Pyspider的基本使用 -- 入门
简介
- 一个国人编写的强大的网络爬虫系统并带有强大的WebUI
- 采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器
- 官方文档:http://docs.pyspider.org/en/latest/
安装
- pip install pyspider
- 安装失败的解决方法
启动服务
- 命令窗口输入pyspider
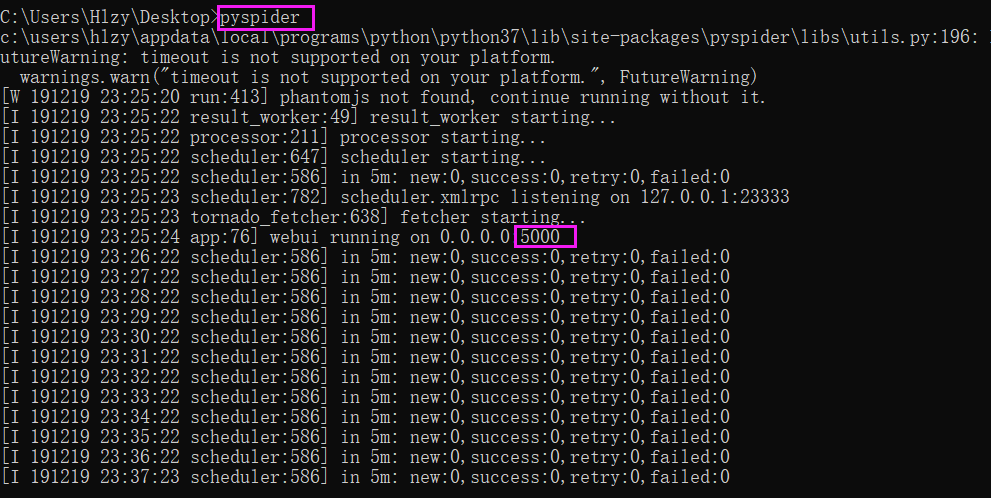
打开Web界面
- 浏览器输入localhost:5000

创建项目

删除项目
- 删除某个:设置 group 为 delete ,status 为 stop ,24小时之后自动删除

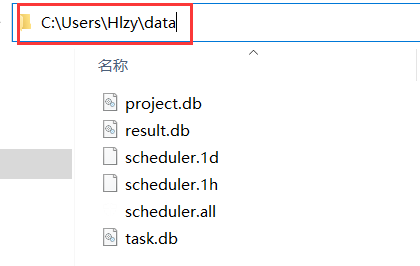
- 删除全部:在启动服务的路径下,找到它自己生成的data目录,直接删除目录里的所有文件
禁止证书验证

- 加上参数 validate_cert = False
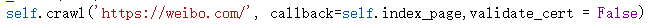
使用方法
- on_start(self)
- 入口方法,run的时候,默认会调用
- crawl()
- 生成一个新的爬取请求,类似于scrapy.Request,接受的参数是ur1和callback
- @every(minutes=2, seconds=30)
- 告诉scheduler两分30秒执行一次
- @config(age=10 * 24 * 60 * 60)
- 告诉调度器(单位:秒)、这个请求过期时间是10天、10天之内不会再次请求
- @config(priority=2)
- 优先级、数字越大越先执行
- age写在函数里面跟写在装饰器上的区别
- 写在函数里面的后执行,下图实际过期时间为5秒,若函数里没有age,则为装饰器里定义的20秒

- 写在函数里面的后执行,下图实际过期时间为5秒,若函数里没有age,则为装饰器里定义的20秒
执行任务
- 完成脚本编写,调试无误后,先save脚本,然后返回到控制台首页
- 直接点击项目状态status那栏,把状态由TODO改成DEBUG或RUNNING
- 最后点击项目最右边的Run按钮启动项目
对接phantomjs
- 将phantomjs.exe放在Python环境根目录下,或者将所在目录添加到系统的环境变量
- 添加成功,启动服务时,会显示如下信息
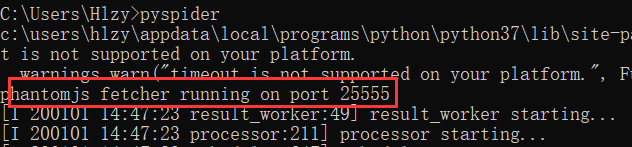
没使用js渲染
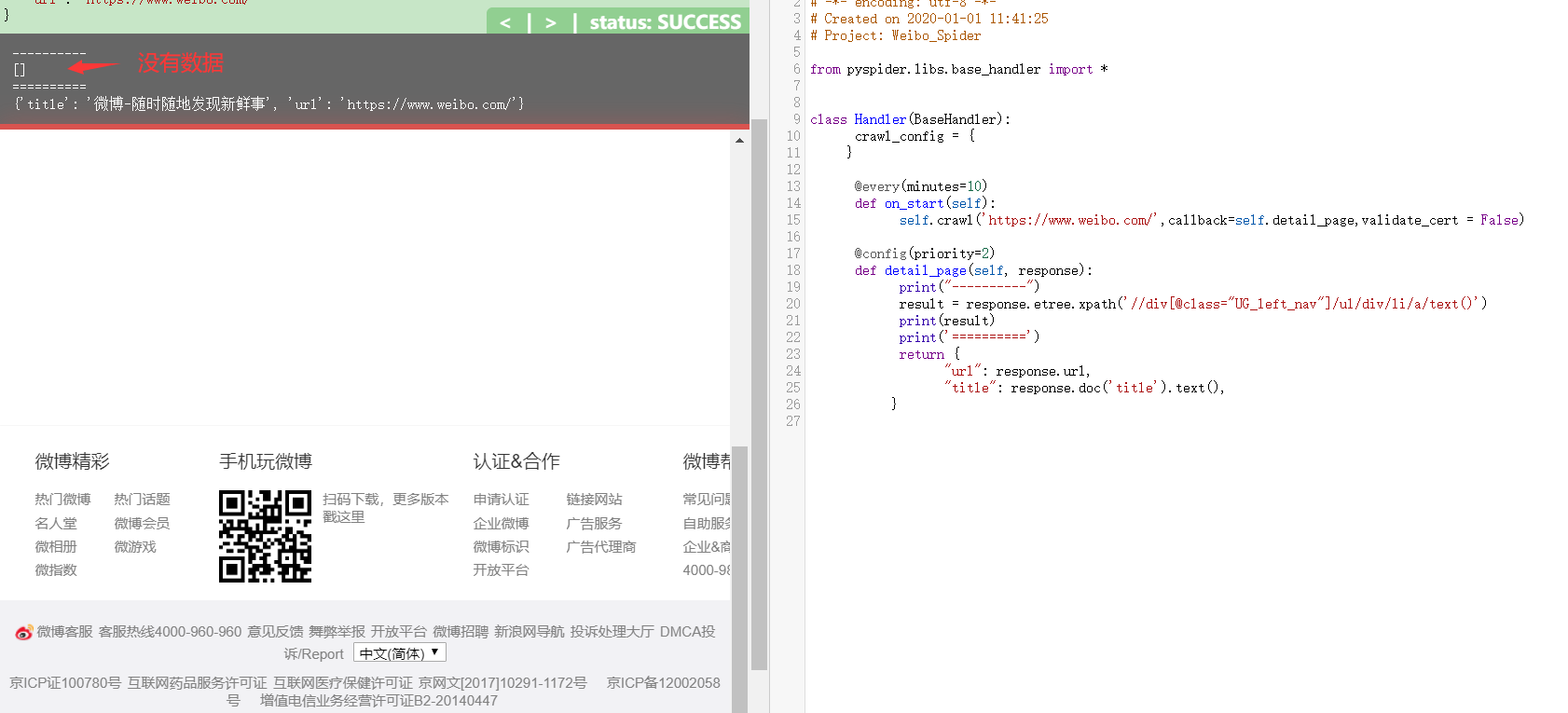
使用js渲染
- 添加参数 fetch_type = 'js'
其它
- rate/burst
- rate:一秒钟执行的请求个数
- burst:并发的数量
- 例如:2/5、每秒两个请求,并发数量为5,即每秒10个请求
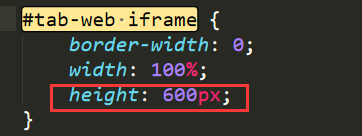
- 设置渲染的web页面的高度

- 在源代码里修改css样式即可(#tab-web iframe)
- css文件路径:python安装目录下 Lib\site-packages\pyspider\webui\static 里的 debug.min.css
Pyspider的基本使用 -- 入门的更多相关文章
- Python爬虫入门教程 27-100 微医挂号网专家团队数据抓取pyspider
1. 微医挂号网专家团队数据----写在前面 今天尝试使用一个新的爬虫库进行数据的爬取,这个库叫做pyspider,国人开发的,当然支持一下. github地址: https://github.com ...
- 爬虫入门【10】Pyspider框架简介及安装说明
Pyspider是python中的一个很流行的爬虫框架系统,它具有的特点如下: 1.可以在Python环境下写脚本 2.具有WebUI,脚本编辑器,并且有项目管理和任务监视器以及结果查看. 3.支持多 ...
- Python爬虫入门教程 29-100 手机APP数据抓取 pyspider
1. 手机APP数据----写在前面 继续练习pyspider的使用,最近搜索了一些这个框架的一些使用技巧,发现文档竟然挺难理解的,不过使用起来暂时没有障碍,估摸着,要在写个5篇左右关于这个框架的教程 ...
- Python爬虫入门教程 28-100 虎嗅网文章数据抓取 pyspider
1. 虎嗅网文章数据----写在前面 今天继续使用pyspider爬取数据,很不幸,虎嗅资讯网被我选中了,网址为 https://www.huxiu.com/ 爬的就是它的资讯频道,本文章仅供学习交流 ...
- pyspider入门
1.http://www.pyspider.cn/jiaocheng/pyspider-webui-12.html 2.https://blog.csdn.net/weixin_37947156/ar ...
- 2、Pyspider使用入门
1.接上一篇,在webui页面,点击右侧[Create]按钮,创建爬虫任务 2.输入[Project Name],[Start Urls]为爬取的起始地址,可以先不输入,点击[Create]进入: 3 ...
- 爬虫入门【11】Pyspider框架入门—使用HTML和CSS选择器下载小说
开始之前 首先我们要安装好pyspider,可以参考上一篇文章. 从一个web页面抓取信息的过程包括: 1.找到页面上包含的URL信息,这个url包含我们想要的信息 2.通过HTTP来获取页面内容 3 ...
- 【Hawk】入门教程(1)——从URL开始
入门教程(1)--从URL开始 首先感谢辛苦的沙漠君 先把沙漠君的教程载过来:)可以先看一遍 Hawk-数据抓取工具:简明教程 Hawk 数据抓取工具 使用说明(二) 20分钟无编程抓取大众点评17万 ...
- python爬虫如何入门
学爬虫是循序渐进的过程,作为零基础小白,大体上可分为三个阶段,第一阶段是入门,掌握必备的基础知识,第二阶段是模仿,跟着别人的爬虫代码学,弄懂每一行代码,第三阶段是自己动手,这个阶段你开始有自己的解题思 ...
随机推荐
- java获取当前机器的公网ip
package com.Interface.util; import javax.servlet.http.HttpServletRequest; /** * 测试类 * * @author 华文 * ...
- i.MX RT600之DSP调试环境搭建篇
恩智浦的i.MX RT600是跨界处理器产品,同样也是i.MX RTxxx系列的开山之作.不同于i.MX RT1xxx系列单片机,i.MX RT600 采用了双核架构,将新一代Cortex-M33内核 ...
- redhat7.6 httpd 匿名目录 目录加密 域名跳转
配置文件/etc/httpd/conf/httpd.conf 监听80端口和8080端口 1.80端口 2.域名 3.index.html目录 4.网站目录 options Indexes //代 ...
- 重学Linux - 文件处理命令
文件处理命令 @auther 张念磊 @date 2020/1/29 touch 命令所在路径:/bin/touch 执行权限:所有用户 语法:touch [filename] 功能描述:创建空文件 ...
- 「AHOI2014/JSOI2014」骑士游戏
「AHOI2014/JSOI2014」骑士游戏 传送门 考虑 \(\text{DP}\). 设 \(dp_i\) 表示灭种(雾)一只编号为 \(i\) 的怪物的代价. 那么转移显然是: \[dp_i ...
- 《JavaScript高级程序设计》读书笔记(二)在html中使用JavaScript
主要内容---使用<script>元素---嵌入脚本与外部脚本---文档模式对JavaScript的影响---考虑禁用JavaScript的场景 <script>元素---向h ...
- JavaScript 引擎「V8」发布 8.0 版本,内存占用量大幅下降
上周,JavaScript 引擎「V8」的开发团队在该项目官方网站上正式宣布推出最新的 8.0 版本.这次更新的重点主要集中在错误修复及性能改善上,正式的版本将在数周后随着谷歌 Chrome 80 稳 ...
- 关于Action模型驱动无法获取属性的问题
这两天在练习ssh小项目发现action层怎都无法获取Ajax传过来的json: 1.检查表单name和action定义属性名是否一致 2.get/Set方法 3.表单和属性名的命名问题,驼峰法
- Qt5.5 使用smtp发邮件的各种坑
本人刚开始学习C++,用的是Qt5.5的IED,经过了两天的学习和查找资料,终于成功发了第一封邮件.以163邮箱为例,简单总结一下. 1.设置邮箱 这一步比较关键,要开通smtp服务,在开通的过程中会 ...
- 【转载】手把手教你使用Git(简单,实用)
手把手教你使用Git(简单,实用) 标签: git 2016年04月21日 20:51:45 1328人阅读 评论(0) 收藏 举报 一:Git是什么? Git是目前世界上最先进的分布式版本控制系统. ...