Redis为什么这么快?
Redis为什么这么快?
关注微信公众号:非典型理科男 回复:redis获取redis三本经典著作
序言
作为企业级的存储组件, Redis被用到很多的业务场景。
Redis经常被用作做缓存, 一致性要求不高场景,还可以当做存储使用。
另外, Redis还提供了消息订阅、事务、索引等特性。 我们还可以利用集群特性搭建分布式存储服务,实现非强一致性的分布式锁服务。
Redis用到上述场景, 都有一个共同的优势, 就是处理速度快(高性能)。
面试中,面试官经常会问到单线程的Redis为什么这么快? 为了阐明这个问题, 下面将分三部分讲解: (1) 第一部分: Redis到底有多快 (2) 第二部分: 详细讲解Redis高性能原因 (3) 第三部分: 影响Redis性能的因素
Redis到底有多快
要了解Reids的到底有多么快, 首先需要有相应的评估工具。 其次,需要Redis 在一些平台经验数据,来评估Redis性能数量级。 幸运的是Redis提供了这样的工具,并给出了常用的硬件平台一些经验数据。
下面篇幅比较长,核心观点如下:
- 可以使用redis-benchmark对Redis的性能进行评估,命令行提供了普通/流水线方式、不同压力评估特定命令的性能的功能。
- redis性能卓越,作为key-value系统最大负载数量级为10W/s, set和get耗时数量级为10ms和5ms。使用流水线的方式可以提升redis操作的性能。
不关心具体数据的小伙伴,可以直接跳到第二部分,直接了解redis性能卓越的原因。
Redis性能评估工具
Redis包含的redis-benchmark实用程序可模拟N个客户端同时发送M个总查询的运行命令(类似于Apache的ab实用程序)。可以使用redis-benchmark对redis的性能进行评估。
支持以下选项:
Usage: redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests]> [-k <boolean>]
-h <hostname> 服务器 hostname (默认 127.0.0.1)
-p <port> 服务器 port (默认 6379)
-s <socket> 服务器 socket (覆盖host和port)
-a <password> 服务器鉴权密钥
-c <clients> 启动的客户端数量(并行度) (默认 50)
-n <requests> 总请求量(默认 100000)
-d <size> GET和SET请求数据大小(默认 2个字节)
--dbnum <db> 选择的db编号 (默认 0)
-k <boolean> 1=keep alive 0=reconnect (默认 1)
-r <keyspacelen> 在SET/GET/INCR使用随机的key值, 在SADD使用随机的va
-P <numreq> 一个Pipeline包含的请求数. 默认值1 (不使用Pipeline).
-q 安静模式. 仅仅展示QPS值
--csv 以csv格式输出
-l 生成循环 永久执行测试
-t <tests> 制定测试命令的命令, 命令列表以逗号分隔
-I Idle模式,仅打开N个idle连接并等待
启动基准之前,您需要具有运行中的Redis实例。我在自己工作的笔记本上, 使用默认参数跑了一个例子:
D:\data\soft\redis-windows>redis-benchmark.exe
.....
====== SET ======
100000 requests completed in 0.81 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.90% <= 1 milliseconds
99.93% <= 2 milliseconds
99.95% <= 78 milliseconds
99.96% <= 79 milliseconds
100.00% <= 79 milliseconds
123609.39 requests per second
====== GET ======
100000 requests completed in 0.70 seconds
50 parallel clients
3 bytes payload
keep alive: 1
100.00% <= 0 milliseconds
142045.45 requests per second
====== INCR ======
100000 requests completed in 0.71 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.95% <= 1 milliseconds
99.95% <= 2 milliseconds
100.00% <= 2 milliseconds
140252.45 requests per second
.....
上面的例子中,截取了SET/GET/INCR的测试结果。
测试结果包括测试的环境参数(请求量、client数量、有效载荷)以及请求耗时的TP值。
redis-benchmark默认使用10万请求量, 50个clinet,有效载荷为3字节进行测试。
返回结果可以看出SET/GET/INCR命令在10万的请求量下,总的请求耗时均低于0.1s以内。 以QPS=10W为例, 计算出来的平均耗时为2ms左右(1/(10W/50))。
Reids基准测试经验数据
Redis的性能跟很多因素相关, 在第三部分会详细介绍。比如客户端网络状况、是否使用流水,链接的客户端。为了说明Redis到底有多快,我们使用Reidis官网使用redis-benchmark测试的一组数据。
警告:请注意,以下大多数基准测试已有数年历史,并且是与今天的标准相比使用旧硬件获得的。该页面应该进行更新,但是在很多情况下,使用硬硬件状态,您会期望看到的数字是此数字的两倍。此外,在许多工作负载中,Redis 4.0比2.6快
硬件环境和软件配置
测试是由50个同时执行200万个请求的客户端完成的。
所有测试在Redis 2.6.14上运行。
使用回环地址(127.0.0.1)执行了测试。
使用一百万个键的键空间执行测试。
使用和不使用流水线(16条命令流水线)执行测试。
Intel(R) Xeon(R) CPU E5520 @ 2.27GHz
Redis系统负载
- 不使用流水线测试结果
$ ./redis-benchmark -r 1000000 -n 2000000 -t get,set,lpush,lpop -q
SET: 122556.53 requests per second
GET: 123601.76 requests per second
LPUSH: 136752.14 requests per second
LPOP: 132424.03 requests per second
- 使用流水线测试结果
$ ./redis-benchmark -r 1000000 -n 2000000 -t get,set,lpush,lpop -q -P 16
SET: 195503.42 requests per second
GET: 250187.64 requests per second
LPUSH: 230547.55 requests per second
LPOP: 250815.16 requests per second
从以上可以看出Redis作为key-value系统读写负载大致在10W+QPS, 使用流水线技术能够显著提升读写性能。
耗时情况
- 不使用流水线测试结果
$ redis-benchmark -n 100000
====== SET ======
100007 requests completed in 0.88 seconds
50 parallel clients
3 bytes payload
keep alive: 1
58.50% <= 0 milliseconds
99.17% <= 1 milliseconds
99.58% <= 2 milliseconds
99.85% <= 3 milliseconds
99.90% <= 6 milliseconds
100.00% <= 9 milliseconds
114293.71 requests per second
====== GET ======
100000 requests completed in 1.23 seconds
50 parallel clients
3 bytes payload
keep alive: 1
43.12% <= 0 milliseconds
96.82% <= 1 milliseconds
98.62% <= 2 milliseconds
100.00% <= 3 milliseconds
81234.77 requests per second
....
所有set操作均在10ms内完成, get操作均在5ms以下。
Redis为什么那么快
Redis是一个单线程应用,所说的单线程指的是Redis使用单个线程处理客户端的请求。 虽然Redis是单线程的应用,但是即便不通过部署多个Redis实例和集群的方式提升系统吞吐, 从官网给出的数据可以看出,Redis处理速度非常快。
Redis性能非常高的原因主要有以下几点:
- 内存存储:Redis是使用内存(in-memeroy)存储,没有磁盘IO上的开销
- 单线程实现:Redis使用单个线程处理请求,避免了多个线程之间线程切换和锁资源争用的开销
- 非阻塞IO:Redis使用多路复用IO技术,在poll,epool,kqueue选择最优IO实现
- 优化的数据结构:Redis有诸多可以直接应用的优化数据结构的实现,应用层可以直接使用原生的数据结构提升性能
下面详细介绍非阻塞IO和优化的数据结构
多路复用IO
在《unix网络编程 卷I》中详细讲解了unix服务器中的5种IO模型。
一个IO操作一般分为两个步骤:
- 等待数据从网络到达, 数据到达后加载到内核空间缓冲区
- 数据从内核空间缓冲区复制到用户空间缓冲区
按照两个步骤是否阻塞线程,分为阻塞/非阻塞, 同步/异步。

五种IO模型分类:
| 阻塞 | 非阻塞 | |
|---|---|---|
| 同步 | 阻塞IO | 非阻塞IO,IO多路复用,信号驱动IO |
| 异步IO | 异步IO |
阻塞IO
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
 阻塞IO
阻塞IO
非阻塞IO
Linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子: 
IO多路复用
IO multiplexing这个词可能有点陌生,但是如果我说select/epoll,大概就都能明白了。有些地方也称这种IO方式为事件驱动IO(event driven IO)。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图: 
信号驱动IO
 信号驱动IO
信号驱动IO
异步IO
Linux下的asynchronous IO其实用得不多,从内核2.6版本才开始引入。先看一下它的流程: 
介绍完unix或者类unix系统IO模型之后, 我们看下redis怎么处理客户端连接的?
Reids的IO处理
总的来说Redis使用一种封装多种(select,epoll, kqueue等)实现的Reactor设计模式多路复用IO处理客户端的请求。
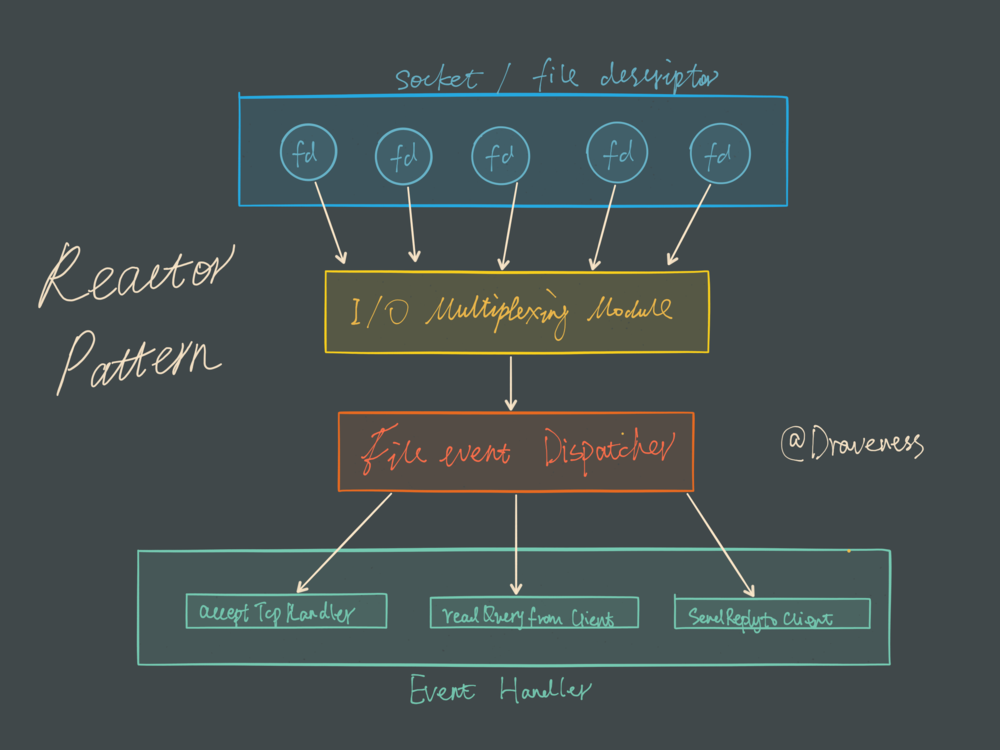 Reactor设计模式
Reactor设计模式
Reactor设计模式常常用来实现事件驱动。除此之外, Redis还封装了不同平台多路复用IO的不同的库。处理过程如下:
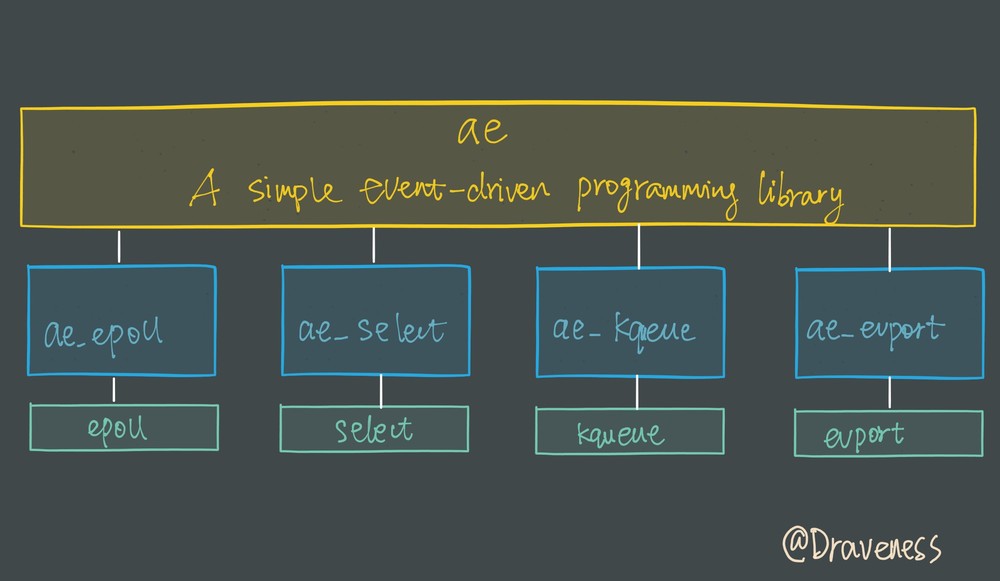 IO库封装
IO库封装
因为 Redis 需要在多个平台上运行,同时为了最大化执行的效率与性能,所以会根据编译平台的不同选择不同的 I/O 多路复用函数作为子模块。
具体选择过程如下: 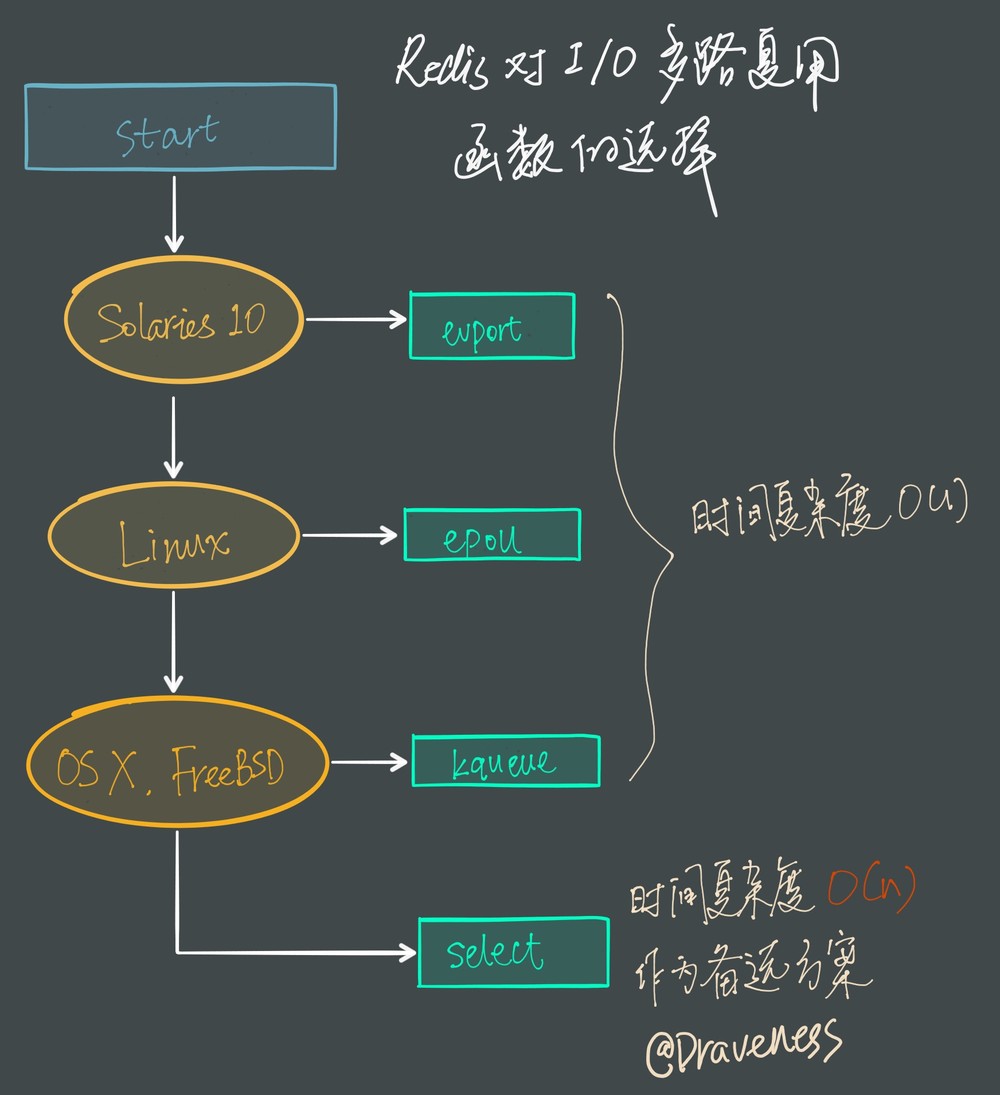
Redis 会优先选择时间复杂度为 O(1) 的 I/O 多路复用函数作为底层实现,包括 Solaries 10 中的 evport、Linux 中的 epoll 和 macOS/FreeBSD 中的 kqueue,上述的这些函数都使用了内核内部的结构,并且能够服务几十万的文件描述符。
但是如果当前编译环境没有上述函数,就会选择 select 作为备选方案,由于其在使用时会扫描全部监听的描述符,所以其时间复杂度较差 O(n),并且只能同时服务 1024 个文件描述符,所以一般并不会以 select 作为第一方案使用。
丰富高效的数据结构
Redis提供了丰富的数据结构,并且不同场景下提供不同实现。
Redis作为key-value系统,不同类型的key对应不同的操作或者操作对应不同的实现,相同的key也会有不同的实现。Redis对key进行操作时,会进行类型检查,调用不同的实现。
为了解决以上问题, Redis 构建了自己的类型系统, 这个系统的主要功能包括:
redisObject 对象。 基于 redisObject 对象的类型检查。 基于 redisObject 对象的显式多态函数。 对 redisObject 进行分配、共享和销毁的机制。
redisObject定义:
/*
* Redis 对象
*/
typedef struct redisObject {
// 类型
unsigned type:4;
// 对齐位
unsigned notused:2;
// 编码方式
unsigned encoding:4;
// LRU 时间(相对于 server.lruclock)
unsigned lru:22;
// 引用计数
int refcount;
// 指向对象的值
void *ptr;
} robj;
type 、 encoding 和 ptr 是最重要的三个属性。
Redis支持4种type, 8种编码, 分别为:
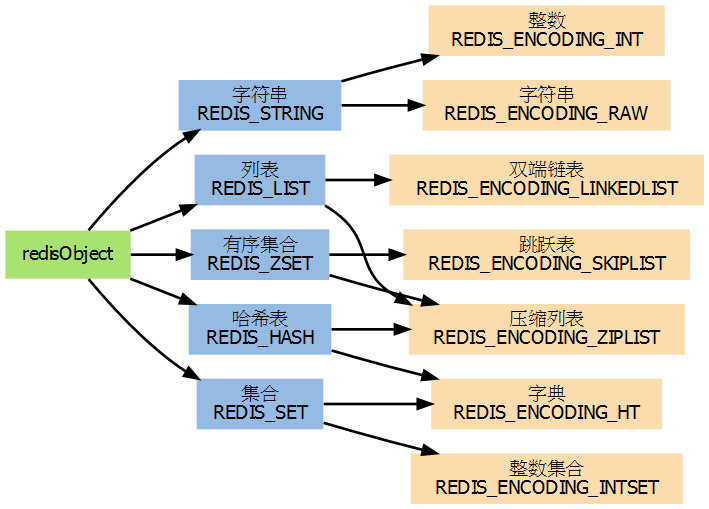

有了redisObject之后, 对于特定key的操作过程就可以很容易的实现:
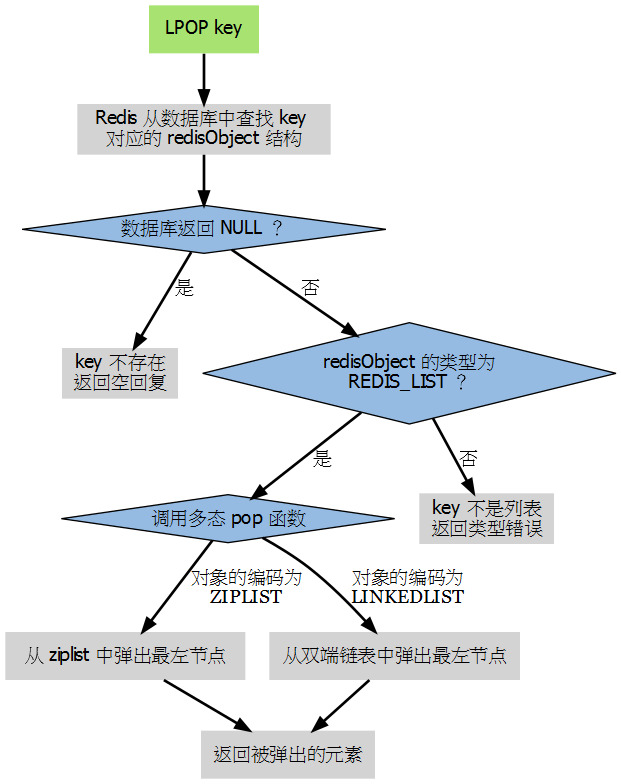
Redis除了提供丰富的高效的数据结构外, 还提供了如HyperLogLog, Geo索引这样高效的算法。
篇幅的原因,影响Redis性能的因素将在另外一篇文章中介绍。
参考文档:
关注微信公众号:非典型理科男 回复:redis获取redis三本经典著作
Redis为什么这么快?的更多相关文章
- 为什么说Redis是单线程的以及Redis为什么这么快!
参考文章:https://blog.csdn.net/xlgen157387/article/details/79470556 redis简介 Redis是一个开源的内存中的数据结构存储系统,它可以用 ...
- 为什么说Redis是单线程的以及Redis为什么这么快!(转)
文章转自https://blog.csdn.net/chenyao1994/article/details/79491337 一.前言 近乎所有与Java相关的面试都会问到缓存的问题,基础一点的会问到 ...
- Redis为什么这么快
Redis为什么这么快 1.完全基于内存,绝大部分请求是纯粹的内存操作,非常快速.数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1): 2.数据结构简单, ...
- Redis性能解析--Redis为什么那么快?
echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!!! Red ...
- 《为什么说Redis是单线程的以及Redis为什么这么快!》
为什么说Redis是单线程的以及Redis为什么这么快! 一.前言 近乎所有与Java相关的面试都会问到缓存的问题,基础一点的会问到什么是“二八定律”.什么是“热数据和冷数据”,复杂一点的会问到缓 ...
- [转帖]Redis性能解析--Redis为什么那么快?
Redis性能解析--Redis为什么那么快? https://www.cnblogs.com/xlecho/p/11832118.html echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加e ...
- 为什么说Redis是单线程的以及Redis为什么这么快!(转)
一.前言 近乎所有与Java相关的面试都会问到缓存的问题,基础一点的会问到什么是“二八定律”.什么是“热数据和冷数据”,复杂一点的会问到缓存雪崩.缓存穿透.缓存预热.缓存更新.缓存降级等问题,这些看似 ...
- 性能测试 | 理解单线程的Redis为何那么快?
前言 Redis是一种基于键值对(Key-Value)的NoSQL数据库,Redis的Value可以由String,hash,list,set,zset,Bitmaps,HyperLogLog等多种数 ...
- Redis 为什么这么快?
1. 纯内存操作,肯定快 数据存储在内存中,读取的时候不需要进行磁盘的 IO 2. 单线程,无锁竞争损耗 单线程保证了系统没有线程的上下文切换 使用单线程,可以避免不必要的上下文切换和竞争条件,没有多 ...
随机推荐
- drf分页组件补充
drf偏移分页组件 pahenations.py from rest_framework.pagination import LimitOffsetPagination class MyLimitOf ...
- python标准库-array 模块
原文地址:http://www.bugingcode.com/blog/python_module_array.html array 模块是python中实现的一种高效的数组存储类型.它和list相似 ...
- Apache虚拟机的配置文件解说
1.为了方便管理虚拟主机,我决定使用一种方法,那就是修改httpd-vhosts.conf文件. 第一步首先要使扩展文件httpd-vhosts.conf生效: 1. 打开 apache/conf/h ...
- Starting php-fpm [18-Jun-2019 12:56:59] NOTICE: PHP message: PHP Warning: Version warning提示报错解决
php-fpm在命令行重启时出现如下提示信息在终端上,虽然不影响使用,但是不够干净利落,参考了一篇国外博客得以解决,参考链接:https://community.centminmod.com/thre ...
- 疯狂补贴的4G+ 会是又一个资费陷阱吗?
会是又一个资费陷阱吗?" title="疯狂补贴的4G+ 会是又一个资费陷阱吗?"> 常言说得好,防火防盗防运营商--具有垄断性质的中国移动.联通.电信三大基础 ...
- array, matrix, list and dataframe
总结一下"入门3R"(Reading, 'Riting, 'Rrithmetic)中的读和写,不同的数据结构下的读写还是有点区别的. vector 命名 12 month.days ...
- 原创:Python爬虫实战之爬取代理ip
编程的快乐只有在运行成功的那一刻才知道QAQ 目标网站:https://www.kuaidaili.com/free/inha/ #若有侵权请联系我 因为上面的代理都是http的所以没写这个判断 代 ...
- IP 转发分组的流程
IP 转发分组的流程 数据路由:路由器在不同网段转发数据包: 网络畅通的条件:数据包能去能回: 从源网络发出时,沿途的每一个路由器必须知道到目标网络下一跳给哪个接口: 从目标网络返回时,沿途的每一个路 ...
- java反序列化-ysoserial-调试分析总结篇(7)
前言: CommonsCollections7外层也是一条新的构造链,外层由hashtable的readObject进入,这条构造链挺有意思,因为用到了hash碰撞 yso构造分析: 首先构造进行rc ...
- 小白自学机器学习----3.令人头秃的pytorch安装 (No module named 'tools.nnwrap' 错误)
tensorflow 刚刚会写基础的模块了,今天找到研究方向的代码是pytorch实现的 总是看到这句话,人生苦短,我用pytorch 看来pytorch应该比tensorflow好学,但是!! py ...