tf-idf、朴素贝叶斯的短文本分类简述
朴素贝叶斯分类器(Naïve Bayes classifier)是一种相当简单常见但是又相当有效的分类算法,在监督学习领域有着很重要的应用。朴素贝叶斯是建立在“全概率公式”的基础下的,由已知的尽可能多的事件A、B求得的$P(A|B)$来推断未知$P(B|A)$。
优点:
- 模型训练使用TF-IDF对训练数据做词频及概率统计;
- 分类使用朴素贝叶斯计算所有类目的概率;
- 适用于电商的短文本分类,加入部分人工干预,top3准确率可达到95%左右;
- 分类预测完全可解释,不存在神经网络黑盒,但比较依赖分词效果;
- 训练数据类目下数据不均衡基本不会影响模型准确率。
缺点:
- 比较依赖分词效果;
- 大规模分类任务模型文件较大(与神经网络相比)。
TF-IDF
tf-idf经常被用于提取文章的关键词(Aoutomatic Keyphrase extraction),完全不加任何的人工干预,就可以达到很好的效果,而且它简单到都不需要高等数学,普通人10分种就可以理解,那我们首先来介绍下TF-IDF算法。
例如,假定现在有一篇比较长的文章《致全世界儿童的一封公开信》我们准备用计算机提取它的关键词。一个简单的思路,就是找到出现次数最多的词。如果这个词很重要,它应该在这篇文章中出现很多次。于是,我们进行“词频”(Term Frequency,缩写为TF)统计,不过你可能会猜到,出现最多的词是---“的”、“是”、“在”----这一类最常用的词。它们叫做“停用词”(stop words)表示对提取结果毫无帮助、必须要过滤掉的词,这是你可能会问,从“文章”到“词”你是怎么转换的,如果你知道中文分词,就应该不会问这个问题了,中文分词有很多模式,通常是采用HMM(隐马尔科夫模型 ),一个好的分词系统非常复杂,想要理接可以点击HMM的进行了解,不过现在也有很多系统使用深度学习的方法NER(lstm+crf)来做物品词识别,这里就不一一介绍了;ok,回到之前所说的,我们可能发现“儿童”、“权力”、“心理健康”、“隐私”、“人口流动”、“冲突”、“贫困”、“疾病”、“食物”、“饮用水”、“联合国”这几个词出现的次数一样多。这是不是意味着,作为关键词,他们的重要性是一样的?
显然不是这样。因为“联合国”是很常见的词,相对而言“心理健康”、“人口流动”、“冲突”不那么常见。如果这四个词出现的次数一样多,有理由认为,“心理健康”、“人口流动”、“冲突”的重要程度要大于“联合国”,在关键词排序上“心理健康”、“人口流动”、“冲突”应该排在“联合国”的前面。
所以,我们需要一个重要性调整系数,衡量一个词是不是很常见。如果这个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。这个调整系数就是在词频统计的基础上,要对每个词分配一个“重要性”权重。这个权重叫做“逆文档频率”(Inverse Document Frequency,缩写为“IDF”),它的大小与一个词的常见程度成反比。
知道了“词频”(TF)和“逆文档频率”(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词;如果应用到文本分类中,把一类中所有的tf-idf值高的词和tf-idf值 提取出并来,这就是此类的特征模型。
总结一下:
TF=(某个词在文档中出现的次数)/(文档中的总词数)IDF=log((语料中文档总数)/(包含该词的文档数+1))分母加1 避免分母为0TF-IDF=TF*IDF
朴素贝叶斯推断
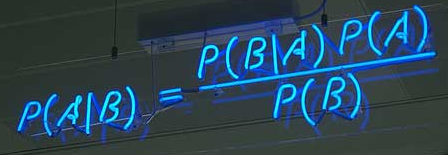
朴素贝叶斯理论听起来很高大上,但实际上并没有运用很高深的数学知识,即便没有学习过高等数学也完全可以理解,初次给我的感觉就是简单但有些绕,再到后来,我逐渐发现看似平凡的贝叶斯公式,背后却隐藏着非常深刻的原理,接下来我将用尽可能直白的话解释下贝叶斯理论。
贝叶斯推断是一种统计学方法,用来估计统计量的某种性质,与其他的统计学推断不同,它建立在主观判断的基础上。这里可能有人会问,tf-idf就能用来做分类了,为什么还要朴素贝叶斯?是的,问得好,tf-idf确实可以进行分类,但朴素贝叶斯会有效增强准确率削弱错误率(如果你之前了解过深度学习,朴素贝叶斯起到的效果有点像softmax),朴素贝叶斯是建立在“全概率公式”的基础下的,由已知的尽可能多的事件A、B求得的P(A|B)来推断未知P(B|A),是的有点玄学的意思,敲黑板!!! 这也就决定了它和tf-idf这种统计学的概率的本质区别。
贝叶斯定理:要理解贝叶斯推断,首先要知道贝叶斯定理。后者实际上是计算“条件概率”的公式。
所谓“条件概率”(Conditional probability),就是指事件B发生的情况下,事件A发生的概率,用P(A|B)来表示,嗯,没错就是上图哪个公式。上学那会老师这公式都要背熟的,用的时候也都是套公式,今天我们来看一下这个公式的推理过程:
在推理之前,我们先看一个典型的例子,便于理解贝叶斯的奥妙之处。
举个例子:生病的概率
一种癌症,得了这个癌症的人被检测出为阳性的几率为90%,未得这种癌症的人被检测出阴性的几率为90%,而人群中得这种癌症的几率为1%,一个人被检测出阳性,问这个人得癌症的几率为多少?
猛地一看,被检出阳性,而且得癌症的话阳性的概率为90%,那想必这个人应该是难以幸免了。那我们接下来就算算看。
我们用$A$表示事件“测出为阳性”,用$B_{1}$表示“得癌症”,$B_{2}$表示“未得癌症”。根据题目,我们知道如下信息:
得癌症的概率:$P(B_{1})=0.01$ 未得癌症的概率:$P(B_{2})=0.99$ 得癌症前提下被检测出为阳性的概率:$P(A|B_{1})=0.9$ 未得癌症的前提下被检测为阳性的概率:$P(A|B_{2})=0.1$
即:$P(B_{1})=0.01, P(B_{2})=0.99, P(A|B_{1})=0.9, P(A|B_{2})=0.1$
那么我们现在想得到的是已知为阳性的情况下,得癌症的几率$P(B_{1},A)$:
$P(B_{1},A) = P(B_{1}) \cdot P(A|B_{1})=0.01\times0.9=0.009$
这里的$P(B_{1},A)$表示的是联合概率,得癌症且检测出阳性的概率是人群中得癌症的概率乘上得癌症时测出是阳性的几率,是0.009.同理可得 未得癌症且检测出为阳性的概率:
$P(B_{2},A)=P(B_{2}) \cdot P(A|B_{2})=0.99\times0.1=0.099$
这个概率是什么意思呢?其实是指如果人群中有1000个人,检测出阳性并且得癌症的人有9个,检测出阳性但未得癌症的人有99个。可以看出,检测出阳性并不可怕,不得癌症的是绝大多数的,这跟我们一开始的直觉判断是不同的!可直到现在,我们并没有得到所谓的“在检测出阳性的前提下得癌症的概率”,怎么得到呢?很简单,就是看杯测出为阳性的这$108(9+99)$人里,9人和99人分别占的比例就是我们要的,也就是说我们只需要添加一个归一因子就可以了。所以检测为阳性得癌症的概率$P(B_{1}|A)=\frac{0.009}{0.009+0.099}\approx0.083$(注意$B_{1}$与$A$之间的符号“ | ”代表的是条件概率) ,阳性未得癌症的概率$P(b_{2}|A)=\frac{0.099}{0.099+0.009}\approx0.917$。这里$P(B_{1}|A), P(B_{2}|A)$中间多了一竖线“|”成为条件概率,而这个概率就是贝叶斯统计中的 后验概率!而人群中患癌症与否的概率$P(B_{1}),P(B_{2})$就是先验概率!我们知道了先验概率,根据观测值(也可以称test evidence):是否为阳性,来判断得癌症的后验概率,这就是基本的贝叶斯思想。
我们现在就能得出本题的后验概率公式为:
$P(B_{i}|A)=\frac{P(B_{i}) \cdot P(A|B_{i})}{P(B_{1}) \cdot P(A|B_{1})+P(B_{2}) \cdot P(A|B_{2})}$
贝叶斯公式
我们把上面例子分母中的$B_{1},B_{2}$的下标变成$i$,由二分类变为多分类,便会得到贝叶斯公式的一般形式:
$P(B_{i}|A)=\frac{P(B_{i}) \cdot P(A|B_{i})}{\sum_{i=1}^n P(B_{i}) \cdot P(A|B_{i})}$
再根据全概率公式:$\sum_{i=1}^n P(B_{i}) \cdot P(A|B_{i})=P(A)$ 于是我们就得到了上面的那张图片:
$P(B|A)=\frac{P(B|A) \cdot P(A)}{P(A)}$
/*********************************************************************************************************************
全概率公式:如果事件$B_{1},B_{2},...$ 满足
- "$B_{1},B_{2}...$ 两两互斥 即$B_{i} \cap B_{j}=\varnothing, i \ne j, i,j=1,2...,且P(B_{i})>0,i=1,2,....;$"
- $B_{1} \cup B_{2}...= \Omega$,则称事件组$B_{1},B_{2}...$是样本空间$\Omega$的一个划分
设$B_{1},B_{2}...$是样本空间$\Omega$的一个划分,A为任一事件,则:$P(A)=\sum_{i=1}^\infty P(B_{i})P(A|B_{i})$
********************************************************************************************************************/
到此对贝叶斯推论的解释基本完成了,接下来我们将说明下在短文本分类中的具体应用。
短文本分类应用
短文本分类中,我们将运用朴素贝叶斯理论(Naive Bayesian),同时需要引入特征条件独立假设。
给定训练数据集(X,Y),其中每个样本(短文本)x都包含n维特征,即$x=(x_{1},x_{2},x_{3},...,x_{n})$,类标记集合含有k种类别(体育、娱乐、科技...),即$y={y_{1},y_{2},y_{3},...,y_{n}}$,如果现在来了一个新样本x,它属于哪个类别的概率最大。那么问题就转化为求解$P(y_{1}|x),P(y_{2}|x),P(y_{3}|x),...P(y_{k}|x)$ 中最大的那个,即求后验概率最大的输出:$argmax_{y_{k}}P(y_{k}|x)$;那$P(y_{k}|x)$怎么求解?答案就是贝叶斯定理:
$P(y_{k}|x)=\frac{P(x|y_{k})P(y_{k})}{P(x)}$
根据全概率公式替换分母:$P(y_{k}|x)=\frac{P(x|y_{k})P(y_{k})}{\sum_{k}P(x|y_{k})P(y_{k})}$
先不管分母(分母是个定值),分子中的$P(y_{k})$是先验概率,根据训练集就可以简单地计算出来。而条件概率$P(x|y_{k})=P(x_{1},x_{2},...,x_{n}|y_{k})$它的参数规模是指数数量级别的,假设第$i$维特征$x_{i}$可取值的个数有$S_{i}$个,类别取值个数为k个,那么参数个数为:$k \prod_{i=1}^n S_{i}$这显然不可行。针对这个问题,朴素贝叶斯算法对条件概率分布作出了独立性的假设,通俗地讲就是说假设各个维度的特征$x_{1},x_{2},x_{3}...,x_{n}$相互独立,在这个假设的前提下,条件概率可以转化为:
$P(x|y_{k})=P(x_{1},x_{2},...,x_{n}|y_{k})= \prod_{i=0}^nP(x_{i}|y_{k})$ 这样参数的规模就降到$\sum_{i=1}^nS_{i}k$
以上就是针对条件概率所作出的特征条件独立性假设,至此,先验概率$P(y_{k})$和条件概率$P(x|y_{k})$的求解问题就都解决了,那么我们是不是可以求解我们所要的后验概率$P(y_{k}|x)$答案是肯定的
关于分母是由$P(A)$和全概率公式转换来的,为定值可以不管,简化得朴素贝叶斯分类器的最终表示为:
$f(x)=argmaxP(y_{k}) \prod_{i=1}^nP(x_{i}|y_{k})$
首先感谢参考文章中无私奉献的前辈们!
由于作者水平有限,欢迎指出本文中错误之处。
参考文章:
- 贝叶斯推断及其互联网应用(一):定理简介
- 机器学习(一)——浅谈贝叶斯和MCMC
- 数学之美番外篇:平凡而又神奇的贝叶斯方法
- 朴素贝叶斯理论推导与三种常见模型
- 朴素贝叶斯分类器的应用
- tf-idf与余弦相似性的应用(一):自动提取关键词
tf-idf、朴素贝叶斯的短文本分类简述的更多相关文章
- python实现随机森林、逻辑回归和朴素贝叶斯的新闻文本分类
实现本文的文本数据可以在THUCTC下载也可以自己手动爬虫生成, 本文主要参考:https://blog.csdn.net/hao5335156/article/details/82716923 nb ...
- 【十大算法实现之naive bayes】朴素贝叶斯算法之文本分类算法的理解与实现
关于bayes的基础知识,请参考: 基于朴素贝叶斯分类器的文本聚类算法 (上) http://www.cnblogs.com/phinecos/archive/2008/10/21/1315948.h ...
- 手写朴素贝叶斯(naive_bayes)分类算法
朴素贝叶斯假设各属性间相互独立,直接从已有样本中计算各种概率,以贝叶斯方程推导出预测样本的分类. 为了处理预测时样本的(类别,属性值)对未在训练样本出现,从而导致概率为0的情况,使用拉普拉斯修正(假设 ...
- 朴素贝叶斯算法——实现新闻分类(Sklearn实现)
1.朴素贝叶斯实现新闻分类的步骤 (1)提供文本文件,即数据集下载 (2)准备数据 将数据集划分为训练集和测试集:使用jieba模块进行分词,词频统计,停用词过滤,文本特征提取,将文本数据向量化 停用 ...
- 机器学习实战之朴素贝叶斯进行文档分类(Python 代码版)
贝叶斯是搞概率论的.学术圈上有个贝叶斯学派.看起来吊吊的.关于贝叶斯是个啥网上有很多资料.想必读者基本都明了.我这里只简单概括下:贝叶斯分类其实就是基于先验概率的基础上的一种分类法,核心公式就是条件概 ...
- <Machine Learning in Action >之二 朴素贝叶斯 C#实现文章分类
def trainNB0(trainMatrix,trainCategory): numTrainDocs = len(trainMatrix) numWords = len(trainMatrix[ ...
- 什么是机器学习的分类算法?【K-近邻算法(KNN)、交叉验证、朴素贝叶斯算法、决策树、随机森林】
1.K-近邻算法(KNN) 1.1 定义 (KNN,K-NearestNeighbor) 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类 ...
- Stanford大学机器学习公开课(五):生成学习算法、高斯判别、朴素贝叶斯
(一)生成学习算法 在线性回归和Logistic回归这种类型的学习算法中我们探讨的模型都是p(y|x;θ),即给定x的情况探讨y的条件概率分布.如二分类问题,不管是感知器算法还是逻辑回归算法,都是在解 ...
- 机器学习Matlab打击垃圾邮件的分类————朴素贝叶斯模型
该系列来自于我<人工智能>课程回顾总结,以及实验的一部分进行了总结学习机 垃圾分类是有监督的学习分类最经典的案例,本文首先回顾了概率论的基本知识.则以及朴素贝叶斯模型的思想.最后给出了垃圾 ...
随机推荐
- Web--Response
using Newtonsoft.Json.Linq; using System; using System.Collections.Generic; using System.Linq; using ...
- 《掌握融资必备知识》---创业学习---训练营第一课---HHR---
一,<开始学习> 1,四个思考题: (1)从你决定开始融资,到你拿到钱,你都需要经历哪些环节? (2)你知道投资机构内部的工作流程吗? (3)融资最好的时机是什么时候? (4)创投圈的专业 ...
- numpy.eye() 生成对角矩阵
numpy.eye(N,M=None, k=0, dtype=<type 'float'>) 关注第一个第三个参数就行了 第一个参数:输出方阵(行数=列数)的规模,即行数或列数 第三个参数 ...
- Jmeter和nmon shell命令
jmeter: sh jmeter -n -t /data/LPPZ/scripts/oauth.jmx -l /data/LPPZ/log/log.jtl nmon: ./nmon_linux_x8 ...
- P1893山峰瞭望
传送门 看完这个题,大家都懂意思吧,然后代码呢,emmmmm #include <bits/stdc++.h> using namespace std; const int maxn = ...
- 获取class对象的三种方法以及通过Class对象获取某个类中变量,方法,访问成员
public class ReflexAndClass { public static void main(String[] args) throws Exception { /** * 获取Clas ...
- 杭电 2136 Largest prime factor(最大素数因子的位置)
Largest prime factor Time Limit: 5000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Oth ...
- 【原】Django常用命令总结
1.终端命令 # 查看django版本 $ python -m django --version # 创建项目,名为mysite $ django-admin startproject mysite ...
- Yar并行的RPC框架的简单使用
前言: RPC,就是Remote Procedure Call的简称呀,翻译成中文就是远程过程调用 RPC要解决的两个问题: 解决分布式系统中,服务之间的调用问题. 远程调用时,要能够像本地调用一样方 ...
- 学习笔记(7)- 基于LSTM的对话模型
LSTM based Conversation Models 本文介绍一种会话语言模型,结合了局部.全局的上下文,以及参与者的角色. 问题提出者 倾向于用"任何人"."如 ...