新闻网大数据实时分析可视化系统项目——3、Hadoop2.X分布式集群部署
(一)hadoop2.x版本下载及安装
Hadoop 版本选择目前主要基于三个厂商(国外)如下所示:
1.基于Apache厂商的最原始的hadoop版本, 所有发行版均基于这个版本进行改进。
2.基于HortonWorks厂商的开源免费的hdp版本。
3.基于Cloudera厂商的cdh版本,Cloudera有免费版和企业版, 企业版只有试用期。不过cdh大部分功能都是免费的。
(二)hadoop2.x分布式集群配置
1.集群资源规划设计
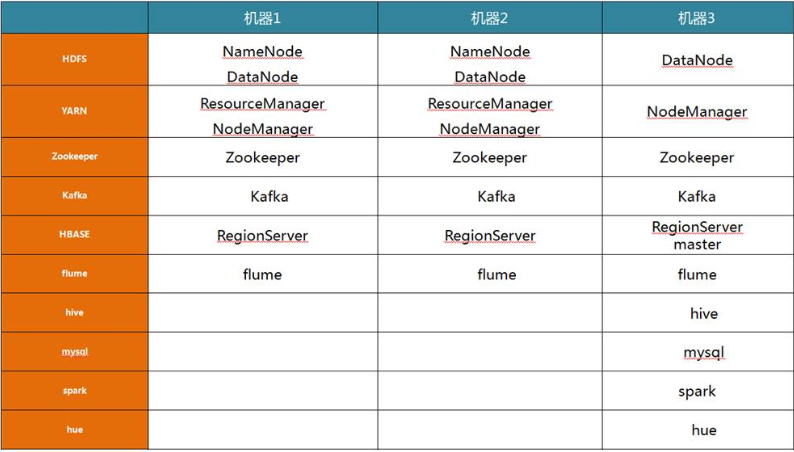
2.hadoop2.x分布式集群配置
1)hadoop2.x分布式集群配置-HDFS
安装hdfs需要修改4个配置文件:hadoop-env.sh、core-site.xml、hdfs-site.xml和slaves
2)hadoop2.x分布式集群配置-YARN
安装yarn需要修改4个配置文件:yarn-env.sh、mapred-env.sh、yarn-site.xml和mapred-site.xml
(三)分发到其他各个机器节点
hadoop相关配置在第一个节点配置好之后,可以通过脚本命令分发给另外两个节点即可,具体操作如下所示。
#将安装包分发给第二个节点
scp -r hadoop-2.5.0 kaf@bigdata-pro02.kfk.com:/opt/modules/
#将安装包分发给第三个节点
scp -r hadoop-2.5.0 kaf@bigdata-pro02.kfk.com:/opt/modules/
(四)HDFS启动集群运行测试
hdfs相关配置好之后,可以启动hdfs集群。
1.格式化NameNode
通过命令:bin/hdfs namenode -format 格式化NameNode。
2.启动各个节点机器服务
1)启动NameNode命令:sbin/hadoop-daemon.sh start namenode
2) 启动DataNode命令:sbin/hadoop-daemon.sh start datanode
3)启动ResourceManager命令:sbin/yarn-daemon.sh start resourcemanager
4)启动NodeManager命令:sbin/yarn-daemon.sh start resourcemanager
5)启动log日志命令:sbin/mr-jobhistory-daemon.sh start historyserver
(五)YARN集群运行MapReduce程序测试
前面hdfs和yarn都启动起来之后,可以通过运行WordCount程序检测一下集群是否能run起来。
集群自带的WordCount程序执行命令:bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount input output
(六)ssh无秘钥登录
在集群搭建的过程中,需要不同节点分发文件,那么节点间分发文件每次都需要输入密码,比较麻烦。另外在hadoop 集群启动过程中,也需要使用批量脚本统一启动各个节点服务,此时也需要节点之间实现无秘钥登录。具体操作步骤如下所示:
1.主节点上创建 .ssh 目录,然后生成公钥文件id_rsa.pub和私钥文件id_rsa
mkdir .ssh
ssh-keygen -t rsa
2.拷贝公钥到各个机器
ssh-copy-id bigdata-pro1.kfk.com
ssh-copy-id bigdata-pro2.kfk.com
ssh-copy-id bigdata-pro3.kfk.com
3.测试ssh连接
ssh bigdata-pro1.kfk.com
ssh bigdata-pro2.kfk.com
ssh bigdata-pro3.kfk.com
4.测试hdfs
ssh无秘钥登录做好之后,可以在主节点通过一键启动命令,启动hdfs各个节点的服务,具体操作如下所示:
sbin/start-dfs.sh
如果yarn和hdfs主节点共用,配置一个节点即可。否则,yarn也需要单独配置ssh无秘钥登录。
(七)配置集群内机器时间同步(使用Linux ntp进行)
选择一台机器作为时间服务器,比如bigdata-pro1.kfk.com节点。
1.查看ntp服务是否已经存在
sudo rpm -qa|grep ntp
2.ntp服务相关操作
1)查看ntp状态
sudo service ntpd status
2)启动ntp
sudo service ntpd start
3)关闭ntp
sudo service ntpd stop
3.设置ntp随机器启动
sudo chkconfig ntpd on
4.修改ntp配置文件
vi /etc/ntp.conf
#释放注释并将ip地址修改为
restrict 192.168.31.151 mask 255.255.255.0 nomodify notrap
#注释掉以下命令行
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
#释放以下命令行
server 127.127.1.0 #local clock
fudge 127.127.1.0 stratum 10
重启ntp服务
sudo service ntpd restart
5.修改服务器时间
#设置当前日期
sudo date -s 2017-06-16
#设置当前时间
sudo date -s 22:06:00
6.其他节点手动同步主服务器时间
#查看ntp位置
which ntpdate
/usr/sbin/ntpdate
1)手动同步bigdata-pro2.kfk.com节点时间
sudo /usr/sbin/ntpdate bigdata-pro2.kfk.com
2)手动同步bigdata-pro3.kfk.com节点时间
sudo /usr/sbin/ntpdate bigdata-pro3.kfk.com
7.其他节点定时同步主服务器时间
bigdata-pro2.kfk.com和bigdata-pro3.kfk.com节点分别切换到root用户, 通过crontab -e 命令,每10分钟同步一次主服务器节点的时间。
crontab -e
#定时,每隔10分钟同步bigdata-pro1.kfk.com服务器时间
0-59/10 * * * * /usr/sbin/ntpdate bigdata-pro1.kfk.com
新闻网大数据实时分析可视化系统项目——3、Hadoop2.X分布式集群部署的更多相关文章
- 新闻网大数据实时分析可视化系统项目——6、HBase分布式集群部署与设计
HBase是一个高可靠.高性能.面向列.可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建 大规模结构化存储集群. HBase 是Google Bigtable 的开源实现,与 ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
- 新闻网大数据实时分析可视化系统项目——16、Spark2.X集群运行模式
1.几种运行模式介绍 Spark几种运行模式: 1)Local 2)Standalone 3)Yarn 4)Mesos 下载IDEA并安装,可以百度一下免费文档. 2.spark Standalone ...
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——14、Spark2.X环境准备、编译部署及运行
1.Spark概述 Spark 是一个用来实现快速而通用的集群计算的平台. 在速度方面, Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理 ...
- 新闻网大数据实时分析可视化系统项目——12、Hive与HBase集成进行数据分析
(一)Hive 概述 (二)Hive在Hadoop生态圈中的位置 (三)Hive 架构设计 (四)Hive 的优点及应用场景 (五)Hive 的下载和安装部署 1.Hive 下载 Apache版本的H ...
随机推荐
- sort的使用
sort主要是用来排序的,可以用自定义的函数进行比较,也可以用系统的4中函数进行比较,即less(),greater(),less_equal(),greater_equal().但是我试了一下,发现 ...
- LeetCode练题——67. Add Binary
1.题目 67. Add Binary——easy Given two binary strings, return their sum (also a binary string). The inp ...
- Vue——前端生成二维码
与后端生成二维码相比,前端生成二维码更具有灵活性,下面就介绍两种前端生成二维码的方式,两种方式相比之下,vue-qr比qrcode多了一个再中间添加logo的功能. 方式一:qrcode npm np ...
- leetcode 0215
目录 ✅ 1002. 查找常用字符 描述 解答 java other's implementation(todo watch me) cpp py ✅ 821. 字符的最短距离 描述 解答 cpp p ...
- springboot 打包成jar
1.pom.xml配置 <build> <plugins> <plugin> <groupId>org.apache.maven.plugins< ...
- Nginx企业级优化!(重点)
隐藏Nginx版本号!(重点) 在生产环境中,需要隐藏 Nginx 的版本号,以避免安全漏洞的泄漏 一旦有黑客知道Nginx版本号便可以利用Nginx漏洞进行攻击,严重影响到了公司的安全 查看隐藏版本 ...
- Mybatis学习day2
Mybatis初探 之前已经用利用mybatis实现链接数据库查询所有用户的信息(用的是在resources下建立和Dao层一样目录的xml实现的).这次再来看一下增删改查等其它的操作. 利用Myba ...
- IDEA工具java开发之 代码重构Refactor 重命名 删除移动复制 生成变量 抽取方法
一.重命名 用shift + F6 或者右键单击 二.抽取方法 .三.生成变量 . 四.文件移动复制和删除 可以右键
- Ollydbg使用问题汇总
1.可疑的断点 描述:看上去您想在一些命令的中间位置或数据中设置断点. 如果真是这样的话, 这些断点将不会执行并可能严重影响调试的程序. 您真的希望在此设置断点吗? 选择 否 的话还是会出现这个问题 ...
- PCF8591 AD/DA模块使用详解
I2C PCF8591 8位AD/DA转换 BCM2835 Library 1.PCF8591T简述 PCF8591器件图如下: PCF8591是一个8位的CMOS数据采集器件,具有4个模拟输入(其中 ...