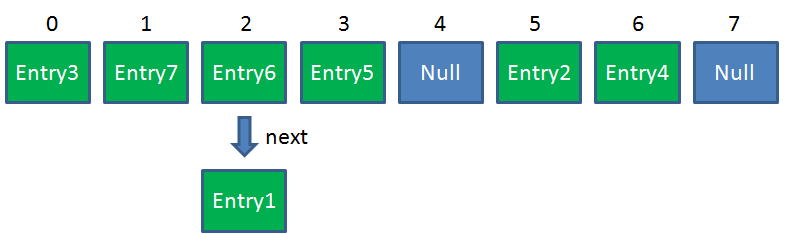
Resize后的HashMap:
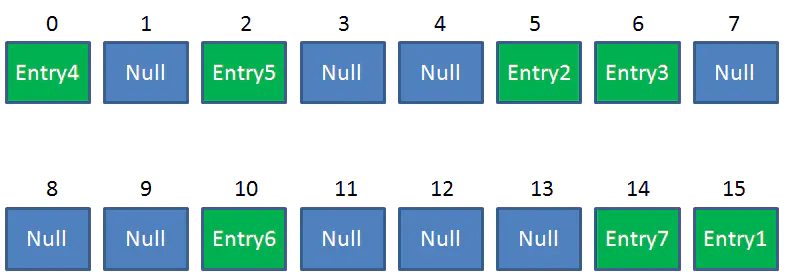
ReHash的Java代码如下:
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
单线程下执行没有问题,多线程下的Rehash有问题!
假设一个HashMap已经到了Resize的临界点。此时有两个线程A和B,在同一时刻对HashMap进行Put操作:
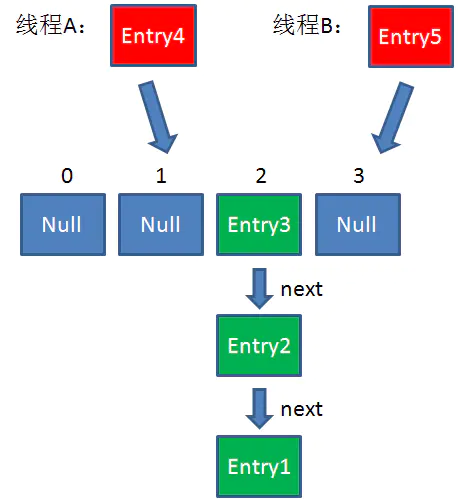
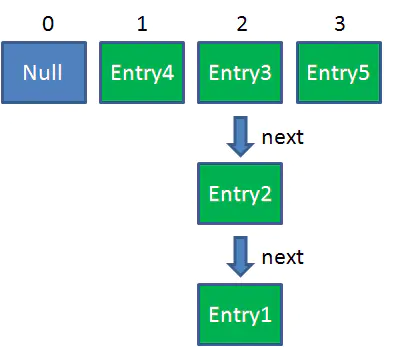
此时达到Resize条件,两个线程各自进行Rezie的第一步,也就是扩容:
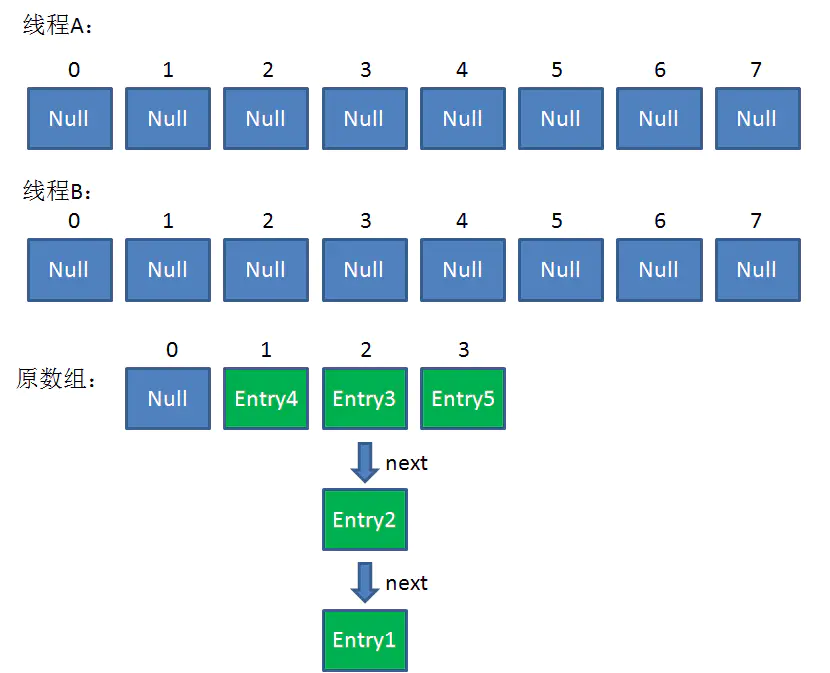
这时候,两个线程都走到了ReHash的步骤。回顾一下ReHash的代码:

假如此时线程B遍历到Entry3对象,刚执行完红框里的这行代码,线程就被挂起。对于线程B来说:
e = Entry3
next = Entry2
这时候线程A畅通无阻地进行着Rehash,当ReHash完成后,结果如下(图中的e和next,代表线程B的两个引用):

直到这一步,看起来没什么毛病。接下来线程B恢复,继续执行属于它自己的ReHash。线程B刚才的状态是:
e = Entry3
next = Entry2

当执行到上面这一行时,显然 i = 3,因为刚才线程A对于Entry3的hash结果也是3。

我们继续执行到这两行,Entry3放入了线程B的数组下标为3的位置,并且e指向了Entry2。此时e和next的指向如下:
e = Entry2
next = Entry2
整体情况如图所示:
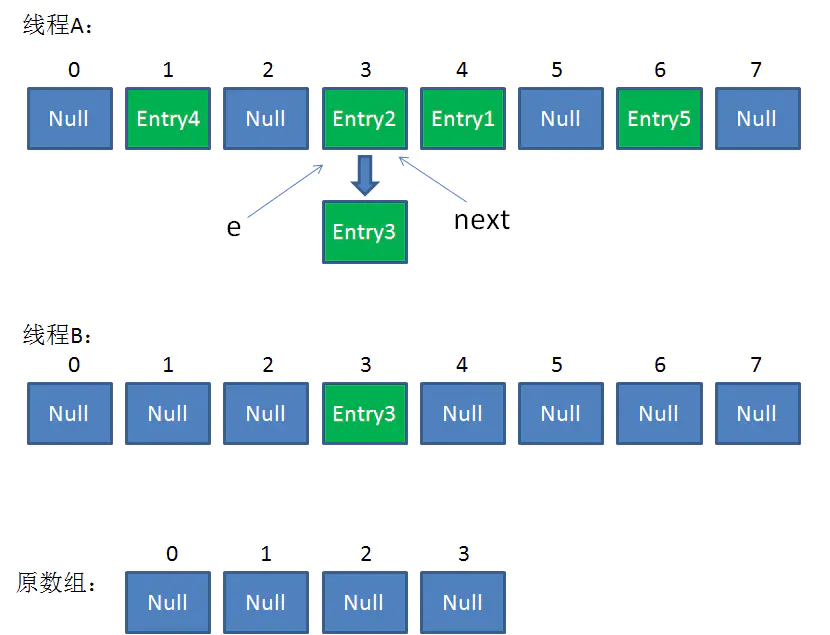
接着是新一轮循环,又执行到红框内的代码行:

e = Entry2
next = Entry3
整体情况如图所示:
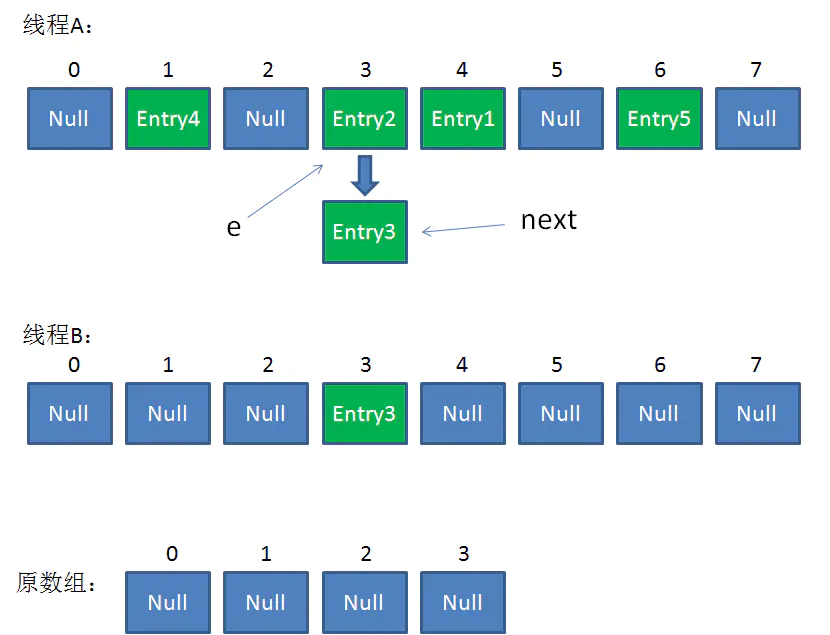
接下来执行下面的三行,用头插法把Entry2插入到了线程B的数组的头结点:

整体情况如图所示:
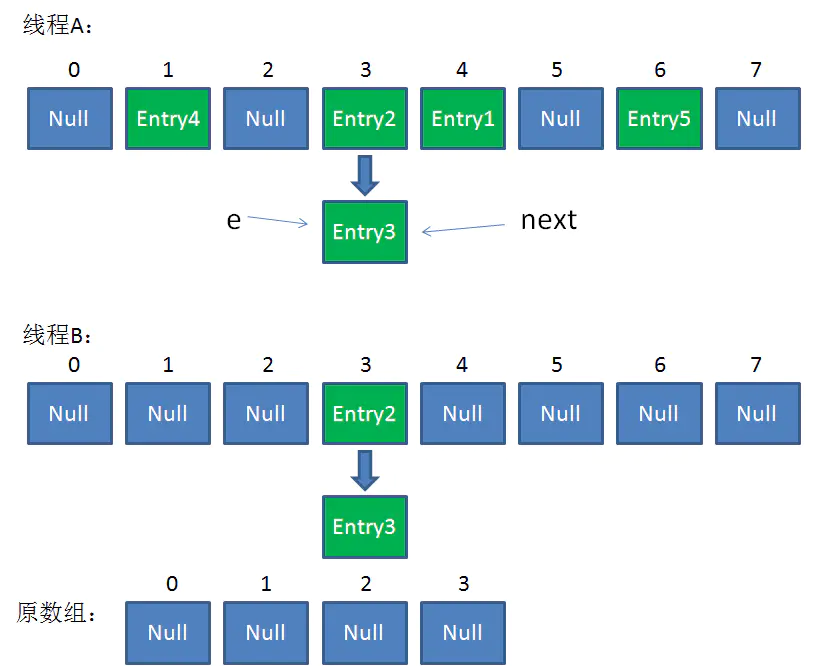
第三次循环开始,又执行到红框的代码:

e = Entry3
next = Entry3.next = null
最后一步,当我们执行下面这一行的时候 !

newTable[i] = Entry2
e = Entry3
Entry2.next = Entry3
Entry3.next = Entry2
链表出现了环形!
整体情况如图所示:
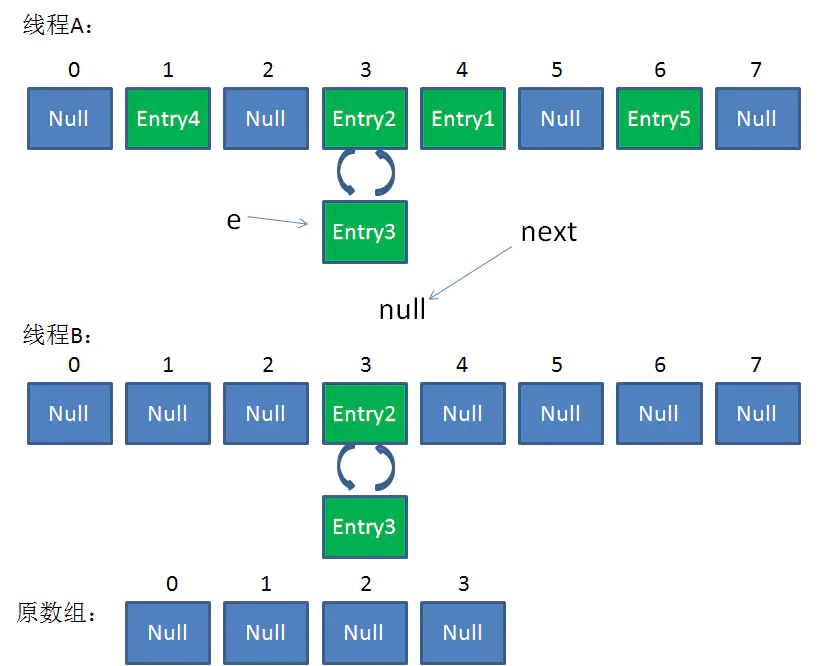
此时,问题还没有直接产生。当调用Get查找一个不存在的Key,而这个Key的Hash结果恰好等于3的时候,由于位置3带有环形链表,所以程序将会进入死循环!
在高并发下通常使用ConcurrentHashMap,这个集合类兼顾了线程安全和性能。
总结:
1.Hashmap在插入元素过多的时候需要进行Resize,Resize的条件是
HashMap.Size >= Capacity * LoadFactor。
2.Hashmap的Resize包含扩容和ReHash两个步骤,ReHash在并发的情况下可能会形成链表环。
JDK 1.8
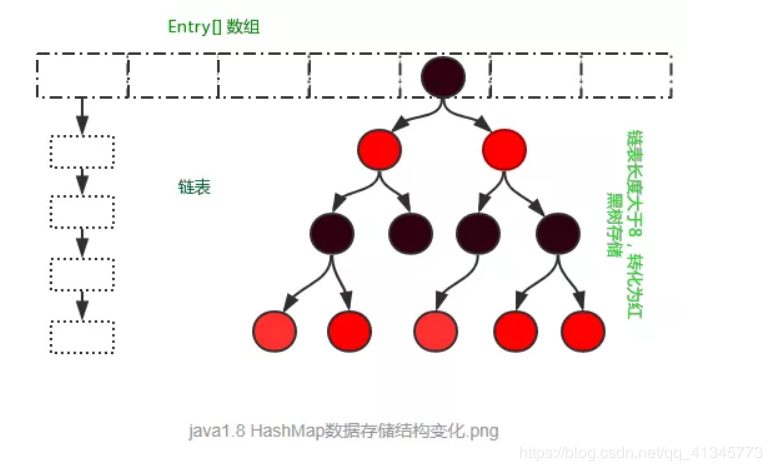
HashMap采用数组+链表+红黑树实现。
在Jdk1.8中HashMap的实现方式做了一些改变,但是基本思想还是没有变得,只是在一些地方做了优化,数据结构的存储由数组+链表的方式,变化为数组+链表+红黑树的存储方式,当链表长度超过阈值(8)时,将链表转换为红黑树。在性能上进一步得到提升。
执行构造函数,当我们看到这个new,第一反应应该是在堆内存里开辟了一块空间。
Map<String,Object> map = new HashMap<String,Object>();
构造方法:
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
初始化了一个负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
负载因子默认为0.75f
transient Node<K,V>[] table;
看到了数组,数组里原对象是Node,来看下
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value; //key,value,用来存储put的key,value值的
Node<K,V> next; // next ,用来标记下一个元素
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value; //构造函数
this.next = next;
}
put方法解析:
public V put(K key, V value) {
//调用putVal()方法完成
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断table是否初始化,否则初始化操作
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//计算存储的索引位置,如果没有元素,直接赋值
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//节点若已经存在,执行赋值操作
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//判断链表是否是红黑树
else if (p instanceof TreeNode)
//红黑树对象操作
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//为链表,
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//链表长度8,将链表转化为红黑树存储
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//key存在,直接覆盖
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//记录修改次数
++modCount;
//判断是否需要扩容
if (++size > threshold)
resize();
//空操作
afterNodeInsertion(evict);
return null;
}
如果存在key节点,返回旧值,如果不存在则返回Null。

红黑树
首先需要理解二叉查找树(Binary Search Tree)
二叉查找树(BST)具备的特性
1.左子树上所有结点的值均小于或等于它的根结点的值。
2.右子树上所有结点的值均大于或等于它的根结点的值。
3.左、右子树也分别为二叉排序树。
下图中这棵树,就是一颗典型的二叉查找树:
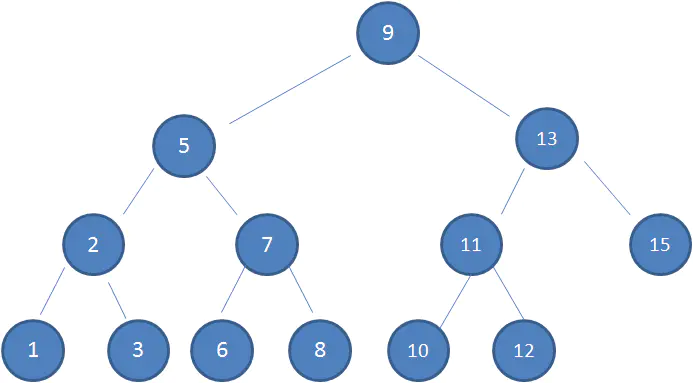
比如我要查找值为10的节点:
1、查看根节点9:
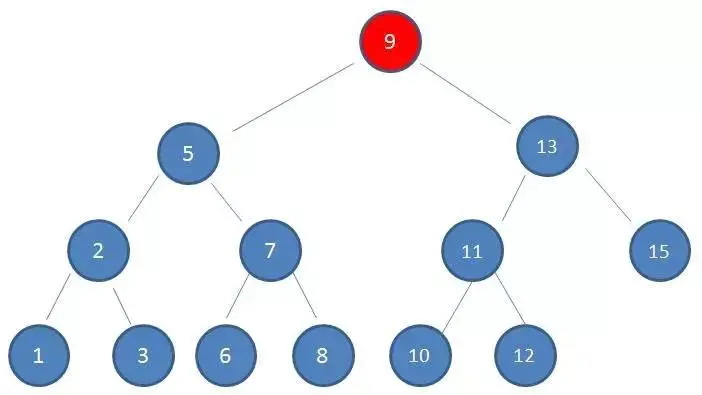
2、由于10 > 9,因此查看右孩子13:
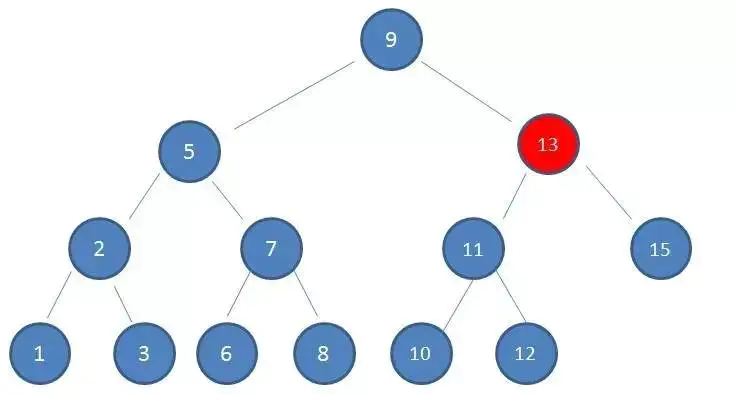
3、由于10 < 13,因此查看左孩子11:
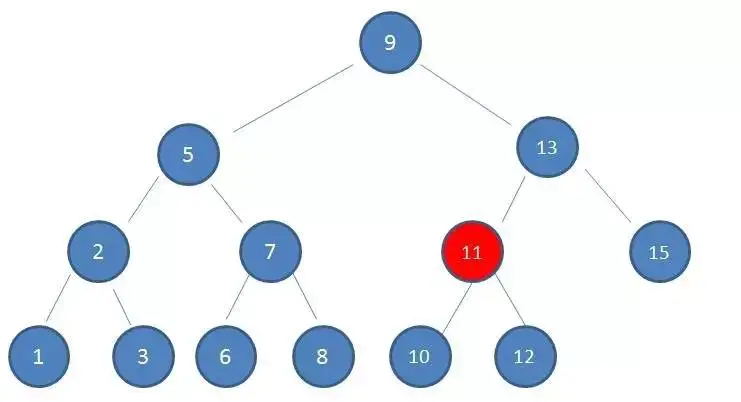
4.由于10 < 11,因此查看左孩子10,发现10正是要查找的节点:
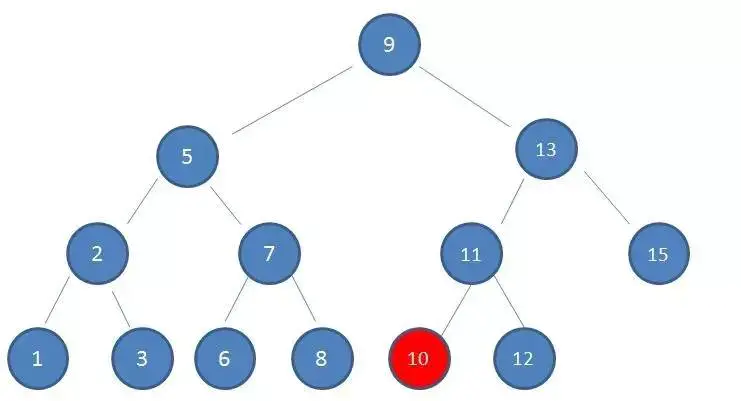
这种方式正是二分查找的思想,查找所需的最大次数等同于二叉查找树的高度。
在插入节点的时候也是利用类似的方法,通过一层一层比较大小,找到新节点适合插入的位置。
但二叉查找树存在缺陷,如:
假设初始的二叉查找树只有三个节点,根节点值为9,左孩子值为8,右孩子值为12:
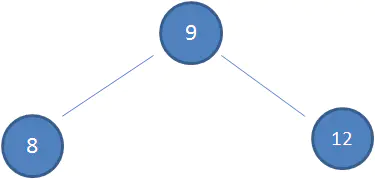
接下来我们依次插入如下五个节点:7,6,5,4,3。依照二叉查找树的特性,结果会变成如下这样:
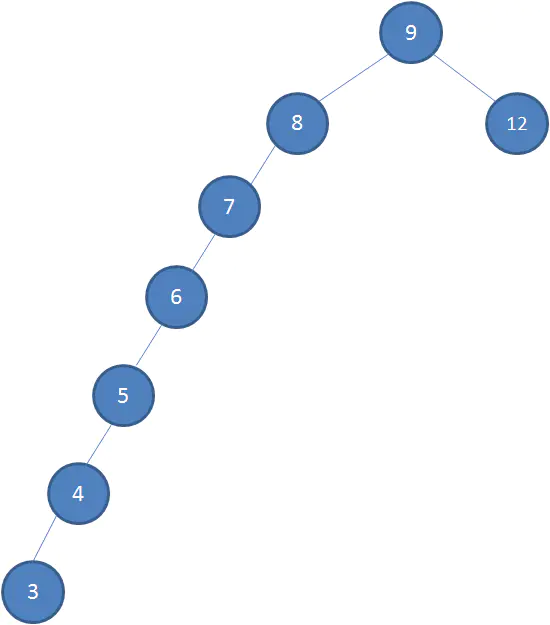
这样的形态虽然也符合二叉查找树的特性,但是查找的性能大打折扣,几乎变成的线性。
如何解决二叉查找树多次插入新节点而导致的不平衡?红黑树应运而生了。
红黑树(Red Black Tree) 是一种自平衡的二叉查找树。除了符合二叉查找树的基本特性外,它还具备下列的附加特性:
1、节点是红色或黑色。
2、根节点是黑色。
3、每个叶子节点都是黑色的空节点(NIL节点)。
4 、每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
5、从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
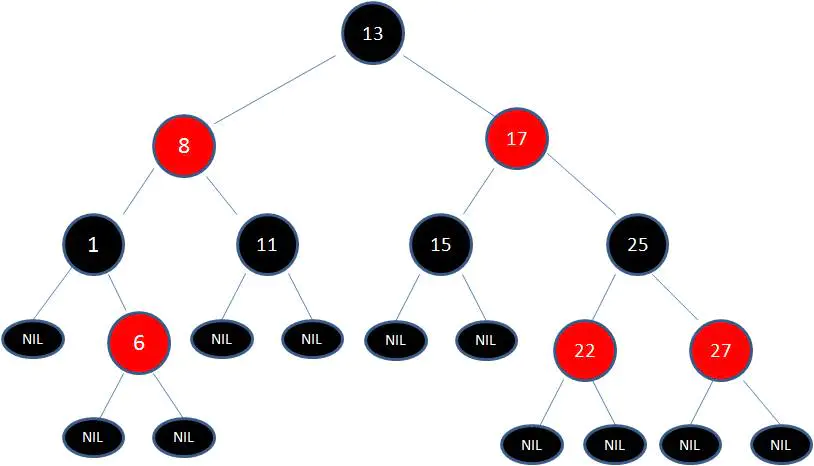
这张图就是典型的红黑树!
正是因为这些规矩限制,才保证了红黑树的自平衡。红黑树从根到叶子的最长路径不会超过最短路径的2倍。
当插入或删除节点的时候,红黑树的规则有可能被打破。这时候就需要做出一些调整,来继续维持我们的规则。
什么情况下会破坏红黑树的规则,什么情况下不会破坏规则呢?举两个简单的例子:
1、向原红黑树插入值为14的新节点:
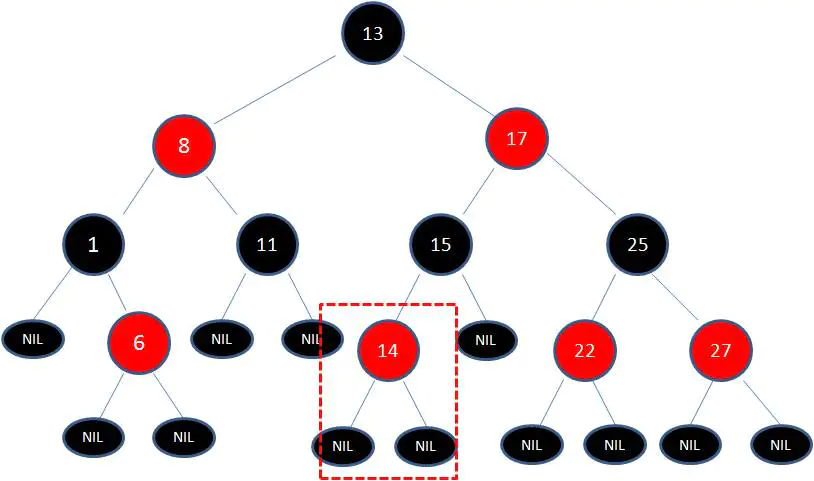
由于父节点15是黑色节点,因此这种情况并不会破坏红黑树的规则,无需做任何调整。
2、向原红黑树插入值为21的新节点:
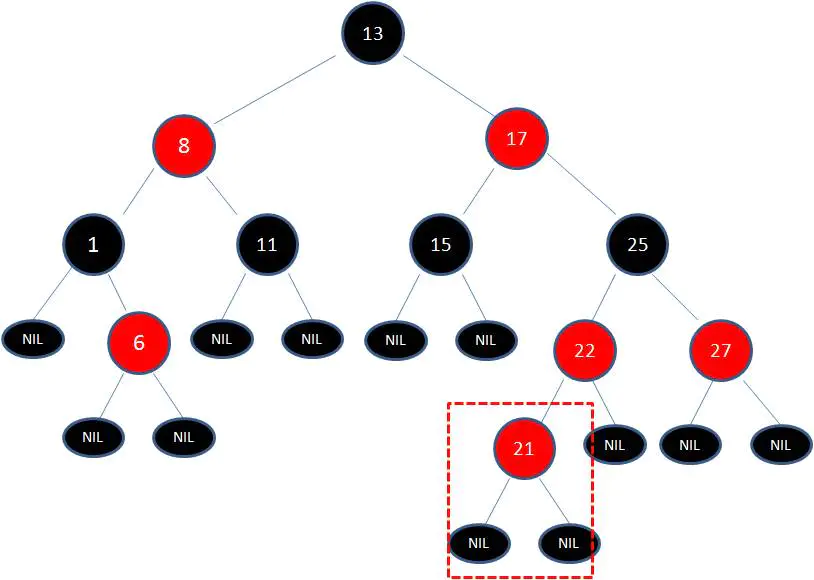
由于父节点22是红色节点,因此这种情况打破了红黑树的规则4(每个红色节点的两个子节点都是黑色),必须进行调整,使之重新符合红黑树的规则。
调整有两种方法:[变色]和[旋转]。而旋转又分成了两种形式:[左旋转]和[右旋转]。
变色
为了重新符合红黑树的规则,尝试把红色节点变为黑色,或者把黑色节点变为红色。
下图所表示的是红黑树的一部分,需要注意节点25并非根节点。因为节点21和节点22连续出现了红色,不符合规则4,所以把节点22从红色变成黑色:
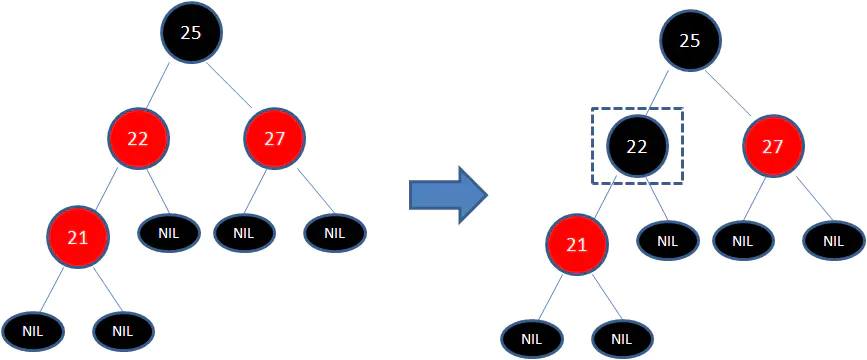
但这样并不算完,因为凭空多出的黑色节点打破了规则5,所以发生连锁反应,需要继续把节点25从黑色变成红色:
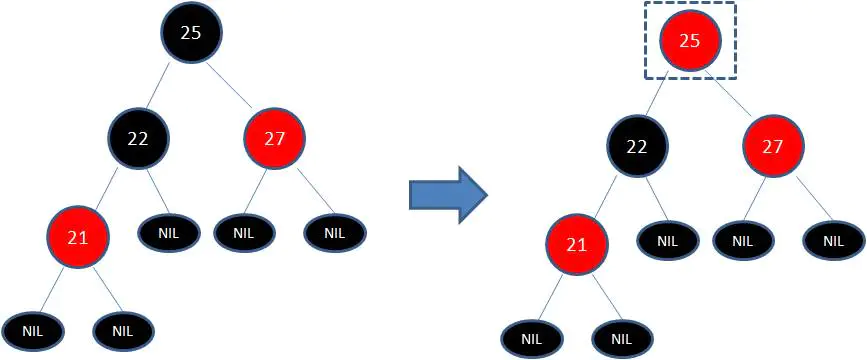
此时仍然没有结束,因为节点25和节点27又形成了两个连续的红色节点,需要继续把节点27从红色变成黑色:
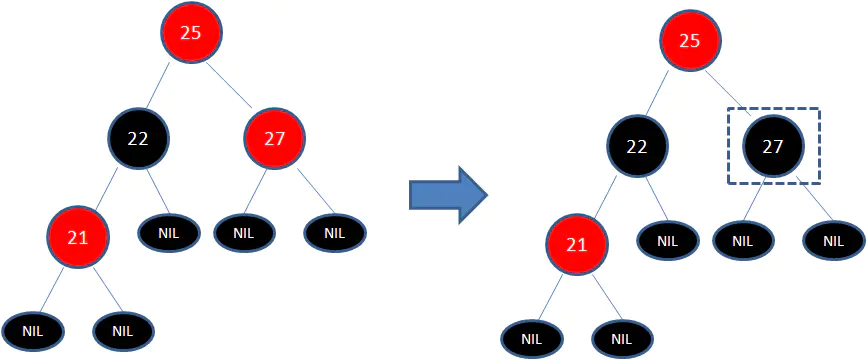
左旋转:
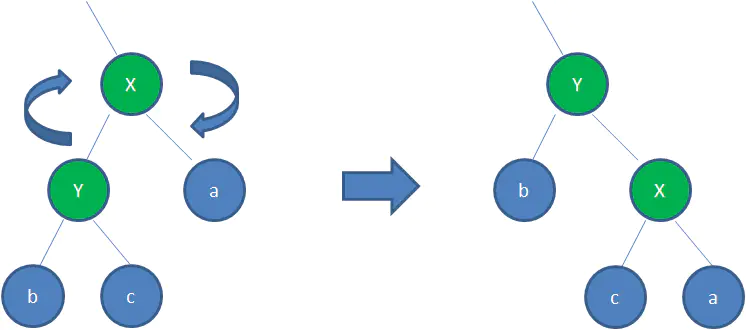
逆时针旋转红黑树的两个节点,使得父节点被自己的右孩子取代,而自己成为自己的左孩子。看下图:

图中,身为右孩子的Y取代了X的位置,而X变成了自己的左孩子。此为左旋转。
右旋转:
顺时针旋转红黑树的两个节点,使得父节点被自己的左孩子取代,而自己成为自己的右孩子。看下图:
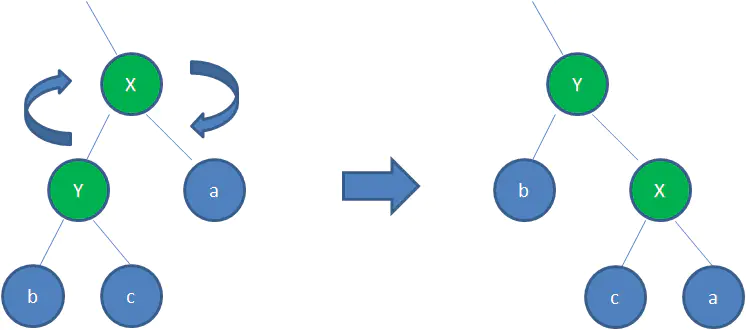
图中,身为左孩子的Y取代了X的位置,而X变成了自己的右孩子。此为右旋转。
红黑树的插入和删除包含很多种情况,每一种情况都有不同的处理方式。在这里举个典型的例子,体会一下!
我们以刚才插入节点21的情况为例:
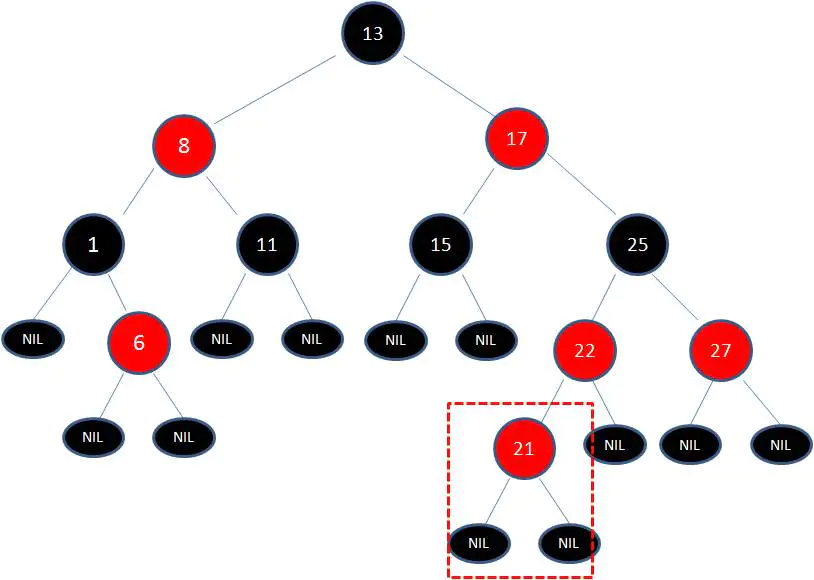
首先,我们需要做的是变色,把节点25及其下方的节点变色:
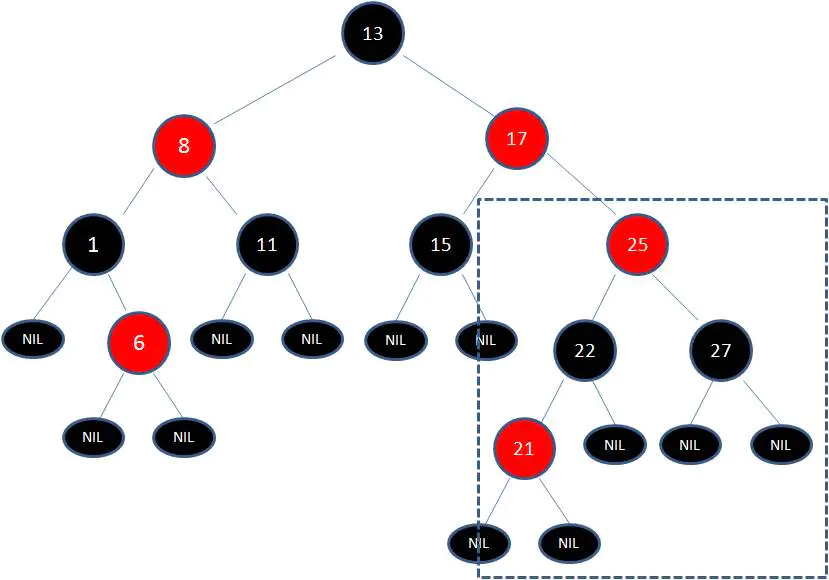
此时 节点17 和 节点25 是连续的两个红色节点,那么把节点17变成黑色节点?恐怕不合适。这样一来不但打破了规则4,而且根据规则2(根节点是黑色),也不可能把节点13变成红色节点。
变色已无法解决问题,把节点13看着X,把节点17看着Y,想刚才的示意图那样进行左旋转:

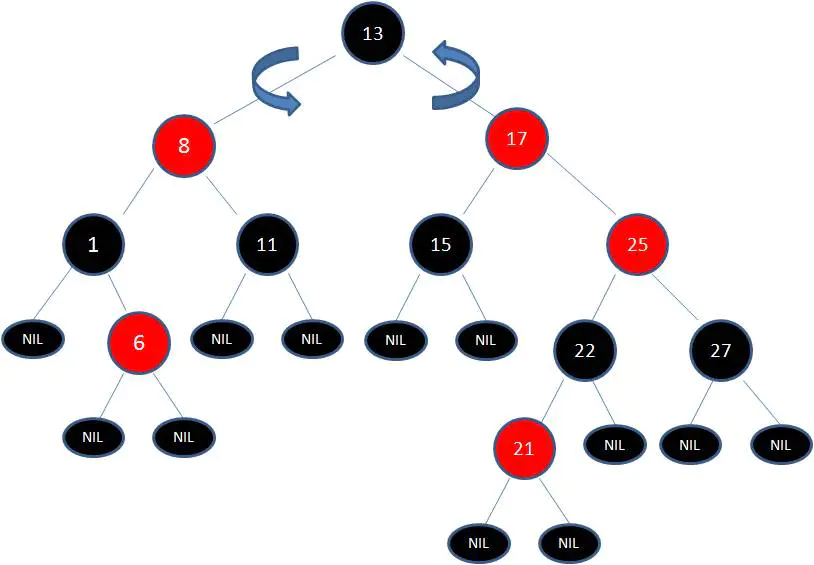
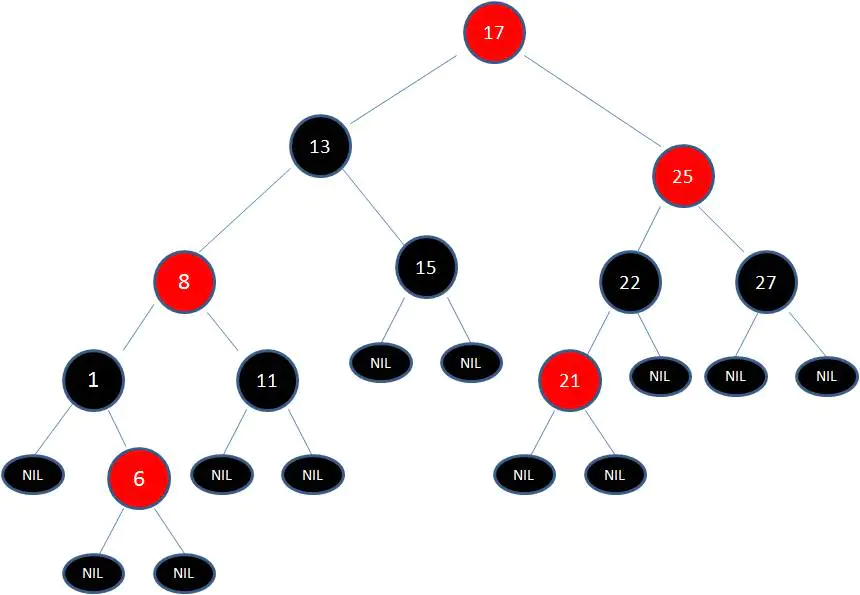
由于根节点必须是黑色节点,所以需要变色,变色结果如下:
这样就结束了吗?并没有。因为其中两条路径(17 -> 8 -> 6 -> NIL)的黑色节点个数是4,其他路径的黑色节点个数是3,不符合规则5。
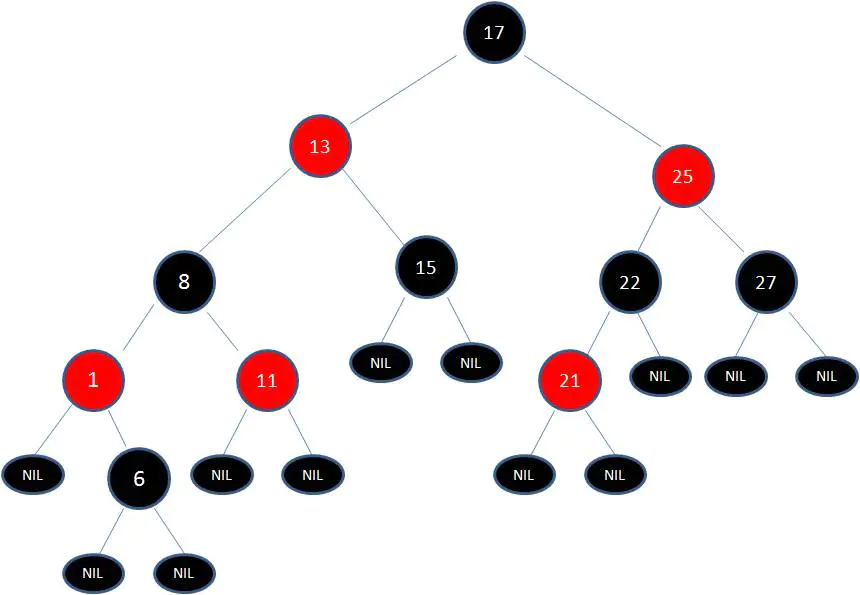
这时候我们需要把节点13看做X,节点8看做Y,像刚才的示意图那样进行右旋转:
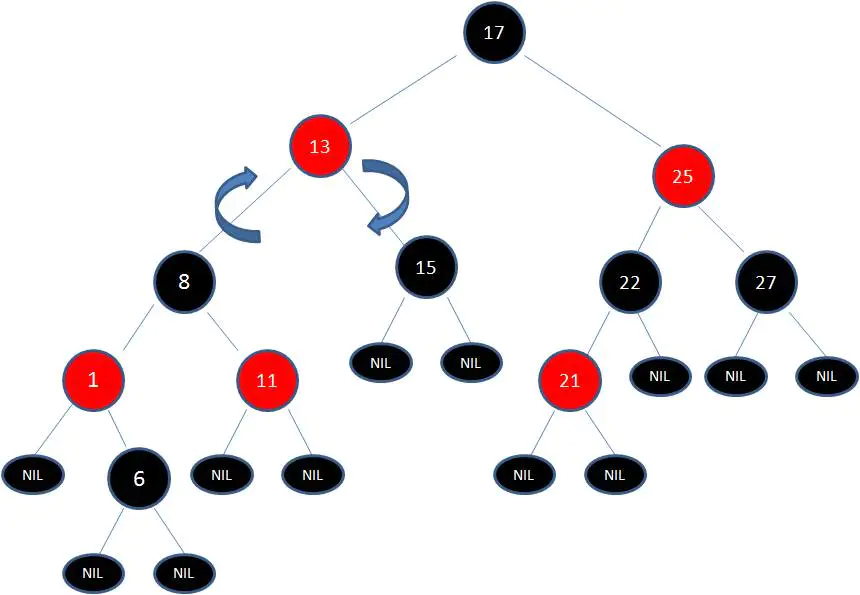
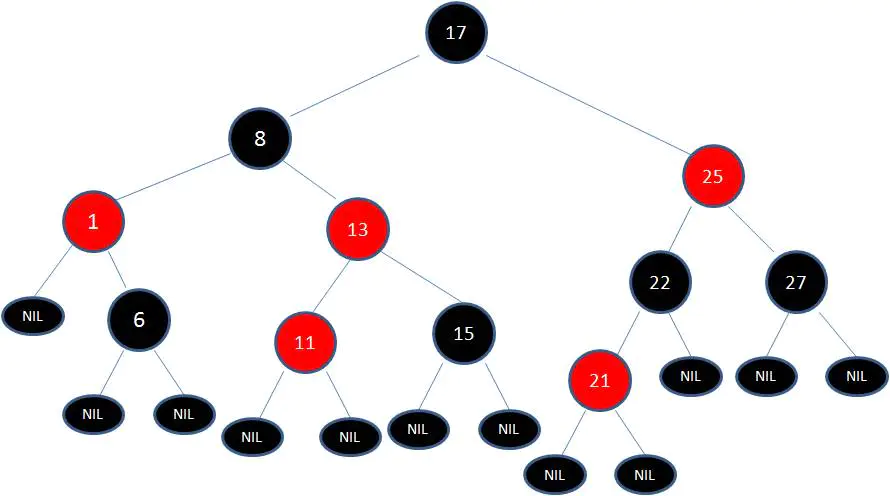
最后根据规则来进行变色:
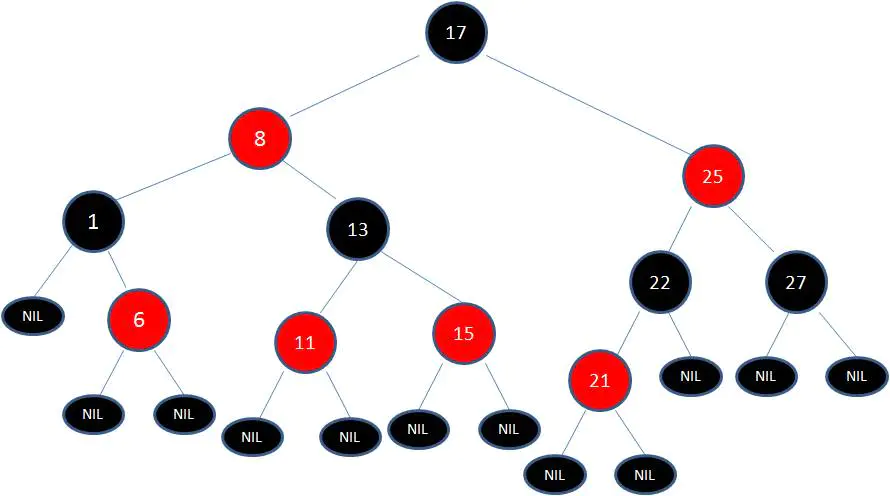
如此一来,红黑树变得重新符合规矩。 这一个例子的调整过程比较复杂,经历了如下步骤: 变色 -> 左旋转 -> 变色 -> 右旋转 -> 变色
红黑树的应用有很多,除了HashMap,jdk 的集合类TreeMap和TreeSet 底层就是红黑树实现的。
几点说明:
1、关于红黑树自平衡的调整,插入和删除节点的时候都涉及到很多种Case,由于篇幅原因无法展开来一一列举,有兴趣的朋友可以参考维基百科,里面讲的非常清晰。
2、红黑树调整过程的示例是一种比较复杂的情形,没太看明白的小伙伴也不必钻牛角尖,关键要懂得红黑树自平衡调整的主体思想。
参考文章
https://juejin.im/post/5a27c6946fb9a04509096248
https://zhuanlan.zhihu.com/p/28501879
https://blog.csdn.net/qq_41345773/article/details/92066554
HashMap1.7和1.8,红黑树原理!的更多相关文章
- Java面试题之红黑树原理
红黑树原理: 每个节点都只能是红色或黑色的: 根节点是黑色的: 每个叶节点(空节点)是黑色的: 如果一个节点是红色的,那么他的子节点都是黑色的: 从任意一个节点到其每个子节点的路径都有相同数目的黑色节 ...
- 红黑树原理详解及golang实现
目录 红黑树原理详解及golang实现 二叉查找树 性质 红黑树 性质 operation 红黑树的插入 golang实现 类型定义 leftRotate RightRotate Item Inter ...
- HashMap1.8源码分析(红黑树)
转载:https://segmentfault.com/a/1190000012926722?utm_source=tag-newest https://blog.csdn.net/weixin_40 ...
- AVL树,红黑树,B-B+树,Trie树原理和应用
前言:本文章来源于我在知乎上回答的一个问题 AVL树,红黑树,B树,B+树,Trie树都分别应用在哪些现实场景中? 看完后您可能会了解到这些数据结构大致的原理及为什么用在这些场景,文章并不涉及具体操作 ...
- 红黑树之 原理和算法详细介绍(阿里面试-treemap使用了红黑树) 红黑树的时间复杂度是O(lgn) 高度<=2log(n+1)1、X节点左旋-将X右边的子节点变成 父节点 2、X节点右旋-将X左边的子节点变成父节点
红黑树插入删除 具体参考:红黑树原理以及插入.删除算法 附图例说明 (阿里的高德一直追着问) 或者插入的情况参考:红黑树原理以及插入.删除算法 附图例说明 红黑树与AVL树 红黑树 的时间复杂度 ...
- jdk1.8 HashMap红黑树操作详解-putTreeVal()
以前也看过hashMap源码不过是看的jdk1.7的,由于时间问题看的也不是太深入,只是大概的了解了一下他的基本原理:这几天通过假期的时间就对jdk1.8的hashMap深入了解了下,相信大家都是对红 ...
- 大数据学习--day17(Map--HashMap--TreeMap、红黑树)
Map--HashMap--TreeMap--红黑树 Map:三种遍历方式 HashMap:拉链法.用哈希函数计算出int值. 用桶的思想去存储元素.桶里的元素用链表串起来,之后长了的话转红黑树. T ...
- 各种查找算法的选用分析(顺序查找、二分查找、二叉平衡树、B树、红黑树、B+树)
目录 顺序查找 二分查找 二叉平衡树 B树 红黑树 B+树 参考文档 顺序查找 给你一组数,最自然的效率最低的查找算法是顺序查找--从头到尾挨个挨个遍历查找,它的时间复杂度为O(n). 二分查找 而另 ...
- HashMap 的工作原理及代码实现,什么时候用到红黑树
HashMap工作原理及什么时候用到的红黑树: 在jdk 1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里.但是当位于一个桶中的元素较多,即has ...
随机推荐
- 使用 vi 命令创建一个cpp文件
mkdir text //创建一个text的文件夹 cd text //打开text的文件夹 vi text.cpp //创建text.cpp 按住 i 键输入程序 输入后按esc,再按wq退出 ls ...
- 设计模式之GOF23代理模式02
静态代理 模拟经纪人与明星开演唱会 public interface Star { /** * 面谈 */ void confer(); /** * 签合同 */ void sign ...
- [hdu4301]DP
题意:给一个2*n的矩形块,求把它分成k个连通块的方法数.(有公共边即视为联通) 思路:由于宽度只有2,于是很容易设计状态使问题满足阶段性以及无后效性.具体来说,令dp[i][j][0]和dp[i][ ...
- Akko海洋之星
今天(2020.5.14)入手Akko海洋之星84茶轴,开心呀~~ 考虑方面: 价格>键线分离>接线接口>轴体>键帽>材质 价格: 200~500之间入门级cherry轴 ...
- 部署SSL站点 IIS+asp.net
使用SSL必须要有证书,今天我们就使用IIS内置的证书完成SSL的部署. 1.打开MMC证书管理器,文件->添加/删除管理单元->证书,双击->确定 2.找到:个人->证书下有 ...
- centos6下filebeat多开问题
centos6下filebeat多开问题 0. 场景 比如之前在用filebeat做收集,但是想新开一个实例把之前的日志全部重新导一遍,如果直接指定filebeat -c 是不行的,因为filebea ...
- Redux:with React(一)
作者数次强调,redux和React没有关系(明明当初就是为了管理react的state才弄出来的吧),它可以和其他插件如 Angular, Ember, jQuery一起使用.好啦好啦知道啦.Red ...
- Python的第三方web开发框架Django
1.Django Django是一个基于Python的第三方Web应用开发框架,可以简化Web开发. 官网:https://www.djangoproject.com/ 主要特点: ①采用MVC模型变 ...
- 愉快地使用Open Live Writer写博客
想要坚持写博客的习惯,却又无法忍受网页编辑器的各种不方便?open live writer是一个不错的选择.对我来说最有诱惑的就是能够快速的黏贴图片.代码.使用过程遇到不少坑,最坑的就是不能使用163 ...
- python3.x 基础五:模块
1.定义 模块:本质是.py结尾的python文件,从逻辑上组织python代码,可以是变量,函数,类,逻辑,目的是实现一个功能,test.py 对应模块名:test 包:从逻辑上组织模块的,本质就是 ...