Apache Hudi集成Apache Zeppelin实战
1. 简介
Apache Zeppelin 是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等等。当前Hive与SparkSQL已经支持查询Hudi的读优化视图和实时视图。所以理论上Zeppelin的notebook也应当拥有这样的查询能力。
2.实现效果
2.1 Hive
2.1.1 读优化视图
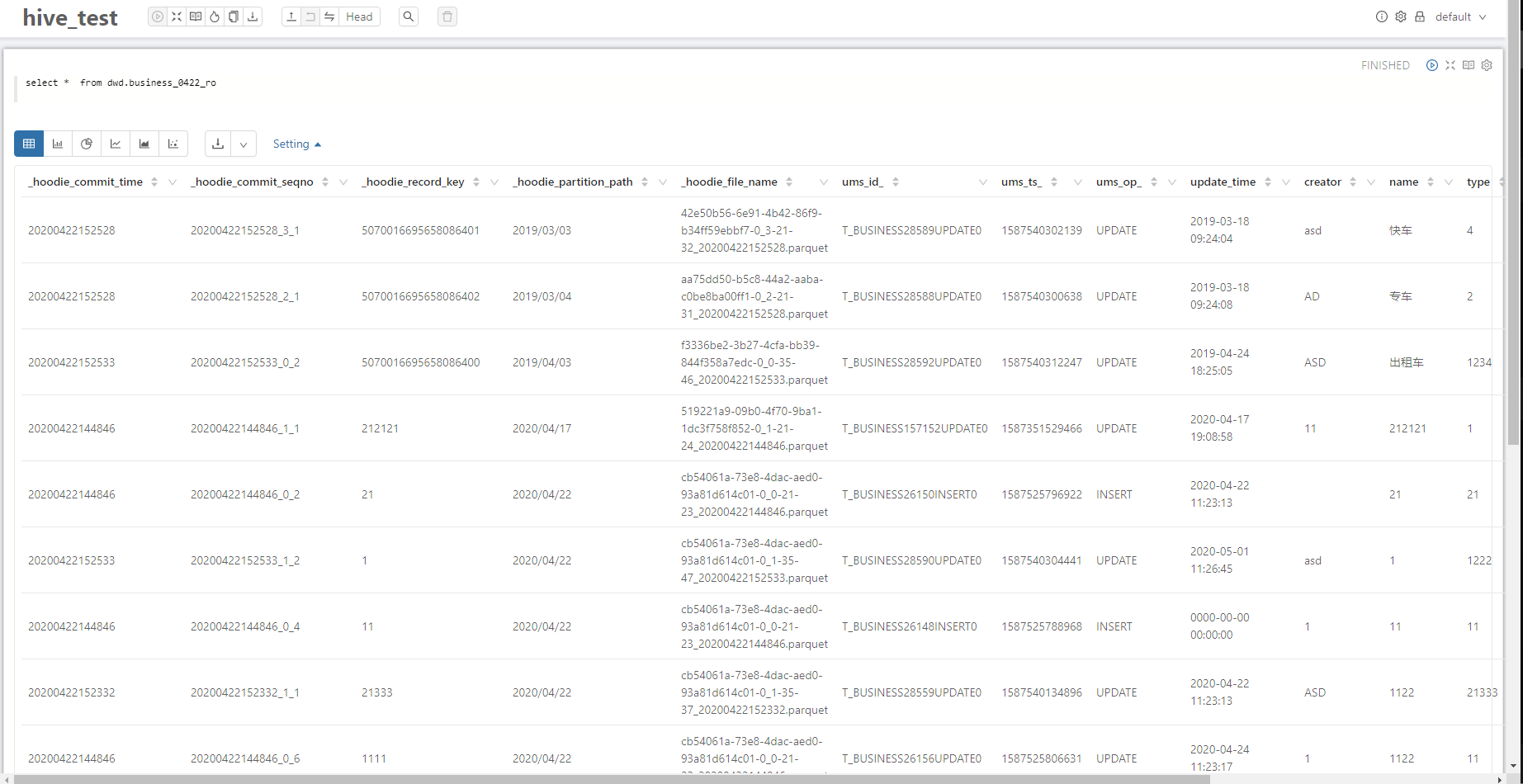
2.1.2 实时视图
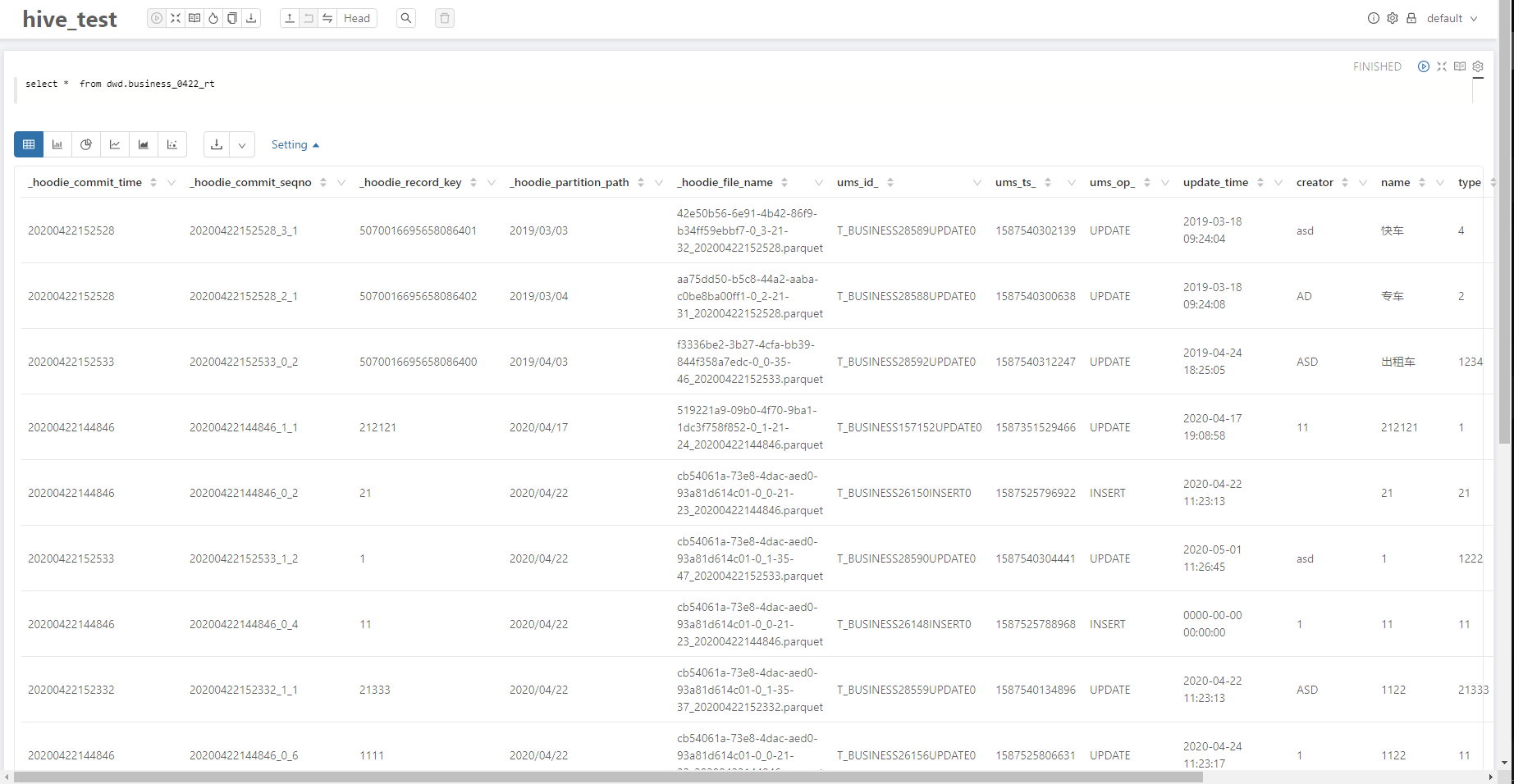
2.2 Spark SQL
2.2.1 读优化视图
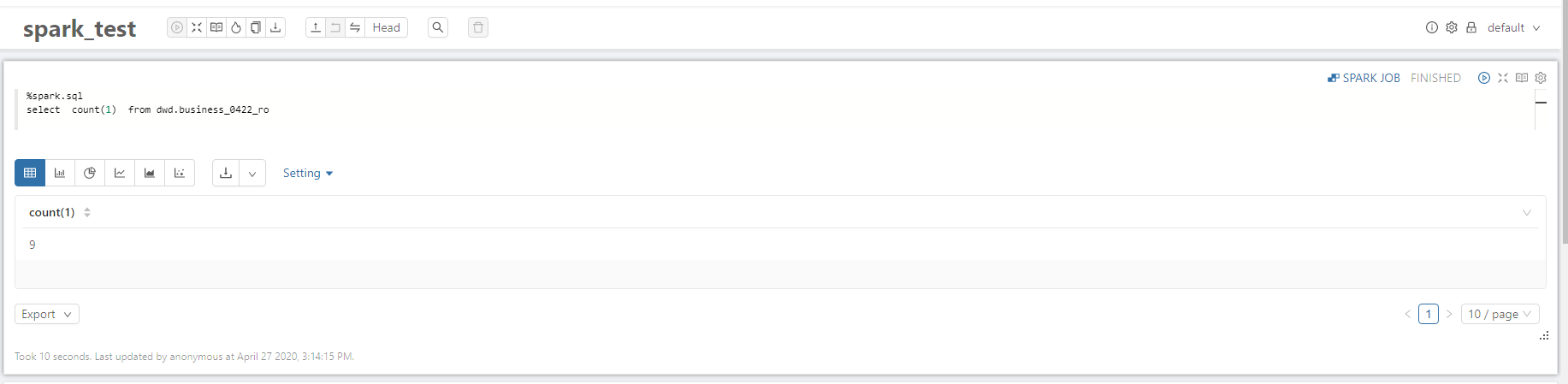
2.2.2 实时视图
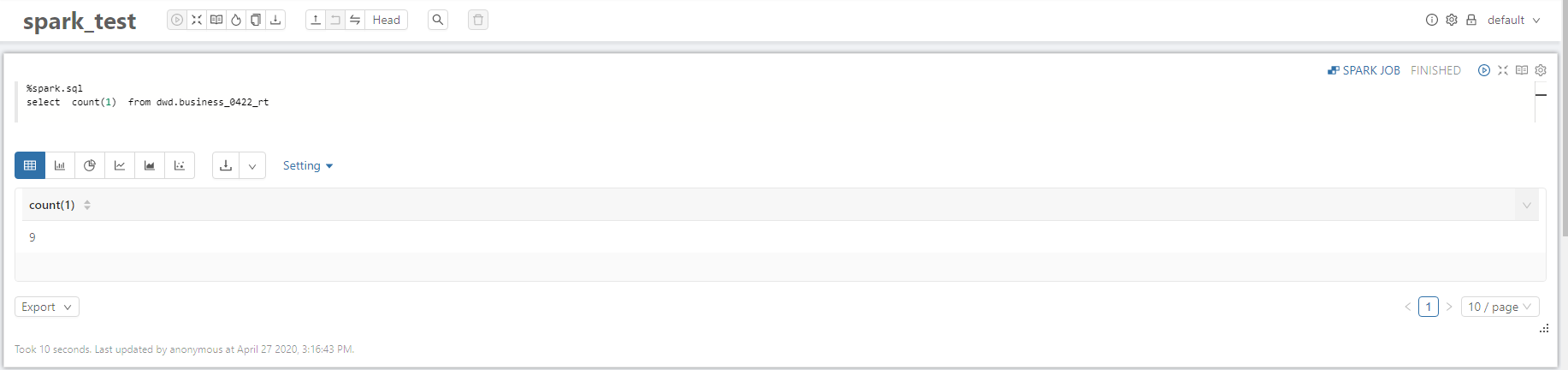
3.常见问题整理
3.1 Hudi包适配
cp hudi-hadoop-mr-bundle-0.5.2-SNAPSHOT.jar zeppelin/lib
cp hudi-hive-bundle-0.5.2-SNAPSHOT.jar zeppelin/lib
cp hudi-spark-bundle_2.11-0.5.2-SNAPSHOT.jar zeppelin/lib
Zeppelin启动时会默认加载lib下的包,对于Hudi这类外部依赖,适合直接放在zeppelin/lib下以避免 Hive或Spark SQL在集群上找不到对应Hudi依赖。
3. 2 parquet jar包适配
Hudi包的parquet版本为1.10,当前CDH集群parquet版本为1.9,所以在执行Hudi表查询时,会报很多jar包冲突的错。
解决方法:在zepeelin所在节点的spark/jars目录下将parquet包升级成1.10。
副作用:zeppelin 以外的saprk job 分配到 parquet 1.10的集群节点的任务可能会失败。
建议:zeppelin 以外的客户端也会有jar包冲突的问题。所以建议将集群的spark jar 、parquet jar以及相关依赖的jar做全面升级,更好地适配Hudi的能力。
3.3 Spark Interpreter适配
相同sql在Zeppelin上使用Spark SQL查询会出现比hive查询记录条数多的现象。
问题原因:当向Hive metastore中读写Parquet表时,Spark SQL默认将使用Spark SQL自带的Parquet SerDe(SerDe:Serialize/Deserilize的简称,目的是用于序列化和反序列化),而不是用Hive的SerDe,因为Spark SQL自带的SerDe拥有更好的性能。
这样导致了Spark SQL只会查询Hudi的流水记录,而不是最终的合并结果。
解决方法:set spark.sql.hive.convertMetastoreParquet=false
方法一:直接在页面编辑属性

方法二:编辑 zeppelin/conf/interpreter.json添加
interpreter
"spark.sql.hive.convertMetastoreParquet": {
"name": "spark.sql.hive.convertMetastoreParquet",
"value": false,
"type": "checkbox"
},
4. Hudi增量视图
对于Hudi增量视图,目前只支持通过写Spark 代码的形式拉取。考虑到Zeppelin在notebook上有直接执行代码和shell 命令的能力,后面考虑封装这些notebook,以支持sql的方式查询Hudi增量视图。
Apache Hudi集成Apache Zeppelin实战的更多相关文章
- Apache Hudi集成Spark SQL抢先体验
Apache Hudi集成Spark SQL抢先体验 1. 摘要 社区小伙伴一直期待的Hudi整合Spark SQL的PR正在积极Review中并已经快接近尾声,Hudi集成Spark SQL预计会在 ...
- Apache Hudi与Apache Flink集成
感谢王祥虎@wangxianghu 投稿 Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目.是当前最 ...
- 生态 | Apache Hudi集成Alluxio实践
原文链接:https://mp.weixin.qq.com/s/sT2-KK23tvPY2oziEH11Kw 1. 什么是Alluxio Alluxio为数据驱动型应用和存储系统构建了桥梁, 将数据从 ...
- Apache Hudi + AWS S3 + Athena实战
Apache Hudi在阿里巴巴集团.EMIS Health,LinkNovate,Tathastu.AI,腾讯,Uber内使用,并且由Amazon AWS EMR和Google云平台支持,最近Ama ...
- 重磅!Vertica集成Apache Hudi指南
1. 摘要 本文演示了使用外部表集成 Vertica 和 Apache Hudi. 在演示中我们使用 Spark 上的 Apache Hudi 将数据摄取到 S3 中,并使用 Vertica 外部表访 ...
- 基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse. 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse. 在深 ...
- Apache Hudi重磅特性解读之存量表高效迁移机制
1. 摘要 随着Apache Hudi变得越来越流行,一个挑战就是用户如何将存量的历史表迁移到Apache Hudi,Apache Hudi维护了记录级别的元数据以便提供upserts和增量拉取的核心 ...
- 恭喜!Apache Hudi社区新晋多位Committer
1. 介绍 经过Apache Hudi项目委员会讨论及投票,向Udit Mehrotra.Gary Li.Raymond Xu.Pratyaksh Sharma 4人发出Committer邀请,4人均 ...
- Apache Hudi助力nClouds加速数据交付
1. 概述 在nClouds上,当客户的业务决策取决于对近实时数据的访问时,客户通常会向我们寻求有关数据和分析平台的解决方案.但随着每天创建和收集的数据量都在增加,这使得使用传统技术进行数据分析成为一 ...
随机推荐
- 在linux虚拟机上安装docker并安装mysql
步骤 1.检查内核版本,必须是3.10及以上 uname -r 2.安装docker yum install docker 3.输入y确认安装 4.启动docker systemctl start d ...
- Servlet---request内置对象
Request 对象: 问题: 浏览器发起请求到服务器,会遵循HTTP协议将请求数据发送给服务器. 那么服务器接受到请求的数据改怎么存储呢?不但要存,而且要保证完成性. 解决: 使用对象进行存储,服务 ...
- Python学习-第三节part1: 关于函数
一 为何要用函数之不用函数的问题 #1.代码的组织结构不清晰,可读性差 #2.遇到重复的功能只能重复编写实现代码,代码冗余 #3.功能需要扩展时,需要找出所有实现该功能的地方修改之,无法统一管理且维护 ...
- 老技术新谈,Java应用监控利器JMX(1)
先聊聊最近比较流行的梗,来一次灵魂八问. 配钥匙师傅: 你配吗? 食堂阿姨: 你要饭吗? 算命先生: 你算什么东西? 快递小哥: 你是什么东西? 上海垃圾分拣阿姨: 你是什么垃圾? 滴滴司机: 你搞清 ...
- Vue引用阿里图标库
首先进入官网http://www.iconfont.cn/ 转载:https://blog.csdn.net/qq_34802010/article/details/81451278 选择图标库 在里 ...
- es6声明一个类
js语言的传统方式是通过定义构造函数,生成心得对象.是一种基于原型的面向对象系统.在es6中增加了class类的概念,可以使用class关键字来声明一个类.之后用这个类来实例化对象. 构造函数示例 c ...
- Shell:Day09.笔记
awk [单独的编程语言解释器]1.awk介绍 全称:Aho Weinberger Kernaighan 三个人的首字母缩写: 1970年第一次出现在Unix机器上,后来在开源领域使用它: 所以,我 ...
- Linux服务器架设篇,Windows中的虚拟机linux上不了外网怎么办?
1.将电脑的网线口直连路由器内网接口(确保该路由器可以直接正常上网,切记不可以使用宽带连接和无线网连接). 2.在实体机电脑可以上网的前提下,在命令框窗口输入 ipconfig 3.记录下电脑以太网的 ...
- CSS躬行记(5)——渐变
渐变是由两种或多种颜色之间的渐进过渡组成,它是一种特殊的图像类型,分为线性渐变和径向渐变,这两类渐变还会细分为单次和重复两种.渐变图像与传统图像相比,它的优势包括占用更少的字节,避免额外的服务器请求, ...
- 【第二章】黎姿的python学习笔记