第1节 storm编程:4、storm环境安装以及storm编程模型介绍
dataSource:数据源,生产数据的东西
spout:接收数据源过来的数据,然后将数据往下游发送
bolt:数据的处理逻辑单元。可以有很多个,基本上每个bolt都处理一部分工作,然后将数据继续往下游的bolt发送
storm不会保存数据,也不会生产数据,只是一个数据的搬运工
tuple:元组的概念,可以理解为一个数组,或者一个集合,里面可以封装很多东西,数据从上游往下游发送,都是封装在tuple里面了
topology:spout与bolt组织到一起,形成一个topology
注意,配置文件比较严格,直接拷贝,尽量不要去手写!
===========================================
1、 storm的安装
三台机器运行服务规划
|
运行服务\机器规划 |
Node01 |
Node02 |
Node03 |
|
Zookeeper版本 |
3.4.5 |
||
|
Zookeeper服务 |
是 |
是 |
是 |
|
Storm版本 |
Apache-storm-1.1.1 |
||
|
Nimbus服务 |
是(leader) |
是 |
是 |
|
Supervisor服务 |
是 |
是 |
是 |
|
IP地址规划 |
192.168.52.100 |
192.168.52.110 |
192.168.52.120 |
3.1三台机器安装zookeeper服务
Node01配置文件修改
修改zoo.cfg
dataDir=/export/servers/zookeeper-3.4.9/zkData/data
dataLogDir=/export/servers/zookeeper-3.4.9/zkData/log
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
修改myid
Node02 修改配置文件
修改zoo.cfg
dataDir=/export/servers/zookeeper-3.4.9/zkData/data
dataLogDir=/export/servers/zookeeper-3.4.9/zkData/log
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
修改myid
Node03修改配置文件
修改zoo.cfg
dataDir=/export/servers/zookeeper-3.4.9/zkData/data
dataLogDir=/export/servers/zookeeper-3.4.9/zkData/log
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
修改myid
三台服务器启动zookeeper服务
bin/zkServer.sh start
三台机器查看zookeeper服务状态
bin/zkServer.sh status
3.2、三台机器安装storm集群
1、上传storm压缩包
2、解压
tar -zxvf apache-storm-1.1.1.tar.gz -C ../servers/
3、修改配置文件
storm.zookeeper.servers:
- "node01"
- "node02"
- "node03"
#
nimbus.seeds: ["node01", "node02", "node03"]
storm.local.dir: "/export/servers/apache-storm-1.1.1/stormdata"
ui.port: 8088 #修改为8089,因为和kafka的8088冲突了
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
4、将storm安装程序分发拷贝到另外两台机器上
scp -r apache-storm-1.1.1/ node02:/export/servers/
scp -r apache-storm-1.1.1/ node03:$PWD
2、 三台机器启动storm服务
Node01 启动相关服务
启动 nimbus进程
nohup bin/storm nimbus >/dev/null 2>&1 &
启动web UI
nohup bin/storm ui >/dev/null 2>&1 &
启动logViewer
nohup bin/storm logviewer >/dev/null 2>&1 &
启动supervisor
nohup bin/storm supervisor >/dev/null 2>&1 &
Node02启动相关服务
nimbus:nohup bin/storm nimbus >/dev/null 2>&1 &
logviewer:nohup bin/storm
logviewer >/dev/null 2>&1 &
supervisor:nohup bin/storm
supervisor >/dev/null 2>&1 &
node03启动相关服务
nimbus:nohup bin/storm
nimbus >/dev/null 2>&1 &
logviewer:nohup bin/storm
logviewer >/dev/null 2>&1 &
supervisor:nohup bin/storm
supervisor >/dev/null 2>&1 &
4、 storm的UI界面管理
访问地址
http://192.168.8.100:8089/index.html 或者
http://node01:8089/
2.
storm的编程模型
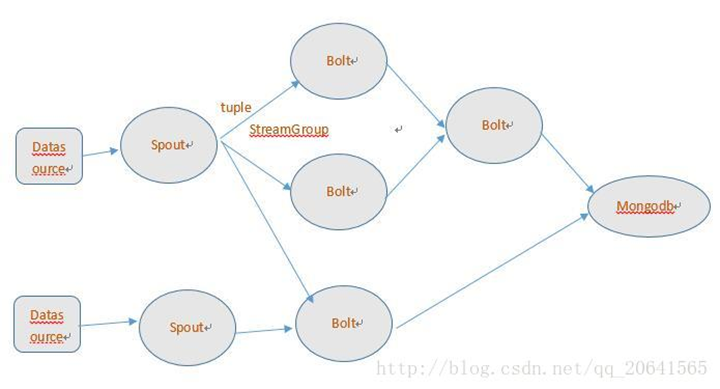
DataSource:外部数据源
Spout:接受外部数据源的组件,将外部数据源转化成Storm内部的数据,以Tuple为基本的传输单元下发给Bolt
Bolt:接受Spout发送的数据,或上游的bolt的发送的数据。根据业务逻辑进行处理。发送给下一个Bolt或者是存储到某种介质上。介质可以是mongodb或mysql,或者其他。
Tuple:Storm内部中数据传输的基本单元,里面封装了一个List对象,用来保存数据。
StreamGrouping:数据分组策略
7种:shuffleGrouping(Random函数),
Non Grouping(Random函数),
FieldGrouping(Hash取模)、
Local or ShuffleGrouping 本地或随机,优先本地。
其中Local or
ShuffleGrouping 是如果分组的时候接收bolt的线程和发送者在一个JVM中默认优先选择一个JVM中的bolt就是local,否则和ShuffleGrouping效果一样。
第1节 storm编程:4、storm环境安装以及storm编程模型介绍的更多相关文章
- kafka和storm集群的环境安装
前言 storm和kafka集群安装是没有必然联系的,我将这两个写在一起,是因为他们都是由zookeeper进行管理的,也都依赖于JDK的环境,为了不重复再写一遍配置,所以我将这两个写在一起.若只需一 ...
- Java SE 9(JDK9)环境安装及交互式编程环境Jshell使用示例
目的 安装JDK 9, 练习Jshell工具的使用, 体验Java的交互式编程环境. 什么是Jshell 其实就是一个命令行工具,安装完JDK9后,可以在bin目录下找到该工具,与Python的解释器 ...
- Web编程:JSP环境安装与配置
Web服务器:Tomcat 数据库服务器:暂时未使用 集成开发环境:eclipse 要运行JSP程序,首先要安装JDK(Java Developer Kit),并且还要配置运行Java程序的环境变量. ...
- Java网络编程:OSI七层模型和TCP/IP模型介绍
OSI(Open System Interconnection),开放式系统互联参考模型 .是一个逻辑上的定义,一个规范,它把网络协议从逻辑上分为了7层.每一层都有相关.相对应的物理设备,比如常规的路 ...
- Storm入门(二)集群环境安装
1.集群规划 storm版本的变更:storm0.9.x storm0.10.x storm1.x上面这些版本里面storm的核心源码是由Java+clojule组成的.storm2.x后期这个 ...
- Storm 学习之路(五)—— Storm编程模型详解
一.简介 下图为Strom的运行流程图,在开发Storm流处理程序时,我们需要采用内置或自定义实现spout(数据源)和bolt(处理单元),并通过TopologyBuilder将它们之间进行关联,形 ...
- Storm 学习之路(三)—— Storm单机版本环境搭建
1. 安装环境要求 you need to install Storm’s dependencies on Nimbus and the worker machines. These are: Jav ...
- Redis安装,mongodb安装,hbase安装,cassandra安装,mysql安装,zookeeper安装,kafka安装,storm安装大数据软件安装部署百科全书
伟大的程序员版权所有,转载请注明:http://www.lenggirl.com/bigdata/server-sofeware-install.html 一.安装mongodb 官网下载包mongo ...
- 第一节:ASP.NET开发环境配置
第一节:ASP.NET开发环境配置 什么是ASP.NET,学这个可以做什么,学习这些有什么内容? ASP.NET是微软公司推出的WEB开发技术. 2002年,推出第一个版本,先后推出ASP.NET2. ...
随机推荐
- js中ES6的Set的基本用法
ES6 提供了新的数据结构 Set.它类似于数组,但是成员的值都是唯一的,没有重复的值. const s = new Set(); [2,3,5,4,5,2,2].forEach(x => s. ...
- 计算机基础 - 动态规划、分治法、memo
动态规划 ≈ 分治法 + memo def memo(func): cache = {} def wrap(*args): if args not in cache: cache[args] = fu ...
- 4_3 救济金发放(UVa133)<子过程/函数设计>
为了缩短领救济品的队伍,NNGLRP决定了以下策略:每天所有来申请救济品的人会被放在一个大圆圈,面朝里面.标明一个人为编号1号,其他的就从那个人开始逆时针开始编号直到N.一个官员一开始逆时针数,数k个 ...
- Centos5.5更新源
将之前的CentOS-Base.repo文件里的内容换成如下内容 vi /etc/yum.repos.d/CentOS-Base.repo # CentOS-Base.repo## The mirro ...
- 《实战Java高并发程序设计》读书笔记二
第二章 Java并行程序基础 1.线程的基本操作 线程:进程是线程的容器,线程是轻量级进程,是程序执行的最小单位,使用多线程而不用多进程去进行并发程序设计是因为线程间的切换和调度的成本远远的小于进程 ...
- WPS/office使用技巧系列
一 WPS中如果要对比2个文档,不想以标签形式打开而是以多窗口形式,该怎么操作? 点击WPS左上角的蓝色或绿色框-->选项->->视图->勾选在任务栏中显示所有窗口,恢复书签模 ...
- [转]轻松理解AOP思想(面向切面编程)
原文链接 Spring是什么 先说一个Spring是什么吧,大家都是它是一个框架,但框架这个词对新手有点抽象,以致于越解释越模糊,不过它确实是个框架的,但那是从功能的角度来定义的,从本质意义上来讲,S ...
- Kubernetes集群部署及简单命令行操作
三个阶段部署docker:https://www.cnblogs.com/rdchenxi/p/10381631.html 环境准备 [root@master ~]# hostnamectl set- ...
- C 语言入门---第十一章---C语言重要知识点补充
====C语言typedef 的用法==== 1. C语言允许为一个数据类型起一个新的别名,就像给人起绰号一样. typedef OldName newName; typedef 和 #define ...
- C++11常用特性介绍——nullptr关键字及用法
一.nullptr关键字及用法 1)NULL的二义性 void func(int) {} void func(int*) {} 当函数调用func(NULL)时会执行哪个函数呢? 先看C++对NULL ...