Spark SQL源码解析(五)SparkPlan准备和执行阶段
Spark SQL原理解析前言:
Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述
Spark SQL源码解析(二)Antlr4解析Sql并生成树
Spark SQL源码解析(四)Optimization和Physical Planning阶段解析
SparkPlan准备阶段介绍
前面经过千辛万苦,终于生成可实际执行的SparkPlan(即PhysicalPlan)。但在真正执行前,还需要做一些准备工作,包括在必要的地方插入一些shuffle作业,在需要的地方进行数据格式转换等等。
这部分内容都在org.apache.spark.sql.execution.QueryExecution类中。我们看看代码
class QueryExecution(val sparkSession: SparkSession, val logical: LogicalPlan) {
......其他代码
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)
//调用下面的preparations,然后使用foldLeft遍历preparations中的Rule并应用到SparkPlan
protected def prepareForExecution(plan: SparkPlan): SparkPlan = {
preparations.foldLeft(plan) { case (sp, rule) => rule.apply(sp) }
}
/** A sequence of rules that will be applied in order to the physical plan before execution. */
//定义各个Rule
protected def preparations: Seq[Rule[SparkPlan]] = Seq(
PlanSubqueries(sparkSession),
EnsureRequirements(sparkSession.sessionState.conf),
CollapseCodegenStages(sparkSession.sessionState.conf),
ReuseExchange(sparkSession.sessionState.conf),
ReuseSubquery(sparkSession.sessionState.conf))
......其他代码
}
准备阶段是去调用prepareForExecution方法,而prepareForExecution也简单,还是我们早先看过的Rule那一套东西。定义一系列的Rule,然后让Rule去匹配SparkPlan然后转换一遍。
这里在于每条Rule都是干嘛用的,这里介绍一下吧。
PlanSubqueries(sparkSession)
生成子查询,在比较早的版本,Spark SQL还是不支持子查询的,不过现在加上了,这条Rule其实是对子查询的SQL新生成一个QueryExecution(就是我们一直分析的这个流程),还记得QueryExecution里面的变量基本都是懒加载的吧,这些不会立即执行,都是到最后一并执行的,说白了就有点递归的意思。
EnsureRequirements(sparkSession.sessionState.conf)
这条是比较重要的,代码量也多。主要就是验证输出的分区(partition)和我们要的分区是不是一样,不一样那自然需要加入shuffle处理重分区,如果有排序需求还会排序。
CollapseCodegenStages
这个是和一个优化相关的,先介绍下相关背景。Whole stage Codegen在一些MPP数据库被用来提高性能,主要就是将一串的算子,转换成一段代码(Spark sql转换成java代码),从而提高性能。比如下图,一串的算子操作,可以转换成一个java方法,这一一来性能会有一定的提升。

这一步就是在支持Codegen的SparkPlan上添加一个WholeStageCodegenExec,不支持Codegen的SparkPlan则会添加一个InputAdapter。这一点在下面看preparations阶段结果的时候能看到,还有这个优化是默认开启的。
ReuseExchange和ReuseSubquery
这两个都是大概同样的功能就放一块说了。首先Exchange是对shuffle如何进行的描述,可以理解为就是shuffle吧。
这里的ReuseExchange是一个优化措施,去找有重复的Exchange的地方,然后将结果替换过去,避免重复计算。
ReuseSubquery也是同样的道理,如果一条SQL语句中有多个相同的子查询,那么是不会重复计算的,会将计算的结果直接替换到重复的子查询中去,提高性能。
这里我略过了CollapseCodegenStages,这部分比较复杂,也没什么时间看,就先跳过了,大概知道这个东西是一个优化措施就行了。
那再来看看这一阶段后,示例代码会变成什么样吧,先看示例代码:
//生成DataFrame
val df = Seq((1, 1)).toDF("key", "value")
df.createOrReplaceTempView("src")
//调用spark.sql
val queryCaseWhen = sql("select key from src ")
结果生成如下:
Project [_1#2 AS key#5]
+- LocalTableScan [_1#2, _2#3]
好吧这里看还是和之前Optimation阶段一样,不过断点看就不大一样了。
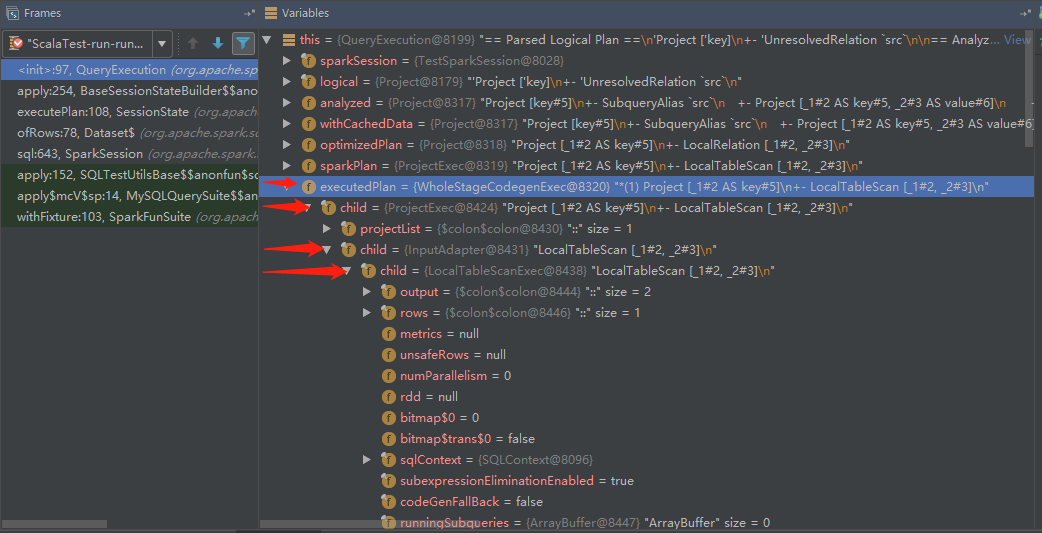
由于我们的SQL比较简单,所以只多了两个SparkPlan,就是WholeStageCodegenExec和InputAdapter,和上面说的是一致的!
OK,经过以上的准备之后,就要开始最后的执行阶段了。
SparkPlan执行生成RDD阶段
依旧是在QueryExecution里面,
class QueryExecution(val sparkSession: SparkSession, val logical: LogicalPlan) {
......其他代码
lazy val toRdd: RDD[InternalRow] = executedPlan.execute()
......其他代码
}
这里实际上是调用了之前生成的SparkPlan的execute()方法,这个方法最终会再调用它的doExecute()方法,而这个方法是各个子类自己实现的,也就是说,不同的SparkPlan执行的doExecute()是不一样的。
通过上面的阶段,我们得到了一棵4层的树,不过其中WholeStageCodegenExec和InputAdapter是为Codegen优化生成的,这里就不讨论了,忽略这两个其实结果是一样的。也就是说这里只介绍ProjectExec和LocalTableScanExec两个SparkPlan的doExecute()方法。
先是ProjectExec这个SparkPlan,我们看看它的doExecute()代码。
case class ProjectExec(projectList: Seq[NamedExpression], child: SparkPlan)
extends UnaryExecNode with CodegenSupport {
......其他代码
protected override def doExecute(): RDD[InternalRow] = {
child.execute().mapPartitionsWithIndexInternal { (index, iter) =>
val project = UnsafeProjection.create(projectList, child.output,
subexpressionEliminationEnabled)
project.initialize(index)
iter.map(project)
}
}
......其他代码
}
可以看到它是先递归去调用child(也就是LocalTableScanExec)的doExecute()方法,还是得先去看看LocalTableScanExec生成什么东西呀。
case class LocalTableScanExec(
output: Seq[Attribute],
@transient rows: Seq[InternalRow]) extends LeafExecNode {
......其他代码
private lazy val rdd = sqlContext.sparkContext.parallelize(unsafeRows, numParallelism)
protected override def doExecute(): RDD[InternalRow] = {
val numOutputRows = longMetric("numOutputRows")
rdd.map { r =>
numOutputRows += 1
r
}
}
......其他代码
可以看到最底层的rdd就是在这里实现的,LocalTableScanExec一开始就会生成一个lazy的rdd,在需要的时候返回。而在doExecute()方法中的numOutputRows可以理解为仅是一个测量值,暂时不用理会。总之这里我们就发现LocalTableScanExec的doExecute()其实就是返回一个parallelize生成的rdd。然后再回到ProjectExec去。
它调用child.execute().mapPartitionsWithIndexInternal {......},这里的mapPartitionsWithIndexInternal和rdd的mapPartitionsWithIndex是类似的,区别只在于mapPartitionsWithIndexInternal只会在内部模块使用,如果有童鞋不明白mapPartitionsWithIndex这个API,可以百度查查看。然后重点看mapPartitionsWithIndexInternal的内部逻辑。
child.execute().mapPartitionsWithIndexInternal { (index, iter) =>
val project = UnsafeProjection.create(projectList, child.output,
subexpressionEliminationEnabled)
project.initialize(index)
iter.map(project)
}
这里最后一行iter.map(project),其实还是scala的语法糖,实际大概是这样iter.map(i => project.apply(i))。就是调用project的apply方法,对每行数据处理。然后通过追踪,可以发现project的实例是InterpretedUnsafeProjection,我们看看它的apply方法。
class InterpretedUnsafeProjection(expressions: Array[Expression]) extends UnsafeProjection {
......其他代码
override def apply(row: InternalRow): UnsafeRow = {
// Put the expression results in the intermediate row.
var i = 0
while (i < numFields) {
values(i) = expressions(i).eval(row)
i += 1
}
// Write the intermediate row to an unsafe row.
rowWriter.reset()
writer(intermediate)
rowWriter.getRow()
}
......其他代码
这里其实重点在最后三行,就是将结果写入到result row,再返回回去。当执行完毕的时候,就会得到最终的RDD[InternalRow],再剩下的,就交给spark core去处理了。
小结
OK,那到这里基本就把Spark整个流程给讲完了,回顾一下整个流程。
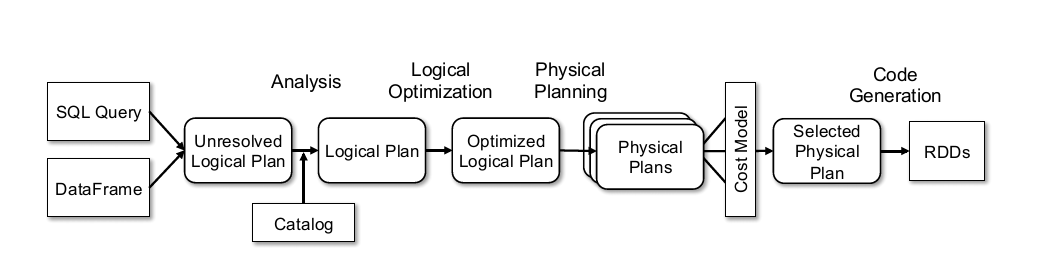
其实可以发现流程是挺简单的,很多其他SQL解析框架(比如calcite)也是类似的流程,只是在设计上在某些方面的取舍会有偏差。而后深入到代码的时候容易陷入一些细节中,当然这几篇也省略了很多细节,很多时候细节才是真正精髓的地方,以后有如果涉及到的时候再写文章讨论吧(/偷笑)。如果在开放过程中涉及到SQL解析这方面的开放,应该都会是在优化方面,也就是Optimization阶段增加或处理Rule,这块就需要对代数优化理论和代码有一些了解了。
限于本人水平,介绍spark sql的这几篇文章难免有疏漏和不足的地方,欢迎在评论区评论,先谢过了~~
以上~
Spark SQL源码解析(五)SparkPlan准备和执行阶段的更多相关文章
- Spark SQL源码解析(四)Optimization和Physical Planning阶段解析
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Spark SQL源码解析(三 ...
- Spark SQL源码解析(三)Analysis阶段分析
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Analysis阶段概述 首先 ...
- Spark SQL源码解析(二)Antlr4解析Sql并生成树
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 这一次要开始真正介绍Spark解析SQL的流程,首先是从Sql Parse阶段开始,简单点说, ...
- 第十一篇:Spark SQL 源码分析之 External DataSource外部数据源
上周Spark1.2刚发布,周末在家没事,把这个特性给了解一下,顺便分析下源码,看一看这个特性是如何设计及实现的. /** Spark SQL源码分析系列文章*/ (Ps: External Data ...
- 第十篇:Spark SQL 源码分析之 In-Memory Columnar Storage源码分析之 query
/** Spark SQL源码分析系列文章*/ 前面讲到了Spark SQL In-Memory Columnar Storage的存储结构是基于列存储的. 那么基于以上存储结构,我们查询cache在 ...
- 第九篇:Spark SQL 源码分析之 In-Memory Columnar Storage源码分析之 cache table
/** Spark SQL源码分析系列文章*/ Spark SQL 可以将数据缓存到内存中,我们可以见到的通过调用cache table tableName即可将一张表缓存到内存中,来极大的提高查询效 ...
- 第七篇:Spark SQL 源码分析之Physical Plan 到 RDD的具体实现
/** Spark SQL源码分析系列文章*/ 接上一篇文章Spark SQL Catalyst源码分析之Physical Plan,本文将介绍Physical Plan的toRDD的具体实现细节: ...
- 第一篇:Spark SQL源码分析之核心流程
/** Spark SQL源码分析系列文章*/ 自从去年Spark Submit 2013 Michael Armbrust分享了他的Catalyst,到至今1年多了,Spark SQL的贡献者从几人 ...
- 【Spark SQL 源码分析系列文章】
从决定写Spark SQL源码分析的文章,到现在一个月的时间里,陆陆续续差不多快完成了,这里也做一个整合和索引,方便大家阅读,这里给出阅读顺序 :) 第一篇 Spark SQL源码分析之核心流程 第二 ...
随机推荐
- Chrome最新版如何安装Proxy SwitchyOmega
由于Chrome的代理设置与windows10的1703及以后的版本不兼容,导致无法使用代理功能,给工作带来了很大的不便.最近发现一款不错的Chrome代理插件Proxy SwitchyOmega,由 ...
- codeforce 225B Code Parsing
Little Vitaly loves different algorithms. Today he has invented a new algorithm just for you. Vita ...
- pycharm(py 文件中添加作者、时间)
1.打开 Pycharm,点击 File,再找到 Settings... 2.选择 Editor ----> File and Code Templates ----> Python Sc ...
- 经典卷积神经网络算法(1):LeNet-5
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- django3开发完整博客带评价
纯django开发最完美博客 2020年5月打造最时尚博客系统教程 为了学习速度,集中精力学习django和博客开发, 没有使用其它框架,也没有使用css预处理等 这样学起来最方便, 博客前后端都完成 ...
- 02_互联网基本原理和HTML入门
上节课的知识复习 互联网的原理:服务器.浏览器.HTTP.知道网页文件是真实的物理存在,用HTTP请求这个文件. 要知道网址的含义:http://www.iqianduan.cn/aaa 请求哪个文件 ...
- k-modes聚类算法
为什么要用k-modes算法 k-means算法是一种简单且实用的聚类算法,但是传统的k-means算法只适用于连续属性的数据集(数值型数据),而对于离散属性的数据集,计算簇的均值以及点之间的欧式距离 ...
- CF-234 F. Fence DP
F. Fence 这个刷Fence的问题看到好几个了... 题意 有一个栅栏,由n块宽为1cm的木板组成,第i块木板高为hi,要给他们刷上油漆,有一桶红色的可以刷a平方厘米的油漆,一桶绿色的可以刷b平 ...
- nginx源码安装方法
nginx源码安装方法 安装方法如下 1.安装nginx必要的源码依赖软件包. yum -y install gcc gcc-c++ automake pcre pcre-devel zlib zli ...
- static RMQ
RMQ问题:对于长度为N的序列,询问区间[L,R]中的最值 RMQ(Range Minimum/Maximum Query),即区间最值查询. 常见解法: 1.朴素搜索 2.线段树 3.DP 4.神奇 ...