MongoDB分片技术原理和高可用集群配置方案
一、Sharding分片技术
1、分片概述
当数据量比较大的时候,我们需要把数分片运行在不同的机器中,以降低CPU、内存和Io的压力,Sharding就是数据库分片技术。
MongoDB分片技术类似MySQL的水平切分和垂直切分,数据库主要由俩种方式做Sharding:垂直扩展和横向切分。
垂直扩展的方式就是进行集群扩展,添加更多的CPU,内存,磁盘空间等。
横向切分则是通过数据分片的方式,通过集群统一提供服务:
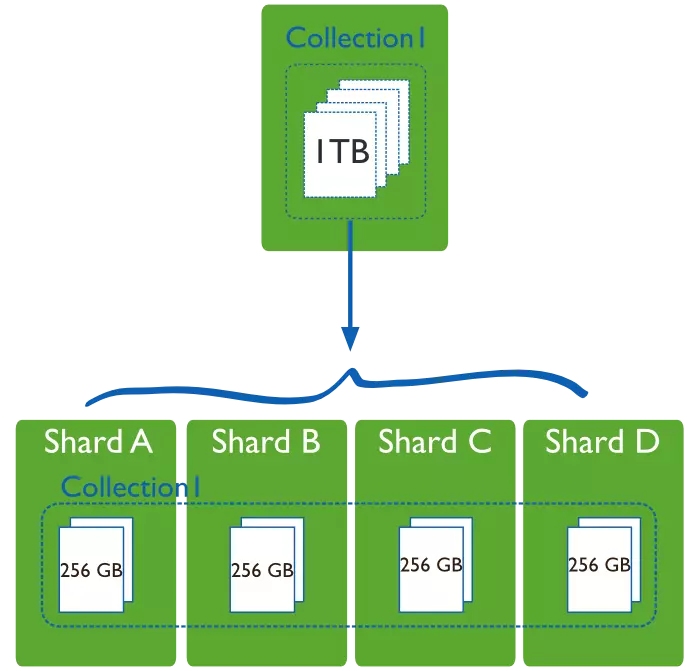
二、MongoDB分片架构原理
(1)MongoDB的Sharding架构

其中,Router负责接受访问,然后去config服务器中查询元数据,将数据存储信息返回给Router,Router服务器根据元数据的存储信息在分片服务器上读取或者写入数据。
(2)MongoDB分片架构中的角色
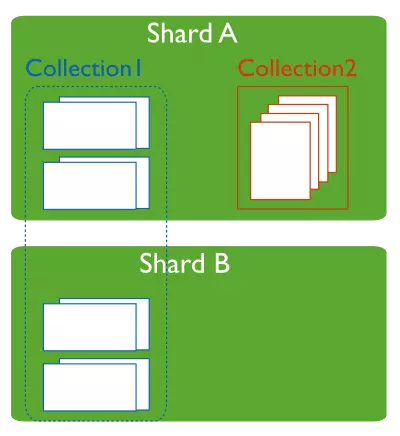
a、数据分片(Shards)
用来保存数据,保证数据的高可用性和一致性。可以是一个单独的mongod实例,也可以是一个副本集。在生产环境下Shard一般是一个Replica Set,以防止该数据片的单点故障。所有Shard中有一个PrimaryShard,里面包含未进行划分的数据集合:
b、查询路由(Query Routers)
路由就是mongos的实例,客户端直接连接mongos,由mongos把读写请求路由到指定的Shard上去。
一个Sharding集群,可以有一个mongos,也可以有多个mongos以减轻客户端请求的压力。
c、配置服务器(Config servers)
保存集群的元数据(metadata),包含各个Shard的路由规则。
Sharding分片技术(混合模式)高可用方案的架构图如下:
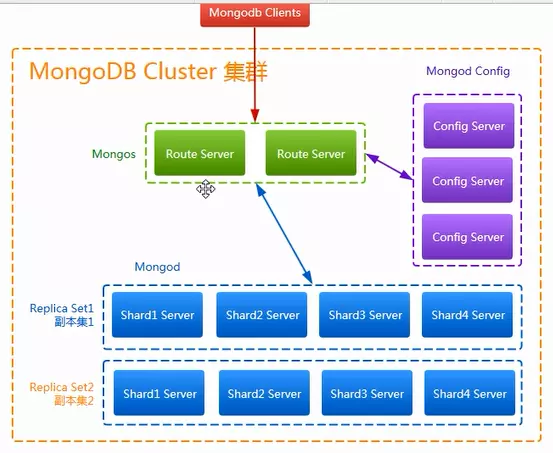
1)Sharding分片技术(混合模式)高可用架构下MongoDB数据写入流程
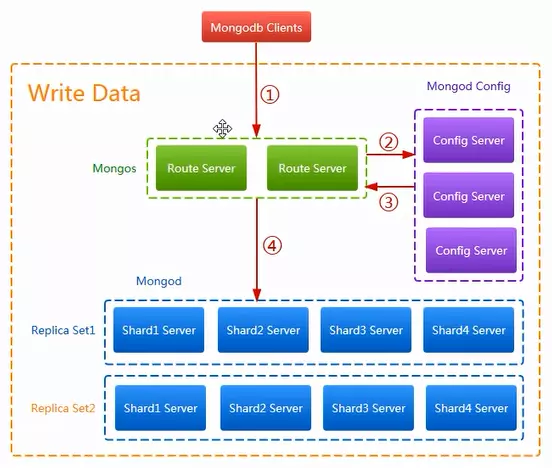
第一步:客户端访问路由服务器(Mongos),路由服务器接收到请求。
第二步:路由服务器将客户端访问配置服务器,配置服务器(Config)根据根据请求信息将数据信息写入到元数据中。
第三步:配置服务器将根据自身记录的元数据信息,指定数据存储位置,并将元数据信息(数据存储位置)返回给路由服务器。
第四步:路由服务器根据Config服务器返回的配置信息,将数据存储到mongod中(数据存储服务器)。存储服务器对数据进行备份和分片存储。
2)高可用集群下从MongoDB读取数据流程
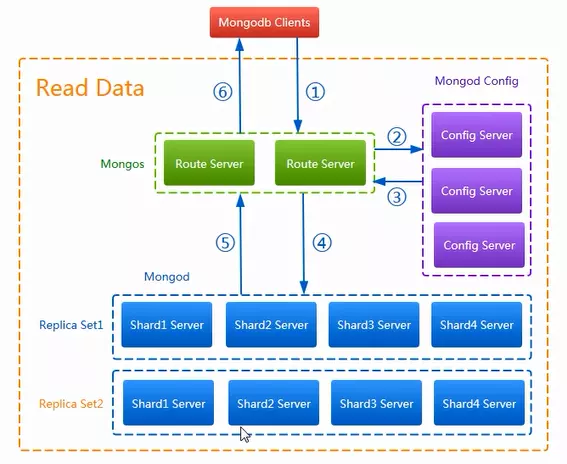
第一步:Mongos接受客户端请求,根据并判断请求是否合理(数据库地址是否正确,连接数是否超过最大)
第二步:路由服务器与客户端建立连接,并根据请求信息,去Config服务器中查询元数据信息。
第三步:config服务器将数信息返回给路由服务器。
第四步: config服务器根据元数据信息(数据存储位置),去MongoD服务器中,查询数据。
第五步:数据服务器将数据查询结果返回给路由服务器。
三、Sharding分片高可用方案搭建过程
1、MongoDB机器信息
| 192.168.86.131 | 192.168.86.132 | 192.168.86.133 |
| mongos | mongos | mongos |
| config server | config server | config server |
| shard server1 主节点 | shard server1 副节点 | shard server1 仲裁 |
| shard server2 仲裁 | shard server2 主节点 | shard server2 副节点 |
| shard server3 副节点 | shard server3 仲裁 | shard server3 主节点 |
2、端口分配
- mongos:20000
- config:21000
- shard1:27001
- shard2:27002
- shard3:27003
3、下载并且安装
- wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-amazon-4.0.9.tgz
- tar -xzvf mongodb-linux-x86_64-amazon-4.0.9.tgz -C /usr/local/
4、建立软连接并配置path信息
- cd /usr/local/
- ln -s /usr/local/mongodb-linux-x86_64-amazon-3.6.2 /usr/local/mongodb
进入到/etc/profile中配置MongoDB的全局变量信息
- vi /etc/profile
- # MongoDB 环境变量内容
- export MONGODB_HOME=/usr/local/mongodb
- export PATH=$MONGODB_HOME/bin:$PATH
生效环境变量
source /etc/profile
5、为服务器建立日志和数据目录
分别在每台机器建立conf、mongos、config、shard1、shard2、shard3六个目录,因为mongos不存储数据,只需要建立日志文件目录即可。
- mkdir -p /usr/local/mongodb/conf \
- mkdir -p /usr/local/mongodb/mongos/log \
- mkdir -p /usr/local/mongodb/config/data \
- mkdir -p /usr/local/mongodb/config/log \
- mkdir -p /usr/local/mongodb/shard1/data \
- mkdir -p /usr/local/mongodb/shard1/log \
- mkdir -p /usr/local/mongodb/shard2/data \
- mkdir -p /usr/local/mongodb/shard2/log \
- mkdir -p /usr/local/mongodb/shard3/data \
6、config server配置服务器
mongodb3.4版本以后要求配置服务器也创建副本集,不然集群搭建不成功。
(三台机器)添加配置文件
- vi /usr/local/mongodb/conf/config.conf
- ## 配置文件内容
- pidfilepath = /usr/local/mongodb/config/log/configsrv.pid
- dbpath = /usr/local/mongodb/config/data
- logpath = /usr/local/mongodb/config/log/congigsrv.log
- logappend = true
- bind_ip = 0.0.0.0
- port = 21000
- fork = true
- #declare this is a config db of a cluster;
- configsvr = true
- #副本集名称
- replSet = configs
- #设置最大连接数
- maxConns = 20000
启动三台服务器的config server
mongod -f /usr/local/mongodb/conf/config.conf
登录任意一台配置服务器,初始化配置副本集
连接 MongoDB
mongo --port 21000
配置config变量
- config = {
- _id : "configs",
- members : [
- {_id : 0, host : "192.168.86.131:21000" },
- {_id : 1, host : "192.168.86.132:21000" },
- {_id : 2, host : "192.168.86.133:21000" }
- ]
- }
初始化副本集
- rs.initiate(config)
响应内容如下
- > config = {
- ... _id : "configs",
- ... members : [
- ... {_id : 0, host : "192.168.86.131:21000" },
- ... {_id : 1, host : "192.168.86.132:21000" },
- ... {_id : 2, host : "192.168.86.133:21000" }
- ... ]
- ... }
- {
- "_id" : "configs",
- "members" : [
- {
- "_id" : 0,
- "host" : "192.168.86.131:21000"
- },
- {
- "_id" : 1,
- "host" : "192.168.86.132:21000"
- },
- {
- "_id" : 2,
- "host" : "192.168.86.133:21000"
- }
- ]
- }
- > rs.initiate(config);
- {
- "ok" : 1,
- "operationTime" : Timestamp(1517369899, 1),
- "$gleStats" : {
- "lastOpTime" : Timestamp(1517369899, 1),
- "electionId" : ObjectId("000000000000000000000000")
- },
- "$clusterTime" : {
- "clusterTime" : Timestamp(1517369899, 1),
- "signature" : {
- "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
- "keyId" : NumberLong(0)
- }
- }
- }
- configs:SECONDARY>
此时会发现终端上的输出已经有了变化。
- //从单个一个
- >
- //变成了
- configs:SECONDARY>
查询状态
- configs:SECONDARY> rs.status()
7、配置分片服务器
7.1设置第一个分片服务器
(三台机器)设置第一个分片副本集
配置文件
- vi /usr/local/mongodb/conf/shard1.conf
- #配置文件内容
- #——————————————–
- pidfilepath = /usr/local/mongodb/shard1/log/shard1.pid
- dbpath = /usr/local/mongodb/shard1/data
- logpath = /usr/local/mongodb/shard1/log/shard1.log
- logappend = true
- bind_ip = 0.0.0.0
- port = 27001
- fork = true
- #副本集名称
- replSet = shard1
- #declare this is a shard db of a cluster;
- shardsvr = true
- #设置最大连接数
- maxConns = 20000
启动三台服务器的shard1 server
mongod -f /usr/local/mongodb/conf/shard1.conf
登陆任意一台服务器,初始化副本集(除了192.168.86.133),因为仲裁服务器没有访问权限,负责会初始化失败。
连接 MongoDB
mongo --port 27001
使用admin数据库
use admin
定义副本集配置
- config = {
- _id : "shard1",
- members : [
- {_id : 0, host : "192.168.86.131:27001" },
- {_id : 1, host : "192.168.86.132:27001" },
- {_id : 2, host : "192.168.86.133:27001" , arbiterOnly: true }
- ]
- }
初始化副本集配置
rs.initiate(config)响应内容如下
- > use admin
- switched to db admin
- > config = {
- ... _id : "shard1",
- ... members : [
- ... {_id : 0, host : "192.168.86.131:27001" },
- ... {_id : 1, host : "192.168.86.132:27001" },
- ... {_id : 2, host : "192.168.86.133:27001" , arbiterOnly: true }
- ... ]
- ... }
- {
- "_id" : "shard1",
- "members" : [
- {
- "_id" : 0,
- "host" : "192.168.86.131:27001"
- },
- {
- "_id" : 1,
- "host" : "192.168.86.132:27001"
- },
- {
- "_id" : 2,
- "host" : "192.168.86.133:27001",
- "arbiterOnly" : true
- }
- ]
- }
- > rs.initiate(config)
- { "ok" : 1 }
此时会发现终端上的输出已经有了变化。
- //从单个一个
- >
- //变成了
- shard1:SECONDARY>
查询状态
- shard1:SECONDARY> rs.status()
7.2设置第二和第三个分片服务器
第二、第三个服务器配置过程同上,只需将配置文件中的服务器名称改为shard2、shard3,将端口改为27002,27003即可,仲裁服务器分别选择第二个和第三个。
8、配置路由服务器 mongos
8.1 配置并初始化
(三台机器)先启动配置服务器和分片服务器,后启动路由实例启动路由实例:
- vi /usr/local/mongodb/conf/mongos.conf
- #内容
- pidfilepath = /usr/local/mongodb/mongos/log/mongos.pid
- logpath = /usr/local/mongodb/mongos/log/mongos.log
- logappend = true
- bind_ip = 0.0.0.0
- port = 20000
- fork = true
- #监听的配置服务器,只能有1个或者3个 configs为配置服务器的副本集名字
- configdb = configs/192.168.86.131:21000,192.168.86.132:21000,192.168.86.133:21000
- #设置最大连接数
- maxConns = 20000
启动三台服务器的mongos server
mongos -f /usr/local/mongodb/conf/mongos.conf
8.2 串联路由服务器
目前搭建了mongodb配置服务器、路由服务器,各个分片服务器,不过应用程序连接到mongos路由服务器并不能使用分片机制,还需要在程序里设置分片配置,让分片生效。
登陆任意一台mongos
mongo --port 20000使用admin数据库
use admin
串联路由服务器与分配副本集
- sh.addShard("shard1/192.168.86.131:27001,192.168.86.132:27001,192.168.86.123:27001");
- sh.addShard("shard2/192.168.86.131:27002,192.168.86.132:27002,192.168.86.133:27002");
- sh.addShard("shard3/192.168.86.131:27003,192.168.86.132:27003,192.168.86.133:27003");
- 查看集群状态
- sh.status()
响应内容如下
- mongos> sh.status()
- --- Sharding Status ---
- sharding version: {
- "_id" : 1,
- "minCompatibleVersion" : 5,
- "currentVersion" : 6,
- "clusterId" : ObjectId("5a713a37d56e076f3eb47acf")
- }
- shards:
- { "_id" : "shard1", "host" : "shard1/192.168.86.131:27001,192.168.86.132:27001", "state" : 1 }
- { "_id" : "shard2", "host" : "shard2/192.168.86.132:27002,192.168.86.133:27002", "state" : 1 }
- { "_id" : "shard3", "host" : "shard3/192.168.86.131:27003,192.168.86.133:27003", "state" : 1 }
- active mongoses:
- "4.0.9" : 3
- autosplit:
- Currently enabled: yes
- balancer:
- Currently enabled: yes
- Currently running: no
- Failed balancer rounds in last 5 attempts: 0
- Migration Results for the last 24 hours:
- No recent migrations
- databases:
- { "_id" : "config", "primary" : "config", "partitioned" : true }
- mongos>
四、启用集合分片
目前配置服务、路由服务、分片服务、副本集服务都已经串联起来了,但我们的目的是希望插入数据,数据能够自动分片。连接在mongos上,准备让指定的数据库、指定的集合分片生效。
登陆任意一台mongos
mongo --port 20000
使用admin数据库
use admin
指定testdb分片生效,如下图:
- db.runCommand( { enablesharding :"testdb"});
- 或
- mongos> sh.enablesharding("testdb")
指定数据库里需要分片的集合和片键,哈希id分片(注意:分片的字段数据应该是变化的,不然分片不成功),如下图:
- db.runCommand( { shardCollection : "testdb.table1",key : {"name": "hashed"} } );
- 或
- mongos> sh.shardCollection("testdb.table1", {"name": "hashed"})
通过命令查看mongodb路由服务器上的shards集合会有数据展示,如下图:
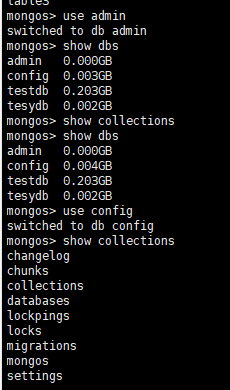
通过命令查看mongodb路由服务器上的chunks集合会有数据展示,如下图

测试分片配置结果
切换到 testdb 数据库
use testdb;
插入测试数据
- for(i=1;i<=100000;i++){db.table3.insert({"id":i,"name":"penglei"})};
总条数
- db.table1.aggregate([{$group : {_id : "$name", totle : {$sum : 1}}}])
查看分片情况如下
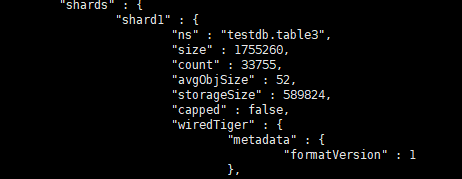
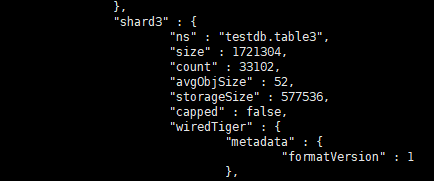
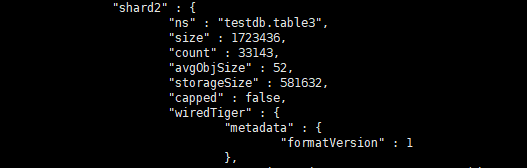
结论数据基本均匀

MongoDB分片技术原理和高可用集群配置方案的更多相关文章
- MongoDB高可用集群配置方案
原文链接:https://www.jianshu.com/p/e7e70ca7c7e5 高可用性即HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非 ...
- MongoDB高可用集群配置的方案
>>高可用集群的解决方案 高可用性即HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性. ...
- MySQL高可用集群MHA方案
MySQL高可用集群MHA方案 爱奇艺在用的数据库高可用方案 MHA 是目前比较成熟及流行的 MySQL 高可用解决方案,很多互联网公司正是直接使用或者基于 MHA 的架构进行改造实现 MySQL 的 ...
- SpringCloud-day04-Eureka高可用集群配置
5.4Eureka高可用集群配置 在高并发的情况下一个注册中心难以满足,因此一般需要集群配置多台. 我们再新建两个module microservice-eureka-server-2002, m ...
- Eureka注册中心高可用集群配置
Eureka高可用集群配置 当注册中心扛不住高并发的时候,这时候 要用集群来扛: 我们再新建两个module microservice-eureka-server-2002 microservic ...
- Hadoop入门学习笔记-第三天(Yarn高可用集群配置及计算案例)
什么是mapreduce 首先让我们来重温一下 hadoop 的四大组件:HDFS:分布式存储系统MapReduce:分布式计算系统YARN: hadoop 的资源调度系统Common: 以上三大组件 ...
- RHCS高可用集群配置(luci+ricci+fence)
一.什么是RHCS RHCS是Red Hat Cluster Suite的缩写,也就是红帽集群套件,RHCS是一个能够提供高可用性.高可靠性.负载均衡.存储共享且经济廉价的集群工具集合,它将集群 ...
- harbor高可用集群配置
目录 说明 双主复制 主从同步 双主复制说明 多harbor实例共享后端存储 方案说明 环境说明 配置说明 安装redis和mysql 导入registry数据库 配置harbor 挂载nfs目录 修 ...
- Hadoop(25)-高可用集群配置,HDFS-HA和YARN-HA
一. HA概述 1. 所谓HA(High Available),即高可用(7*24小时不中断服务). 2. 实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制:HDFS的HA ...
随机推荐
- ANSYS布尔运算APDL
目录 1.交运算 2.加运算 3.减运算 4.分割 5. 搭接 6. 互分 6.粘结 1.交运算 交运算的结果是由每个初始图元的共同部分,形成一个新的图元. 命令 功能 备注 LINL 线与线的交 A ...
- C++ STL之集合set的使⽤
写在最前面,本文摘录于柳生笔记: set是集合,一个set里面个元素各不相同的,而且set会按照元素从小到大的进行排序,一下是set的常用方法:
- php的注释、变量、类型、常量、运算符、比较符、条件语句;
php的注释 1.// 2.# 3./* */ 变量 变量是储存信息的容器: 变量规则: 1.变量以$开头,后面跟名称>>>$sum; 2.变量必须以字母或下滑先开头,不能用数字开 ...
- 重新理解CEO的学习能力----HHR计划----以太入门课--第一课
一共5个小节. 第一节:开始学习 1,投资人最看重的一点:CEO的学习能力. (因为CEO需要:找优秀的合伙人,需要市场调研,机会判断,组建团队,验证方向,去融资,冷启动,做增长,解决法务,财务,税务 ...
- nginx的addition模块在响应的前后报文添加内容与变量的运行原理
nginx默认未编译此模块:让nginx编译启用此模块 ./configure --prefix=/data/web --sbin-path=/usr/bin --user=nginx --group ...
- spring boot中不能识别RestController
参考:https://blog.csdn.net/qq_16739693/article/details/80271987
- redis 高级学习和应用场景
redis 高级学习 1.redis 复制 2.redis 集群 3.哨兵机制 4.spring 与哨兵结合 5.数据恢复与转移 6.redis 的阻塞分析 redis 实战 1. 数据缓存(热点数据 ...
- Java后端 带File文件及其它参数的Post请求
http://www.roak.com Java 带File文件及其它参数的Post请求 对于文件上传,客户端通常就是页面,在前端web页面里实现上传文件不是什么难事,写个form,加上enctype ...
- vue中 el [$el] 的理解
<template> <div class="a"> <div class="basic" ref="ba"& ...
- css属性选择器: | 与 ~
[attribute|=value] 选择器用于选取带有以指定值开头的属性值的元素. 注释:该值必须是整个单词,指属性的值是一个完整的单词,并未被中断.如“eng”."img".& ...