java 如何爬取百度百科词条内容(java如何使用webmagic爬取百度词条)
这是老师所布置的作业
说一下我这里的爬去并非能把百度词条上的内容一字不漏的取下来(而是它分享链接的一个主要内容概括...)(他的主要内容我爬不到 也不想去研究大家有好办法可以call me)
例如 互联网+这个词汇 我这里爬的解释为
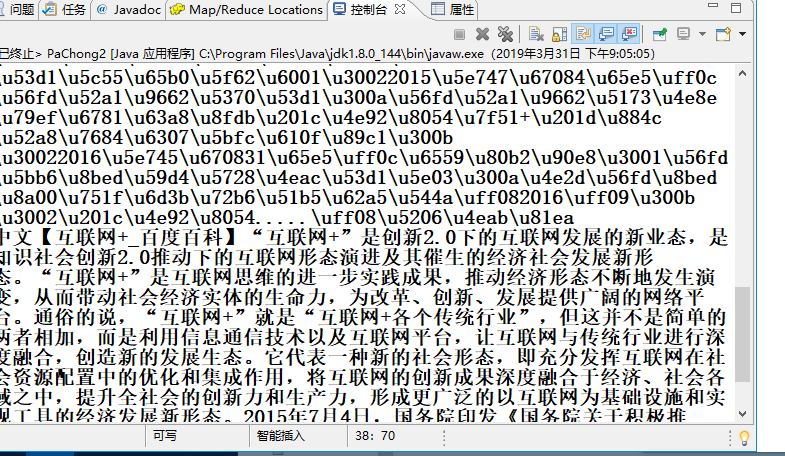
中文【互联网+_百度百科】“互联网+”是创新2.0下的互联网发展的新业态,是知识社会创新2.0推动下的互联网形态演进及其催生的经济社会发展新形态。“互联网+”是互联网思维的进一步实践成果,推动经济形态不断地发生演变,从而带动社会经济实体的生命力,为改革、创新、发展提供广阔的网络平台。通俗的说,“互联网+”就是“互联网+各个传统行业”,但这并不是简单的两者相加,而是利用信息通信技术以及互联网平台,让互联网与传统行业进行深度融合,创造新的发展生态。它代表一种新的社会形态,即充分发挥互联网在社会资源配置中的优化和集成作用,将互联网的创新成果深度融合于经济、社会各域之中,提升全社会的创新力和生产力,形成更广泛的以互联网为基础设施和实现工具的经济发展新形态。2015年7月4日,国务院印发《国务院关于积极推进“互联网+”行动的指导意见》。2016年5月31日,教育部、国家语委在京发布《中国语言生活状况报告(2016)》。“互联.....(分享自
而不同于百度词条的长篇大论
webmagic 使用不再赘述 导入包实现PageProcessor接口
代码如下
package com.test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @author 信1605-1 hjj
*
*/
public class PaChong2 implements PageProcessor{ private Site site = Site.me()
.setUserAgent("Mozilla/5.0 (Windows NT 10.0; WOW64; rv:56.0) Gecko/20100101 Firefox/56.0")
.setRetryTimes(3)
.setSleepTime(1000);
@Override
public Site getSite() {
// TODO Auto-generated method stub
return site;
} public static void main(String[] args) {
Spider.create(new PaChong2())
.addUrl("https://baike.baidu.com/item/互联网+")//这里填写你第一次要爬的网址(后面直接跟你要查的词汇名称把互联网改了就行)
.addPipeline(new ConsolePipeline())
.thread(15)
.run(); } @Override
public void process(Page page) {
//这段代码重复获取
System.out.println(mySplitBaiDu(page));
System.out.println("中文"+unicodeToString(mySplitBaiDu(page)));
} //爬取百度解释 为unicode文本
public static String mySplitBaiDu(Page page)
{
String wordname=page.getUrl().toString().split("item/")[1];
String basehtml=page.getJson().toString();
String content =basehtml.split("bdText: \"")[1].split("@")[0];
return content;
} //unicode 转中文
public static String unicodeToString(String str) { Pattern pattern = Pattern.compile("(\\\\u(\\p{XDigit}{4}))");
Matcher matcher = pattern.matcher(str);
char ch;
while (matcher.find()) {
//group 6728
String group = matcher.group(2);
//ch:'木' 26408
ch = (char) Integer.parseInt(group, 16);
//group1 \u6728
String group1 = matcher.group(1);
str = str.replace(group1, ch + "");
}
return str;
} }
结果
java 如何爬取百度百科词条内容(java如何使用webmagic爬取百度词条)的更多相关文章
- 爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释 我的第一个想法是做一个数据库,把常用的词语和词语的解释放到数据库里面,当用户查询时直接读取数据库结果 但是自己又没有心思做这样一个数 ...
- python简单爬虫 用beautifulsoup爬取百度百科词条
目标:爬取“湖南大学”百科词条并处理数据 需要获取的数据: 源代码: <div class="basic-info cmn-clearfix"> <dl clas ...
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
- R语言爬虫:爬取百度百科词条
抓取目标:抓取花儿与少年的百度百科中成员信息 url <- "http://baike.baidu.com/item/%E8%8A%B1%E5%84%BF%E4%B8%8E%E5%B0 ...
- Python3爬取百度百科(配合PHP)
用PHP写了一个网页,可以获取百度百科词条.源代码已分享至github:https://github.com/1049451037/xiaobaike/tree/master 那么通过Python来爬 ...
- Python 爬虫实例(爬百度百科词条)
爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入 ...
- python爬虫—爬取百度百科数据
爬虫框架:开发平台 centos6.7 根据慕课网爬虫教程编写代码 片区百度百科url,标题,内容 分为4个模块:html_downloader.py 下载器 html_outputer.py 爬取数 ...
- python_爬百度百科词条
如何爬取? 明确目标:爬取百度百科,定初始百度词条:python,初始URL:http://baike.baidu.com/item/Python,爬取数据量为1000条,值爬取简介,标题,和简介中u ...
- Python开发简单爬虫(二)---爬取百度百科页面数据
一.开发爬虫的步骤 1.确定目标抓取策略: 打开目标页面,通过右键审查元素确定网页的url格式.数据格式.和网页编码形式. ①先看url的格式, F12观察一下链接的形式;② 再看目标文本信息的标签格 ...
随机推荐
- navicat连接数据库报错:未发现数据源名称并且未指定默认驱动程序
解决方法:安装navicat自带sqlncli_x64.msi,在navicat安装目录下
- springboot 跨域
参考: https://blog.csdn.net/qq779446849/article/details/53102925 https://blog.csdn.net/wo541075754/art ...
- 【PAT甲级】1025 PAT Ranking (25 分)(结构体排序,MAP<string,int>映射)
题意: 输入一个正整数N(N<=100),表示接下来有N组数据.每组数据先输入一个正整数M(M<=300),表示有300名考生,接下来M行每行输入一个考生的ID和分数,ID由13位整数组成 ...
- 【PAT甲级】1018 Public Bike Management (30 分)(SPFA,DFS)
题意: 输入四个正整数C,N,S,M(c<=100,n<=500),分别表示每个自行车站的最大容量,车站个数,此次行动的终点站以及接下来的M行输入即通路.接下来输入一行N个正整数表示每个自 ...
- Linux centosVMware Nginx负载均衡、ssl原理、生成ssl密钥对、Nginx配置ssl
一.Nginx负载均衡 vim /usr/local/nginx/conf/vhost/load.conf // 写入如下内容 upstream qq_com { ip_hash; 同一个用户始终保持 ...
- SRS源码——Listener
1. 整理了一下Listener相关的UML类图:
- CSS文本居中显示
因为一直为元素居中问题而困扰,所以决定把自己遇到和看到的方法记录下来,以便以后查看 如果要让inline或inline-block元素居中显示,则父元素css中包含text-align:center; ...
- jmeter学习笔记一foreach控制器
ForEach控制器 输入变量前缀:上一步所提取的变量名的前缀,例如appid_1, 则appid就是前缀 start index for loop:循环的起始位置,默认为空也可 end index ...
- SqlSession为什么可以提交事务
本应在开始读MyBatis源码时首先应该了解下MyBatis的SqlSession的四大对象:Executor.StatemenHandler.ParameterHandler.ResultHandl ...
- java并发初探ConcurrentHashMap
java并发初探ConcurrentHashMap Doug Lea在java并发上创造了不可磨灭的功劳,ConcurrentHashMap体现这位大师的非凡能力. 1.8中ConcurrentHas ...