自动网络搜索(NAS)在语义分割上的应用(二)
前言:
- 由于光线等原因,实际场景图像的intensity分布更复杂,而segmentation需要细分边界, 对像素值的判定尤为重要。然而,相比detection来说segmentation的数据标记成本高导致训练数据较少,只依靠data augmentation等手段提升有限。
- Segmentation是pixelwise的任务,因为它要处理到每一个pixel,所以模型一般都会比object detection的模型大许多(你看这个模型它又长又宽)。如果你的模型被要求real-time推理(>16 fps),那么准确度和速度必然会成为冲突,Double kill!
- 当语义分割用在了视频流,对准确度的要求会更高。即使每两帧只相差几个pixel,即使在mIoU的数值上相差无几,但是人眼看上去不够稳定,会有“抖动”的边界, Triple kill!
- 当语义分割模型走下云端,部署在算力有限的移动端,底层芯片可能对很多操作不支持,使得在原本在可以在GPU上开心玩耍的模型到了CPU上便一朝打回解放前, Quadra kill!
1.Overview of ProxylessNAS
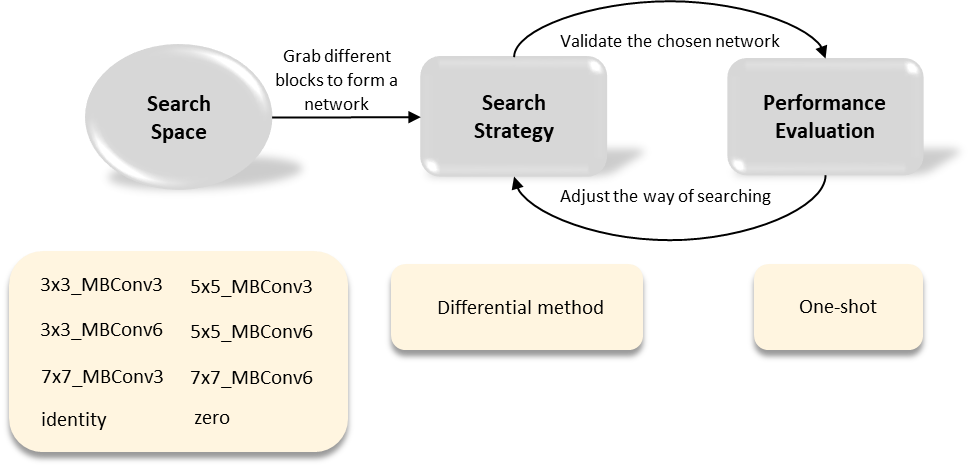
Figure 1: NAS framework
- Search Space: 在搜索空间中定义的operation candidate的是来自MobileNetv2 [8]的block,分别取不同的kernel size(3, 5, 7)和不同的expansion rate(3,6),再加上identity和zero操作一共8种ops(c.f. Figure 1)。 网络的宏观结构是一个常见的链状结构来完成classification, 每一层都有8个ops candidate(c.f. Figure 2)。正如前面提到的,算子之间太复杂的连接方式会让速度变慢,常见的小模型结构都是这种链状结构。
- Search Strategy: 搜索策略采用可微分的方法,这种搜索策略近两年很常见。虽然不及RL和EA稳定,但是可以大幅度提高搜索速度。
- Evaluation Performance: One-shot 权值共享, 也是现有最常见的super-net的形式。对于计算资源匮乏的团队和个人来说,这种方式能够提高搜索效率减少内存占用。
- Training: 每个iteration开始的时候,在每一层都随机激活一个operation(c.f. the binary gate in Figure 2),将所有激活的operation连接起来组成一条子网络记为subnet,通过back propagation来更新这条subnet的weight。没有激活的ops不放入内存,也就是说训练的时候只有一条subnet在内存中,这也使得整个搜索过程可以在单卡上完成。
- Searching:每个operation的权重alpha代表它的重要程度,也就是最终被选择的概率,probability = Softmax(alphas)。换言之,搜索的过程,就是不断更新权重alpha的过程。和training一样,每个iteration都要随机激活一条subnet,但是这次要让operation的weight固定,通过back propagation计算这条subnet上的alpha。Paper里面Eq (4)给出了计算方式,由于binary gate和probability成正比,公式里面将loss对probability的求导转化成对binary gate的求导,而loss对binary gate的导数在back propagation的时候有计算过并且保存了下来(这部分paper没有细说可参考源代码)。
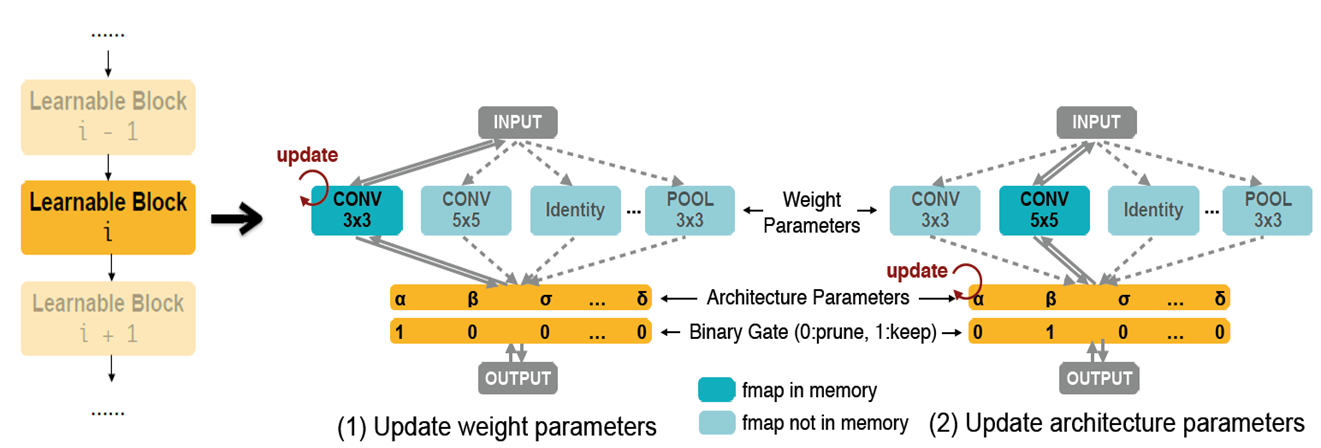
Figure 2 illustrates the architecture of the super-net: the chained-structure searchable backbone (left) and each layer of the searchable backbone (right).

2.Real-time Semantic Segmentation using ProxylessNAS on CPU
- Search space: 在设置搜索空间的时候,秉着大力出奇迹的心态我把常用的operation都塞了进来,分别是MBv3 (3x3), MBv3 (5x5), DilConv (3x3), DilConv (5x5), SepConv (3x3), SepConv (5x5), ShuffleBlock一共7种ops。其中MBv3是来自MobileNetv3 [5]的基本模块,DilConv和SepConv是来自DARTS [1]的dilated sepatable convolutions和separable convolutions,ShuffleBlock是来自ShuffleNetv2 [4]的基本模块,前面三种operation都设置了两种kernel size可以选择。在定义宏观网络结构的时候,采用deeplabv3+ [9]的结构 (c.f. Figure 3): head + searchable backbone + ASPP + decoder。与UNet类似,将encoder的feature map直接”add”到decoder,这里没有用”concatenation”是为了避免模型过“宽”使速度变慢。其中s2, s4, s8, s16, s32分别指feature map的resolution下降2,4,8,16,32倍。与ProxylessNAS类似,supernet的参数包含两部分,一部分是operation本身的weight,另一部分是operation的权重alpha。
- Searching Strategy: 延续ProxylessNAS的可微分求导方式
- Evaluation Performance: One-shot权重共享
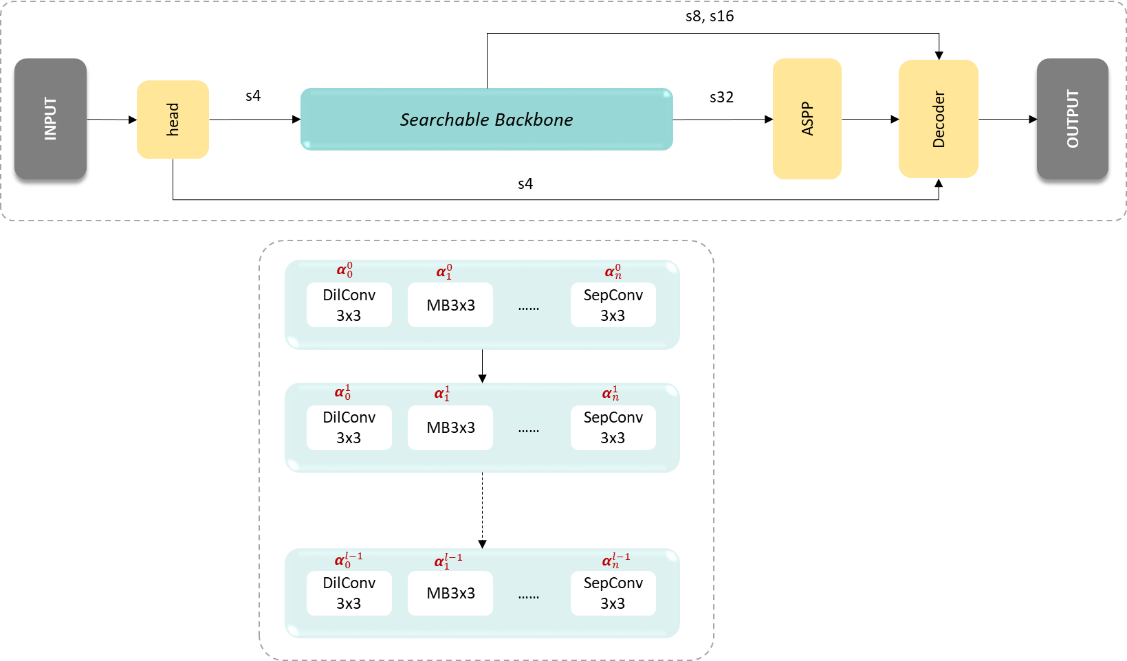
Figure 3 illustrates the macro-architecture of our super-net (top) and the searchable backbone (bottom)
- Decoupling the training and searching process: 在ProxylessNAS中“training”和“searching”是同时轮流完成的,也就是一边训练一边搜索。我在实验的时候把“training”和“searching”彻底分开,先用50个epochs只更新super-net里面operation的参数,在训练之后,再更新operation的权重alphas。这么做的原因是避免在operation参数不稳定的时候,某些alpha过大影响后面的决策。
- Consider the latency as a hard constraint: 因为模型推理速度比较重要,而且不能用简单的叠加方式计算,所以每次随机激活subnet的时候都要算一下这条subnet的推理速度,如果不符合要求(如latency > 30ms)则重新搜索一条subnet,这样一定程度上避免很多推理速度过慢的operation被选择和学习。
- Task: 基于CPU(x86)的实时人像分割
- DL platform: Intel openvinohttps://software.intel.com/content/www/us/en/develop/tools/openvino-toolkit.html
- Dataset : >20k张图像,一部分来自 coco/pascal数据集中带有”person”类别的,另一部分是私有数据
- Data augmentation: random crop, cutout, random brightness/contrast adjust, random Gaussian blur/sharpen
- Searching time: 单卡2 GPU days (K80) 包括training和searching
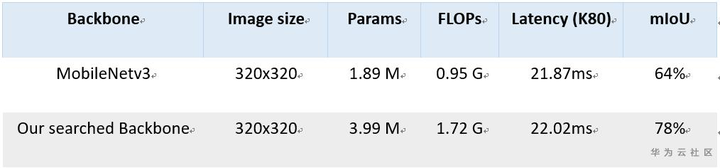

Figure 4 compares the segmentation results of our searched network and MobileNetv3

Figure 5 shows the segmentation results in real application scenario
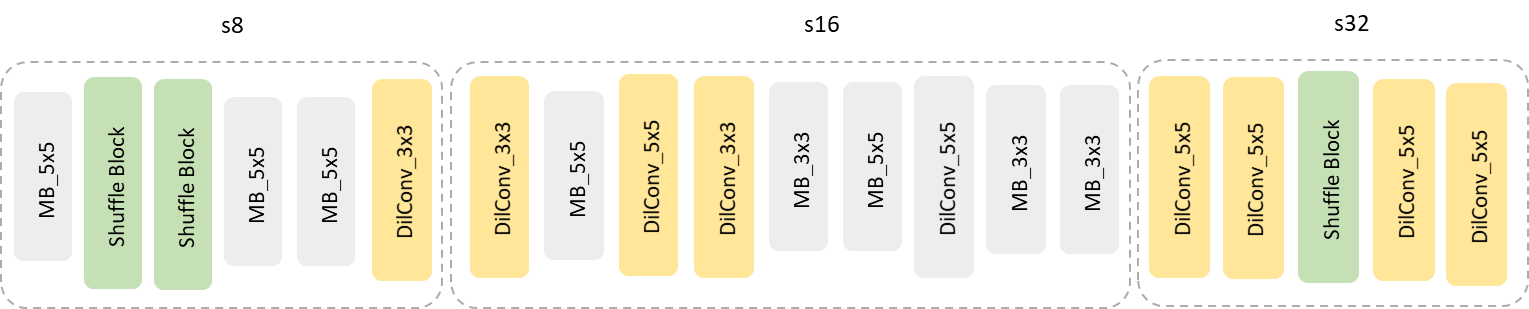
Figure 6 illustrates the searched backbone structure
3.Future work
- 实验结果表明super-net权值共享的形式有一定合理性。但是在结构搜索的时候,将每层probability最大的operation组成subnet作为输出结果还是有不合理之处。因为subnet在搜索和训练的时候具有一定的耦合性,每层的operation一荣俱荣一损俱损。最终将每层最佳的operation选出来,组合在一起的时候未必能符合预先设定的hard constraint,这里还是有需要改进的地方,比如可以计算相邻两层operation的sub-path的权重代替每层operation的权重。
- ProxylessNAS是MIT Hansong团队早期的work,现在已有后续OFA问世(也是跪着读完的)。在OFA中作者彻底将training和searching分开,结合了knowledge distillation,先训练teacher model,然后用NAS的思路在teacher model中搜索出最佳student model。OFA可以理解为自动化network pruning或自动distillation。如果OFA实验效果好,后续还会有关于OFA的实战经验的分享。
- Figure 5种实际效果展示的时候,人像和背景融合的比较自然,但是语义分割归根到底是一个分类任务,边缘的pixel“非黑即白”,如果想要和背景自然的融合,需要计算出前景的透明度alpha matte,这里涉及到另一项背景抠图技术,和segmentation配合使用效果更佳。其实Figure 5的下图中已经看出segmentation没有把头发分割出来,但是在结果中却保留了下来,也是用了背景抠图的原因。Matting除了可以优化segmentation结果,还可以实现切换背景(cf. Figure 7),PS等功能。
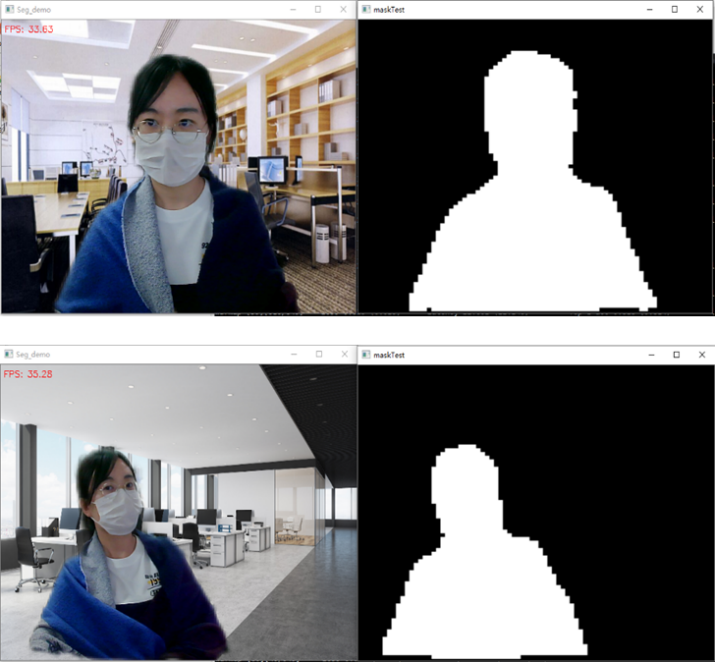
Figure 7 shows the demo of background matting

自动网络搜索(NAS)在语义分割上的应用(二)的更多相关文章
- 自动网络搜索(NAS)在语义分割上的应用(一)
[摘要]本文简单介绍了NAS的发展现况和在语义分割中的应用,并且详细解读了两篇流行的work:DARTS和Auto-DeepLab. 自动网络搜索 多数神经网络结构都是基于一些成熟的backbone, ...
- 【Semantic segmentation Overview】一文概览主要语义分割网络(转)
文章来源:https://www.tinymind.cn/articles/410 本文来自 CSDN 网站,译者蓝三金 图像的语义分割是将输入图像中的每个像素分配一个语义类别,以得到像素化的密集分类 ...
- 多篇开源CVPR 2020 语义分割论文
多篇开源CVPR 2020 语义分割论文 前言 1. DynamicRouting:针对语义分割的动态路径选择网络 Learning Dynamic Routing for Semantic Segm ...
- 细粒度语义分割:ICCV2019论文解析
细粒度语义分割:ICCV2019论文解析 Fine-Grained Segmentation Networks: Self-Supervised Segmentation for Improved L ...
- FCN与U-Net语义分割算法
FCN与U-Net语义分割算法 图像语义分割(Semantic Segmentation)是图像处理和是机器视觉技术中关于图像理解的重要一环,也是 AI 领域中一个重要的分支.语义分割即是对图像中每一 ...
- CVPR2020:点云弱监督三维语义分割的多路径区域挖掘
CVPR2020:点云弱监督三维语义分割的多路径区域挖掘 Multi-Path Region Mining for Weakly Supervised 3D Semantic Segmentation ...
- [论文][半监督语义分割]Adversarial Learning for Semi-Supervised Semantic Segmentation
Adversarial Learning for Semi-Supervised Semantic Segmentation 论文原文 摘要 创新点:我们提出了一种使用对抗网络进行半监督语义分割的方法 ...
- 几篇关于RGBD语义分割文章的总结
最近在调研3D算法方面的工作,整理了几篇多视角学习的文章.还没调研完,先写个大概. 基于RGBD的语义分割的工作重点主要集中在如何将RGB信息和Depth信息融合,主要分为三类:省略. 目录 ...
- 语义分割--全卷积网络FCN详解
语义分割--全卷积网络FCN详解 1.FCN概述 CNN做图像分类甚至做目标检测的效果已经被证明并广泛应用,图像语义分割本质上也可以认为是稠密的目标识别(需要预测每个像素点的类别). 传统的基于C ...
随机推荐
- C++编程入门题目--No.4
题目: 输入某年某月某日,判断这一天是这一年的第几天? 程序分析: 以3月5日为例,应该先把前两个月的加起来,然后再加上5天即本年的第几天,特殊情况,闰年且输入月份大于3时需考虑多加一天. #incl ...
- python sort和sorted的区别
sort 与 sorted 区别: sort 是应用在 list 上的方法,使用方法为 list.sort(),是对原有列表进行操作,改变原有列表的排序: sorted 可以对所有可迭代的对象进行排序 ...
- async与await----js的异步处理
async与await----js的异步处理 博客说明 文章所涉及的资料来自互联网整理和个人总结,意在于个人学习和经验汇总,如有什么地方侵权,请联系本人删除,谢谢! 说明 之前写代码遇到一个问题,返回 ...
- P1680 奇怪的分组(组合数+逆元)
传送门戳我 首先将n减去所有的Ci,于是是原问题转换为:n个相同的球放入m个不同盒子里,不能为空,求方案数. 根据插空法:n个球,放到m个箱子里去不能为空,也就是有m-1块板子放在n-1个空隙之间 那 ...
- P2320鬼谷子的钱袋(分治)
------------恢复内容开始------------ 描述:https://www.luogu.com.cn/problem/P2320 m个金币,装进一些钱袋.钱袋中大于1的钱互不相同. 问 ...
- Code::Blocks无法调试 Starting the debuggee failed: No executable specified, use `target exec'
1.必须建立工程 2.工程名不可有特殊字符或空格,可以有字母.数字.下划线 2.编译器设置里勾选-g(产生调试符号) 3.重新编译项目(如果之前编译过了) 4.调试器设置 > Default & ...
- 2020年python开发微信小程序,公众号,手机购物商城APP
2020年最新的技术全栈,手机短信注册登陆等运用, 精准定位用户 支付宝支付 以及前后端从0到大神的全部精解 2020年最新的技术全栈,手机短信注册登陆等运用, 精准定位用户 支付宝支付 以及前后端从 ...
- pyhanlp安装成功,import导入失败,出现:importerror: cannot import name 'jvmnotfoundexception'
1.问题描述: pyhanlp成功安装,并且可以正常使用,但是这段时间再去用的时候,发现出问题了,一运行就出现,下面的问题: importerror: cannot import name 'jvmn ...
- java1.8新特性之stream
什么是Stream? Stream字面意思是流,在java中是指一个来自数据源的元素队列并支持聚合操作,存在于java.util包中,又或者说是能应用在一组元素上一次执行的操作序列.(stream是一 ...
- CF-557C Arthur and Table 权值线段树
Arthur and Table 题意 一个桌子有n个腿,每个腿都有一个高度,当且仅当最高的腿的数量大于桌子腿数量的一半时,桌子才是稳定的.特殊的是当只有一个腿时,桌子是稳定的,当有两个腿时两个腿必须 ...