1、flink介绍,反压原理
一、flink介绍

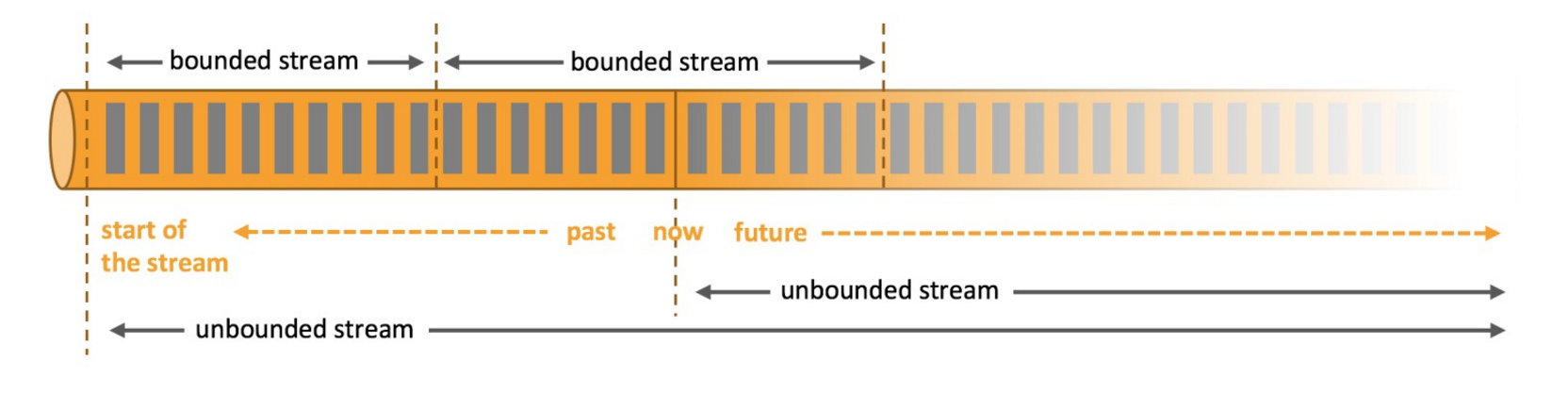
1.1、有界数据流和无界数据流
1.2、flink的特点
- 支持java 和 scala api
- 流(dataStream)批(dataSet)一体化
- 支持事件处理和无序处理通过DataStream API,基于DataFlow数据流模型
- 在不同的时间语义(事件时间-数据产生的时间,摄取时间:集群获取到数据、处理时间)下支持灵活的窗口(时间,滑动、翻滚,会话,自定义触发器)
- 支持有状态计算的Exactly-once(仅处理一次)容错保证
- 支持基于轻量级分布式快照checkpoint机制实现的容错
- 支持savepoints 机制,一般手动触发,在升级应用或者处理历史数据是能够做到无状态丢失和最小停机时间
- 兼容hadoop的mapreduce,集成YARN,HDFS,Hbase 和其它hadoop生态系统的组件
- 支持大规模的集群模式,支持yarn、Mesos。可运行在成千上万的节点上
- 在dataSet(批处理)API中内置支持迭代程序
- 图处理(批) 机器学习(批) 复杂事件处理(流)
- 自动反压机制
- 高效的自定义内存管理
- 健壮的切换能力在in-memory和out-of-core中
1.3、flink的分层模型
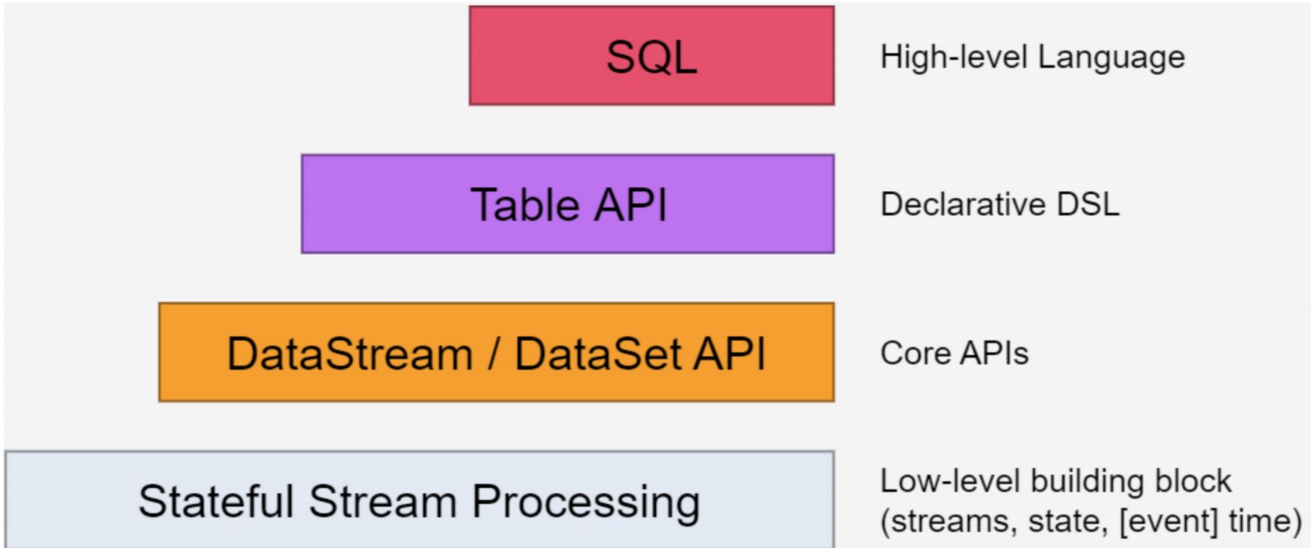
flink自身提供了不同级别的抽象来支持我们开发流式或者批处理程序,上图描述了Flink 支持的四种不同级别的抽象。
- 位于最底层, 是core API 的底层实现
- processFunction (处理函数)
- 利用低阶,构建一些新的组件或者算子
- 灵活性高,但开发比较复杂
- 表达性最强,可以操作状态,time等
- DataSet - 批处理 API
- DataStream –流处理 API
- 封装了一些算子
- 构建在Table 之上,都需要构建Table 环境
- 不同的类型的Table 构建不同的Table 环境
- Table 可以与DataStream或者DataSet进行相互转换
- Streaming SQL不同于存储的SQL,最终会转化为流式执行计划
二、finlk的反压原理

- 根据配置,Flink 会在 NetworkBufferPool 中生成一定数量(默认2048,一个32K)的内存块 MemorySegment,内存块 的总数量就代表了网络传输中所有可用的内存。NetworkEnvironment 和 NetworkBufferPool 是 Task 之间共 享的,每个节点(TaskManager - 跑任务的进程,类似于spark的extour)只会实例化一个。
- Task 线程启动时,会向 NetworkEnvironment 注册,NetworkEnvironment 会为 Task 的 InputGate(IG)和 ResultPartition(RP) 分别创建一个 LocalBufferPool(缓冲池)并设置可申请的 MemorySegment(内存块)数量。IG 对应的缓冲池初始的内存块数量与 IG 中 InputChannel 数量一致,RP 对应的缓冲池初始的内存 块数量与 RP 中的 ResultSubpartition 数量一致。不过,每当创建或销毁缓冲池时,NetworkBufferPool 会计 算剩余空闲的内存块数量,并平均分配给已创建的缓冲池。注意,这个过程只是指定了缓冲池所能使用的内存 块数量,并没有真正分配内存块,只有当需要时才分配。为什么要动态地为缓冲池扩容呢?因为内存越多,意 味着系统可以更轻松地应对瞬时压力(如GC),不会频繁地进入反压状态,所以我们要利用起那部分闲置的 内存块。
- 在 Task 线程执行过程中,当 Netty 接收端收到数据时,为了将 Netty 中的数据拷贝到 Task 中, InputChannel(实际是 RemoteInputChannel)会向其对应的缓冲池申请内存块(上图中的①)。如果缓冲池 中也没有可用的内存块且已申请的数量还没到池子上限,则会向 NetworkBufferPool 申请内存块(上图中的 ②)并交给 InputChannel 填上数据(上图中的③和④)。如果缓冲池已申请的数量达到上限了呢?或者 NetworkBufferPool 也没有可用内存块了呢?这时候,Task 的 Netty Channel 会暂停读取,上游的发送端会立 即响应停止发送,拓扑会进入反压状态。当 Task 线程写数据到 ResultPartition 时,也会向缓冲池请求内存 块,如果没有可用内存块时,会阻塞在请求内存块的地方,达到暂停写入的目的。
- 当一个内存块被消费完成之后(在输入端是指内存块中的字节被反序列化成对象了,在输出端是指内存块中的 字节写入到 Netty Channel 了),会调用 Buffer.recycle() 方法,会将内存块还给 LocalBufferPool (上 图中的⑤)。如果LocalBufferPool中当前申请的数量超过了池子容量(由于上文提到的动态容量,由于新注 册的 Task 导致该池子容量变小),则LocalBufferPool会将该内存块回收给 NetworkBufferPool(上图中的 ⑥)。如果没超过池子容量,则会继续留在池子中,减少反复申请的开销。
2.1、反压的过程

- 记录“A”进入了 Flink 并且被 Task 1 处理。(这里省略了 Netty 接收、反序列化等过程)
- 记录被序列化到 buffer 中。
- 该 buffer 被发送到 Task 2,然后 Task 2 从这个 buffer 中读出记录。
- 本地传输:如果 Task 1 和 Task 2 运行在同一个 worker 节点(TaskManager),该 buffer 可以直接交给下一 个 Task。一旦 Task 2 消费了该 buffer,则该 buffer 会被缓冲池1回收。如果 Task 2 的速度比 1 慢,那么 buffer 回收的速度就会赶不上 Task 1 取 buffer 的速度,导致缓冲池1无可用的 buffer,Task 1 等待在可用的 buffer 上。最终形成 Task 1 的降速。
- 远程传输:如果 Task 1 和 Task 2 运行在不同的 worker 节点上,那么 buffer 会在发送到网络(TCP Channel)后被回收。在接收端,会从 LocalBufferPool 中申请 buffer,然后拷贝网络中的数据到 buffer 中。 如果没有可用的 buffer,会停止从 TCP 连接中读取数据。在输出端,通过 Netty 的水位值机制(可配置)来 保证不往网络中写入太多数据。如果网络中的数据(Netty输出缓冲中的字节数)超过了高水位值,我们会等 到其降到低水位值以下才继续写入数据。这保证了网络中不会有太多的数据。如果接收端停止消费网络中的数 据(由于接收端缓冲池没有可用 buffer),网络中的缓冲数据就会堆积,那么发送端也会暂停发送。另外,这 会使得发送端的缓冲池得不到回收,writer 阻塞在向 LocalBufferPool 请求 buffer,阻塞了 writer 往 ResultSubPartition 写数据。
这种固定大小缓冲池就像阻塞队列一样,保证了 Flink 有一套健壮的反压机制,使得 Task 生产数据的速度不会快 于消费的速度。我们上面描述的这个方案可以从两个 Task 之间的数据传输自然地扩展到更复杂的 pipeline 中,保 证反压机制可以扩散到整个 pipeline。
2.2、反压监控
1、flink介绍,反压原理的更多相关文章
- 第一章-Flink介绍-《Fink原理、实战与性能优化》读书笔记
Flink介绍-<Fink原理.实战与性能优化>读书笔记 1.1 Apache Flink是什么? 在当代数据量激增的时代,各种业务场景都有大量的业务数据产生,对于这些不断产生的数据应该如 ...
- 一文搞懂 Flink 网络流控与反压机制
https://www.jianshu.com/p/2779e73abcb8 看完本文,你能get到以下知识 Flink 流处理为什么需要网络流控? Flink V1.5 版之前网络流控介绍 Flin ...
- 如何分析及处理 Flink 反压?
反压(backpressure)是实时计算应用开发中,特别是流式计算中,十分常见的问题.反压意味着数据管道中某个节点成为瓶颈,处理速率跟不上上游发送数据的速率,而需要对上游进行限速.由于实时计算应用通 ...
- 咱们从头到尾讲一次 Flink 网络流控和反压剖析
本文根据 Apache Flink 系列直播整理而成,由 Apache Flink Contributor.OPPO 大数据平台研发负责人张俊老师分享.主要内容如下: 网络流控的概念与背景 TCP的流 ...
- Flink 反压 浅入浅出
前言 微信搜[Java3y]关注这个朴实无华的男人,点赞关注是对我最大的支持! 文本已收录至我的GitHub:https://github.com/ZhongFuCheng3y/3y,有300多篇原创 ...
- Flink中发送端反压以及Credit机制(源码分析)
上一篇<Flink接收端反压机制>说到因为Flink每个Task的接收端和发送端是共享一个bufferPool的,形成了天然的反压机制,当Task接收数据的时候,接收端会根据积压的数据量以 ...
- [转帖]实时流处理系统反压机制(BackPressure)综述
实时流处理系统反压机制(BackPressure)综述 https://blog.csdn.net/qq_21125183/article/details/80708142 2018-06-15 19 ...
- flink - 反压
http://wuchong.me/blog/2016/04/26/flink-internals-how-to-handle-backpressure/ https://ci.apache.org/ ...
- Flink中接收端反压以及Credit机制 (源码分析)
先上一张图整体了解Flink中的反压 可以看到每个task都会有自己对应的IG(inputgate)对接上游发送过来的数据和RS(resultPatation)对接往下游发送数据, 整个反压机制通 ...
随机推荐
- 面向对象(OO)第一阶段学习总结
前言:对OO本阶段作业情况说明 本阶段一共完成三次作业,第一次主要是在主方法里面进行编程,也就是和之前C差不多,而随着学习的深入,慢慢了解到面向对象与面向过程的区别.作业的难度也在慢慢增大,后两次都用 ...
- intelliJ IDEA 教育版下载教程
声明:本教程针对的是在校本科大学生及以上学历学生群体,因为申请账号需要学校的邮箱来进行验证,所以"社会人士"为了对的起"社会"这两个字,还是花点钱买个正版吧! ...
- SQL实战(二)
一. 获取所有员工当前的manager,如果当前的manager是自己的话结果不显示,当前表示to_date='9999-01-01'.结果第一列给出当前员工的emp_no,第二列给出其manager ...
- 迁移桌面程序到MS Store(15)——通过注册表开启Developer Mode
没想到该系列不仅没有太监,还打算更新一个小短篇.在各种大厂小厂工作的各位想必都知道Windows域的概念.入域的机器很多的设置就由不得当前登入所使用的域账号了,Windows的更新和安全等众多的设置均 ...
- Java Web项目bug经验202002112049
运行程序后,如果配置有问题,可能不会进代码,而直接报错.
- html5调用手机摄像头
<input type="file" accept="image/*" capture="camera"><input t ...
- vscode 保存自动 格式化eslint 代码
在网上找了很多种方法,大多都没有成功 一下是一种成功的 配置方法: 1) First, you need to install the ESLint extension in the VS code ...
- 1008 Elevator (20 分)
The highest building in our city has only one elevator. A request list is made up with N positive nu ...
- 一天学一个Linux命令:第一天 ls
文章更新于:2020-03-02 注:本文参照 man ls 手册,并给出使用样例. 文章目录 一.命令之`ls` 1.名字及介绍 2.语法格式 3.输出内容示例 4.参数 二.命令实践 1.`ls ...
- (js描述的)数据结构[树结构之红黑树](13)
1.二叉送搜索树的缺点: 2.红黑树难度: 3.红黑树五大规则: 4.红黑树五大规则的作用: 5.红黑树二大变换: 1)变色 2)旋转 6.红黑树的插入五种变换情况: 先声明--------插入的数据 ...