架构设计 | 分布式业务系统中,全局ID生成策略
本文源码:GitHub·点这里 || GitEE·点这里
一、全局ID简介
在实际的开发中,几乎所有的业务场景产生的数据,都需要一个唯一ID作为核心标识,用来流程化管理。比如常见的:
- 订单:order-id,查订单详情,物流状态等;
- 支付:pay-id,支付状态,基于ID事务管理;
如何生成唯一标识,在普通场景下,一般的方法就可以解决,例如:
import java.util.UUID;
public class UuidUtil {
public static String getUUid() {
UUID uuid = UUID.randomUUID();
return String.valueOf(uuid).replace("-","");
}
}
这个方法可以解决绝大部分唯一ID需求的场景业务,但是网上各种UUID重复场景的描述帖,说的好像该API不好用。
絮叨一句:说一个真实使用的业务场景,大概是半年近3000万的数据流水,用的就是UUID的API,暂时未捕捉到ID重复的问题,仅供参考。
二、雪花算法
1、概念简介
Twitter公司开源的分布式ID生成算法策略,生成的ID遵循时间的顺序。
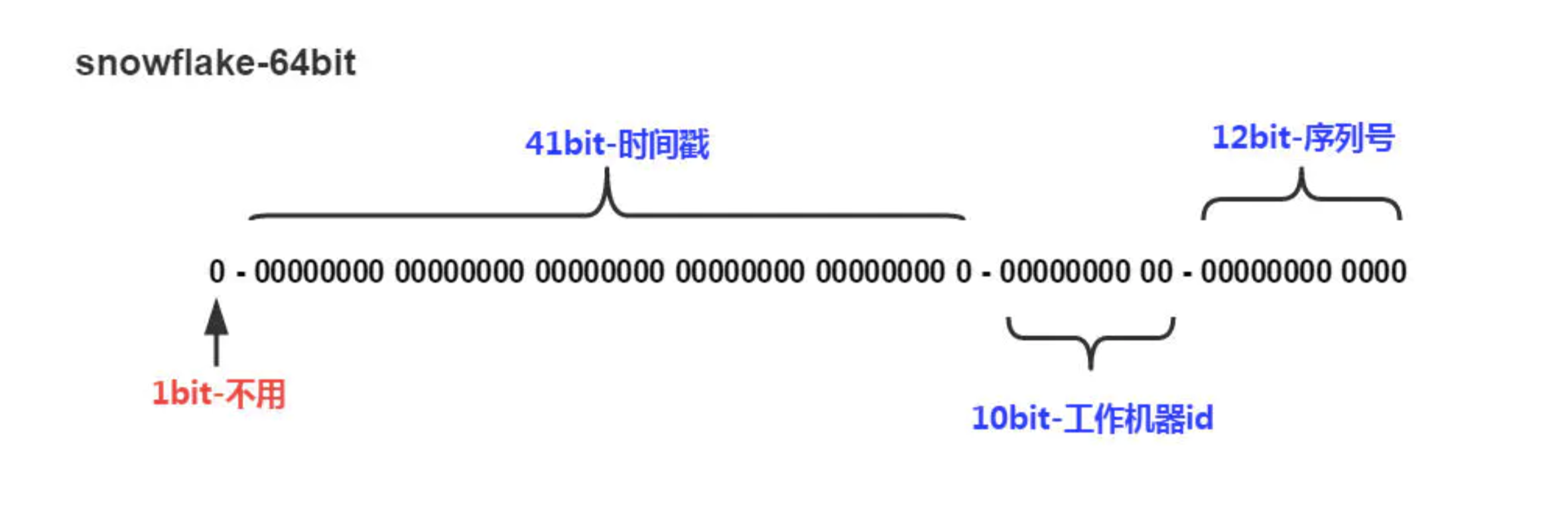
- 1为位标识,始终为0,不可用;
- 41位时间截,存储时间截的差值(当前时间截-开始时间截);
- 10位的机器标识,10位的长度最多支持部署1024个节点;
- 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒产生4096个ID序号;
SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高。
2、编码实现
工具类中很多可以自定义的,比如起始时间,机器ID配置等。
/**
* 雪花算法ID生成
*/
public class SnowIdWorkerUtil {
// 开始时间截 (2020-01-02)
private final long timeToCut = 1577894400000L;
// 机器ID所占的位数
private final long workerIdBits = 2L;
// 数据标识ID所占的位数
private final long dataCenterIdBits = 8L;
// 支持的最大机器ID,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 支持的最大数据标识ID,结果是31
private final long maxDataCenterId = -1L ^ (-1L << dataCenterIdBits);
// 序列在ID中占的位数
private final long sequenceBits = 12L;
// 机器ID向左移12位
private final long workerIdShift = sequenceBits;
// 数据标识ID向左移17位(12+5)
private final long dataCenterIdShift = sequenceBits + workerIdBits;
// 时间截向左移22位(5+5+12)
private final long timestampLeftShift = sequenceBits + workerIdBits + dataCenterIdBits;
// 生成序列的掩码
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
// 工作机器ID(0~31)
private long workerId;
// 数据中心ID(0~31)
private long dataCenterId;
// 毫秒内序列(0~4095)
private long sequence = 0L;
// 上次生成ID的时间截
private long lastTimestamp = -1L;
/**
* 构造函数
* @param workerId 工作ID (0~31)
* @param dataCenterId 数据中心ID (0~31)
*/
public SnowIdWorkerUtil (long workerId, long dataCenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException("workerId 不符合条件");
}
if (dataCenterId > maxDataCenterId || dataCenterId < 0) {
throw new IllegalArgumentException("dataCenterId 不符合条件");
}
this.workerId = workerId;
this.dataCenterId = dataCenterId;
}
public synchronized String nextIdVar(){
return String.valueOf(nextId());
}
/**
* 线程安全,获得下一个ID
*/
private synchronized long nextId() {
long timestamp = timeGen();
// 如果当前时间小于上一次ID生成的时间戳,抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format(
"时间顺序异常,时间差(上次时间-现在)=%d",
lastTimestamp - timestamp));
}
// 如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
} else {
// 时间戳改变,毫秒内序列重置
sequence = 0L;
}
// 上次生成ID的时间截
lastTimestamp = timestamp;
// 移位并通过或运算拼到一起组成64位的ID
return ((timestamp - timeToCut) << timestampLeftShift)
| (dataCenterId << dataCenterIdShift)
| (workerId << workerIdShift) | sequence;
}
/**
* 阻塞,获得新的时间戳
*/
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回当前时间节点
*/
private long timeGen() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
// 参数在实际业务下需要配置管理
SnowIdWorkerUtil idWorker = new SnowIdWorkerUtil(1, 1);
for (int i = 0; i < 100; i++) {
String id = idWorker.nextIdVar();
System.out.println(id+" "+id.length()+"位");
}
}
}
三、自定义实现
还有一种常见的实现思路,基于数据库的自增主键ID,不过基于这个原理,却有各种不同的实现策略。
简单表结构:
CREATE TABLE `du_temp_id` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='主键ID临时表';
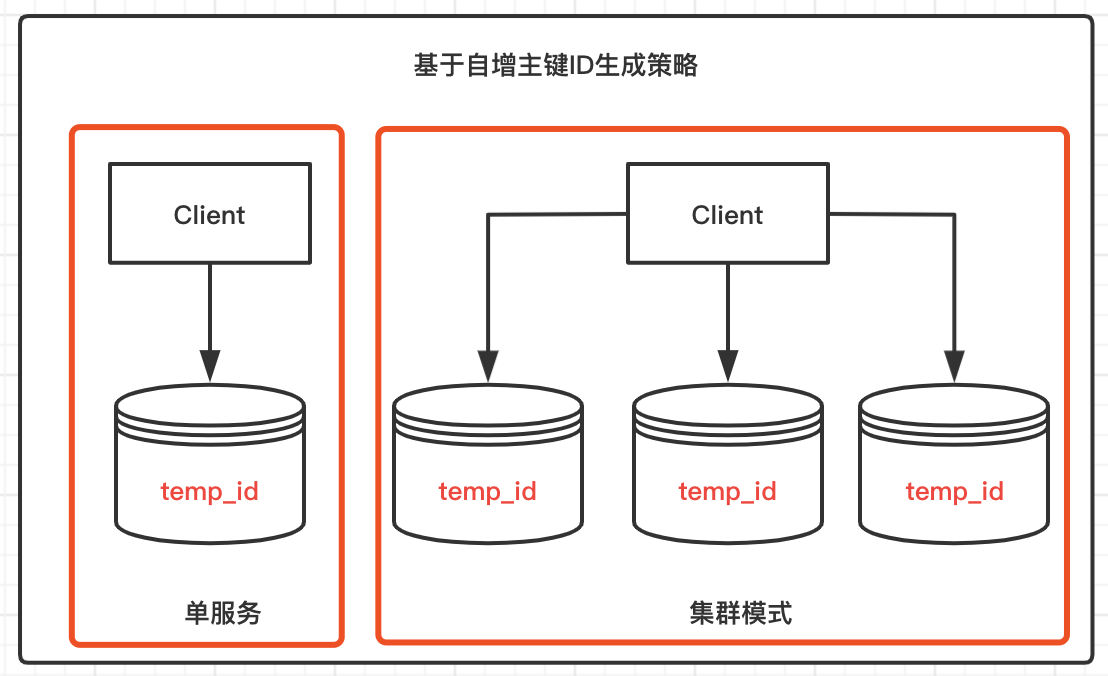
1、基于主键
这种模式的原理比较单调,向临时表写入一条记录,借助MySQL生成的唯一主键ID,然后拿出来稍微处理一下,作为各种业务场景的唯一ID使用。
@Service
public class TempIdServiceImpl implements TempIdService {
@Resource
private TempIdMapper tempIdMapper ;
@Override
public List<String> getIdList() {
List<String> idList = new ArrayList<>() ;
TempIdEntity tempIdEntity = new TempIdEntity ();
tempIdEntity.setCreateTime(new Date());
for (int i = 0 ; i < 10 ; i++){
tempIdMapper.insert(tempIdEntity);
idList.add(UuidUtil.getNoId(8,Long.parseLong(tempIdEntity.getId().toString()))) ;
}
return idList ;
}
}
问题点:如果作为ID生成的临时表所在的MySQL服务宕掉,那可能会影响整个业务流程,造成雪崩效应。
2、高可用集群
单服务如果不能安稳的支撑业务需求,很自然集群模式就该上场了。提供多台MySQL服务[A,B,C],处理策略也不止一种:
- 库设置主键自增策略
例如A库[1,4,7],B库[2,5,8],C库[3,6,9],基于不同自增规则,生成统一的自增唯一标识。
- 生成ID做分库标识
这种先把ID生成,然后不同的数据库生成的ID给一个不同的标识,例如UIDA,UIDB,UIDC。
@Service
public class TempIdServiceImpl implements TempIdService {
@Resource
private TempIdMapper tempIdMapper ;
@Override
public List<String> getRouteIdList() {
List<String> idList = new ArrayList<>() ;
TempIdEntity tempIdEntity = new TempIdEntity ();
tempIdEntity.setCreateTime(new Date());
for (int i = 0 ; i < 2 ; i++){
tempIdMapper.insertA(tempIdEntity);
idList.add(UuidUtil.getRouteId("UID-A",10,
Long.parseLong(tempIdEntity.getId().toString()))) ;
tempIdMapper.insertB(tempIdEntity);
idList.add(UuidUtil.getRouteId("UID-B",10,
Long.parseLong(tempIdEntity.getId().toString()))) ;
tempIdMapper.insertC(tempIdEntity);
idList.add(UuidUtil.getRouteId("UID-C",10,
Long.parseLong(tempIdEntity.getId().toString()))) ;
}
return idList ;
}
}
结果样例:
UID-A00001,UID-B00001,UID-C00001
UID-A00002,UID-B00002,UID-C00002
3、ID样式优化
从数据获取的ID基本是一个自增的整数序列,可以提供一个格式美化工具方法。
public class UuidUtil {
private static final String ZERO = "00000000000";
private static final String PREFIX = "UID";
public static String getNoId(int length,Long id){
String idVar = String.valueOf(id) ;
if (idVar.length()>length){
return PREFIX+idVar ;
} else {
int gapLen = length-idVar.length()-PREFIX.length() ;
return PREFIX+ZERO.substring(0,gapLen)+idVar ;
}
}
public static String getRouteId(String route,Integer length,Long id){
String idVar = String.valueOf(id) ;
if (idVar.length()>length){
return route+idVar ;
} else {
int gapLen = length-idVar.length()-route.length() ;
return route+ZERO.substring(0,gapLen)+idVar ;
}
}
}
基于不同的策略,把ID格式为统一的位数。
4、性能问题
如果在高并发的业务场景下,实时基于MySQL去生成唯一ID容易产生性能瓶颈,当然其他方法也可能产生这个问题。可以在系统空闲时间批量生成一批,放入缓存中,在使用的时候直接从缓存层取出即可。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent

推荐阅读:数据和架构管理
| 序号 | 标题 |
|---|---|
| A01 | 数据源管理:主从库动态路由,AOP模式读写分离 |
| A02 | 数据源管理:基于JDBC模式,适配和管理动态数据源 |
| A03 | 数据源管理:动态权限校验,表结构和数据迁移流程 |
| A04 | 数据源管理:关系型分库分表,列式库分布式计算 |
| C01 | 架构基础:单服务.集群.分布式,基本区别和联系 |
架构设计 | 分布式业务系统中,全局ID生成策略的更多相关文章
- 分布式高并发下全局ID生成策略
数据在分片时,典型的是分库分表,就有一个全局ID生成的问题.单纯的生成全局ID并不是什么难题,但是生成的ID通常要满足分片的一些要求: 1 不能有单点故障. 2 以时间为序,或者ID里包含时间 ...
- 高并发环境下全局id生成策略
解决方案: 基于Redis的全局id生成策略:(推荐此方法) 基于雪花算法的全局id生成: https://www.cnblogs.com/kobe-qi/p/8761690.html 基于zooke ...
- 分布式系统下的全局id生成策略分析
对于分布式系统而言,意味着会有很多个instance会并发的生成很多业务数据,比如订单.不同的机房.不同的机器.不同的应用实例会同时生成.所以,如何生成一个好用的全局id并不是一个简单的uuid就能够 ...
- 架构设计 | 分布式系统调度,Zookeeper集群化管理
本文源码:GitHub·点这里 || GitEE·点这里 一.框架简介 1.基础简介 Zookeeper基于观察者模式设计的组件,主要应用于分布式系统架构中的,统一命名服务.统一配置管理.统一集群管理 ...
- 聊聊业务系统中投递消息到mq的几种方式
背景 电商中有这样的一个场景: 下单成功之后送积分的操作,我们使用mq来实现 下单成功之后,投递一条消息到mq,积分系统消费消息,给用户增加积分 我们主要讨论一下,下单及投递消息到mq的操作,如何实现 ...
- 数据库分库分表(一)常见分布式主键ID生成策略
主键生成策略 系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,下面介绍一些常见的ID生成策略. Sequence ID UUID GUID COMB Snowflake 最开始的自增ID为了实 ...
- 可实现的全局唯一有序ID生成策略
在博客园搜素全局唯一有序ID,罗列出来的文章大致讲述了以下几个问题,常见的生成全局唯一id的常见方法 :使用数据库自动增长序列实现 : 使用UUID实现: 使用redis实现: 使用Twitter的 ...
- 图解Janusgraph系列-分布式id生成策略分析
JanusGraph - 分布式id的生成策略 大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 本次更新时间:2020-9-1 文章为作者跟踪源码和查看官方文档整理,如有任何问题,请联 ...
- 全局ID生成--雪花算法
分布式ID常见生成策略: 分布式ID生成策略常见的有如下几种: 数据库自增ID. UUID生成. Redis的原子自增方式. 数据库水平拆分,设置初始值和相同的自增步长. 批量申请自增ID. 雪花算法 ...
随机推荐
- 通过ISAPI http协议控制海康摄像头
一直用海康的SDK进行摄像头控制,但有时候非常不灵活,必须有X86的主机,在嵌入式上面就不行,通过写一个HTTPCLIENT可以通过ISAPI来控制海康的摄像头. 代码如下:git@github.co ...
- 快速创建Flask Restful API项目
前言 Python必学的两大web框架之一Flask,俗称微框架.它只需要一个文件,几行代码就可以完成一个简单的http请求服务. 但是我们需要用flask来提供中型甚至大型web restful a ...
- 【开源】使用Angular9和TypeScript开发RPG游戏(20200410版)
源代码地址 通过对于斗罗大陆小说的游戏化过程,熟悉Angular的结构以及使用TypeScript的面向对象开发方法. Github项目源代码地址 RPG系统构造 ver0.03 2020/04/10 ...
- 单周期CPU
一个时钟周期执行一条指令的过程理解(单周期CPU): https://blog.csdn.net/a201577F0546/article/details/84726912 单周期CPU指的是一条指令 ...
- Python机器学习笔记 集成学习总结
集成学习(Ensemble learning)是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合,从而获得比单个学习器显著优越的泛化性能.它不是一种单独的机器学习算法啊,而更像是一种优 ...
- Redis 笔记(三)—— LIST 常用命令
常用命令 命令 用例和描述 RPUSH RPUSH key value [value ...] —— 将一个或多个值推入列表的右端 LPUSH LPUSH key value [value ...] ...
- Spring Taco Cloud——design视图的创建(含thymeleaf模板遇到的一些小问题)
先来看下综合前两篇内容加上本次视图的成果 可能不是很美观,因为并没有加css样式,我想等整个项目有个差不多的功能实现后再进行页面优化,请谅解 下面我贴上自己定义修改过的Taco的design视图代 ...
- Linux系统安装Dos系统(虚拟机里装)
结合以下两篇优秀的文章就能完成任务. 1.https://www.jb51.net/os/609411.html 2.http://blog.51cto.com/6241809/1687361 所需要 ...
- Maybatis的一些总结(三:增删改查)
回顾一个点 之前不懂这句: UserMapper userMapper = sqlSession.getMapper(UserMapper.class); 现在理解了一点点,相当于实现了userMap ...
- Linux下删除大量文件效率对比
来自公众号:马哥Linux运维 今天我们来测试一下Linux下面删除大量文件的效率. 首先建立50万个文件 $ test for i in $(seq 1 500000);do echo text ...